ЛР2 вопросы. Почему анализ называется линейным
 Скачать 1.25 Mb. Скачать 1.25 Mb.
|

|
Почему анализ называется линейным? Анализ называется линейным потому что он характеризует то как взаимодействуют между собой линейные функции, характеризует то, каким предполагается воздействие переменных друг на друга. В самом простом видео это:   Почему анализ называется регрессионным? Анализ называется регрессионным потому что регрессия представляет собой анализ форм связи и устанавливает количественные соотношения между случайными величинами. Регрессио́нный анализ — набор статистических методов исследования влияния одной или нескольких независимых переменных. на зависимую переменную. . Независимые переменные иначе называют регрессорами. Ну то есть мы же в лабах изучаем влияние независимых переменных на зависимую, вот это и есть регрессия. Почему анализ называется множественным? Анализ называется множественным, потому что в модели результативный признак связан с несколькими факторными признаками. y b0 b1 x1 b2 x2 + . Сколько показателей содержится в исходных данных? 1 – результативный показатель, 3 – факторных показателя. Какие показатели использовались как факторные, какие- как результативные? Работающие активы, млн руб – это результативный показатель. Средства предприятий и организаций(%), Кредиты предприятиям и организациям (млн руб.), Средства предприятий и организаций (млн руб.) – факторные показатели. Как выглядит уравнение регрессии в двухфакторном линейном регрессионном анализе? В общем случае множественного регрессионного анализа? Уравнение регрессии в двухфакторном линейном регрессионном анализе выглядит так : y=b0+b1x1+b2x2 + Общее уравнение множественной регрессии : y=b0+b1x1+b2x2 +b3x3 +…+bnxn + где x – значения факторных признаков, b – параметры уравнения ( коэффициенты регрессии) 7. Сколько получился, что показывают и в чем измеряются полученные коэффициенты регрессии? (в контексте рассматриваемой проблемной ситуации) Коэффициент регрессии показывает на сколько единиц изменится результат при изменении фактора на 1 единицу. B показывает среднеее изменение y, a - прогнозирует у. 8. Каково направление связи между каждым фактором и результативным показателем? Направление связи измеряется с помощью коэффициента Пирсона. (вроде у каждого конкретно своё) 9. Чем прямая связь отличается от обратной? Знак при линейном коэффициенте корреляции указывает на направление связи - прямой зависимости соответствует знак плюс, а обратной зависимости - знак минус. 10. Что показывает коэффициент детерминации?  11. Как обозначаются расчетные значения результативного показателя? ŷi - расчетное значение результативного признака ??? 12.Как рассчитываю расчетные значения результативного показателя? Прогнозное значение 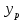 определяется путем подстановки в уравнение регрессии соответствующего прогнозного значения определяется путем подстановки в уравнение регрессии соответствующего прогнозного значения 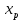 . Вычисляется средняя стандартная ошибка прогноза: . Вычисляется средняя стандартная ошибка прогноза: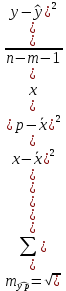 И строится доверительный интервал прогноза: 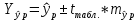 13.Как обозначается коэффициент детерминации? В чем он измеряется и в каких пределах может варьировать? Коэффициент детерминации обозначается: Характеризует долю вариации результативного признака, объясняемую регрессией yˆ в общей вариации y. Чем ближе 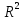 к единице, тем лучше качество подгонки. к единице, тем лучше качество подгонки. Он принимает значения из интервала (отрезка) [0;1] 14.Выполните тесты Стьюдента и Фишера. Оцените 95% и 99% доверительные интервалы для коэффициентов b1 и b2 .Ответьте на вопросы: Оценка значимости уравнения регрессии в целом дается с помощью F-критерия Фишера. Согласно F-критерию Фишера, выдвигается «нулевая» гипотеза H0 о статистической незначимости уравнения регрессии и показателя тесноты связи.  Для оценки статистической значимости коэффициентов регрессии и корреляции рассчитывается t-критерии Стьюдента и доверительные интервалы каждого из показателей. Оценка значимости с помощью t-критерия Стьюдента проводится путем сопоставления их значений с величиной случайной ошибки  Определим доверительные интервалы коэффициентов построенной регрессии (при помощи регрессии в Excel) нулевое значение Если полученный интервал не включает делаем вывод о значимом отличии от нуля коэффициента. Если же точка 0 лежит в интервале - то интервальная оценка коэффициента статистически незначима. 15.Что означает термин «значимость»? Это означает, что фактор не влияет на изменение Y 16.Какова альтернативная гипотеза в F-критерии? ( в контекст6е рассматриваемой проблемной ситуации) Ho : гипотеза об отсутствии линейной связи между x и y Так как F расч. ˃ F табл., то: С вероятностью 0,95 отвергаем нулевую гипотезу об отсутствии линейной связи между Y , X1,X3 в пользу альтернативной гипотезы о наличии линейной связи 17. В результате выполнения F-критерия нулевая гипотеза была принята или отвергнута? Почему? Так как Fтабл.< Fрасч. с вероятностью 0,95 отвергаем нулевую гипотезу от отсутствии линейной связи между Y и Х1, Х3, Х2 в пользу альтернативной гипотезы о наличии линейной связи 18. В результате выполнения F-критерия альтернативная гипотеза была принята или отвергнута? Почему? Принимаем альтернативную гипотезу о наличии линейной связи¸ так как Fтабл.< Fрасч. 19. Какова нулевая гипотеза в t-критерии для каждого коэффициента? (в контексте рассматриваемой проблемной ситуации); Для Y-пересечения Но: гипотеза о незначимости фактора х (отвергаем) Для переменных Х1,Х2,Х3 Но: гипотеза о незначимости фактора х (принимаем) 20. Какова альтернативная гипотеза в t-критерии для каждого коэффициента? (в контексте рассматриваемой проблемной ситуации); Для Y-пересечения Н1: гипотеза о значимости фактора х (принимаем) Для переменных Х1,Х2,Х3 Н1: гипотеза о значимости фактора х (отвергаем) 21. Какой вывод был сделан относительно значимости факторов? Для Y-пересечения :с вероятностью 0,95 отвергаем гипотезу о незначимости фактора х в пользу альтернативной гипотезы о значимости фактора Для факторов Х1, Х2, Х3: с вероятностью 0,95 принимаем гипотезы о незначимости фактора 22) Как рассчитали доверительные интервалы для прогноза результативной переменной? Что нужно рассчитать для нахождения доверительного интервала зависимой переменной? При построении доверительного интервала прогноза используется стан- дартная ошибка прогноза Sy Далее находим искомый доверительный интервал 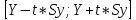 , ,t – определяем по таблице Стьюдента 23) Какой интервал получится шире- 95% или 99%? 99% доверительный интервал шире, чем 95%, но это мои догадки 24) В чем различие между доверительными интервалами для оценки среднего и индивидуального значения результативного признака? Какой из этих интервалов получился шире, почему? Что еще влияет на ширину доверительного интервала результативного признака? Различие между доверительными интервалами для оценки среднего и индивидуального значения в среднем квадратичном отклонении. Интервал для индивидуального значения получился шире, чем интервал для среднего значения, так как средняя ошибка для индивидуального значения больше средней ошибки для среднего значения. 25) Что такое автокорреляция в остатках? Как она влияет на результаты оценивания регрессионного уравнения? Автокорреляция остатков чаще всего наблюдается тогда, когда эконометрическая модель строится на основе временных рядов. Если существует корреляция между последовательными значениями некоторой независимой переменной, то будет наблюдаться и корреляция последовательных значений остатков. Автокорреляция в остатках может быть вызвана несколькими причинами: 1. Она может быть связана с исходными данными и вызвана наличием ошибок измерения в значениях результативного признака. 2. В ряде случаев автокорреляция может быть следствием неправильной спецификации модели. Модель может не включать фактор, который оказывает существенное воздействие на результат и влияние которого отражается в остатках, вследствие чего последние могут оказаться автокоррелированными. Один из более распространенных методов определения автокорреляции в остатках – это расчет критерия Дарбина-Уотсона: 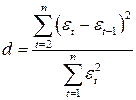 На практике пользуются следующим правилом: DW близкое к 2 свидетельствует об отсутствии автокорреляции остатков; DW близкое к 0 свидетельствует о наличии положительной автокорреляции остатков; DW близкое к 4 свидетельствует об отрицательной автокорреляции остатков 26, Для чего используется статистика Дарбина-Уотсона? Критерий Дарбина-Уотсона (или DW-критерий) — статистический критерий, используемый для нахождения автокорреляции остатков первого порядка регрессионной модели. На практике применение критерия Дарбина—Уотсона основано на сравнении величины d с теоретическими значениями dL и dU для заданного числа наблюдений n, числа независимых переменных модели k и уровня значимости α. Если d < dL, то гипотеза о независимости случайных отклонений отвергается (следовательно присутствует положительная автокорреляция); Если d > dU, то гипотеза не отвергается; Если dL < d < dU, то нет достаточных оснований для принятия решений. Когда расчетное значение d превышает 2, то с dL и dU сравнивается не сам коэффициент d, а выражение (4 − d). ВО 2Й ЛАБЕ ИСПОЛЬЗОВАЛИ N=3, ТЕ МЕНЯЮТСЯ ТОЛЬКО ТАЛИЧНЫЕ ЗНАЧЕНИЯ Какова нулевая гипотеза в тесте Дарбина-Уотсона? Н0: 0 , (т.е. автокорреляция остатков вида () отсутствует; H1: Какова альтернативная гипотеза в тесте Дарбина-Уотсона? Нарисуйте числовую ось, которую использовали для формулировки решения в тесте Дарбина-Уотсона.  Какой вывод сделали по результатам теста Дарбина-Уотсона? DW близкое к 2 свидетельствует об отсутствии автокорреляции остатков; DW близкое к 0 свидетельствует о наличии положительной автокорреляции остатков; DW близкое к 4 свидетельствует об отрицательной автокорреляции остатков. Для чего проводили тест Голфелда-Квандта? Тестирования гетероскедастичности случайных ошибок регрессионной модели, применяемая в случае, когда есть основания полагать, что стандартное отклонение ошибок может быть пропорционально некоторой переменной. Тест также основывается на предположении нормальности распределения случайных ошибок регрессионной модели. Фактически это f-тест, поскольку статистика теста имеет распределение фишера. Что такое гомоскедастичность и гетероскедастичность остатков модели? Какое из этих своиств негативно сказывается на качество оценивания регрессионной модели? Гетероскедастичность Термин гетероскедастичность в широком смысле понимается как предположение о дисперсии случайных ошибок модели регрессии. При построении нормальной линейной модели регрессии учитываются следующие условия, касающиеся случайной ошибки модели регрессии: Для обнаружения гетероскедастичности остатков модели регрессии необходимо провести их анализ. При этом проверяются следующие гипотезы. Основная гипотеза H0 предполагает постоянство дисперсий случайных ошибок модели регрессии, т. е. присутствие в модели условия гомоскедастичности: Альтернативная гипотеза H1 предполагает непостоянство дисперсиий случайных ошибок в различных наблюдениях, т. е. присутствие в модели условия гетероскедастичности:  Гомоскедастичность Гомоскедастичность остатков означает, что дисперсия каждого отклонения одинакова для всех значений x. Если это условие не соблюдается, то имеет место гетероскедастичность. Наличие гетероскедастичности можно наглядно видеть из поля корреляции.  33 Какова нулевая гипотеза в тесте Голфелда-Квандта? При выполнение нулевой гипотезы о гомоскедастичности отношение F будет удовлетворять критерию с степенями свободы для каждой остаточной суммы квадратов. Чем больше величина F превышает табличное значение F-критерия, тем более нарушена предпосылка о равенстве дисперсий остаточных величин. 34 Какова альтернативная гипотеза в Голфелда-Квандта? Основная и альтернативная гипотезы в тесте Голфельда – Квандта (и во всех остальных тестах, в которых проверяется, имеет ли место гетероскедастичность) формулируются следующим образом: H0: гомоскедастичность H1: гетероскедастичность 35 Какой вывод сделали по результатам теста Голфелда-Квандта? 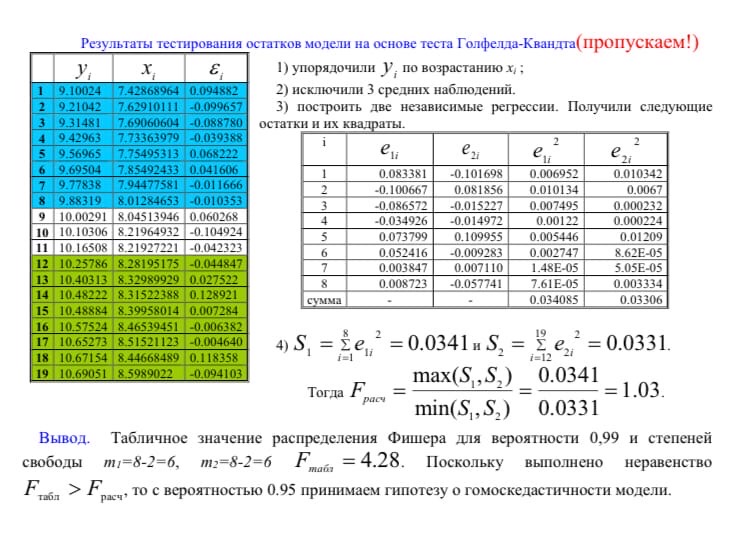 36 Что такое степень свободы для распределения? Какие значения степеней свободы использовали для нахождения табличного значения в F-критерии, t –критерии, тесте Дарбина-Уотсона, тесте Голфелда-Квандта? Аналогично ,меняются только табличные значения   37 Что такое мультиколлинеарность?каковы последствия мультиколлинеаоности?   38. Как определили наличие мультиколлинеарности в модели? Для этого с помощью Excel построили корреляционную матрицу. И если коэффициент корреляции между двумя параметрами X(икса) больше, чем 0,5, то мультиколлениарность считается установленной , т. е. между параметрами тесная линейная зависимость. 39. Имеет ли место мультиколлинеарность в оцененной модели? Каким способом вы решили вопрос мультиколлинеарности в модели? Мультиколлинеарность не имеет место в данной модели, т.к она может привести к нежелательным последствиям: -оценки параметров становятся ненадежными. Они обнаруживают большие стандартные ошибки. С изменением объема наблюдений оценки меняются (не только по величине, но и по знаку), что делает модель непригодной для анализа и прогнозирования. -затрудняется интерпретация параметров множественной регрессии как характеристик действия факторов в «чистом» виде, ибо факторы коррелированны; параметры линейной регрессии теряют экономический смысл; -становится невозможным определить изолированное влияние факторов на результативный показатель. Для устранения мультиколлениарности необходимо исключить из модели один из факторов (у которого расчетное значение t-критерия наименьшее) 40. Что понимается под адекватностью модели? Эконометрические модели создаются для последующего их использования, как инструмент прогнозирования поведения эндогенной переменной экономического объекта в различных условиях. Или, другими словами, чтобы ответить на вопрос: что будет, если определенные переменные объекта примут некоторое, интересующее нас, значение? Модель, таким образом, служит инструментом имитации поведения экономического объекта в различных ситуациях. Понятно, что лучшим ответом на вопрос "что будет?", было бы наблюдение за объектом в интересующей ситуации. Однако в экономике это или невозможно, или чревато негативными последствиями. Следовательно, в нашем случае под адекватностью модели следует понимать возможность получения прогноза с удовлетворительной точностью. Очевидно, чтобы оценить точность прогноза, необходимо сопоставить вычисленное по модели прогнозное значение эндогенной переменной с ее реальным значением при одинаковых значениях набора регрессоров. Если разница между этими значениями по абсолютной величине окажется приемлемой, то можно будет сделать вывод об адекватном описании поведения объекта полученной моделью. 41. С каких позиций исследуется адекватность линейной парной регрессии? Анализ адекватности модели является важным этапом эконометрического моделирования. Для проверки адекватности моделей множественной регрессии, также как и парной линейной регрессии используют коэффициент детерминации и его модификации(R^2,сигма^2), отражающие особенности множественной модели, а также процедуры проверки статистических гипотез и построения доверительных интервалов для оценок параметров и прогнозов зависимой переменной. 42. Какой вывод по результатам проведенного анализа можете сделать об адекватности модели? Основными направлениями оценки адекватности эконометрической модели являются: 1. Проверка с помощью F-теста (F-критерий Фишера)( Если расчетный F-критерий превышает его критическое значение, то можно утверждать, что объяснение, которое дает уравнение, в целом важно, а эконометрическая модель адекватна. В противном случае модель считается неадекватной, а объяснение неважным); 2. Использование t-распределения Стьюдента для оценки надежности коэффициента корреляции(Используется для оценки надежности коэффициента корреляции. Следует отметить, что когда нулевая гипотеза подтверждается, то значение t будет превышать его критическое значение (в положительную или отрицательную сторону) только в 5% случаев. Это означает, что при выполнении проверки вероятности допущения ошибки, отклоняющего нулевую гипотезу, когда она фактически правильным, составляет 5%. Вероятно, что риск допущения такой ошибки в 5% случаев достаточно большой для исследователя. Тогда он может сократить степень риска, осуществляя расчеты при уровне значимости в 1%. Критическое значение t сейчас будет выше, чем до сих пор, поэтому необходима более высокая (положительная или отрицательная) t-статистика для отклонения нулевой гипотезе, а это значит, что нужно более выше значение коэффициента корреляции); 3. Проверка модели на гомо-гетескедастичнисть(тест Голфелда-Квандта); 4. Проверка факторов эконометрической модели на мультиколинеарнисть. |