ЛР1 ИИ. Работа защищена с оценкой преподаватель
 Скачать 196.13 Kb. Скачать 196.13 Kb.
|

|
МИНИСТЕРСТВО НАУКИ И ВЫСШЕГО ОБРАЗОВАНИЯ РОССИЙСКОЙ ФЕДЕРАЦИИ Федеральное государственное автономное образовательное учреждение высшего профессионального образования «САНКТ-ПЕТЕРБУРГСКИЙ ГОСУДАРСТВЕННЫЙ УНИВЕРСИТЕТ АЭРОКОСМИЧЕСКОГО ПРИБОРОСТРОЕНИЯ» КАФЕДРА №14 РАБОТА ЗАЩИЩЕНА С ОЦЕНКОЙ ПРЕПОДАВАТЕЛЬ
РАБОТУ ВЫПОЛНИЛИ
Санкт-Петербург 2021 Цель работы Реализовать алгоритм итерации по ценностям действий для среды FrozenLake; Исследовать реализованный алгоритм. Задачи Изучить теоретическую часть работы; Реализовать алгоритм итерации по стратегиям для игры FrozenLake; Исследовать влияние функцию вознаграждения на выучиваемую стратегию поведения агента. Краткие теоретические сведения В данной лабораторной работе требуется реализовать алгоритм итерации по ценностям действий для среды FrozenLake, который относится к алгоритмам машинного обучения с подкреплением, активно развивающимся и широко применяемым в разного рода прикладных задачах. Алгоритмы машинного обучения (МО) с подкреплением отличаются от обучения без учителя тем, что за решение задач в среде агенту назначается награда, эквивалентная тому, насколько хорошо агент решает задачу. Агент – некоторая сущность, которая способна «существовать» в среде, а именно – выполнять какие-то действия в среде, наблюдать за изменениями этой среды и получать вознаграждение за выполнение действий в среде. Среда FrozenLake – среда дискретна, представляет собой доску размерностью 4х4 (16 клеток). Агент в начале игры находится в левой верхней клетке и должен дойти до правой нижней клетки. На поле находятся проруби, в которые агент может провалиться и эпизод заканчивается. За достижение правой нижней клетки агент получает награду, равную 1 и эпизод заканчивается, иначе – 0 и эпизод так же заканчивается. У агента имеется 4 возможных действия – переход влево, вправо, вверх или вниз. Также, из любого положения с равной вероятностью p=0.33 агент может попасть в клетку правее, левее или выше, т.к. покрытие озера «скользкое» и агент может «поскользнуться». В среде FrozenLake применяется Марковский процесс принятия решения – результат зависит только от текущего положения и последующих действий агента, но никак не от предыдущих состояний. Коэффициент гамма вводится для того, чтобы уменьшить вклад сильно отсроченных вознаграждений, коэффициент дельта вводится для того, чтобы регулировать степень обученности агента – на каждой итерации алгоритма, при обновлении таблицы, если все ее значения изменились меньше, чем на дельта, мы считаем, что агент обучен достаточно. Выполнение работы Для выполнения работы будем использовать пакет gym, реализующий среду FrozenLake, в которой агент будет существовать, выполнять действия и получать награды, также пакет tensorboardX для формирования графиков, позволяющих оценить процесс обучения при разных входных данных. Листинг Листинг 1 – реализация алгоритма итерации по ценностям действий import gym import collections from tensorboardX import SummaryWriter ENV_NAME = "FrozenLake-v0" DELTA = 0.001 GAMMA = 0.99 TEST_EPISODES = 20 class Agent: def __init__(self): self.env = gym.make(ENV_NAME) self.state = self.env.reset() self.reward_table = collections.defaultdict(float) self.transition_table = collections.defaultdict(collections.Counter) self.Q = collections.defaultdict(float) self.q_prev = collections.defaultdict(float) def play_n_random_steps(self, count): for _ in range(count): action = self.env.action_space.sample() new_state, reward, is_done, _ = self.env.step(action) self.reward_table[(self.state, action, new_state)] = reward self.transition_table[(self.state, action)][new_state] += 1 self.state = self.env.reset() if is_done else new_state def select_action(self, state): best_action, best_value = None, None for action in range(self.env.action_space.n): action_value = self.Q[(state, action)] if best_value is None or best_value < action_value: best_value = action_value best_action = action return best_action def play_episode(self, env, do_rendering=False): total_reward = 0.0 state = env.reset() while True: action = self.select_action(state) new_state, reward, is_done, _ = env.step(action) if do_rendering: env.render() self.reward_table[(state, action, new_state)] = reward self.transition_table[(state, action)][new_state] += 1 total_reward += reward if is_done: break state = new_state return total_reward def Q_iteration(self): self.q_prev = self.Q.copy() for state in range(self.env.observation_space.n): for action in range(self.env.action_space.n): action_value = 0.0 target_counts = self.transition_table[(state, action)] total = sum(target_counts.values()) for tgt_state, count in target_counts.items(): reward = self.reward_table[(state, action, tgt_state)] best_action = self.select_action(tgt_state) action_value += (count / total) * \ (reward + GAMMA * self.Q[(tgt_state, best_action)]) self.Q[(state, action)] = action_value if __name__ == '__main__': test_env = gym.make(ENV_NAME) agent = Agent() writer = SummaryWriter(comment="-q-iteration") iter_no = 0 best_reward = 0.0 is_done = False while not is_done: iter_no += 1 agent.play_n_random_steps(100) agent.Q_iteration() reward = 0.0 for _ in range(TEST_EPISODES): reward += agent.play_episode(test_env) reward /= TEST_EPISODES writer.add_scalar("reward", reward, iter_no) if reward > best_reward: print("Best reward updated {} -> {}".format(best_reward, reward)) best_reward = reward if iter_no > 15: for state, action in agent.Q: if abs(agent.Q[(state, action)] - agent.q_prev[(state, action)]) < DELTA: is_done = True else: is_done = False break if is_done: print("Solved in %d iterations!" % iter_no) break writer.close() env = gym.make(ENV_NAME) agent.play_episode(env, True) Результаты работы Эксперимент для gamma = 0.99, delta = 0.001 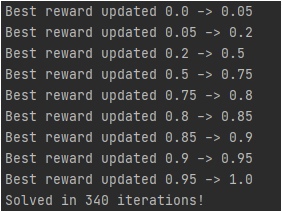 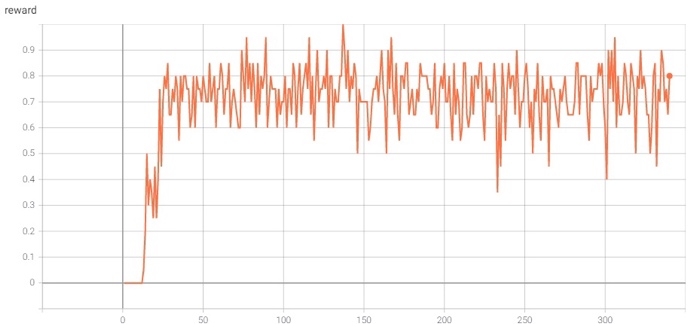 Рисунки 1-2 – динамика изменения наград в зависимости от количества совершенных итераций. Эксперимент для gamma = 0.7, delta = 0.001 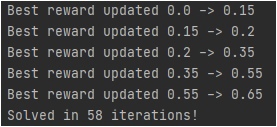 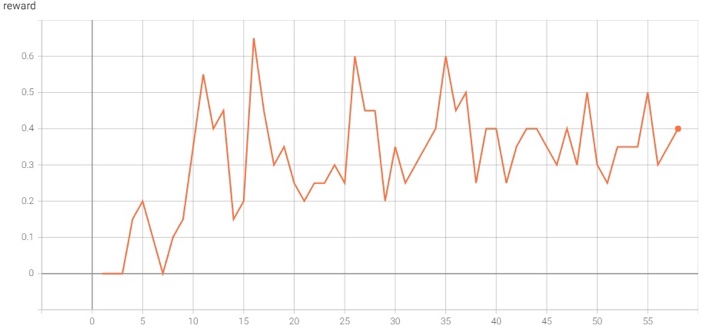 Рисунки 3-4 - динамика изменения наград в зависимости от количества совершенных итераций. Выводы Исходя из результатов проделанных экспериментов с разными гамма, можно сделать вывод, что чем большее значение принимает гамма, тем медленнее обучается агент, т.к. чем выше гамма, тем больший вклад отсроченных наград имеет место быть. |