учебник по паскалю. Программа 5 Алгоритм 5 Свойства алгоритма 6 Формы записи алгоритма 6
 Скачать 2.21 Mb. Скачать 2.21 Mb.
|

10. Цикл со счетчиком и досрочное завершение цикловПрежде, чем перейти к примерам, обсудим еще ряд проблем, связанных с циклами. Как для while, так и для repeat, во-первых, нигде в явном виде не задается число шагов цикла (хотя его обычно можно вычислить), во-вторых, при использовании обоих циклов программист должен заботиться об изменении управляющей переменной. Между тем, весьма распространены задачи, где объем последовательно обрабатываемых данных известен заранее (а значит, известно и требуемое число шагов цикла), а управляющая переменная меняется с шагом, равным единице. Рассмотренный выше пример с двадцатью значениями x относится именно к таким задачам. Поэтому для обработки заранее известного объема данных с шагом по управляющей переменной, равным единице, вместо цикла while используется цикл со счетчиком (цикл for). Его общий вид следующий: for счетчик := НЗ to КЗ do begin {операторы тела цикла} end; Здесь счетчик -- целочисленная переменная, НЗ (начальное) и КЗ (конечное) значения -- целочисленные выражения или константы. Тело цикла образовано не менее чем одним оператором, если этот оператор единственный, операторные скобки можно не писать. Работает цикл for следующим образом: счетчик автоматически меняется от начального значения до конечного включительно, для каждого значения счетчика повторяется тело цикла. После каждого шага цикла значение счетчика автоматически увеличивается на единицу. Если требуется, чтобы значение счетчика уменьшалось, а не увеличивалось, вместо ключевого слова to используется downto. Подобно while, цикл for может не выполниться и ни разу -- если начальное значение управляющей переменной сразу же больше конечного (при использовании to) или меньше (при использовании downto). Запишем рассмотренный выше цикл по переменной x с помощью оператора for: for x:=1 to 20 do begin {операторы тела цикла} end; Удобства очевидны -- границы изменения x заданы сразу же при входе в цикл, а выполнять шаг по x отдельным оператором не требуется. Понятны и ограничения -- x должен быть описан с типом данных integer, а в случае изменения значения x с шагом, не равным единице, использовать for вместо while не удалось бы. Еще одна проблема связана с тем, что при выполнении программы довольно часто возникает необходимость завершить цикл досрочно -- например, если искомое в нем значение уже найдено или возникла ошибка, из-за которой дальнейшие шаги становятся бессмысленными. Теоретически цикл можно было бы завершить, присвоив управляющей переменной значение, выходящее за пределы ее изменения: x:=1; while x<10 do begin y:=ln(x); if y>2 then x:=10; {При y>2 цикл нужно завершить} x:=x+0.5; end; Однако, во избежание трудноуловимых ошибок, управляющую переменную не принято менять иначе, чем для выполнения шага цикла. Например, после оператора if y>2 then x:=10; в нашем листинге выполнение текущего шага продолжится, что чревато лишними или неправильными вычислениями. Кроме того, текст такой программы воспринимается нелегко. Поэтому для досрочного выхода из цикла существует оператор break (от англ. "to break" -- прервать), немедленно прекращающий его выполнение: x:=1; while x<10 do begin y:=ln(x); if y>2 then break; x:=x+0.5; end; Указание break здесь передаст управление на оператор, следующий непосредственно за циклом. В отличие от предыдущего примера, здесь не будет выполняться часть тела цикла, следующая за break;. Для немедленного продолжения цикла со следующего шага используется оператор continue (от англ. "to continue" -- продолжить): var n:integer; begin repeat writeln ('Введите положительное число:'); read (n); if n<1 then continue; {Если введено n<1, снова запросить число} {Операторы обработки числа} break; {Выход из цикла обработки} until false; end. В этом примере оператор continue использован для повторного перехода к вводу n, если введено n<1. Так как цикл обработки здесь -- бесконечный, для выхода из него необходим break;. Кроме того, пример показывает одну из возможностей контроля правильности ввода данных. Указав директиву {$I-}, изученную в гл. 8, мы могли бы защитить программу и от ввода пользователем нечисловых значений в качестве n. В теме "Кратные циклы" второй части курса будет рассмотрен оператор goto, также способный решить проблему аварийного завершения циклов. 11. Типовые алгоритмы табулирования функций, вычисления количества, суммы и произведенияИтак, основное назначение циклов -- обработка большого объема данных. Математически эта обработка зачастую сводится к поиску, выбору и статистической обработке нужных величин. Практически в любой реальной задаче мы ищем максимальные и минимальные значения в наборе данных, суммируем или перемножаем требуемые данные, определяем арифметическое среднее или количество элементов, отвечающих условию. Для решения всех этих распространенных задач существуют типовые алгоритмы, задающие правила выполнения соответствующих расчетов. Изучением этих алгоритмов мы займемся в гл. 11 и 12. Разумеется, настоящие задачи, встающие перед программистами, значительно сложнее, чем приведенные далее примеры, но из типовых алгоритмов, как из кирпичиков, строится здание любой сложной программы. 11.1. Алгоритм табулированияПрименяется для составления всевозможных таблиц, которыми могут быть как абстрактная таблица значений математической функции, так и конкретная таблица стоимости товара или платежей, совершенных абонентом сотового оператора. В общем виде алгоритм можно описать так:
В качестве примера составим таблицу синусов в пределах от 0 до π с шагом по аргументу 0.25. Обозначим аргумент как x, значение синуса от x обозначим как y. В простейшем случае программа табулирования может выглядеть так: var x,y:real; begin writeln('x':10,'sin(x)':10); {печать заголовка таблицы до цикла} x:=0; {начальное значение аргумента} while x<=pi+1e-6 do begin y:=sin(x); {вычисление функции} writeln (x:10:2, y:10:2); {печать строки таблицы} x:=x+0.25; {шаг по x} end; end. "Расширим" задачу за счет использования произвольных границ изменения аргумента и произвольного шага, а также выполнения всех необходимых проверок корректности. Пусть, например, требуется составить таблицу значений следующей функции: 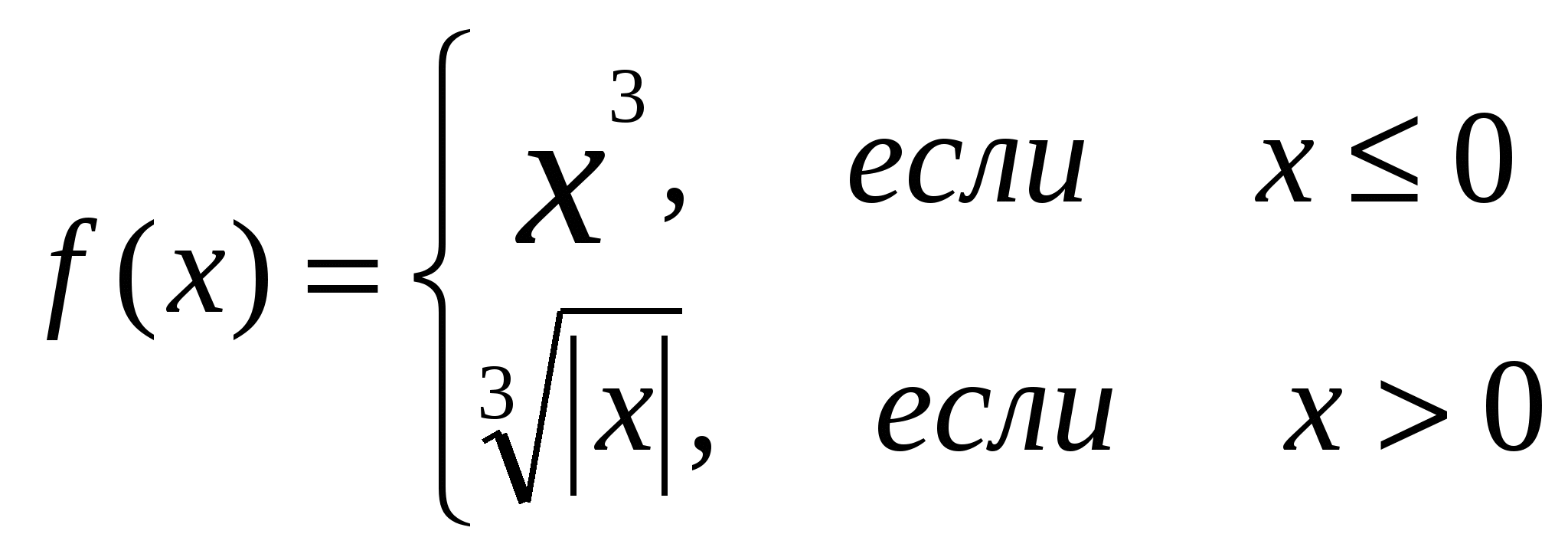 , , Напишем текст программы, сопроводив его соответствующими комментариями. var x,f,a,b,dx:real; n:integer; {счетчик выведенных строк} begin repeat {Цикл ввода с контролем правильности значений: a,dx,b должны быть числами, dx>0, a+dx должно быть меньше b} writeln ('Введите a,dx,b:'); {$I-}read (a,dx,b);{$I+} if IoResult <> 0 then begin writeln ('Вы не ввели 3 числовых ', 'значения, попробуем еще раз'); continue; end; if (dx<=0) or (a+dx>=b) then begin writeln ('Вы не ввели допустимые ', 'данные, попробуем еще раз'); continue; end else break; until false; {Печать заголовка таблицы} writeln; writeln ('x':10,'f(x)':10); x:=a; n:=2; {2 строки уже использованы} while x<=b+1e-6 do begin {в условии цикла учитываем возможную погрешность работы с real!} if x<=0 then f:=sqr(x)*x else f:=exp(1/3*ln(abs(x))); {корень 3 степени взяли через exp и ln} writeln (x:10:2,f:10:2); n:=n+1; if n=24 then begin {На экране консоли по умолчанию 25 строк} write ('Нажмите Enter...'); reset (input); readln; n:=1; end; x:=x+dx; end; writeln ('Таблица выведена'); reset (input); readln; end. Как видно из примера, основной порядок действий -- такой же, как в предыдущей задаче. Так как экран консоли по умолчанию содержит всего 25 строк, с помощью переменной n мы дополнительно контролируем число уже выведенных строк и делаем по заполнении экрана паузу до нажатия пользователем клавиши Enter. Разумеется, другие изученные нами виды циклов также могут применяться при табулировании. Рассмотрим в качестве примера следующую задачу. Известна стоимость единицы товара. Составить таблицу стоимости 1, 2, ..., K единиц товара, значение K вводится. Так как число единиц товара -- заведомо целое, при программировании задачи будет удобен цикл for: var t:real; i,k:integer; begin writeln; writeln ('Стоимость единицы товара:'); read (t); writeln ('Количество единиц товара:'); read (k); writeln ('Единиц':10,'Стоимость':10); for i:=1 to k do writeln (i:10,(i*t):10:2); end. Здесь для простоты мы исключили сделанные в предыдущем примере проверки. Стоимость единицы товара обозначена t, переменная i необходима для перебора возможных значений единиц товара в цикле for. Поскольку счетчик цикла for автоматически меняется с шагом 1, а оператором writeln можно выводить не только значения переменных, но и выражения, основной цикл программы состоит из одного оператора и не нуждается в операторных скобках. 11.2. Алгоритм организации счетчикаЭтот алгоритм применяется, когда требуется подсчитать количество элементов данных, отвечающих какому-либо условию или условиям. В общем виде алгоритм описывается следующим образом:
Необходимость присваивания начальных значений на шаге 2 этого и последующих алгоритмов связана с тем, что после описания в разделе var значение переменной еще не определено. "Пока мы не начали подсчитывать количество, оно равно нулю" -- этот очевидный для человека факт не очевиден для компьютера! Поэтому любой переменной, которая может изменяться в теле цикла, необходимо присвоить до цикла начальное значение, что и делает оператор вида k:=0;. Рассматриваемый нами алгоритм очень часто встречается в самых различных задачах, поэтому для "быстрой" записи операции по увеличению счетчика (она называется инкремент) или его уменьшению (декремент) существуют специальные стандартные процедуры: Inc(X,N); -- увеличивает значение переменной. Здесь параметр X -- переменная порядкового типа, а N -- переменная или выражение целочисленного типа. Значение X увеличивается на 1, если параметр N не определен, или на N, если параметр N определен, то есть Inc(X); соответствует X:=X+1;, а Inc(X,N); соответствует X:=X+N;. Dec(X,N); -- уменьшает значение переменной. Параметр X -- также переменная порядкового типа, N -- целочисленное значение или выражение. Значение X уменьшается на 1, если параметр N не определен, или на N, если параметр N определен, то есть Dec(X); соответствует X:=X-1;, а Dec(X,N); соответствует X:=X-N;. С помощью Inc и Dec генерируется более оптимизированный код, особенно полезный в сложных циклах. Возможно, мы будем использовать их не во всех примерах, но вам советую о них не забывать. В качестве примера реализации алгоритма рассмотрим следующую задачу. Последовательность z(i) задана соотношениями 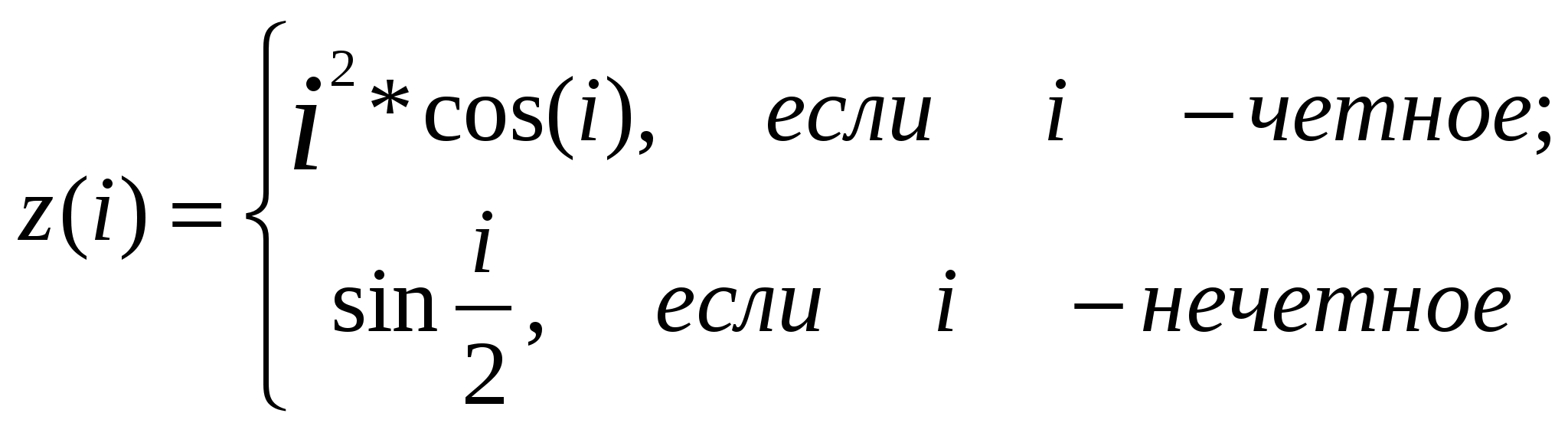 , i=1,2,...,100. Найти количество элементов последовательности, больших значения 0.5. , i=1,2,...,100. Найти количество элементов последовательности, больших значения 0.5.Обозначив искомое количество за k, составим программу: var z:real; i,k:integer; begin k:=0; for i:=1 to 100 do begin if i mod 2 = 0 then z:=sqr(i)*cos(i) else z:=sin(i/2); if z>0.5 then inc(k); end; writeln ('Количество=',k); end. Так как шаг по переменной i равен 1, в программе использован цикл for, для проверки того, является ли значение i четным, использована операция mod. В следующей задаче займемся обработкой данных по мере их ввода пользователем. Известны оценки за экзамен по информатике для группы из n студентов, 2≤n≤25. Оценить количественную и качественную успеваемость группы по формулам: Для ввода текущей оценки используем целочисленную переменную a, в качестве счетчика цикла for введем переменную i ("номер студента"), остальные величины описаны в условии задачи. При вводе значения n и очередного значения a для простоты не будем контролировать корректность вводимых данных. var a,i,n,k1,k2:integer; ykol,ykach:real; begin writeln; writeln ('Введите количество студентов:'); read (n); k1:=0; k2:=0; for i:=1 to n do begin write ('Введите оценку ',i,' студента:'); read (a); if a>2 then begin inc(k1); if a>3 then inc(k2); end; end; ykol:=k1/n*100; ykach:=k2/n*100; writeln ('Количественная успеваемость=',ykol:6:2); writeln ('Качественная успеваемость =',ykach:6:2); reset (input); readln; end. 11.3. Алгоритмы накопления суммы и произведенияДанные алгоритмы применяются, когда требуется сложить или перемножить выбранные данные. В общем виде эти широко применяемые алгоритмы можно описать так:
Очевидно, почему начальное значение произведения -- 1, а не 0. После оператора p:=0; оператор p:=p*t;, расположенный в теле цикла, будет возвращать только нули. Рассмотрим типовую задачу. Для функции 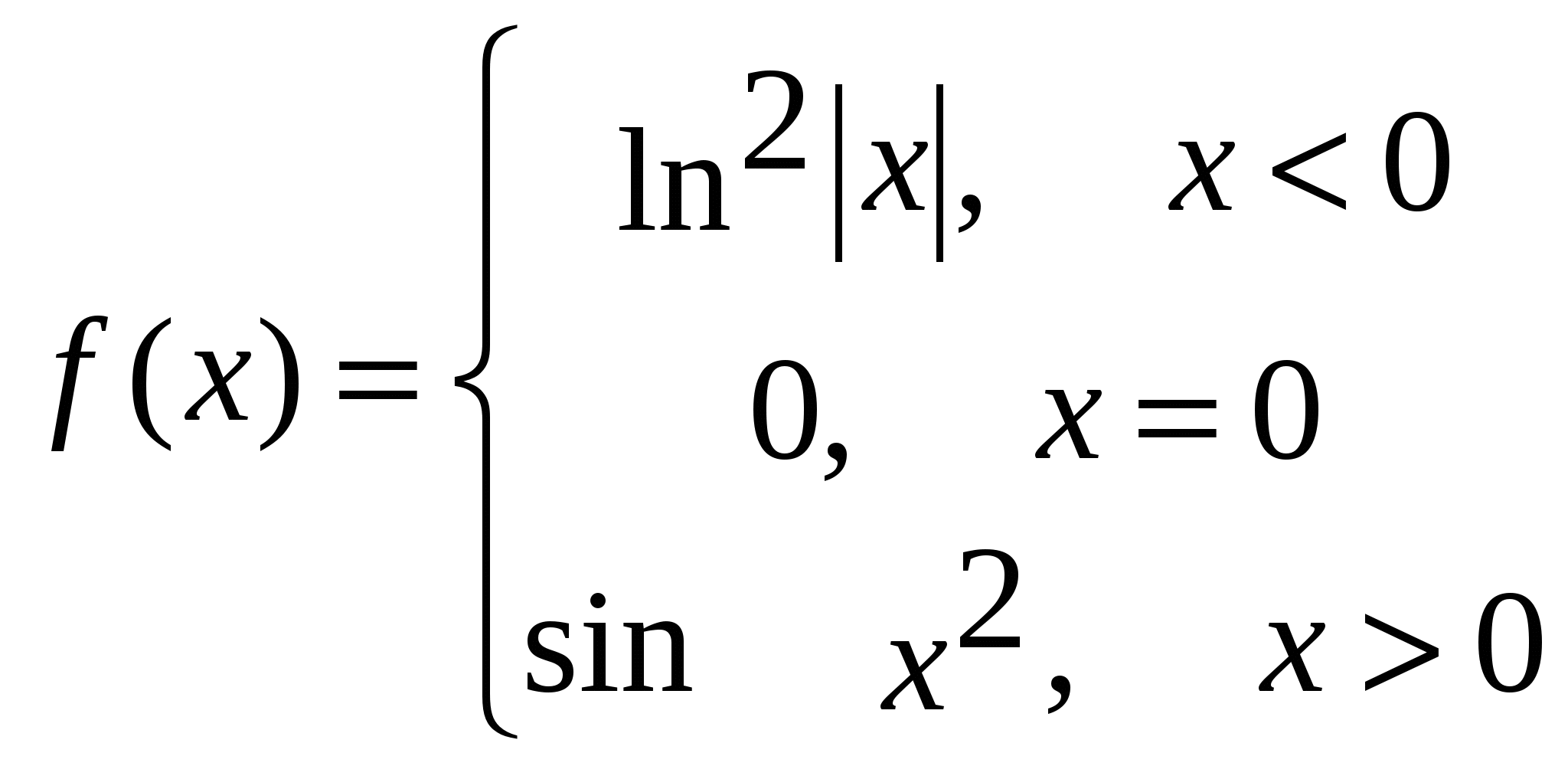 , , Для поиска арифметического среднего необходимо сначала найти сумму s и количество k положительных значений функции. Составим следующую программу: var x,f,s,p:real; k:integer; begin s:=0; k:=0; p:=1; x:=-5; while x<=5+1e-6 do begin if x<0 then f:=sqr(ln(abs(x))) else if x>0 then f:=sin(sqr(x)) else f:=0; if f>0 then begin s:=s+f; k:=k+1; end; if f<>0 then p:=p*f; x:=x+0.5; end; s:=s/k; {теперь в s - искомое среднее} writeln ('Среднее положительных =',s:10:6); writeln ('Произведение ненулевых=',p:10:6); reset (input); readln; end. В следующей задаче также применяется алгоритм накопления суммы. Требуется написать программу, имитирующую работу кассового аппарата: пользователь в цикле вводит цену очередного товара или 0 для завершения ввода, программа суммирует цены. По завершении цикла ввода программа начисляет скидку с общей стоимости товара по правилам: скидки нет, если общая стоимость покупки -- менее 10000 руб.; скидка равна 5%, если общая стоимость -- от 10000 до 20000 руб.; скидка равна 7%, если общая стоимость -- свыше 20000 руб. После начисления скидки выводится окончательная стоимость покупки. Обозначив общую стоимость покупки s, а цену очередного товара -- t, напишем следующую программу: var s,t:real; begin writeln; s:=0; {начальное значение суммы!} repeat writeln ('Введите стоимость товара или ' '0 для завершения ввода:'); {$I-}read(t);{$I+} if (IoResult<>0) or (t<0) then begin writeln ('Ошибка! Повторите ввод'); continue; end; if t=0 then break; {Округляем t до 2 знаков после запятой – на случай, если есть копейки} t:=round (t*100) / 100; s:=s+t; {накопление суммы} until false; {Начисление скидки и вывод ответа} writeln ('Стоимость без скидки:',s:8:2); if s>20000 then s:=s-s*0.07 else if s>10000 then s:=s-s*0.05; writeln ('Стоимость со скидкой:',s:8:2); writeln ('Спасибо за покупку!'); reset (input); readln; end. Тип данных real выбран для s и t не случайно -- выбор integer ограничил бы диапазон обрабатываемых значений и не позволил в удобном виде ввести копейки. Проверки корректности ввода, делаемые программой, знакомы по предыдущим примерам и поэтому не закомментированы. 12. Типовые алгоритмы поиска максимума и минимумаВ этой главе мы изучим простейшие статистические алгоритмы, главный из которых -- определение максимального и минимального значений на множестве данных. Рассмотрим алгоритм в общем виде:
Шаг 2 этого алгоритма требует комментариев, которые мы сделаем на примере поиска максимума. Очевидно, что сам алгоритм несложен -- каждый элемент данных t последовательно сравнивается с ячейкой памяти max и, если обнаружено значение t, большее текущего значения max, оно заносится в max оператором max:=t;. Как мы помним, после описания на шаге 1 переменной max, ее значение еще не определено, и может оказаться любым, откуда следует необходимость задания начального значения. Представим, что после выбора начального значения max, равного нулю, при анализе встретились только отрицательные значения элементов t. В этом случае условие t>max не выполнится ни разу и ответом будет max, равное нулю, что неправильно. Выбор заведомо малого начального значения max (например, значение -1E30, т. е., -1030, вряд ли встретится в любых реальных данных) гарантирует, что условие t>max выполнится хотя бы раз и максимум будет найден. Альтернативный способ -- присвоить переменной max значение отдельно вычисленного первого элемента последовательности данных. В этом случае ответ либо уже найден, если первый элемент и есть максимальный, либо будет найден в цикле. Аналогичные рассуждения помогают понять, почему минимуму следует присваивать в качестве начального значения заведомо большое число. Перейдем к примерам. Для функции y(x)=sin2(x), Обозначив искомые значения min и max соответственно, напишем следующую программу: var x,y,max,min:real; begin x:=-pi/3; max:=-2; min:=2; {эти начальные значения - заведомо малое и большое для синуса} while x<=pi/3+1e-6 do begin y:=sqr(sin(x)); if y>0 then {ищем min только среди положительных!} if y if y>max then max:=y; x:=x+pi/24; end; writeln ('Минимум =',min:8:2); writeln ('Максимум=',max:8:2); reset (input); readln; end. В следующем примере дополнительно сохраним значения аргументов функции, для которых найдены минимум и максимум. Последовательность T(k) задана соотношениями T(k)=max(sin k, cos k), k=1, 2, ... ,31. Найти номера максимального и минимального элементов последовательности. Поиск номеров не избавит нас от необходимости поиска значений. Поэтому, кроме переменных min и max, нам понадобятся две целочисленные переменные для хранения номеров минимального и максимального значений, обозначим их kmin и kmax соответственно. Обратите также внимание, что на каждом шаге цикла дополнительно потребуется находить максимальное из значений sin(k) и cos(k), для занесения его в переменную t. var t,max,min:real; k,kmin,kmax:integer; begin min:=1e30; max:=-1e30; {задаем "надежные" значения, близкие к плюс и минус бесконечности} for k:=1 to 31 do begin if sin(k)>cos(k) then t:=sin(k) else t:=cos(k); if t {по условию нужны 2 оператора – сохранение нового мин. значения и сохранение номера элемента, отсюда операторные скобки!} min:=t; kmin:=k; end; if t>max then begin max:=t; kmax:=k; end; end; writeln ('Номер мин. элемента =',kmin); writeln ('Номер макс. элемента=',kmax); reset (input); readln; end. 13. Решение учебных задач на циклыПрименяя полученные навыки работы с типовыми алгоритмами, рассмотрим несколько учебных задач различных типов. На практике нередко встречаются задачи, для которых число шагов цикла заранее неизвестно и не может быть вычислено. Как правило, в этом случае расчетный цикл работает до выполнения некоторого условия, определяющего достижение требуемого результата. Приведем пример подобной задачи. Задана функция и ее разложение в ряд: Перед нами -- типичная задача на ряды. С ростом величины n слагаемые Реализуем все сказанное в следующей программе: {$N+} {Совместимость с процессором 80287 – для использования double} var x,sn,sn1,xn,nf,eps:double; k,n:longint; znak:integer; begin writeln ('Введите значение x:'); read (x); writeln ('Введите требуемую точность:'); read (eps); sn1:=0; sn:=0; k:=0; n:=0; xn:=1; nf:=1; znak:=1; repeat sn1:=sn; {Текущая сумма стала предыдущей для следующего шага} sn:=sn+znak*xn/nf; {Выполняем шаг цикла} {Меняем переменные для следующего шага:} znak:=-znak; xn:=xn*sqr(x); nf:=nf*(n+1)*(n+2); n:=n+2; k:=k+1; until abs(sn1-sn) writeln ('Значение =',cos(x):20:16); writeln ('Предыдущая сумма=',sn1:20:16); writeln ('Текущая сумма=',sn:20:16); writeln ('Число шагов=',k); reset (input); readln; end. Даже не владея приемами работы с графикой (см. гл. 25), можно наглядно проиллюстрировать результаты своих расчетов. Рассмотрим в качестве примера задачу. Сформировать на экране изображение функции f(x)= cos(x)+ln(x) на интервале [1, 5] с шагом 0.2. Программа с комментариями приводится далее. var x,y,{ Значение аргумента и функции } a,b,{ Интервал } ymin,ymax:real; { Мин. и макс. y } cy, { Позиция столбца на экране } i:integer; begin a:=1; b:=5; { Первый цикл нужен, чтобы определить минимальное и максимальное значения функции на заданном интервале } x:=a; ymin:=1e20; ymax:=1e-20; while x<=b do begin y:=cos(x)+ln(x); if y else if y>ymax then ymax:=y; x:=x+0.2; end; { Во втором цикле обработки можно выводить на экран значения функции } x:=a; while x<=b do begin y:=cos(x)+ln(x); cy:=round(8+(y-ymin)*(70/(ymax-ymin))); { Чтобы пересчитать y из границ [ymin,ymax] в границы [8,78] (столбцы экрана, в которые выводим график), используем формулу cy= 8 + (y-ymin)* (78-8)/(ymax – ymin) } writeln; write (x:7:3,' '); { Выводим очередной x и пробел } for i:=8 to cy do write ('*'); { Рисуем звездочками значение y } x:=x+0.2; { Переходим к следующему x } end; end. В заключительном примере этого пункта проверим, является ли введенное положительное целое число N простым. Простое число делится без остатка только на единицу и само на себя. В цикле последовательно проверим остатки от деления N на числа 2, 3, ... ,N/2. Если найден хотя бы один остаток, равный нулю, число не является простым и дальнейшие проверки бессмысленны. Ясно также, что не имеет смысла проверять, есть ли целые делители, которые больше половины исходного числа, поэтому верхняя граница цикла = N/2 (для деления используем операцию div). Обратите внимание на использование логической переменной-флага s в этой программе. var n,i:longint; s:boolean; begin write ('N='); readln (n); s:=true; for i:=2 to n div 2 do if n mod i = 0 then begin s:=false; break; end; if s=true then writeln ('простое') else writeln ('НЕ простое'); end. 14. Одномерные массивы. Описание, ввод, вывод и обработка массивов на ПаскалеМассивом называют упорядоченный набор однотипных переменных (элементов). Каждый элемент имеет целочисленный порядковый номер, называемый индексом. Число элементов в массиве называют его размерностью. Массивы используются там, где нужно обработать сразу несколько переменных одного типа -- например, оценки всех 20 студентов группы или координаты 10 точек на плоскости. Строку текста можно рассматривать как массив символов, а текст на странице -- как массив строк. Массив описывается в разделе var оператором следующего вида: var ИмяМассива: array [НИ .. ВИ] of Тип; Здесь НИ (нижний индекс) -- целочисленный номер 1-го элемента массива; .. -- оператор диапазона Паскаля (см. п. 7.8); ВИ (верхний индекс) -- целочисленный номер последнего элемента; Тип -- любой из известных типов данных Паскаля. Каждый элемент массива будет рассматриваться как переменная соответствующего типа. Опишем несколько массивов разного назначения. var a: array [1..20] of integer; Здесь мы описали массив с именем A, состоящий из 20 целочисленных элементов; var x,y : array [1..10] of real; Описаны 2 массива с именами x и y, содержащие по 10 вещественных элементов; var t : array [0..9] of string; Массив t состоит из 10 строк, которые занумерованы с нуля. Легко увидеть, что размерность (число элементов) массива вычисляется как ВИ – НИ + 1. Для обращения к отдельному элементу массива используется оператор вида ИмяМассива [Индекс]. Здесь Индекс -- целочисленный номер элемента (может быть целочисленным выражением или константой). Индекс не должен быть меньше значения нижнего или больше верхнего индекса массива, иначе возникнет ошибка "Constant out of range". Отдельный элемент массива можно использовать так же, как переменную соответствующего типа, например: A[1]:=1; x[1]:=1.5; y[1]:=x[1]+1; t[0]:='Hello'; В этой главе мы изучаем одномерные массивы, в которых каждый элемент имеет один номер (индекс), характеризующий его положение в массиве. В математике понятию одномерного массива из n элементов соответствует понятие вектора из n компонент: A = {Ai}, i=1, 2 ,..., n. Как правило, ввод, обработка и вывод массива осуществляются поэлементно, с использованием цикла for. Простейший способ ввода -- ввод массива с клавиатуры: const n = 10; var a: array [1..n] of real; i:integer; begin writeln ('Введите элементы массива'); for i:=1 to n do read (A[i]); Размерность массива определена константой n, элементы вводятся по одному в цикле for -- при запуске этой программы пользователю придется ввести 10 числовых значений. При решении учебных задач вводить массивы "вручную", особенно если их размерность велика, не всегда удобно. Существуют, как минимум, два альтернативных решения. Описание массива констант удобно, если элементы массива не должны изменяться в процессе выполнения программы. Как и другие константы, массивы констант описываются в разделе const. Приведем пример такого описания: const a:array [1..5] of real=( 3.5, 2, -5, 4, 11.7 ); Как видно из примера, элементы массива перечисляются в круглых скобках через запятую, их количество должно соответствовать его размерности. Формирование массива из случайных значений уместно, если при решении задачи массив служит лишь для иллюстрации того или иного алгоритма, а конкретные значения элементов несущественны. Для того чтобы получить очередное случайное значение, используется стандартная функция random(N), где параметром N передается значение порядкового типа. Она вернет случайное число того же типа, что тип аргумента и лежащее в диапазоне от 0 до N-1 включительно. Например, оператор вида a[1]:=random(100); запишет в a[1] случайное число из диапазона [0,99]. Для того чтобы при каждом запуске программы цепочка случайных чисел была новой, перед первым вызовом random следует вызвать стандартную процедуру randomize;, запускающую генератор случайных чисел. Приведем пример заполнения массива из 20 элементов случайными числами, лежащими в диапазоне от -10 до 10: var a:array [1..20] of integer; i:integer; begin randomize; for i:=1 to 20 do begin a[i]:=random(21)-10; write (a[i]:4); end; end. Еще более удобный путь -- чтение элементов массива из текстового или двоичного файла. Об этом рассказывается в гл. 21 и 22. К массивам применимы все типовые алгоритмы, изученные в теме "Циклы". Приведем один пример, в котором вычисляется сумма s положительных элементов массива. var b:array [1..5] of real; s:real; i:integer; begin writeln ('Введите 5 элементов массива'); for i:=1 to 5 do read (b[i]); s:=0; for i:=1 to 5 do if b[i]>0 then s:=s+b[i]; Вывод массива на экран также делается с помощью цикла for. for i:=1 to 5 do write (b[i]:6:2); Здесь 5 элементов массива b напечатаны в одну строку. Для вывода одного элемента на одной строке можно было бы использовать оператор writeln вместо write. Существенно то, что если обработка массива осуществляется последовательно, по 1 элементу, циклы ввода и обработки зачастую можно объединить, как в следующем примере. Найти арифметическое среднее элементов вещественного массива t размерностью 6 и значение его минимального элемента. var b:array [1..6] of real; s, min:real; i:integer; begin s:=0; min:=1e30; writeln ('Ввод B[6]'); for i:=1 to 6 do begin read (b[i]); s:=s+b[i]; if b[i] end; writeln ('min=',min,' s=', s/6); end. Теоретически в этой программе можно было бы обойтись и без массива -- ведь элементы b[i] используются только для накопления суммы и поиска максимума, так что описание массива вполне можно было заменить описанием вещественной переменной b. Однако, в реальных задачах данные, как правило, обрабатываются неоднократно и без массивов обойтись трудно. Приведем пример учебной задачи, где использование массива дает выигрыш за счет уменьшения объема вычислений, выполняемых программой. Задана последовательность Ti = max {sin i, cos i}, i= -5, -4, ..., 5. Найти элемент последовательности, имеющий минимальное отклонение от арифметического среднего положительных элементов. Здесь в первом цикле можно сформировать массив по заданному правилу и найти арифметическое среднее положительных элементов. Во втором цикле, когда среднее известно, можно искать отклонение. Без использования массива нам пришлось бы считать элементы последовательности дважды. var t : array [-5..5] of real; i,k:integer; s, ot : real; begin s:=0; k:=0; for i:=-5 to 5 do begin t[i]:=sin(i); if t[i] if t[i]>0 then begin k:=k+1; s:=s+t[i]; end; end; s:=s/k; ot:=1e30; for i:=-5 to 5 do begin if abs(t[i]-s) end; writeln ('Ot=', ot:8:2); end. Распространена обработка в одной задаче сразу нескольких массивов. Приведем пример. Координаты 10 точек на плоскости заданы массивами x={xi}, y={yi}, i=1, 2, ..., 10. Найти длину ломаной, проходящей через точки (x1, y1), (x2, y2), ..., (x10, y10), а также номер точки, лежащей дальше всего от начала координат. При решении задачи используем формулу для нахождения расстояния между 2 точками на плоскости, заданными координатами (x1,y1) и (x2,y2): Обозначим через r расстояние между текущей точкой и следующей, Len искомую длину ломаной, Dist -- расстояние от текущей точки до начала координат, max -- максимальное из этих расстояний, Num -- искомый номер точки. var x,y : array [1..10] of real; I, num:integer; r, Len, Dist, max : real; begin {найдем max при вводе данных} max:=0; {т.к. расстояние не м.б. <0 } num:=1; {на случай, если все точки (0,0)} writeln ('Введите координаты 10 точек'); for i:=1 to 10 do begin read (x[i], y[i]); Dist:=sqrt (sqr(x[i]) + sqr (y[i])); if dist > max then begin max:=dist; {запомнили новое расстояние} Num:=i; {и номер точки} end; end; writeln ('Номер точки=',num, ' расстояние=',dist:8:2); Len:=0;{длина ломаной - сумма длин сторон} for i:=1 to 9 do begin {у 10-й точки нет следующей!} r:= sqrt (sqr(x[i]-x[i+1])+ sqr(y[i]-y[i+1])); Len:=Len+r; end; writeln ('Длина ломаной=',len:8:2); end. Приведем пример задачи формирования массива по правилу. Задан массив x из 8 элементов. Сформировать массив y по правилу 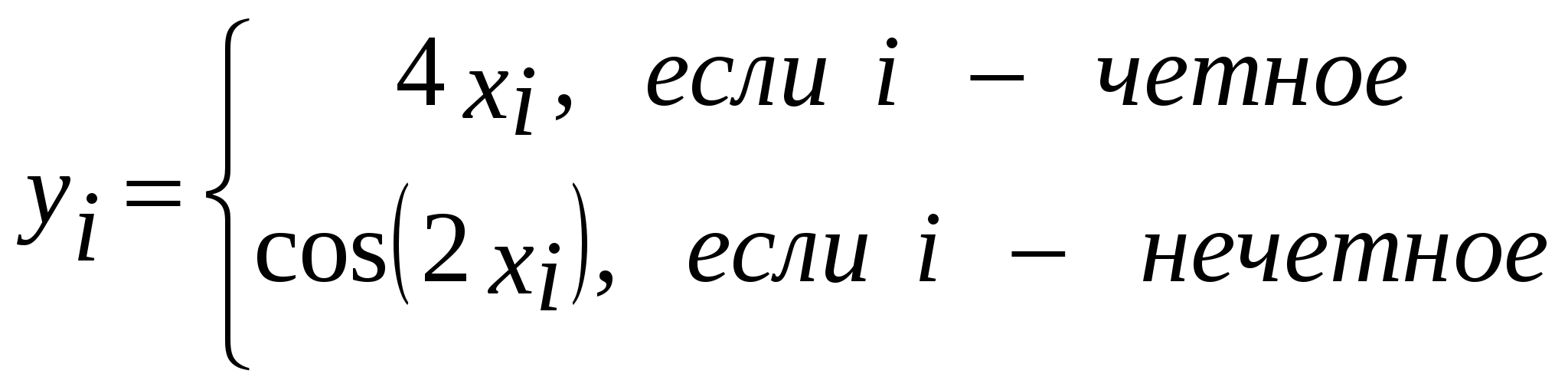 и найти количество его положительных элементов. var x,y: array [1..8] of real; i,k:integer; begin writeln ('Введите массив x из 8 эл.'); for i:=1 to 8 do begin read (x[i]); if i mod 2 =0 then y[i]:=4*x[i] else y[i]:=cos(2*x[i]); end; K:=0; writeln ('Массив y'); for i:=1 to 8 do begin if y[i]>0 then k:=k+1; write (y[i]:8:2); end; writeln; writeln ('K=',k); end. 15. Решение типовых задач на массивыВ гл. 14 мы подчеркивали, что типовые алгоритмы, изученные в теме "Циклы", в полной мере применимы и к массивам. Занимая определенный объем оперативной памяти, однажды полученные элементы массива остаются доступными весь сеанс работы программы и не требуют повторного вычисления или чтения из файла. Это порождает круг приложений, связанных с типовой обработкой наборов данных -- вычисление математических и статистических характеристик векторов, объединение массивов или поиск нужных значений в них и т. д. Другие интересные примеры, такие как подсчет частоты встречаемости элементов в массиве, задача сортировки (упорядочения) данных, будут рассмотрены в гл. 16. 1. Найти сумму, скалярное произведение и длину двух векторов произвольно заданной размерности. Размерность не может превышать значения 100. Предельную размерность массивов зададим константой size=100. Размерность реальных векторов a и b, с которыми работает программа, не обязательно столь велика, обозначим ее n и позаботимся о том, чтоб при вводе значения n соблюдалось соотношение 2≤n≤size. Введем вектор a с клавиатуры, а вектор b сгенерируем из случайных вещественных чисел, принадлежащих диапазону от 0 до 10. Для этого достаточно умножить на 10 значение, возвращаемое стандартной функцией random, если она вызвана без параметров: b[i]:=random*10;. При написании кода мы применим изученный в гл. 8 прием контроля правильности вводимых данных с помощью директивы компилятора и стандартной функции IoResult. Как известно из математики, сумма векторов a и b ищется поэлементно по правилу ci=ai+bi, скалярное произведение может быть вычислено по формуле const size=100; var a,b,c:array [1..size] of real; n,i:integer; la,lb,s:real; begin repeat writeln; write ('Введите размерность A и B, ', 'значение от 2 до ',size,':'); {$I-}readln (n);{$I+} if (IoResult<>0) or (n<2) or (n>size) then writeln ('Неверный ввод, повторите') else break; until false; writeln ('Введите вектор A из ', n,' элементов:'); for i:=1 to n do begin repeat write ('A[',i,']='); {$I-}readln (a[i]);{$I+} if IoResult=0 then break; until false; end; writeln ('Генерируется вектор B из ', n,' элементов:'); randomize; for i:=1 to n do begin b[i]:=random*10; write (b[i]:8:2); end; la:=0; lb:=0; s:=0; writeln; writeln ('Вектор c=A+B:'); for i:=1 to n do begin c[i]:=a[i]+b[i]; write (c[i]:8:2); la:=la+sqr(a[i]); lb:=lb+sqr(b[i]); s:=s+a[i]*b[i]; end; writeln; writeln ('Длина вектора A: ', sqrt(la):8:2); writeln ('Длина вектора B: ', sqrt(lb):8:2); writeln ('Скалярное произведение:',s:8:2); reset (input); readln; end. Думаю, при анализе листинга вы обратили внимание еще на одну особенность программы -- на каждом шаге цикла ввода вектора a дополнительно выполняется цикл repeat...until, предназначенный для контроля правильности ввода элементов массива. Подробнее такие конструкции, называемые кратными циклами, будут изучены в гл. 16. 2. Задана выборка из n случайных чисел. Для n=100 определить математическое ожидание mx и дисперсию dx выборки по формулам: Две подсчитываемые величины -- самые распространенные статистические характеристики набора случайных данных. Фактически, математические ожидание характеризует арифметическое среднее данных выборки, а дисперсия -- среднеквадратичное отклонение данных от среднего значения. Для хранения данных используем массив x из 100 элементов, сами данные сгенерируем из случайных чисел, находящихся в диапазоне от -1 до 1 включительно. Поскольку алгоритм накопления суммы предполагает последовательное и однократное использование каждого элемента массива, в цикле генерации элементов массива могут быть подсчитаны значения const n=100; var x:array [1..100] of real; s,d:real; i:integer; begin writeln; writeln ('Массив x[100]:'); randomize; s:=0; d:=0; for i:=1 to n do begin x[i]:=random*2-1; write (x[i]:8:3); s:=s+x[i]; d:=d+sqr(x[i]); end; s:=s/n; {теперь в s - мат. ожидание,} d:=d/(n-1)-sqr(s)/(n*(n-1)); {а в d - дисперсия} writeln; writeln ('s=',s:8:4); writeln ('D=',d:8:4); reset (input); readln; end. 3. Объединить 2 упорядоченных по возрастанию массива A и B в массив C. Для решения этой задачи тоже достаточно одного прохода по массивам. Действительно, заведя для каждого из массивов a, b и c по собственному счетчику (обозначим их ia, ib и i соответственно), мы можем, в зависимости от истинности или ложности соотношения aia≤bib переписывать в элемент ci значение aia или bib. Остается проконтролировать, чтобы ни один из счетчиков не вышел за границу размерности своего массива. Увидеть детали вам поможет внимательный анализ листинга. Для простоты не будем просить пользователя вводить с клавиатуры две неубывающих последовательности чисел -- ввод заменен генерацией случайных элементов, совмещенной с выводом генерируемых значений. program m_concat; const size=10; step=5; var a,b:array [1..size] of integer; c:array [1..2*size] of integer; i,n1,n2,ia,ib,ic:integer; begin writeln; repeat write('Размерность 1 массива ', '(от 2 до ',size,'):'); read (n1); until (n1>1) and (n1<=size); randomize; a[1]:=random(step); write ('A= ',a[1],' '); for i:=2 to n1 do begin a[i]:=a[i-1]+random(step); write (a[i],' '); end; writeln; repeat write('Размерность 2 массива ', '(от 2 до ',size,'):'); read (n2); until (n2>1) and (n2<=size); b[1]:=random(step); write ('B= ',b[1],' '); for i:=2 to n2 do begin b[i]:=b[i-1]+random(step); write (b[i],' '); end; writeln; ia:=1; ib:=1; write ('c= '); for i:=1 to n1+n2 do begin if a[ia]<=b[ib] then begin c[i]:=a[ia]; if ia else begin a[n1]:=b[ib]; if ib end; end else begin c[i]:=b[ib]; if ib else begin b[n2]:=a[ia]; if ia end; end; write (c[i],' '); end; writeln; end. |