Разработка баз данных. Практическая работа_1docx. Создание базы данных в среде субд cassandra
 Скачать 200.48 Kb. Скачать 200.48 Kb.
|

Москва 2020 Цель работы Получить навыки работы с Cassandra. Теоретическое введение Apache Cassandra – это децентрализованная распределенная система, состоящая из нескольких узлов, по которым она распределяет данные. В отличие от многих других Big Data решений экосистемы Apache Hadoop (HBase, HDFS), эта СУБД не поддерживает концепцию master/slave (ведущий/ведомый), когда один из серверов является управляющим для других компонентов кластера. Для распределения элементов данных по узлам Кассандра использует последовательное хэширование, применяя хэш-алгоритм для вычисления хэш-значений ключей каждого элемента данных (имя столбца, ID строки и пр.). Диапазон всех возможных хэш-значений, т.е. пространство ключей, распределяется между узлами кластера так, что каждому элементу данных назначен свой узел, который отвечает за хранение и управление этим элементом данных. Благодаря такой распределенной архитектуре, Кассандра предоставляет следующие возможности: распределение данных между узлами кластера прозрачно для пользователей – каждый сервер может принимать любой запрос (на чтение, запись или удаление данных), пересылая его на другой узел, если запрашиваемая информацию хранится не здесь; пользователи могут сами определить необходимое количество реплик, создание и управление которыми обеспечит Cassandra; настраиваемый пользователями уровень согласованности данных по каждой операции хранения и считывания; высокая скорость записи (около 80-360 МБ/с на узел) – данные записываются быстрее, чем считываются за счет того, что их большая часть хранится в оперативной памяти ответственного узла, и любые обновления сперва выполняются в памяти, а только потом – в файловой системе. Чтобы избежать потери информации, все транзакции фиксируются в специальном журнале на диске. При этом, в отличие от обновления данных, записи в журналы фиксации только добавляются, что исключает задержку при вращении диска. Кроме того, если не требуется полная согласованность записей, Cassandra записывает данные в достаточное число узлов без разрешения конфликтов несоответствия, которые разрешаются только при первом считывании. гибкая масштабируемость – можно построить кластер даже на сотню узлов, способный обрабатывать петабайты данных. Таким образом, отсутствие центрального узла лишает Кассандру главного недостатка, свойственного системам master/slave, в которых отказывает весь кластер при сбое главного сервера (Master Node). В кластере Cassandra все узлы равноценны между собой и, если один из них отказал, его функции возьмет на себя какой-то из оставшихся. Благодаря такой децентрализации Apache Cassandra отлично подходит для географически распределенных систем с высокой доступностью, расположенных в разных датацентрах. Однако, при всех преимуществах такой гибко масштабируемой архитектуры, она обусловливает особенности операций чтения и записи, а также накладывает ряд существенных ограничений на использование этой СУБД в реальных Big Data проектах. Задание на практическую работу Ознакомиться с операциями, производимыми c консоли СУБД и выполнить следующие действия: создать и использовать пространство ключей; изменить и удалить пространство ключей; создать таблицу; отобразить структуру таблиц; добавить необходимое количество записей в таблицы для выполнения запросов; просмотреть все записи в одной таблице; удалить одну запись в таблице; добавить и удалить столбец; создать таблицу с составным первичным ключом; создать таблицы с комбинированным ключом раздела и ключом группировки; Решение заданий Создание и использование пространства ключей. Рис. 1. –Создание пространство ключей. Рис. 2. Использование пространство ключей. Изменить и удалить пространство ключей.  Рис. 3. До изменения пространства ключей. 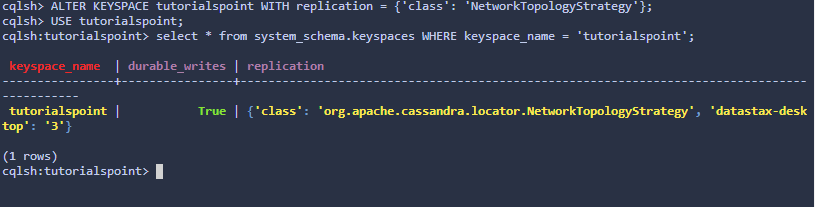 Рис. 4. После изменения значения org.apache.cassandra.locator.SimpleStrategy.  Рис. 5. Удаление пространства ключей. Создать таблицу. 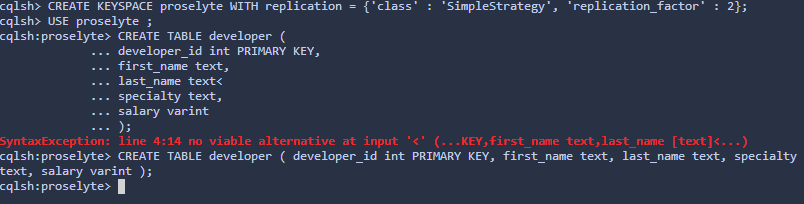 Рис. 6. Создание таблицы. Отобразить структуру таблиц.  Рис. 7. Отображение структуры таблицы. Добавить необходимое количество записей в таблицы для выполнения запросов и просмотреть все записи в одной таблице. 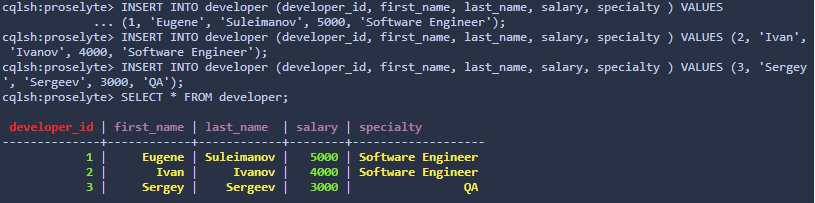 Рис. 8. Добавление записей в таблицу и просмотр их. Удалить одну запись в таблице. 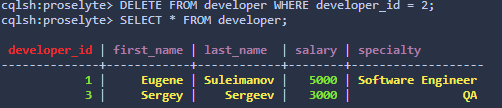 Рис. 9. Удаление одной записи в таблице. Добавить и удалить столбец.  Рис. 9. Добавление и удаление столбца. Создать таблицу с составным первичным ключом. Рис. 10. Создание таблицы с первичным ключом. developer_id – первичный ключ. Создать таблицы с комбинированным ключом раздела и ключом группировки. Рис. 11. Создание таблицы с комбинированным ключом. Рис. 12. Создание таблицы с групповым ключом. Выводы по работе В ходе данной работы я научился создавать, изменять и удалять пространства ключей, а также создавать и удалять таблицы, добавлять, удалять столбцы и добавлять и удалять значения в них. Список литературы Кузнецов Максим, Симдянов Игорь. MySQL на примерах. — Спб.: «БХВ-Петербург», 2008. — 952 c. [http://www.sql-tutorial.ru/] – select, drop, update и т.д [https://habr.com/ru/company/oleg-bunin/blog/348172/] – SQL внешние и первичные ключи. | |||||||||||||||||||||||||||||||||||||||||||||
