Ответы к экзамену по базам данных. Создание, модификация и уничтожение таблиц. Предложение языка sql create table. Основные типы данных. Предложение alter table. Предложение drop table
 Скачать 0.53 Mb. Скачать 0.53 Mb.
|

|
WHERE [<предикат>] [GROUP BY {<имя столбца>/<целое>}, ..] HAVING[<предикат>] ORDER BY [{<имя столбца>/<целое>}.,..] Предложение ORDER BY В общем случае строки в результирующей таблице SQL-запроса никак не упорядочены. Однако их можно требуемым образом отсортировать, для чего в оператор SELECT помещается фраза ORDER BY, которая сортирует данные выходного набора в заданной последовательности. Сортировка может выполняться по нескольким полям, в этом случае они перечисляются за ключевым словом ORDER BY через запятую. Способ сортировки задается ключевым словом, указываемым в рамках параметра ORDER BY следом за названием поля, по которому выполняется сортировка. По умолчанию реализуется сортировка по возрастанию. Явно она задается ключевым словом ASC. Для выполнения сортировки в обратной последовательности необходимо после имени поля, по которому она выполняется, указать ключевое слово DESC. Фраза ORDER BY позволяет упорядочить выбранные записи в порядке возрастания или убывания значений любого столбца или комбинации столбцов, независимо от того, присутствуют эти столбцы в таблице результата или нет. Фраза ORDER BY всегда должна быть последним элементом в операторе SELECT. Во фразе ORDER BY может быть указано и больше одного элемента. Пример. Вывести список фирм и клиентов. Названия фирм упорядочить в алфавитном порядке, имена клиентов в каждой фирме отсортировать в обратном порядке. SELECT Клиент.Фирма, Клиент.Фамилия FROM Клиент ORDER BY Клиент.Фирма, Клиент.Фамилия DESC Оператор GROUP BY (группировать по) перекомпоновывает таблицу, представленную фразой FROM, в разделы или группы таким образом, чтобы в каждой группе все строки имели одно и то же значение поля, указанного во фразе GROUP BY.  SELECT Название FROM Детали GROUP BY Название; При помощи HAVING отражаются все предварительно сгруппированные посредством GROUP BY блоки данных, удовлетворяющие заданным в HAVING условиям. Это дополнительная возможность "профильтровать" выходной набор. Условия в HAVING отличаются от условий в WHERE: • HAVING исключает из результирующего набора данных группы с результатами агрегированных значений; • WHERE исключает из расчета агрегатных значений по группировке записи, не удовлетворяющие условию; • в условии поиска WHERE нельзя задавать агрегатные функции. Пример. Определить фирмы, у которых общее количество сделок превысило три. SELECT column,SUM(column) FROM table GROUP BY column HAVING SUM(column) condition value SELECT Клиент.Фирма, Count(Сделка.Количество) AS Количество_сделок FROM Клиент INNER JOIN Сделка ON Клиент.КодКлиента=Сделка.КодКлиента GROUP BY Клиент.Фирма HAVING Count(Сделка.Количество)>3 3. Язык SQL – структурированный язык запросов к реляционным базам данных. Понятие объемлющего языка. Непроцедурный, структуризированный язык запросов (SQL) – язык, ориентированный на операции с данными, представленными в виде логически взаимосвязанных совокупностей таблиц. Особенность предложений языка запросов SQL – ориентированность в большей степени на конечный результат обработки данных, чем на процедуру этой обработки. SQL сам определяет, где находятся данные, какие индексы и даже наиболее эффективные последовательности операций следует использовать для их получения: не надо указывать эти детали в запросе к базе данных. Структура SQL (операторы): Операторы определения данных (Data Definition Language, DDL) 1. CREATE создает объект БД (саму базу, таблицу, представление, пользователя и т.д.) 2. ALTER изменяет объект 3. DROP удаляет объект Операторы манипуляции данными (Data Manipulation Language, DML) 1. SELECT считывает данные, удовлетворяющие заданным условиям 2. INSERT добавляет новые данные 3. UPDATE изменяет данные 4. DELETE удаляет данные Операторы определения доступа к данным (Data Control Language, DCL) 1. GRANT предоставляет пользователю (группе) разрешения на определенные операции с объектом 2. REVOKE отзывает ранее выданные разрешения 3. DENY задает запрет, имеющий приоритет над разрешением Операторы управления транзакциями (Transaction Control Language, TCL) 1. COMMIT применяет транзакцию. 2. ROLLBACK откатывает все изменения, сделанные в контексте текущей транзакции. 3. SAVEPOINT делит транзакцию на более мелкие участки Экзаменационный билет № 8
Реляционная БД представляет собой совокупность таблиц, связанных отношениями. Основные понятия: “таблица”, “отношение”, “строка”, “первичный ключ”. Все операции над реляционной базой данных сводятся к манипуляциям с таблицами. Связь между таблицами существует на логическом уровне и определяется предметной областью. Практически связь между таблицами устанавливается путем использования логически связанных данных в разных таблицах. Для работы с реляционными СУБД используется стандартизированный язык структурированных запросов SQL. Достоинствами реляционной модели данных являются простота, гибкость структуры, удобство реализации на компьютере, высокая стандартизированность и использование математического аппарата реляционной алгебры и реляционного исчисления. К недостаткам можно отнести ограниченность и предопределенность набора возможных типов данных. Это затрудняет использование реляционных моделей для некоторых современных приложений. Наиболее распространенная трактовка реляционной модели данных принадлежит К.Дейту. Согласно Дейту, реляционная модель состоит из трех частей: Структурная часть описывает, какие объекты рассматриваются реляционной моделью. Постулируется, что единственной структурой данных, используемой в реляционной модели, являются нормализованные n-арные отношения. Целостная часть описывает ограничения специального вида, которые должны выполняться для любых отношений в любых реляционных базах данных. Это целостность сущностей и целостность внешних ключей. Манипуляционная часть описывает два эквивалентных способа манипулирования реляционными данными - реляционную алгебру и реляционное исчисление. В настоящее время в неформальном контексте термины отношение и таблица принято считать синонимами. Таблица ниже показывает примерные соответствия терминов:
Домен представляет собой множество всех возможных значений определенного атрибута отношения.Домен характеризуется следующими свойствами:
Кортеж - это множество пар {имя атрибута, значение}, которое содержит одно вхождение каждого имени атрибута. "Значение" является допустимым значением домена данного атрибута. Попросту говоря, кортеж - это набор именованных значений заданного типа. Отношение (таблица) - это множество кортежей, соответствующих одной схеме отношения. На самом деле, понятие схемы отношения ближе всего к понятию структурного типа данных в языках программирования. Сущность – некоторый обособленный объект или событие, информацию о котором необходимо сохранять в базе данных и который имеет определенный набор свойств – атрибутов. Для сущностей различают тип и экземпляр. Тип характеризуется именем и списком свойств, а экземпляр – конкретными значениями свойств. Атрибуты представляют собой свойства, характеризующие сущность. В структуре таблицы каждый атрибут именуется и ему соответствует заголовок некоторого столбца таблицы. Атрибуты сущности бывают: 1) идентифицирующие и описательные. Идентифицирующие атрибуты имеют уникальное значение для сущностей данного типа и являются потенциальными ключами. Они позволяют однозначно распознавать экземпляры сущности. Из потенциальных ключей выбирается один первичный ключ. В качестве первичного ключа обычно выбирается потенциальный ключ, по которому чаще происходит обращение к экземплярам записи. Первичный ключ должен включать в свой состав минимально необходимое для идентификации количество атрибутов. Остальные атрибуты называются описательными; 2) простые и составные. Простой атрибут состоит из одного компонента, его значение неделимо. Составной атрибут является комбинацией нескольких компонентов, возможно принадлежащих разным типам данных (например, адрес). Решение о том, использовать составной атрибут или разбивать его на компоненты, зависит от особенностей процессов его применения и может быть связано с обеспечением высокой скорости работы с большими базами данных; 3) однозначные и многозначные. Атрибуты могут иметь соответственно одно или много значений для каждого экземпляра сущности; 4) основные и производные. Значение основного атрибута не зависит от других атрибутов. Значение производного атрибута вычисляется на основе значений других атрибутов (например, возраст человека вычисляется на основе даты его рождения и текущей даты). Спецификация атрибута состоит из его названия, указания типа данных и описания ограничений целостности – множества значений (или домена), которые может принимать данный атрибут. Схема отношения (заголовок отношения) представляет собой список имен атрибутов с указанием имен доменов. Кортеж, соответствующий данной схеме отношения, представляет собой множество пар (имя атрибута, значение}, которое содержит одно вхождение каждого имени атрибута. Аргумент “значение” является допустимым значением домена данного атрибута. Первичным ключом (ключом отношения, ключевым атрибутом) называется атрибут или набор атрибутов отношения, однозначно идентифицирующий каждый из его кортежей. Первичный ключ по определению уникален: в отношении не может быть двух разных кортежей с одинаковыми значениями первичного ключа. Атрибуты, составляющие первичный ключ, не могут иметь значение NULL. Понятие NULL в теории реляционных баз данных призвано обозначать отсутствие какого-либо значения атрибута. Для каждого отношения первичный ключ может быть только один. Внешние ключи – это основной механизм для организации связей между таблицами и поддержания целостности и непротиворечивости информации в базе данных. Внешний ключ – это набор атрибутов одного отношения, являющийся возможным ключом другого отношения.
ПЕРВАЯ ФОРМА − Отношение R находится в первой нормальной форме (1НФ), если значения каждого его атрибута являются атомарными, т.е. такими значениями, которые не являются множеством значений или повторяющейся группой. В определении реляционной модели Кодда все отношения всегда находятся в 1НФ. Каждый атрибут отношения должен хранить одно-единственное значение и не являться ни списком, ни множеством значений. ВТОРАЯ ФОРМА − Отношение R находится во второй нормальной форме (2НФ), если никакие не ключевые атрибуты не являются функционально зависимыми лишь от части ключа. Таким образом, 2НФ может оказаться нарушена только в том случае, когда ключ составной. Каждый не ключевой столбец в таблице должен уникально идентифицироваться по первичному ключу ТРЕТЬЯ ФОРМА − Отношение R находится в третьей нормальной форме (3NF) в том и только в том случае, если находится в 2NF и каждый не ключевой атрибут не транзитивно зависит от первичного ключа. Кроме удовлетворения требованиям второй нормальной формы, каждый не ключевой столбец таблицы должен быть независимым от других не ключевых столбцов
Операторы определения данных (Data Definition Language, DDL): 1. CREATE создает объект БД (саму базу, таблицу, представление, пользователя и т.д.) 2. ALTER изменяет объект 3. DROP удаляет объект Оператор CREATE TABLE CREATE TABLE базовая_таблица (столбец_1 тип_данных, столбец_2 тип_данных ...); где тип_данных должен принадлежать к одному из типов данных, поддерживаемых СУБД. Применим DDL для создания в базе данных MyDB таблицы с именем Customer_Data (Сведения_о_заказчиках). Для создания таблицы применяется оператор CREATE TABLE. Наша таблица-пример будет задана как имеющая четыре колонки, при помощи следующих операторов: Use MyDB CREATE TABLE Customer_Data (customer_id smallint, first_name char(20), last_name char(20), phone char(10)) GO CREATE TABLE имя_таблицы(имя_столбца тип_данных [NOT NULL],… PRIMARY KEY(имя_столбца,…), FOREIGN KEY имя_ограничения (имя_столбца,…) REFERENCE имя_таблицы UNIQUE(имя_столбца,…), ) Предложение NOT NULL предотвращает занесение в столбец пустых значений. PRIMARY KEY и FOREIGN KEY – столбец или столбцы первичного и внешнего ключей (в определениях столбцов первичного ключа должно быть указано, что они не могут содержать значения NULL) . UNIQUE – условие уникальности данных. Оператор ALTER TABLE Оператор ALTER TABLE применяется для изменения определения или атрибутов таблицы. ALTER TABLE имя_таблицы ADD имя_столбца; Применим для добавления в существующую таблицу Customer_Data колонки middle_initial: ALTER TABLE Customer_Data ADD middle_initial char(1) GO Теперь определение таблицы содержит не четыре колонки, как было первоначально, а пять колонок. Оператор DROP TABLE Оператор DROP TABLE применяется для уничтожения определений таблиц и всех данных, индексов, триггеров, ограничений и специальных разрешений, относящихся к удаляемым таблицам. Для уничтожения нашей таблицы Customer_Data применяется команда: DROP TABLE Customer_Data GO DROP TABLE имя_таблицы [RESTRICT | CASCADE] Если в операторе указано ключевое слово RESTRICT, то при наличии в базе данных хотя бы одного объекта, существование которого зависит от удаляемой таблицы, выполнение оператора DROP TABLE будет отменено. Если указано ключевое слово CASCADE, автоматически удаляются и все прочие объекты базы данных, чье существование зависит от удаляемой таблицы, а также другие объекты, зависящие от удаляемых объектов. 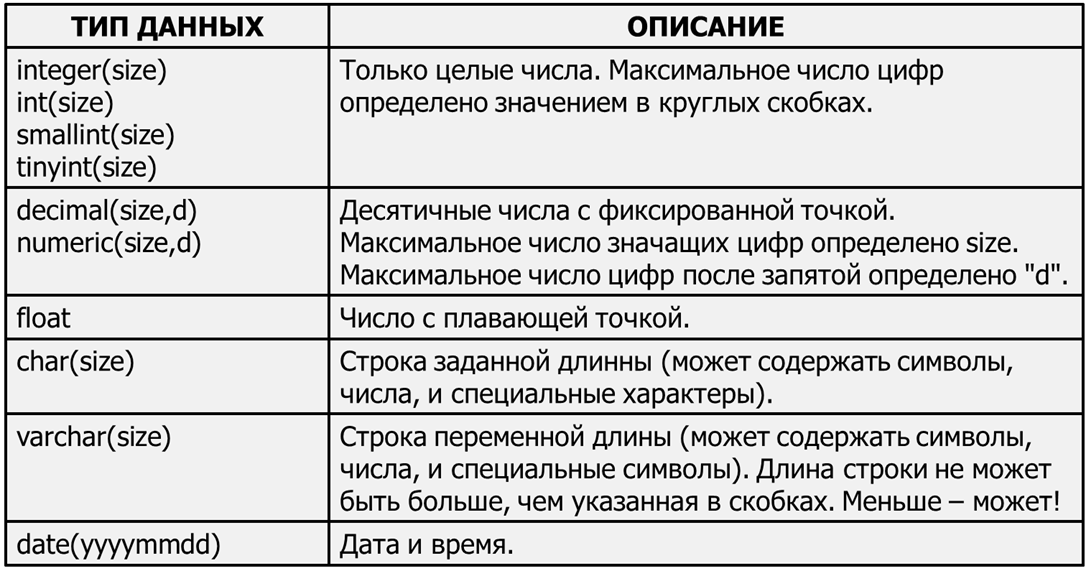 Экзаменационный билет № 9 1. Нормализация, основное назначение. Что оптимизирует нормализация. Нормальная форма — свойство отношения в реляционной модели данных, характеризующее его с точки зрения избыточности, которая потенциально может привести к логически ошибочным результатам выборки или изменения данных. Нормальная форма определяется как совокупность требований, которым должно удовлетворять отношение. Процесс преобразования базы данных к виду, отвечающему нормальным формам, называется нормализацией. Нормализация предназначена для приведения структуры базы данных к виду, обеспечивающему минимальную избыточность, то есть нормализация не имеет целью уменьшение или увеличение производительности работы или же уменьшение, или увеличение объёма БД. Конечной целью нормализации является уменьшение потенциальной противоречивости хранимой в БД информации. Цель нормализации - минимизировать повторения данных и возможные структурные изменения БД при процедурах обновления. Это достигается разделением (декомпозицией) одной таблицы в две или несколько с последующим использованием при запросах операции навигации. Функциональная зависимость - в отношении R атрибут Y функционально зависит от атрибута X (X и Y могут быть составными) в том и только в том случае, если каждому значению X соответствует в точности одно значение Y: R.X (r) R.Y. Множество атрибутов X называется детерминантом функциональной зависимости, а множество атрибутов Y называется зависимой частью. Функциональная зависимость атрибутов утверждает лишь то, что для каждого конкретного состояния базы данных по значению одного атрибута (детерминанта) можно однозначно определить значение другого атрибута (зависимой части). Но конкретные значение зависимой части могут быть различны в различных состояниях базы данных. |