КУРСОВАЯ РАБОТА По дисциплине: «Теория автоматов и формальных языков». курсовая. Разработка компилятора модельного языка
 Скачать 1.03 Mb. Скачать 1.03 Mb.
|

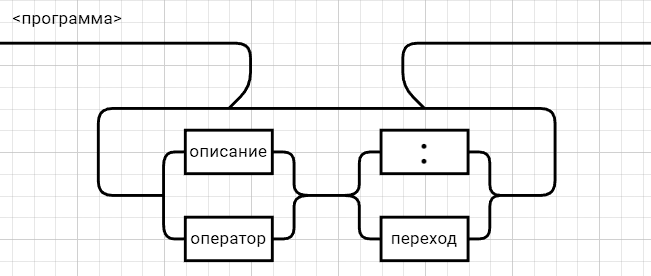
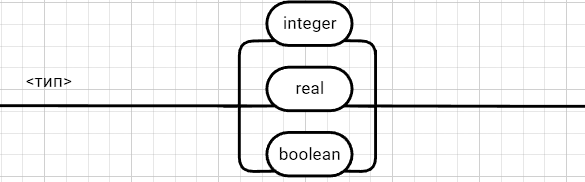
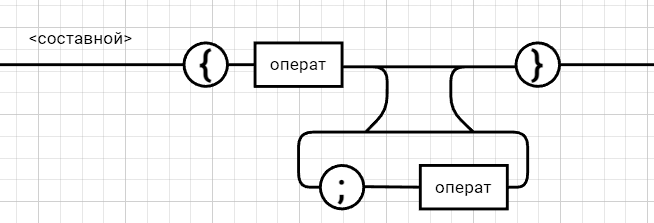
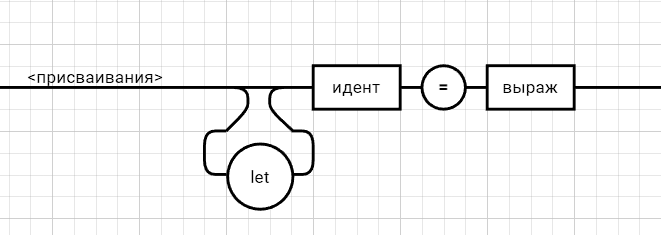
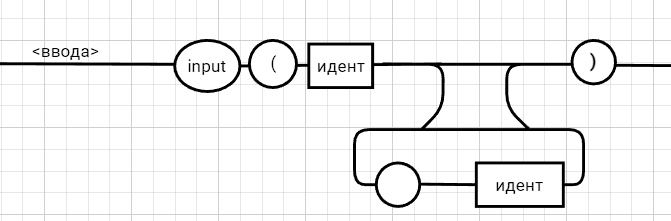
Рецензия СодержаниеВведение 4 1.Постановка задачи 5 2.Формальная модель задачи 7 2.1. Формальные грамматики 7 2.2. Формы Бэкуса-Наура 8 2.3. Расширенные формы Бэкуса-Наура 8 2.4. Диаграммы Вирта 10 Синтаксис группы операций 11 Синтаксис группы операций 11 Номер 12 Синтаксис группы операций 12 (в порядке следования: умножение, деление, конъюнкция) 12 Номер 12 Синтаксис операции 12 3. Спецификация основных процедур и функций 22 3.1. Лексический анализатор 22 3.2. Диаграмма состояний с действиями 27 3.3. Синтаксический анализатор 29 3.4. Семантический анализ 30 4. Работа с программным средством 31 4.1. Укрупненная схема алгоритма программного средства 31 4.2. Детальная разработка алгоритмов отдельных подзадач 32 4.2.1. Блок-схема лексического анализатора 32 4.2.2. Блок-схема синтаксического анализатора 34 4.2.3. Блок-схема семантического анализатора 36 Заключение 37 Список использованных источников 38 ВведениеКомпилятор – это программа, которая создаётся для перевода программы, написанной на высокоуровневом языке программирования в машинный код, который в последствие будет исполняться процессором компьютера. В большинстве случаев компиляция программы происходит полностью. Компилятор целиком считывает программу, проводит её пошаговый анализ (лексический, синтаксический, семантический), оптимизирует её, очищая от излишних конструкций, но сохраняя исходный смысл операций, и также целиком переводит её в машинный код. Цель курсовой работы: - закрепление теоретических знаний в области теории формальных языков, грамматик, автоматов и методов трансляции; - формирование практических умений и навыков разработки собственного компилятора модельного языка программирования; - закрепление практических навыков самостоятельного решения инженерных задач, развитие творческих способностей студентов и умений пользоваться технической, нормативной и справочной литературой. В настоящее время в мире появляются более новые языки программирования и не каждый из ныне существующих трансляторов могут прочитать программы, написанный на новом языке, и перевести его в другой язык. Поэтому сейчас разрабатываются новые трансляторы, в этом и заключается актуальность данной курсовой работы. Постановка задачиРазработать компилятор модельного языка, выполнив следующие действия. 1) В соответствии с номером варианта составить формальное описание модельного языка программирования с помощью: а) РБНФ; б) диаграмм Вирта; в) формальных грамматик. 2) Написать пять содержательных примеров программ, раскрывающих особенности конструкций учебного языка программирования, отразив в этих примерах все его функциональные возможности. 3) Составить таблицы лексем и диаграмму состояний с действиями для распознавания и формирования лексем языка. 4) По диаграмме с действиями написать функцию сканирования текста входной программы на модельном языке. 5) Разработать программное средство, реализующее лексический анализ текста программы на входном языке. 6) Реализовать синтаксический анализатор текста программы на модельном языке методом рекурсивного спуска. 7) Построить цепочку вывода и дерево разбора простейшей программы на модельном языке из начального символа грамматики. 8) Дополнить синтаксический анализатор процедурами проверки семантической правильности программы на модельном языке в соответствии с контекстными условиями вашего варианта. 9) Распечатать пример таблиц идентификаторов и двуместных операций. 10) Показать динамику изменения содержимого стека при семантическом анализе программы на примере одного синтаксически правильного выражения. 11) Составить набор контрольных примеров, демонстрирующих: а) все возможные типы лексических, синтаксических и семантических ошибок в программах на модельном языке; б) представить ход интерпретации синтаксически и семантически правильной программы с помощью таблицы. Формальная модель задачиСуществуют три основных метода описания синтаксиса языков программирования: формальные грамматики, формы Бэкуса-Наура и диаграммы Вирта. 2.1. Формальные грамматики Определение. Формальной грамматикой называется четверка вида: 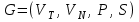 , (1.1) , (1.1)где VN- конечное множество нетерминальных символов грамматики (обычно прописные латинские буквы); VT - множество терминальных символов грамматики (обычно строчные латинские буквы, цифры, и т.п.),VT VN =; Р – множество правил вывода грамматики, являющееся конечным подмножеством множества (VTVN)+ (VTVN)*; элемент (, ) множества Р - называется правилом вывода и записывается в виде (читается: «из цепочки выводится цепочка »); S – начальный символ грамматики, S VN. Для записи правил вывода с одинаковыми левыми частями вида 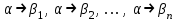 используется сокращенная форма записи используется сокращенная форма записи  . .Пример: P -> begin D2 B end D2->var D1 D1 -> D | D1; D D -> I1:int|I1:float|I1:bool I1 -> I | I1, I S1 -> S | S1; S S -> begin S1 end | if (E) S else S | while (E) S | for Z to R1 step R1 S next | readln I | writeln E Z -> I := R1 | I := W | I := L W -> R1.R1 | R1.R1e+R1 | R1.R1e-R1 R1 -> RR1 | R E -> E1 | E1 eq E1 | E1 ne E1 | E1 lt E1 | E1 le E1 | E1 gt E1 | E1 ge E1 E1 -> T | T plus E1 | T min E1 | T or E1 T -> F | F mult T | F div T | F and T F -> I | N | L | F | (E) L -> true | false I -> C | IC | IR N -> R | NR C -> A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | U | V | W | X | Y | Z | a | b | c | d | e | f | g | h | i | j | k | l | m | n | o | p | q | r | s | t | u | v | w | x | y | z R -> 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 2.2. Формы Бэкуса-НаураМетаязык, предложенный Бэкусом и Науром, использует следующие обозначения: - символ «::=» отделяет левую часть правила от правой (читается: «определяется как»); - нетерминалы обозначаются произвольной символьной строкой, заключенной в угловые скобки «<» и «>»; - терминалы — это символы, используемые в описываемом языке; - правило может определять порождение нескольких альтернативных цепочек, отделяемых друг от друга символом вертикальной черты «|» (читается: «или»). 2.3. Расширенные формы Бэкуса-Наура Для повышения удобства и компактности описаний, в РБНФ вводятся следующие дополнительные конструкции (метасимволы): - квадратные скобки «[» и «]» означают, что заключенная в них синтаксическая конструкция может отсутствовать; - фигурные скобки «{» и «}» означают повторение заключенной в них синтаксической конструкции ноль или более раз; - сочетание фигурных скобок и косой черты «{/» и «/}» используется для обозначения повторения один и более раз; - круглые скобки «(» и «)» используются для ограничения альтернативных конструкций. Вариант: 331233 <операции_группы_отношения>:: = NE | EQ | LT | LE | GT | GE <операции_группы_сложения>:: = plus | min | or <операции_группы_умножения>:: = mult | div | and <унарная_операция>::= <выражение>::= <операнд>{<операции_группы_отношения> <операнд>} <операнд>::= <слагаемое> {<операции_группы_сложения> <слагаемое>} <слагаемое>::= <множитель> {<операции_группы_умножения> <множитель>} <множитель>::= <идентификатор> | <число> | <логическая_константа> | <унарная_операция> <множитель> | (<выражение>) <число>::= <целое> | <действительное> <логическая_константа>::= true | false <идентификатор>::= <буква> {<буква> | <цифра>} <буква>::= A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | U | V | W | X | Y | Z | a | b | c | d | e | f | g | h | i | j | k | l | m | n | o | p | q | r | s | t | u | v | w | x | y | z <цифра>::= 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 <целое>::= <двоичное> | <восьмеричное> | <десятичное> | <шестнадцатеричное> <двоичное>::= {/ 0 | 1 /} (B | b) <восьмеричное>::= {/ 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 /} (O | o) <десятичное>::= {/ <цифра> /} [D | d] <шестнадцатеричное>::= <цифра> {<цифра> | A | B | C | D | E | F | a | b | c | d | e | f} (H | h) <действительное>::= <числовая_строка> <порядок> | [<числовая_строка>] . <числовая_строка> [порядок] <числовая_строка>::= {/ <цифра> /} <порядок>::= ( E | e )[+ | -] <числовая_строка> <программа>::={/ (<описание> | <оператор>) ( : | переход строки) /} end <описание>::= {<идентификатор> {, <идентификатор> } : <тип> ;} <тип>::= integer | real | boolean <оператор>::= <составной> | <присваивания> | <условный> | <фиксированного_цикла> | <условного_цикла> | <ввода> | <вывода> <составной>::= «{» <оператор> { ; <оператор> } «}» <присваивания> ::= [ let ] <идентификатор> = <выражение> <условный>::= if <выражение> then <оператор> [else <оператор>] endelse <фиксированного_цикла>::= for «(» [<выражение>] ; [<выражение>] ; [<выражение>] «)» <оператор> <условного_цикла>::= dowhile <выражение> <оператор> loop <ввода>::= input«(»<идентификатор> {пробел <идентификатор>}«)» <вывода>::= output «(»<выражение> { пробел <выражение> }«)»
2.4. Диаграммы ВиртаВ метаязыке диаграмм Вирта используются графические примитивы. При построении диаграмм учитывают следующие правила: - каждый графический элемент, соответствующий терминалу или нетерминалу, имеет по одному входу и выходу, которые обычно изображаются на противоположных сторонах; - каждому правилу соответствует своя графическая диаграмма, на которой терминалы и нетерминалы соединяются посредством дуг; - альтернативы в правилах задаются ветвлением дуг, а итерации - их слиянием; - должна быть одна входная дуга (располагается обычно слева или сверху), задающая начало правила и помеченная именем определяемого нетерминала, и одна выходная, задающая его конец (обычно располагается справа и снизу); - стрелки на дугах диаграмм обычно не ставятся, а направления связей отслеживаются движением от начальной дуги в соответствии с плавными изгибами промежуточных дуг и ветвлений.

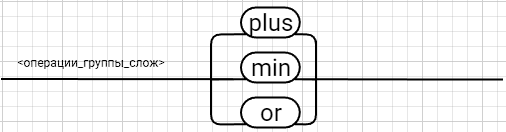
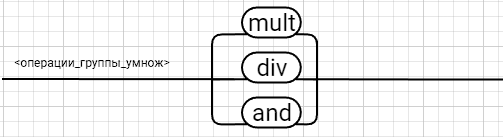
 <выражение>::= <операнд>{<операции_группы_отношения><операнд>} 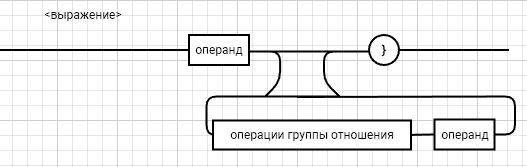 <операнд>::= <слагаемое> {<операции_группы_сложения><слагаемое>} 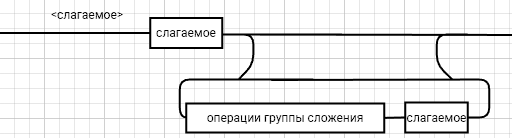 <слагаемое>::= <множитель> {<операции_группы_умножения><множитель>}  <множитель>::= <идентификатор> | <число>|<логическая_константа>| <унарная_операция><множитель> | (<выражение>)  <число>::= <целое> | <действительное> 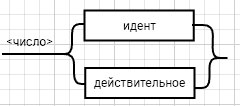 <логическая_константа>::= true | false 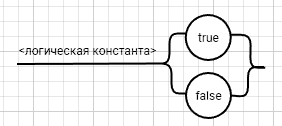 <идентификатор>::= <буква> {<буква> | <цифра>}  <буква>::= A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | U | V | W | X | Y | Z | a | b | c | d | e | f | g | h | i | j | k | l | m | n | o | p| q | r | s | t | u | v | w | x | y | z 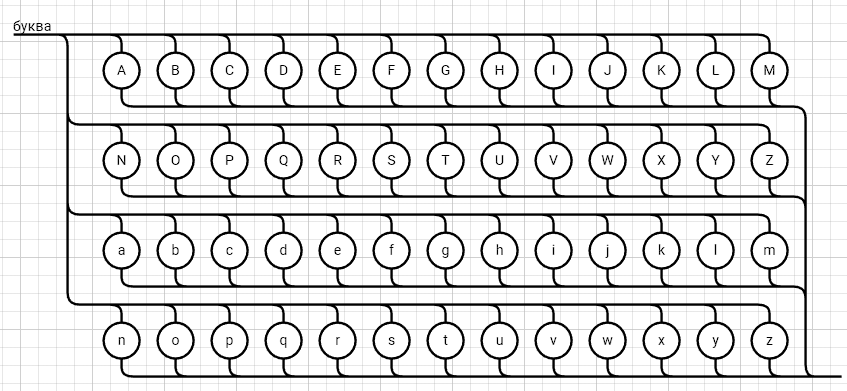 <цифра>::= 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9  <целое>::= <двоичное> | <восьмеричное> | <десятичное> | <шестнадцатеричное>  <двоичное>::= {/ 0 | 1 /} (B | b) 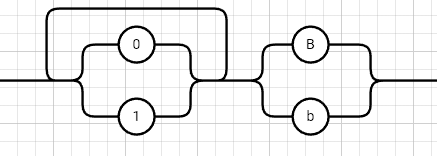 <восьмеричное>::= {/ 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 /} (O | o) 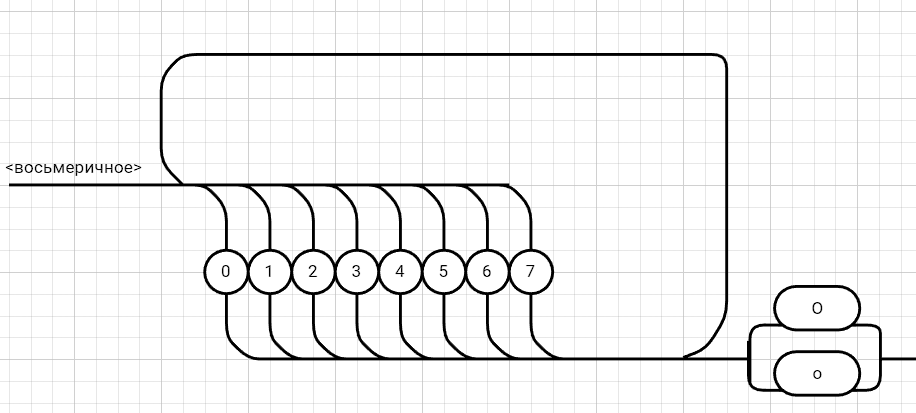 <десятичное>::= {/ <цифра> /} [D | d] 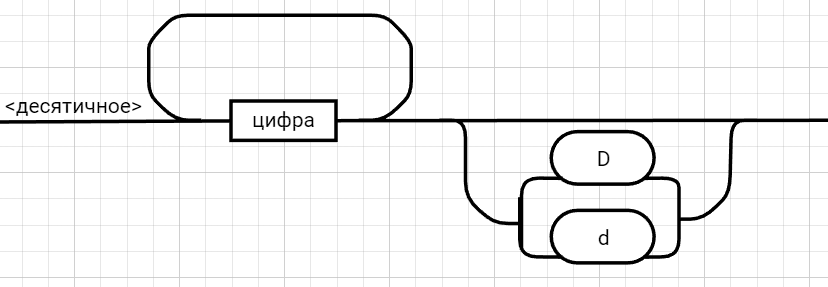 <шестнадцатеричное>::= <цифра> {<цифра> | A | B | C | D | E | F | a | b | c | d | e | f} (H | h)  <действительное>::= <числовая_строка><порядок> | [<числовая_строка>] . <числовая_строка> [порядок]  <числовая_строка>::= {/ <цифра> /} 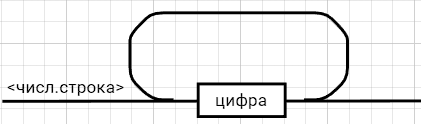 <порядок>::= ( E | e )[+ | -] <числовая_строка> 





 3. Спецификация основных процедур и функций3.1. Лексический анализаторЛексический анализатор (ЛА) – это первый этап процесса компиляции, на котором символы, составляющие исходную программу, группируются в отдельные минимальные единицы текста, несущие смысловую нагрузку – лексемы. Задача лексического анализа - выделить лексемы и преобразовать их к виду, удобному для последующей обработки. Каждая лексема представляет собой пару чисел вида (n, k), где n – номер таблицы лексем, k - номер лексемы в таблице. Входные данные ЛА - текст транслируемой программы на входном языке. Выходные данные ЛА - таблица лексем в числовом представлении. Структура данных, выбранная для хранения таблиц – является List <>, т.е. таблицы: ключевых слов, разделителей, идентификаторов, чисел – хранятся в виде списков. Списки – представляют собой удивительно гибкий инструмент по работе с коллекциями. Одной из главных особенностей списков является возможность использовать любой тип данных. В списках удобно хранить и управлять данными, т. к. списки позволяют манипулировать указателями. Следовательно, т.к. есть возможность манипулировать указателями – скорость работы с данными списков очень высока, а значит разрабатываемый компилятор модельного языка М, будет работать очень быстро Таблица № 0 – таблица ключевых слов:
Таблица № 1 – таблица разделителей:
Таблицы идентификаторов (3) и чисел (2) формируются в ходе лексического анализа. Алгоритм ЛА: Считываем символ введенной программы: Если это буква – считываем буквы и цифры, пока не встретим разделитель или ключевое слово. Если цепочка символов введенной программы, совпадает с одним из ключевым словом, то записываем результат в таблицу лексем (0, k). Если цепочка символов введенной программы, совпадает с одним из разделителей, то записываем результат в таблицу лексем (1, k). Если это не ключевое слово и не разделитель, то является идентификатором. Считываем после идентификатора его разделитель. Записываем идентификатор и его разделитель, через двоеточие, в таблицу идентификаторов, и записываем лексему идентификатора с разделителем (1, k); Если это цифра – считываем пока не встретим разделитель. Проверяем числа на правильность. Если число введено верно, то переводим числа в двоичное представление. Записываем число и его бинарное представление в таблицу чисел, и записываем лексему числа (2, k) Если это символ – считываем пока не найдем совпадение с таблицей разделителей. Если это разделитель, то записываем лексему разделителя в таблицу лексем (1, k) Если это неизвестный символ, то выдаем ошибку. Опишем результаты работы лексического анализатора для модельного языка М. Входные данные ЛА: k, n, i, sum: integer: { input(n): let sum EQ 0: let i EQ 1: do while i LE n { input(k): let sum EQ sum plus k: let k EQ k plus 1: loop: } output(sum div n): } Выходные данные ЛА: [(3:0),(1:14),(3:1),(1:14),(3:2),(1:14),(3:3),(1:16),(0:11),(1:16),(1:18), (0:9),(1:20),(3:1),(1:21),(1:16),(0:14),(3:3),(1:2),(2:0),(1:16),(0:14),(3:2),(1:2),(2:1), (1:16),(0:6),(0:7),(3:2),(1:4),(3:1),(1:18),(0:9),(1:20),(3:0),(1:21),(1:16),(0:14),(3:3), (1:2),(3:3),(1:7),(3:0),(1:16),(0:14),(3:0),(1:2),(3:0),(1:7),(2:1),(1:16),(0:8),(1:16), (1:19), (0:10),(1:20),(3:3),(1:11),(3:1),(1:21),(1:16), (1:19),(0:4)] Составим ЛА для модельного языка. Предварительно введем следующие обозначения для переменных, процедур и функций. Переменные: 1) СН – очередной входной символ; 2) S – буфер для накапливания символов лексемы; 3) B – переменная для формирования числового значения константы; 4) CS – текущее состояние буфера накопления лексем с возможными значениями: H – начало, I – идентификатор, N – число, С – комментарий, SK – считывание скобки, R – ограничитель, V – выход программы, ER – ошибка. 5) t - таблица лексем анализируемой программы с возможными значениями: TW – таблица ключевых слов М-языка, TR – таблица разделителей М-языка, TI – таблица идентификаторов программы, TN – таблица целых чисел; 6) z - номер лексемы в таблице t (если лексемы в таблице нет, то z=0). Процедуры и функции: 1) gc – процедура считывания очередного символа текста в переменную СН; 2) let – логическая функция, проверяющая, является ли переменная СН буквой; 3) digit - логическая функция, проверяющая, является ли переменная СН цифрой; 4) nill – процедура очистки буфера S; 5) add – процедура добавления очередного символа в конец буфера S; 6) look(t) – процедура поиска лексемы из буфера S в таблице t с возвращением номера лексемы в таблице; 7) put(t) – процедура записи лексемы из буфера S в таблицу t, если там не было этой лексемы, возвращает номер данной лексемы в таблице; 8) out(n, k) – процедура записи пары чисел (n, k) в файл лексем. Построим ДС с действиями для распознавания и формирования внутреннего представления лексем модельного языка М. 3.2. Диаграмма состояний с действиями  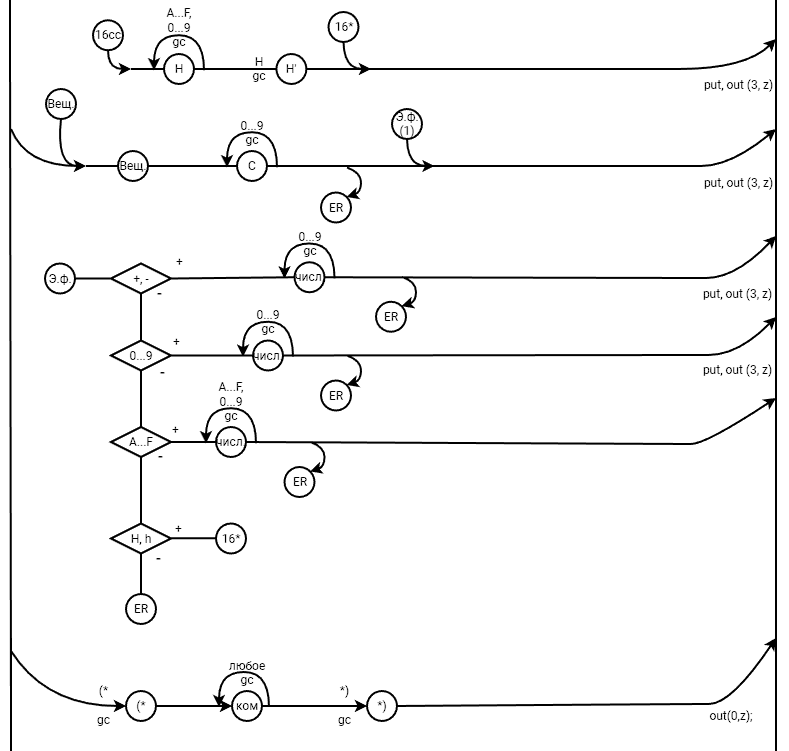 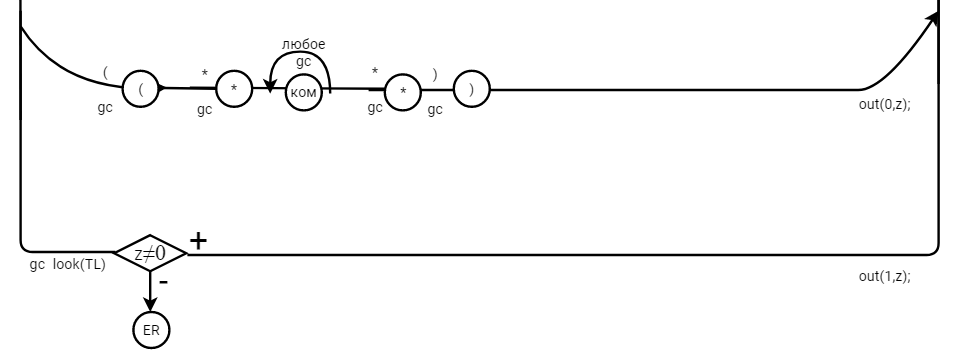 3.3. Синтаксический анализатор Задача синтаксического анализатора: провести разбор текста программы, сопоставив его с эталоном, данным в описании языка. Для синтаксического разбора используются контекстно-свободные грамматики (КС-грамматика). Один из эффективных методов синтаксического анализа – метод рекурсивного спуска. В основе метода рекурсивного спуска лежит левосторонний разбор строки языка. Исходной сентенциальной формой является начальный символ грамматики, а целевой – заданная строка языка. На каждом шаге разбора правило грамматики применяется к самому левому нетерминалу сентенции. Данный процесс соответствует построению дерева разбора цепочки сверху вниз (от корня к листьям). В курсовой работе применяется такая проверка открытия и закрытия программы, как: Код в программе начинается с описания или оператора ; Считывается описание или оператор; Считав ключевое слово “end”,объявляется конец программы; Если ключевое слово “end”не обнаружено, выводится ошибка. В качестве примера рассмотрен оператор условного цикла: 1. Считывание ключевого слова do; 2. Проверяется наличие ключевого слово “while” если нет - выдаётся ошибка; 3. Считывается выражение, если не выражение – выдаётся ошибка; 3. Считывается оператор, если не оператор – выдаётся ошибка; 4. Конец выражения определяется ключевым словом “loop” при отсутствии выдаётся ошибка; 3.4. Семантический анализ В ходе семантического анализа проверяются отдельные правила записи исходных программ, которые не описываются КС-грамматикой. Эти правила носят контекстно-зависимый характер, их называют семантическими соглашениями или контекстными условиями. Соблюдение контекстных условий для языка М предполагает три типа проверок: 1) обработка описаний; 2) анализ выражений; 3) проверка правильности операторов. Вход: файл лексем в числовом представлении. Выход: заключение о семантической правильности программы или о типе обнаруженной семантической ошибки. Задача обработки описаний – проверить, все ли переменные программы описаны правильно и только один раз. Задача анализа выражений – проверить описаны ли переменные, встречающиеся в выражениях, и соответствуют ли типы операндов друг другу и типу операции. Задачи проверки правильности операторов: 1) выяснить, все ли переменные, встречающиеся в операторах, описаны; 2) установить соответствие типов в операторе присваивания слева и справа от символа «:=»; Задача решается проверкой типов в соответствующих местах программы. Если при анализе цепочек лексем возникает ошибка или встретилась неизвестная лексема или лексема, не принадлежащая анализируемому оператору, то вызывается исключение с текстом ошибки. 4. Работа с программным средством 4.1. Укрупненная схема алгоритма программного средства 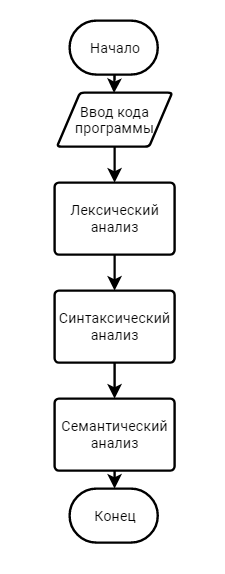 Рис. 1. Блок-схема алгоритма программного средства 4.2. Детальная разработка алгоритмов отдельных подзадач 4.2.1. Блок-схема лексического анализатора 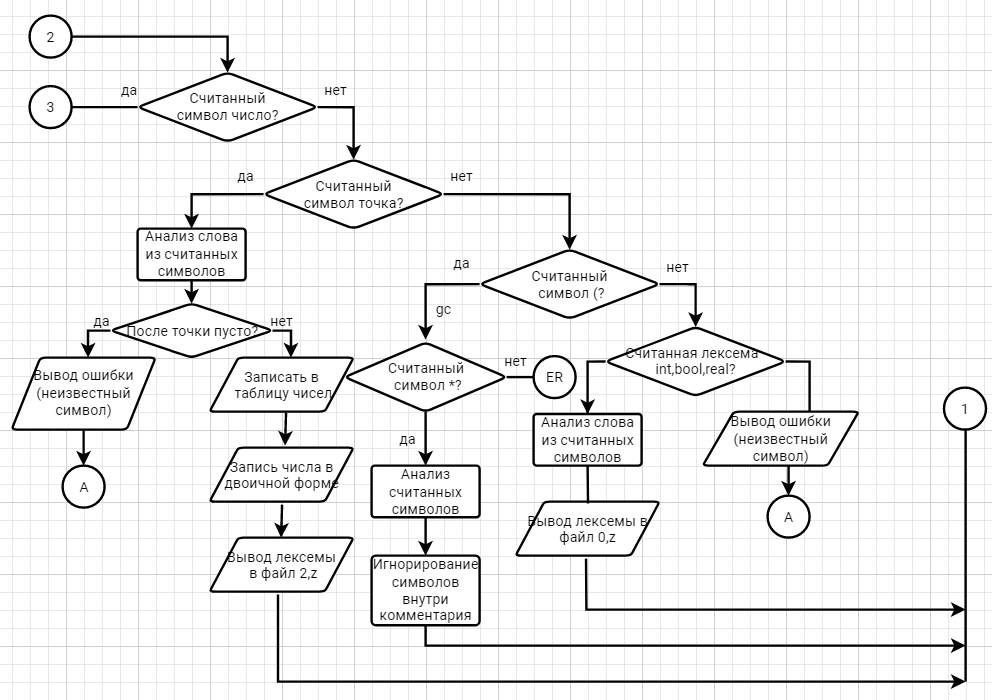 Рис.2. Блок-схема лексического анализатора 4.2.2. Блок-схема синтаксического анализатора 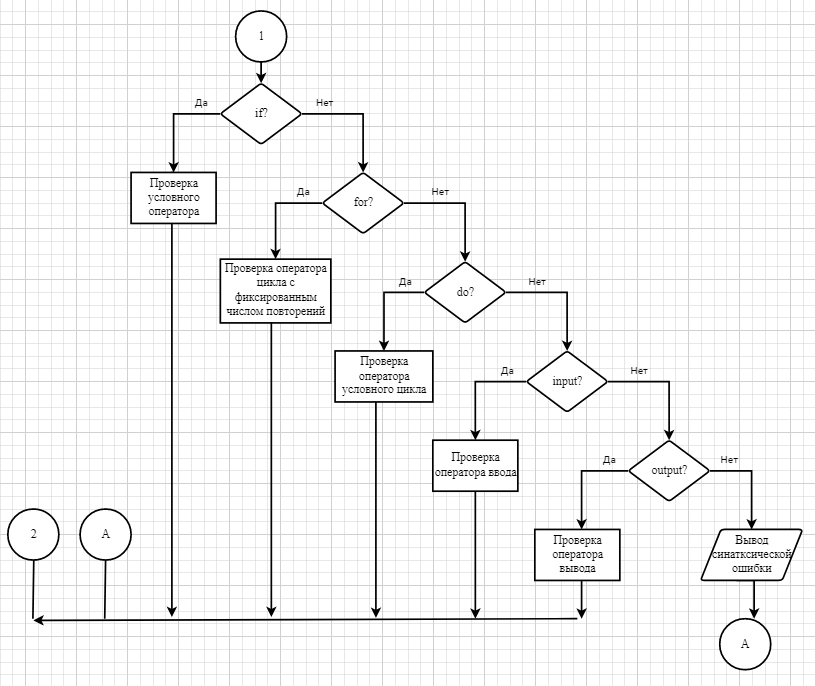 Рис.3. Блок-схема синтаксического анализатора 4.2.3. Блок-схема семантического анализатора Рис.4. Блок-схема семантического анализатора | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||