Семантическая теория программ. Семантическая теория программ
 Скачать 172.36 Kb. Скачать 172.36 Kb.
|

Код с малой плотностью проверок на чётностьКод с малой плотностью проверок на чётность (LDPC-код от англ. Low-density parity-check code, LDPC-code, низкоплотностный код) — используемый в передаче информации код, частный случай блочного линейного кода с проверкой чётности. Особенностью является малая плотность значимых элементов проверочной матрицы, за счёт чего достигается относительная простота реализации средств кодирования.Также называют кодом Галлагера, по имени автора первой работы на тему LDPC-кодов.ПредпосылкиВ 1948 году Шеннон опубликовал свою работу по теории передачи информации. Одним из ключевых результатов работы считается теорема о передаче информации для канала с шумами, которая говорит о возможности свести вероятность ошибки передачи по каналу к минимуму при выборе достаточного большой длины ключевого слова — единицы информации передаваемой по каналу. Упрощённая схема передачи информации по каналу с шумами. При передаче информации её поток разбивается на блоки определённой (чаще всего) длины, которые преобразуются кодером (кодируются) в блоки, называемыми ключевыми словами. Ключевые слова передаются по каналу, возможно с искажениями. На принимающей стороне декодер преобразует ключевые слова в поток информации, исправляя (по возможности) ошибки передачи. Теорема Шеннона утверждает, что при определённых условиях вероятность ошибки декодирования (то есть невозможность декодером исправить ошибку передачи) можно уменьшить, выбрав большую длину ключевого слова. Однако, данная теорема (и работа вообще) не показывает, как можно выбрать большую длину, а точнее как эффективно организовать процесс кодирования и декодирования информации с большой длиной ключевых слов. Если предположить, что в кодере и декодере есть некие таблицы соответствия между входным блоком информации и соответствующим кодовым словом, то такие таблицы будут занимать очень много места. Для двоичного симметричного канала без памяти (если говорить упрощённо, то на вход кодера поступает поток из нулей и единиц) количество различных блоков составляет 2n, где n — количество бит (нулей или единиц) которые будут преобразовываться в одно кодовое слово. Для 8 бит это 256 блоков информации, каждый из которых будет содержать в себе соответствующее кодовое слово. Причём кодовое слово обычно большей длины, так как содержит в себе дополнительные биты для защиты от ошибок передачи данных. Поэтому одним из способов кодирования является использование проверочной матрицы, которые позволяют за одно математическое действие (умножение строки на матрицу) выполнить декодирование кодового слова. Аналогичным образом каждой проверочной матрице соответствует порождающая матрица, аналогичным способом одной операцией умножения строки на матрицу генерирующей кодовой слово. Таким образом, для сравнительно коротких кодовых слов кодеры и декодеры могут просто содержать в памяти все возможные варианты, или даже реализовывать их в виде полупроводниковой схемы. Для большего размера кодового слова эффективнее хранить порождающую и проверочную матрицу. Однако, при длинах блоков в несколько тысяч бит хранение матриц размером, соответственно, в мегабиты, уже становится неэффективным. Одним из способов решения данной проблемы становится использования кодов с малой плотностью проверок на чётность, когда в проверяющей матрице количество единиц сравнительно мало, что позволяет эффективнее организовать процесс хранения матрицы или же напрямую реализовать процесс декодирования с помощью полупроводниковой схемы. Первой работой на эту тему стала работа Роберта Галлагера «Low-Density Parity-Check Codes» 1963 года (основы которой были заложены в его докторской диссертации 1960 года). В работе учёный описал требования к таким кодам, описал возможные способы построения и способы их оценки. Поэтому часто LDPC-коды называют кодами Галлагера. В русской научной литературе коды также называют низкоплотностными кодами или кодами с малой плотностью проверок на чётность. Однако, из-за сложности в реализации кодеров и декодеров эти коды не использовались и были забыты до тех пор, пока работа Галлагера не была повторно открыта в 1996 году. С развитием телекоммуникационных технологий, снова возрос интерес к передаче информации с минимальными ошибками. Несмотря на сложность реализации по сравнению с турбо-кодом, отсутствие преград к использованию (незащищённость патентами) сделало LDPC-коды привлекательными для телекоммуникационной отрасли, и фактически стали стандартом де-факто. В 2003 году LDPC-код, вместо турбо-кода, стал частью стандарта DVB-S2 спутниковой передачи данных для цифрового телевидения. Аналогичная замена произошла и в стандарте DVB-T2 для цифрового наземного телевизионного вещания[5]. LDPC-кодыLDPC-коды описываются низкоплотностной проверочной матрицей, содержащей в основном нули и относительно малое количество единиц. По определению, если каждая строка матрицы содержит ровно {\displaystyle k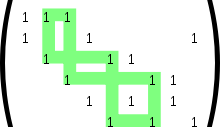 роверочная матрица LDPC-кода (9, 2, 3) с минимальным циклом длины 8 Важной характеристикой матрицы LDPC-кода является отсутствие циклов определённого размера. Под циклом длины 4 понимают образование в проверочной матрице прямоугольника, в углах которого стоят единицы. Отсутствие цикла длины 4 можно также определить через скалярное произведение столбцов (или строк) матрицы. Если каждое попарное скалярное произведение всех столбцов (или строк) матрицы не более 1, это говорит об отсутствии цикла длины 4. Циклы большей длины (6, 8, 10 и т. д.) можно определить, если в проверочной матрице построить граф, вершинами которого являются единицы, а рёбра — все возможные соединения вершин, параллельные сторонам матрицы (то есть вертикальные или горизонтальные линии). Минимальный цикл в этом графе и будет минимальным циклом в проверочной матрице LDPC-кода. Очевидно, что цикл будет иметь длину как минимум 4, а не 3, так как рёбра графа должны быть параллельны сторонам матрицы. Вообще, любой цикл в этом графе будет иметь чётную длину, минимальный размер 4, а максимальный размер обычно не играет роли (хотя, очевидно, он не более, чем количество узлов в графе, то есть n×k). Описание LDPC-кода возможно несколькими способами: проверочной матрицей двудольным графом другим графическим способом специальные способы Последний способ является условным обозначением группы представлений кодов, которые построены по заданным правилам-алгоритмам, таким, что для повторного воспроизведения кода достаточно знать лишь инициализирующие параметры алгоритма, и, разумеется, сам алгоритм построения. Однако данный способ не является универсальным и не может описать все возможные LDPC-коды. Способ задания кода проверочной матрицей является общепринятым для линейных кодов, когда каждая строка матрицы является элементом некоторого множества кодовых слов. Если все строки линейно-независимы, строки матрицы могут рассматриваться как базис множества всех кодовых векторов кода. Однако использование данного способа создаёт сложности для представления матрицы в памяти кодера — необходимо хранить все строки или столбцы матрицы в виде набора двоичных векторов, из-за чего размер матрицы становится равен {\displaystyle j\times k} бит. 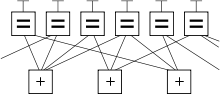 Представление LDPC-кода в виде двудольного графа Распространённым графическим способом является представление кода в виде двудольного графа. Сопоставим все {\displaystyle k} строк матрицы {\displaystyle k} нижним вершинам графа, а {\displaystyle n} столбцов — верхним, и соединим верхние и нижние вершины графа, если на пересечении соответствующих строк и столбцов стоят единицы. К другим графическим способам относят преобразования двудольного графа, происходящие без фактического изменения самого кода. Например, можно все верхние вершины графа представить в виде треугольников, а все нижние — в виде квадратов, после чего расположить рёбра и вершины графа на двухмерной поверхности в порядке, удобном для визуального понимания структуры кода. Например, такое представление используется в качестве иллюстраций в книгах Девида Маккея. 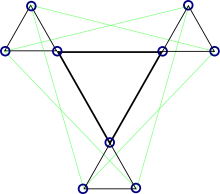 Представление (9, 2, 3) LDPC-кода в виде графа специального вида. Матрица кода приведена выше. Вводя дополнительные правила графического отображения и построения LDPC-кода, можно добиться, что в процессе построения код получит определённые свойства. Например, если использовать граф, вершинами которого являются только столбцы проверочной матрицы, а строки изображаются многогранниками, построенными на вершинах графа, то следование правилу «два многогранника не разделяют одно ребро» позволяет избавиться от циклов длины 4. При использовании специальных процедур построения кода могут использоваться и свои способы представления, хранения и обработки (кодирования и декодирования). Построение кодаВ настоящее время используются два принципа построения проверочной матрицы кода. Первый основан на генерации начальной проверочной матрицы с помощью псевдослучайного генератора. Коды, полученные таким способом, называют случайными (англ. random-like codes). Второй — использование специальных методов, основанных, например, на группах и конечных полях. Коды, полученные этими способами называют структурированными. Лучшие результаты по исправлению ошибок показывают именно случайные коды, однако структурированные коды позволяют использовать методы оптимизации процедур хранения, кодирования и декодирования, а также получать коды с более предсказуемыми характеристиками. В своей работе Галлагер предпочёл с помощью генератора псевдослучайных чисел создать начальную проверочную матрицу небольшого размера с заданными характеристиками, а далее увеличить её размер, дублируя матрицу[6] и используя метод перемешивания строк и столбцов для избавления от циклов определённой длины. В 2003 году Джеймсом МакГованом и Робертом Вильямсоном был предложен способ удаления циклов из матрицы LDPC-кода, в связи с чем стало возможным в начале сгенерировать матрицу с заданными характеристиками (n, j, k), а затем удалить из неё циклы. Так происходит в схеме Озарова-Вайнера[7]. В 2007 году в журнале «IEEE Transactions on Information Threory» была опубликована статья об использовании конечных полей для построения квази-цикличных LDPC-кодов для каналов с аддитивным белым Гауссовым шумом и двоичных каналов со стиранием. Для увеличения размерности кода может быть использовано кратное торцевое произведение порождающих матриц[6]. ДекодированиеКак и для любого другого линейного кода, для декодирования используется свойство ортогональности порождающей и транспонированной проверочной матриц: {\displaystyle G\odot H^{T}=0}, где {\displaystyle G} — порождающая матрица, и {\displaystyle H} — проверочная, {\displaystyle \odot } - символ умножения по модулю 2 (если в качестве элемента результирующей матрицы получается число, кратное 2, то вместо него записывается ноль). Тогда для каждого принятого без ошибок кодового слова выполняется соотношение {\displaystyle s=v\odot H^{T}=0}, а для принятого кодового слова с ошибкой: {\displaystyle s=v\odot H^{T}\neq 0}, где {\displaystyle v} — принятый вектор, {\displaystyle s} — синдром. В случае, если после умножения принятого кодового слова на транспонированную проверочную матрицу получается ноль, блок считается принятым без ошибок. В противном случае используются специальные методы для определения местоположения ошибки и её исправления. Для LDPC-кода стандартные способы исправления оказываются слишком трудоёмкими — их относят к классу NP-полных задач, что, учитывая большую длину блока, не может применяться на практике. Вместо них применяют метод вероятностного итеративного декодирования, исправляющую большую долю ошибок за границей половины кодового расстояния[8]. Рассмотрим[9] симметричный канал без памяти со входом {\displaystyle \pm a} и аддитивным гауссовым шумом {\displaystyle \sigma ^{2}=1}. Для принятого кодового слова {\displaystyle y} нужно найти соответствующий наиболее вероятный вектор {\displaystyle x}, такой что {\displaystyle H\odot x=0\mod 2}. Определим {\displaystyle f_{n}^{1}={1/{\mathord {\left(1+\exp \left(-2ay_{n}/{\mathord {\sigma ^{2}}}\right)\right)}}}}; {\displaystyle f_{n}^{0}=1-f_{n}^{1}}; где {\displaystyle y_{n}} — принятое значение n-го символа кодового слова (которое для данного канала имеет произвольное значение, обычно в рамках {\displaystyle \pm (a+3\sigma )}). Будем использовать слово «бит» для обозначения отдельных элементов вектора {\displaystyle x}, и слово «проверка» для обозначения строк проверочной матрицы {\displaystyle H}. Обозначим через {\displaystyle N\left(m\right)\equiv \{n:H_{nm}=1\}} набор битов, которые будут участвовать в m-ой проверке. Аналогично, обозначим {\displaystyle M\left(n\right)\equiv \{m:H_{nm}=1\}} набор проверок, в которых участвует бит n. (То есть перечислим индексы ненулевых элементов для каждой строки и для каждого столбца проверочной матрицы {\displaystyle H}). Инициализируем матрицы {\displaystyle q_{mn}^{0}} и {\displaystyle q_{mn}^{1}} значениями {\displaystyle f_{n}^{0}} и {\displaystyle f_{n}^{1}} соответственно (Горизонтальный шаг) {\displaystyle \delta q_{mn}=q_{mn}^{0}-q_{mn}^{1}} {\displaystyle \delta r_{mn}=\prod \limits _{n'\in N(m)\backslash n}{\delta q_{mn'}}} {\displaystyle r_{mn}^{0}={1 \over 2}\left({1+\delta r_{mn}}\right)} {\displaystyle r_{mn}^{1}={1 \over 2}\left({1-\delta r_{mn}}\right)} (Вертикальный шаг) {\displaystyle q_{mn}^{0}=\alpha _{mn}f_{n}^{0}\prod \limits _{m'\in M\left(n\right)\backslash m}{r_{m'n}^{0}}} {\displaystyle q_{mn}^{1}=\alpha _{mn}f_{n}^{1}\prod \limits _{m'\in M\left(n\right)\backslash m}{r_{m'n}^{1}}} где для каждого {\displaystyle m} и {\displaystyle n} выбранное {\displaystyle \alpha _{mn}} даёт: {\displaystyle q_{mn}^{0}+q_{mn}^{1}=1} Теперь также обновляем «псевдопостериорные вероятности» того, что биты вектора {\displaystyle x} принимают значения 0 или 1: {\displaystyle q_{n}^{0}=\alpha _{n}f_{n}^{0}\prod \limits _{m\in M\left(n\right)}{r_{mn}^{0}}} {\displaystyle q_{n}^{1}=\alpha _{n}f_{n}^{1}\prod \limits _{m\in M\left(n\right)}{r_{mn}^{1}}} Также, как и ранее, {\displaystyle \alpha _{n}} выбирается таким образом, что {\displaystyle q_{n}^{0}+q_{n}^{1}=1} Данные значения используются для воссоздания вектора x. Если полученный вектор удовлетворяет {\displaystyle H\odot x=0\mod 2}, то алгоритм на этом прерывается, иначе повторяются горизонтальный и вертикальные шаги. Если же алгоритм продолжается до некоторого шага (например, 100), то он прерывается и блок объявляется принятым с ошибкой. Известно, что данный алгоритм даёт точное значение вектора {\displaystyle x} (то есть, совпадающее с классическими способами), если проверочная матрица {\displaystyle H} не содержит циклов. |