реляционная модель данных распечатать. Реляционная модель данных
 Скачать 58.54 Kb. Скачать 58.54 Kb.
|

|
МИНИСТЕРСТВО ОБРАЗОВАНИЯ И НАУКИ ЧЕЧЕНСКОЙ РЕСПУБЛИКИ Государственное бюджетное профессиональное образовательное учреждение «Гудермесский железнодорожный техникум» 09.02.05 Прикладная информатика (по отраслям) КУРСОВАЯ ПРОЕКТ ПО ДИСЦИПЛИНЕ: «База данных и знаний». НА ТЕМУ: «Реляционная модель данных»_______________________________ Выполнил(а): студент(ка) гр. 3П-17 __Хожбатиров Ислам Алиханович___ Руководитель: преподаватель спец. Дисциплин Измаилов Дауд Султанович Допущен(а) к защите: «___»______________ 20___ г. Подпись __________ Защищена с оценкой __________ «___»____________ 20___ г. Подпись ________ г.Гудермес 2020 СОДЕРЖАНИЕ Введение……………………………………………………………………………..…3 1. Модель данных……………………………………………………………………....5 1.1. Типы моделей данных……………………………………………………….....5 2. Базовые понятия реляционной модели данных………………………………….12 2.1. Атрибуты базы данных……………………………………………….…...…..12 2.2. Общие представления о модели данных………………………………...…..22 Заключение…………………………………………………………………………….26 Список используемой литературы……………………………………………….......27 Введение Человечество стремительно вступает в принципиально новую для него информационную эпоху. Существенным образом меняются все слагаемые образа жизни людей. В современном обществе уровень информатизации характеризует уровень развития государства. ХХI век специалисты называют веком компьютерных технологий. Их революционное воздействие касается государственных структур и институтов гражданского общества, экономической и социальной сфер, науки и образования, культуры и образа жизни людей. Многие развитые и развивающиеся страны в полной мере осознали те колоссальные преимущества, которые несет с собой развитие и распространение информационно-коммуникационных технологий. Не у кого не вызывает сомнения тот факт, что движение к информационному обществу - это путь в будущее человеческой цивилизации. В соответствии с реляционной моделью база данных представляется в виде совокупности таблиц, над которыми могут выполняться операции, формулируемые в терминах реляционной алгебры и реляционного исчисления. В реляционной модели операции над объектами базы данных имеют теоретико-множественный характер. Основы реляционной модели данных были впервые изложены в статье Е.Кодда в 1970 г. Эта работа послужила стимулом для большого количества статей и книг, в которых реляционная модель получила дальнейшее развитие[6]. Именно поэтому реляционную модель данных часто называют моделью Кодда. Ядром любой базы данных является модель данных. Модель данных представляет собой множество структур данных, ограничений целостности и операций манипулирования данными. С помощью модели данных могут быть представлены объекты предметной области и взаимосвязи между ними. Цель данной работы рассмотреть базовые понятия реляционной модели данных, атрибуты реляционной модели базы данных. Модель данных 1.1. Типы моделей данных Модель данных – совокупность структур данных и операций их обработки. Модели данных определяются: - способами организации данных; - ограничением ценности данных; - операциями с данными. СУБД основывается на использовании иерархической, сетевой или реляционной модели, на комбинации этих моделей или на некотором их подмножестве[10]. Рассмотрим 3 основных типа моделей данных: иерархическую, сетевую и реляционную. Иерархическая модель данных а) Иерархическая структура представляет совокупность элементов, связанных между собой по определённым правилам. Объекты, связанные иерархическими отношениями, образуют ориентированный граф (перевёрнутое дерево), вид которого представлен на рисунке 1.  А Уровень 1 А Уровень 1 В1 В2 В3 В4 В5 Уровень 2 С1 С2 С3 С4 С5 С6 С7 С8 Уровень 3 Рис. 1 К основным понятиям иерархической структуры относятся: уровень, элемент (узел), связь. Узел – это совокупность атрибутов данных, описывающих некоторый объект. На схеме иерархического дерева узлы представляются вершинами графа. Каждый узел на более низком уровне связан только с одним узлом, находящимся на более высоком уровне. Иерархическое дерево имеет только одну вершину (корень дерева), не подчинённую никакой другой вершине и находящуюся на самом верхнем (первом) уровне. Зависимые (подчинённые) узлы находятся на втором, третьем и т.д. уровнях. Количество деревьев в базах данных определяется числом корневых записей. К каждойдятся на втором, третьемершине и находящуюся на самом верхнем первом) уровне. ровне. Записи базы данных существует только иерархический путь от корневой записи. Например, как видно на рисунке 1 для записи С4 путь проходит через записи А и В3[5]. Пример, представленный на рисунке 2 иллюстрирует использование иерархической модели базы данных. Для рассматриваемого примера иерархическая структура правомерна, т.к. каждый студент учится в определённой (только одной) группе, которая относится к определённому (только одному) институту. b) Ограничение целостности- целостность ссылок между предком и потомком с учетом основного правила: никакой потомок не может существовать без предка. Примеры: 1) ОКА 3)TOTAL 2)ИНЭС 4) IMS с) Операции над данными: - найти указанное дерево; - перейти от одного дерева к другому; - перейти от одной записи к другой; - перейти от одной записи к другой в порядке обхода иерархии; - удаление текущей записи[11]. Институт (специальность, название, ректор) 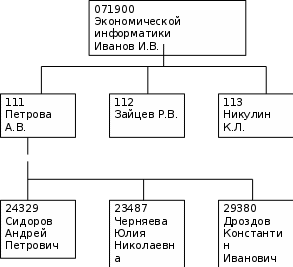 Группа (номер, староста) Студент (номер зачётной книжки, фамилия, имя, отчество) Рис. 2. Пример иерархической структуры бах данных Сетевые модели данных. а) В сетевых моделях данных при тех же основных понятиях (уровень, узел, связь) каждый элемент может быть связан с любым другим элементом. 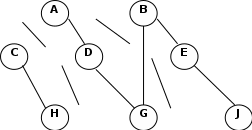 Рис. 3 Сетевая структура базы данных в виде графа С 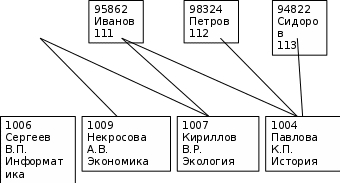 тудент (номер зачётной книжки, фамилия, группа) тудент (номер зачётной книжки, фамилия, группа)Работа (шифр, руководитель, область) Рис. 4. Примером сложной сетевой структуры может служить структура базы данных, содержащей сведения о студентах, участвующих в научно – исследовательских работах (НИР). Возможно участие одного студента в нескольких НИР, а также участие нескольких студентов в разработке одной НИР[4]. Графическое изображение описанной в примере сетевой структуры, состоящей только из двух типов записей, показано на рисунке 4. Единственное отношение представляет собой сложную связь между записями в обоих направлениях. с) Операции над данными сетевой модели данных: - найти конкретную запись в наборе однотипных записей; - перейти от узла высшего уровня к первому узлу низшего по некоторой связи; - перейти к следующему узлу по некоторой связи; - создать новую запись; - уничтожить запись; - модифицировать запись; - включить 1 связь; - исключить из связи; - переставить в другую связь. Особенность сетевой модели данных: возможность осуществления навигации по связям данных, т.е. переход от просмотра реквизитов экземпляра одного типа записи к просмотру реквизитов экземпляра, связанного типом записи. Пользователю предоставляется возможность многокритериального анализа базы данных без непосредственной формализации своих информационных потребностей через формирование запросов на языке, встроенном в СУБД. Другая сильная сторона сетевой модели данных – использование множественных типов данных для описания атрибутов информации объектов. Это позволяет создавать информационные структуры, которые представляют собой табличную форму данных.Не смотря на развитие сетевой модели данных, не получилось создать языковых программных средств на их основе, которые позволили бы в прикладных информационных системах одинаково описывать данные сетевой организации. 2. Базовые понятия реляционной модели данных 2.1. Атрибуты базы данных Понятие реляционной (англ. relation – отношение) связано с разработками известного американского специалиста в области систем баз данных Е. Кодда[6]. Реляционная модель данных представляет информацию в виде совокупности связанных таблиц, которые называются отношениями или реляциями. Тип данных – эквивалентно понятию типа данных в алгоритмических языках. Существуют: - целочисленные типы; - вещественные типы; - строковые типы; - типы данных для денежных величин; - типы данных для временных величин; - типы двоичных объектов (не имеет аналогов в языках программирования, и обозначаются Blob)[12]. Наименьшая единица данных реляционной модели — это отдельное атомарное (неразложимое) для данной модели значение данных. Доменом называется множество атомарных значений одного и того же типа. Иными словами, домен представляет собой допустимое потенциальное множество значений данного типа. Понятие домена более специфично для баз данных, хотя и имеет некоторые аналогии с диапазонными типами и множествами, имеющимися в ряде языков программирования. В самом общем виде домен определяется заданием некоторого базового типа данных, к которому относятся элементы домена, и произвольного логического выражения, применяемого к элементу типа данных. Если вычисление этого логического выражения дает результат «истина», то элемент данных является элементом домена[4]. Следует отметить также семантическую нагрузку понятия домена: данные считаются сравнимыми только в том случае, когда они относятся к одному домену. Если же значения двух атрибутов берутся из различных доменов, то их сравнение, вероятно, лишено смысла. Понятие домена используется далеко не во всех СУБД. В качестве примера реляционных баз данных, использующих домены, можно привести Огасle и InterBase[13]. Атрибуты, схема отношения, схема базы данных Столбцы отношения называют атрибутами, им присваиваются имена, по которым к ним затем производится обращение. Список имен атрибутов отношения с указанием имен доменов (или типов, если домены не поддерживаются) называется схемой отношения. Степень отношения — это число его атрибутов. Отношение степени один называют унарным, степени два — бинарным, степени три — тернарным,..., а степени п — n-арным. Схемой базы данных называется множество именованных схем отношений[18]. Кортеж Кортеж, соответствующий данной схеме отношения, представляет собой множество пар {имя атрибута, значение}, которое содержит одно вхождение каждого имени атрибута, принадлежащего схеме отношения. «Значение» является допустимым значением домена данного атрибута (или типа данных, если понятие домена не поддерживается). Тем самым степень кортежа, то есть число элементов в нем, совпадает со степенью соответствующей схемы отношения. Иными словами, кортеж — это набор именованных значений заданного типа. Схему отношения иногда называют также заголовком отношения, а отношение как набор кортежей — телом отношения. Понятие схемы отношения напоминает понятие структурного типа данных в языках про граммирования (структура в С/С++, запись в Pascal). Однако в реляционных базах данных имя схемы отношения всегда совпадает с именем соответствующего отношения-экземпляра. В классических реляционных базах данных после определения схемы базы Данных изменяются только отношения-экземпляры. В них могут появляться новые и удаляться или модифицироваться существующие кортежи. Однако во многих реализациях допускается и изменение схемы базы данных: определение новых и изменение существующих схем отношения. Это принято называть эволюцией схемы базы данных. Ключи отношения Поскольку отношение с математической точки зрения является множеством, а множества по определению не содержат совпадающих элементов, то никакие два кортежа отношения не могут быть дубликатами друг друга в любой произвольно заданный момент времени. Таким образом, в отношении всегда должен присутствовать некоторый атрибут (или набор атрибутов), однозначно определяющий каждый кортеж отношения и обеспечивающий уникальность строк таблицы. Такой атрибут (или набор атрибутов) называется первичным ключом отношения[3]. Для каждого отношения свойством уникальности обладает, по крайней мере, полный набор его атрибутов. Однако требуется обеспечить и условие минимальности. Поэтому, как правило, в отношении всегда имеется один атрибут, обладающий свойством уникальности и являющийся первичным ключом. В зависимости от количества атрибутов, входящих в ключ, различают простые и сложные (или составные) ключи. Простой ключ — ключ, содержащий только один атрибут. В общем случае операции объединения выполняются быстрее в том случае, когда в качестве ключаис пользуется самый короткий и самый простой из возможных типов данных. С этой точки зрения наилучшим образом подходит целочисленный тип, который имеет аппаратную поддержку для выполнения над ним логических операций. Сложный или составной ключ — ключ, состоящий из нескольких атрибутов. Набор атрибутов, обладающий свойством уникальности, но не обладающий минимальностью, называется суперключом. Суперключ — сложный (составной) ключ с большим числом столбцов, чем необходимо для того, чтобы быть уникальным идентификатором. Такие ключи нередко используются на практике, так как избыточность может оказаться полезной пользователю[14]. В зависимости от того, содержит ли атрибут, являющийся первичным ключом, какую-либо информацию, различают искусственные и естественные ключи. Искусственный или суррогатный ключ — ключ, созданный самой СУБД или пользователем с помощью некоторой процедуры, который сам по себе не содержит ин формации. Искусственный ключ используется для создания уникальных идентификаторов строк, когда сущность должна быть описана полностью, чтобы однозначно идентифицировать конкретный элемент. Искусственный ключ часто используют вместо значимого сложного ключа, который является слишком громоздким, чтобы использоваться в реальной базе данных. Система поддерживает искусственный ключ, но он никогда не показывается пользователю. Естественный ключ — ключ, в который включены значимые атрибуты и который, таким образом, содержит информацию[2]. Каждый из типов первичных ключей имеет свои преимущества и недостатки; их обсуждению посвящено большое количество публикаций. Мы не будем проводить подробное их сравнение, а отметим лишь основные плюсы и минусы каждого из видов ключей. Основными достоинствами естественных ключей является то, что они несут вполне определенную информацию и их использование не приводит к необходимости добавлять в таблицы атрибуты, значения которых не имеют никакого смысла и используются лишь для связи между отношениями. Иными словами, использование естественных ключей позволяет получить более компактную форму таблиц (в которых не будет избыточных, неинформативных данных) и более естественные связи между ними. Основным же недостатком естественных ключей является то, что их использование весьма затруднительно в случае изменчивости предметной области. Следует пони мать, что значения атрибутов первичного ключа не должны изменяться. То есть однажды заданное значение первичного ключа для кортежа не может быть позже изменено. Такое требование ставится в основном для поддержания целостности базы данных. Связь между отношениями обычно устанавливается именно по первичному ключу, и его изменение приведет к нарушению этих связей или к необходимости изменения записей в нескольких таблицах. Даже в сравнительно простых базах данных это может вызвать ряд трудноразрешимых проблем. В некоторых реляционных СУБД допускается изменение первичного ключа. Иногда это бывает действительно полезно. Однако прибегать к этому следует лишь в случае крайней необходимости. Типичным примером изменчивой предметной области, в которой для сущности невозможно определить неизменный естественный ключ, является любая область, где в качестве сущности выступает человек. Действительно, невозможно определить для человека набор атрибутов, которые были бы уникальны и неизменны на протяжении всей его жизни. Второй, довольно существенный недостаток естественных ключей состоит в том, что, как правило, уникальные естественные ключи являются составными и содержат строковые атрибуты. Как уже отмечалось выше, максимальная скорость выполнения операций над данными обеспечивается при использовании простых целочисленных ключей. Таким образом, с точки зрения быстродействия системы естественные ключи часто оказываются неоптимальными[17]. Оба недостатка естественных ключей можно преодолеть, определив в отношениях суррогатные ключи, представляющие собой некоторый универсальный атрибут, как правило, целочисленного типа, который не зависит ни от предметной области, ни, тем более, от структуры отношения, которое он идентифицирует. Таким образом, можно обеспечить уникальность и неизменность ключа (раз он никаким образом не зависит от предметной области, то никогда не возникнет необходимость изменять его). Однако за это приходится платить избыточностью данных в таблицах. Следует заметить, что во многих практических реализациях реляционных СУБД до пускается нарушение свойства уникальности кортежей для промежуточных отношений, порождаемых неявно при выполнении запросов. Такие отношения являются не множествами, а мультимножествами, что в ряде случаев позволяет добиться определенных преимуществ, но иногда приводит к серьезным проблемам. В любой из таблиц может оказаться несколько наборов атрибутов, которые можно выбрать в качестве ключа. Такие наборы называются потенциальными или альтернативными ключами. Нередко в отношениях определяются так называемые вторичные ключи. Вторичный ключ представляет собой комбинацию атрибутов, отличную от комбинации, составляющей первичный ключ[1]. Причем вторичные ключи не обязательно обладают свойством уникальности. При их определении могут задаваться следующие ограничения: UNIQUE — ограничение уникальности, значения вторичных ключей при дан ном ограничении не могут дублироваться; NOT NULL — при данном ограничении ни один из атрибутов, входящих в со став вторичного ключа, не может принимать значение NULL. Перекрывающиеся ключи — сложные ключи, которые имеют один или несколько общих столбцов. Связанные отношения В реляционной модели данные представляются в виде совокупности взаимосвязанных таблиц. Подобное взаимоотношение между таблицами называется связью (rilationship). Таким образом, еще одним важным понятием реляционной модели является связь между отношениями. При рассмотрении связанных таблиц важное значение имеет понятие внешнего ключа. Рассмотрим его более подробно. Внешние ключи отношения В базах данных одни и те же имена атрибутов часто используются в разных отношениях. Внешний ключ — это атрибут (или множество атрибутов) одного отношения, являющийся ключом другого (или того же самого) отношения. Внешние ключи используются для установления логических связей между отношениями. Связь между двумя таблицами устанавливается путем присваивания значений внешнего ключа одной таблицы значениям ключа другой[2]. Так же как и любые другие ключи, внешние ключи могут быть простыми либо составными. Часто связь между отношениями устанавливается по первичному ключу, то есть значениям внешнего ключа одного отношения присваиваются значения первичного ключа другого отношения. Однако это не является обязательным — в общем случае связь может устанавливаться также и с помощью вторичных ключей. Кроме того, при установлении связей между таблицами необязательно требование уникальности ключа, по которому устанавливается связь. Атрибуты внешнего ключа не обязательно должны иметь те же имена, что и атрибуты ключа, которым они соответствуют. Внешний ключ может ссылаться и на ту же таблицу, к которой он принадлежит. В этом случае внешний ключ называется рекурсивным[14]. Условия целостности данных Чтобы информация, хранящаяся в базе данных, была однозначной и непротиворе чивой, в реляционной модели устанавливаются некоторые ограничительные усло вия. Ограничительные условия — это правила, определяющие возможные значе ния данных. Они обеспечивают логическую основу для поддержания корректных значений данных в базе. Ограничения целостности позволяют свести к минимуму ошибки, возникающие при обновлении и обработке данных. Важнейшими ограничениями целостности данных являются: категорийная целостность; ссылочная целостность[15]. Ограничение категорийной целостности заключается в следующем. Кортежи отношения представляют в базе данных элементы определенных объектов реального мира или, в соответствии с терминологией реляционных СУБД, категорий. Первичный ключ таблицы однозначно определяет каждый кортеж и, следовательно, каждый элемент категории. Таким образом, для извлечения данных, содержащихся в строке таблицы, или для манипулирования этими данными необходимо знать значение ключа для этой строки. Поэтому строка не может быть занесена в базу данных до тех пор, пока не будут определены все атрибуты ее первичного ключа. Это правило называется правилом категорийной целостности и кратко формулируется следующим образом: никакой атрибут первичного ключа строки не может быть пустым. Второе условие накладывает на внешние ключи ограничения для обеспечения целостности данных, называемой ссылочной целостностью. Если две таблицы связаны между собой, то внешний ключ таблицы должен содержать только те значения, которые уже имеются среди значений ключа, по которому осуществляется связь. Если корректность значений внешних ключей не контролируется СУБД, то может нарушиться ссылочная целостность данных.Ограничения категорийной и ссылочной целостности должны поддерживаться СУБД. Для соблюдения целостности сущности достаточно гарантировать отсут ствие в любом отношении кортежей с одним и тем же значением первичного ключа. Что же касается ссылочной целостности, то здесь обеспечение целостности выглядит несколько сложнее. При обновлении ссылающегося отношения (при вставке новых кортежей или модификации значения внешнего ключа в существующих кортежах) достаточно следить за тем, чтобы не появлялись некорректные значения внешнего ключа. А вот при удалении кортежа из отношения, на которое ведет ссылка, возможно использовать один из трех подходов, каждый из которых поддерживает целостность по ссылкам: первый подход заключается в том, что запрещается производить удаление кортежа, на который существуют ссылки (то есть сначала нужно либо удалитьссы лающиеся кортежи, либо соответствующим образом изменить значения их внешнего ключа); при втором подходе при удалении кортежа, на который имеются ссылки, во всех ссылающихся кортежах значение внешнего ключа автоматически становится неопределенным; третий подход (называемый также каскадным удалением) состоит в том, что при удалении кортежа из отношения, на которое ведет ссылка, из ссылающегося отношения автоматически удаляются все ссылающиеся кортежи[18]. В развитых реляционных СУБД обычно можно выбрать способ поддержания ссылочной целостности для каждой отдельной ситуации определения внешнего ключа. Конечно, для принятия такого решения необходимо анализировать требования конкретной прикладной области. Хотя большинство современных СУБД обеспечивает ссылочную целостность данных, все же следует помнить, что существуют реляционные СУБД, в которых не выполняются ограничения ссылочной целостности[7]. Типы связей между таблицами При установлении связи между двумя таблицами одна из них будет являться глав ной (master), а вторая — подчиненной (detail). Различие между ними несколько упрощенно можно пояснить следующим образом. В главной таблице всегда доступны все содержащиеся в ней записи. В подчиненной же таблице доступны только те записи, у которых значение атрибутов внешнего ключа совпадает со значением соответствующих атрибутов текущей записи главной таблицы. Причем изменение текущей записи главной таблицы приведет к изменению множества доступных записей подчиненной таблицы, а изменение текущей записи в подчиненной таблице не вы зовет никаких изменений ни в одной из таблиц. На практике часто связывают более двух таблиц. Одна и та же таблица может быть главной по отношению к одной таблице и подчиненной по отношению к другой. Или у одной главной таблицы может находиться в подчинении не одна, а несколько таблиц. Однако подчиненная таблица не может управляться двумя таблицами. Таким образом, у главной таблицы может быть несколько подчиненных, но у подчиненной таблицы может быть только одна главная. Различают четыре типа связей между таблицами реляционной базы данных: один к одному — каждой записи одной таблицы соответствует только одна запись другой таблицы; один ко многим — одной записи главной таблицы могут соответствовать несколько записей подчиненной таблицы; многие к одному — нескольким записям главной таблицы может соответствовать одна и та же запись подчиненной таблицы; многие ко многим — одна запись главной таблицы связана с несколькими записями подчиненной таблицы, а одна запись подчиненной таблицы связана с не сколькими записями главной таблицы[8]. Различие между типами связей «один ко многим» и «многие к одному» зависит от того, какая из таблиц выбирается в качестве главной, а какая в качестве подчиненной[16]. Основные свойства отношений Рассмотрим теперь некоторые важнейшие свойства отношений реляционной мо дели данных. 2.2. Общие представления о модели данных Можно по-разному характеризовать понятие модели данных. С одной стороны, модель данных – это способ структурирования данных, которые рассматриваются как некоторая абстракция в отрыве от предметной области. С другой стороны, модель данных – это инструмент представления концептуальной модели предметной области и динамики ее изменения в виде базы данных. Учитывая обе вышеуказанные стороны, определим основные структуры моделей данных, используемые для представления концептуальной модели предметной области (сущностей, атрибутов, связей)[18]. Элемент данных (поле) – наименьшая поименованная единица данных. Используется для представления значения атрибута. Запись – поименованная совокупность полей. Используется для представления совокупности атрибутов сущности (записи о сущности). Экземпляр записи – запись с конкретными значениями полей. Агрегат данных – поименованная совокупность элементов данных внутри записи, которую можно рассматривать как единое целое. Файл – поименованная совокупность экземпляров записей одного типа. Используется для представления однородного набора сущностей. Набор файлов – поименованная совокупность файлов, обрабатываемых в системе. Используется для представления нескольких наборов сущностей. Введем понятие «группа», обобщающее понятия «агрегат» и «запись». Группа – это поименованная совокупность элементов данных или элементов данных и других групп. Важнейшим понятием концептуальной модели является понятие связи между сущностями (наборами сущностей). В моделях данных соответствующее понятие отражается понятием «групповое отношение»[18]. Групповое отношение – поименованное бинарное отношение, заданное на двух множествах экземпляров рассматриваемых групп. По характеру бинарных связей различают групповые отношения вида 1:1, 1:M, M:1, M:N. Пары чисел называют коэффициентами группового отношения. В групповом отношении один член группы назначается владельцем отношения, другой – членом. База данных – поименованная совокупность экземпляров групп и групповых отношений. Для представления группового отношения используется две формы: а) Графовая. Группы изображаются вершинами графа, связи между группами – дугами, направленными от группы-владельца к группе-члену с указанием имени отношения и коэффициента. По типу графов различают: 1. иерархическую модель (граф без циклов – дерево); 2. сетевую модель (ориентированный граф общего вида). б) Табличная. Связь между группами изображается таблицей, столбцы которой представляют ключи соответствующих групп. Для формального описания таблицы используется математическое (теоретико-множественное) понятие отношения. Соответствующая модель данных называется реляционной моделью. Модель данных описывается следующим образом: Определяются типы и характеристики логических структур данных (полей, записей, файлов); Описываются правила составления структур более общего типа из структур более простых типов; Описываются возможные действия над структурами и правила их выполнения, включающие: − основные элементарные операции над данными; − обобщенные операции (процедуры); − средства контроля относительно простых условий корректности ввода данных (ограничения); − средства контроля сколь угодно сложных условий корректности выполнения определенных действий (правила). В качестве основных элементарных операций обычно рассматриваются следующие: поиск записи с заданным значением ключа, чтение нужной записи, добавление записи, корректировка, удаление. В моделях данных также предусматриваются специальные операции для установления групповых отношений. Обобщенные операции или процедуры – последовательность операций, реализующая определенный алгоритм обработки данных. Процедуры могут инициироваться СУБД автоматически, а также могут запускаться пользователем. Примерами процедур являются процедуры копирования БД, восстановления БД, процедуры, вычисляющие значения определенных атрибутов в БД по значениям других атрибутов, и т.п[9]. Средства контроля используются для реализации ограничений целостности концептуальной модели. Простейшие средства контроля ограничения используются для реализации, как внешних ограничений концептуальной модели, так и внутренних ограничений модели данных. В качестве последних ограничений, в частности, реализованы ограничения на ввод данных несоответствующего типа, несоответствующей характеристики (по числу битов, по числу полей, по количеству записей и т.п.). Более сложные средства контроля (правила) позволяют вызывать выполнение определенной последовательности операций (сколь угодно сложной) при изменении или добавлении данных в БД и тем самым реализовывать ограничения целостности, описанные с помощью специальных конструкций. Заключение В данной работе ,когда мы говорили об основных понятиях реляционных баз данных, мы не опирались на какую-либо конкретную реализацию. Эти рассуждения в равной степени относились к любой системе, при построении которой использовался реляционный подход. Другими словами, мы использовали понятия так называемой реляционной модели данных. Модель данных описывает некоторый набор родовых понятий и признаков, которыми должны обладать все конкретные СУБД и управляемые ими базы данных, если они основываются на этой модели. Наличие модели данных позволяет сравнивать конкретные реализации, используя один общий язык. Хотя понятие модели данных является общим, и можно говорить о иерархической, сетевой, некоторой семантической и т.д. моделях данных, нужно отметить, что это понятие было введено в обиход применительно к реляционным системам и наиболее эффективно используется именно в этом контексте. Попытки прямолинейного применения аналогичных моделей к дореляционным организациям показывают, что реляционная модель слишком "велика" для них, а для постреляционных организаций она оказывается "мала". Список используемой литературы Атре Ш. Структурный подход к организации баз данных. - М.: Финансы и статистика, 1983. - 320 с. Беренсон Х., Бернштейн Ф., Грэй Д., Мелтон Д., О"Нил Э., О"Нил П. Критика уровней изолированности в стандарте ANSI SQL //СУБД. - 1996. - №2. - С. 45-60. Бойко В.В., Савинков В.М. Проектирование баз данных информационных систем. - М.: Финансы и статистика, 1989. - 351 с. Гилуа М.М. Множественная модель данных в информационных системах. - М.: Наука, 1992. – 40 с. Голосов А.О. Аномалии в реляционных базах данных //СУБД. - 1986. - №3. - С. 23-28. Дейт К. Введение в системы баз данных . 6-издание. - Киев: Диалектика, 1998. - 784 с. Джексон Г. Проектирование реляционных баз данных для использования с микроЭВМ. - М.: Мир, 1991. - 252 с. Джонс Э., Саттон Д. пользователя Office 97./ К.: Диалектика, 1999г. Диго С.М. Проектирование и использование баз данных. - М.: Финансы и статистика, 1995. - 208 с. Компьютеры в офисе и дома: Реляционные БД: 2004г. 228 стр. Мичи Д., Джонатон Р. Реляционные СУБД. 2004г. №8, стр. 4 Петров В.Н. Информационные системы: учебное пособие для студентов высших учебных заведений, 2003г. 2е изд. стр. 139 Пушников А.Ю. Введение в системы управления базами данных. Часть Реляционная модель данных: Учебное пособие/Изд-е Башкирского ун-та. - Уфа, 1999. - 108 с. Савельев В.А. Персональный компьютер для всех. Создание и использование баз данных. - М.: Просвещение, 1991. – 248 c. Симонович С.В. Информатика. Базовый курс. - М.: Дрофа, 2000. – 388 c. Тиори Т., Фрай Д. Проектирование структур баз данных. В 2 кн., - М.: Мир, 1985. Кн. 1. – С. 287 с., Кн. 2. – 320 с. Интернет ресурсы: www.bankreferatov.ru (2014 по 2018г. Раздел: База данных). www.libbooks.ru (2016 по 2018г. Раздел: База данных). |