Ответы к экзамену по базам данных. Создание, модификация и уничтожение таблиц. Предложение языка sql create table. Основные типы данных. Предложение alter table. Предложение drop table
 Скачать 0.53 Mb. Скачать 0.53 Mb.
|

|
Экзаменационный билет № 1
Операторы определения данных (Data Definition Language, DDL): 1. CREATE создает объект БД (саму базу, таблицу, представление, пользователя и т.д.) 2. ALTER изменяет объект 3. DROP удаляет объект Оператор CREATE TABLE CREATE TABLE базовая_таблица (столбец_1 тип_данных, столбец_2 тип_данных ...); где тип_данных должен принадлежать к одному из типов данных, поддерживаемых СУБД. Применим DDL для создания в базе данных MyDB таблицы с именем Customer_Data (Сведения_о_заказчиках). Для создания таблицы применяется оператор CREATE TABLE. Наша таблица-пример будет задана как имеющая четыре колонки, при помощи следующих операторов: Use MyDB CREATE TABLE Customer_Data (customer_id smallint, first_name char(20), last_name char(20), phone char(10)) GO CREATE TABLE имя_таблицы(имя_столбца тип_данных [NOT NULL],… PRIMARY KEY(имя_столбца,…), FOREIGN KEY имя_ограничения (имя_столбца,…) REFERENCE имя_таблицы UNIQUE(имя_столбца,…), ) Предложение NOT NULL предотвращает занесение в столбец пустых значений. PRIMARY KEY и FOREIGN KEY – столбец или столбцы первичного и внешнего ключей (в определениях столбцов первичного ключа должно быть указано, что они не могут содержать значения NULL) . UNIQUE – условие уникальности данных. Оператор ALTER TABLE Оператор ALTER TABLE применяется для изменения определения или атрибутов таблицы. ALTER TABLE имя_таблицы ADD имя_столбца; Применим для добавления в существующую таблицу Customer_Data колонки middle_initial: ALTER TABLE Customer_Data ADD middle_initial char(1) GO Теперь определение таблицы содержит не четыре колонки, как было первоначально, а пять колонок. Оператор DROP TABLE Оператор DROP TABLE применяется для уничтожения определений таблиц и всех данных, индексов, триггеров, ограничений и специальных разрешений, относящихся к удаляемым таблицам. Для уничтожения нашей таблицы Customer_Data применяется команда: DROP TABLE Customer_Data GO DROP TABLE имя_таблицы [RESTRICT | CASCADE] Если в операторе указано ключевое слово RESTRICT, то при наличии в базе данных хотя бы одного объекта, существование которого зависит от удаляемой таблицы, выполнение оператора DROP TABLE будет отменено. Если указано ключевое слово CASCADE, автоматически удаляются и все прочие объекты базы данных, чье существование зависит от удаляемой таблицы, а также другие объекты, зависящие от удаляемых объектов. 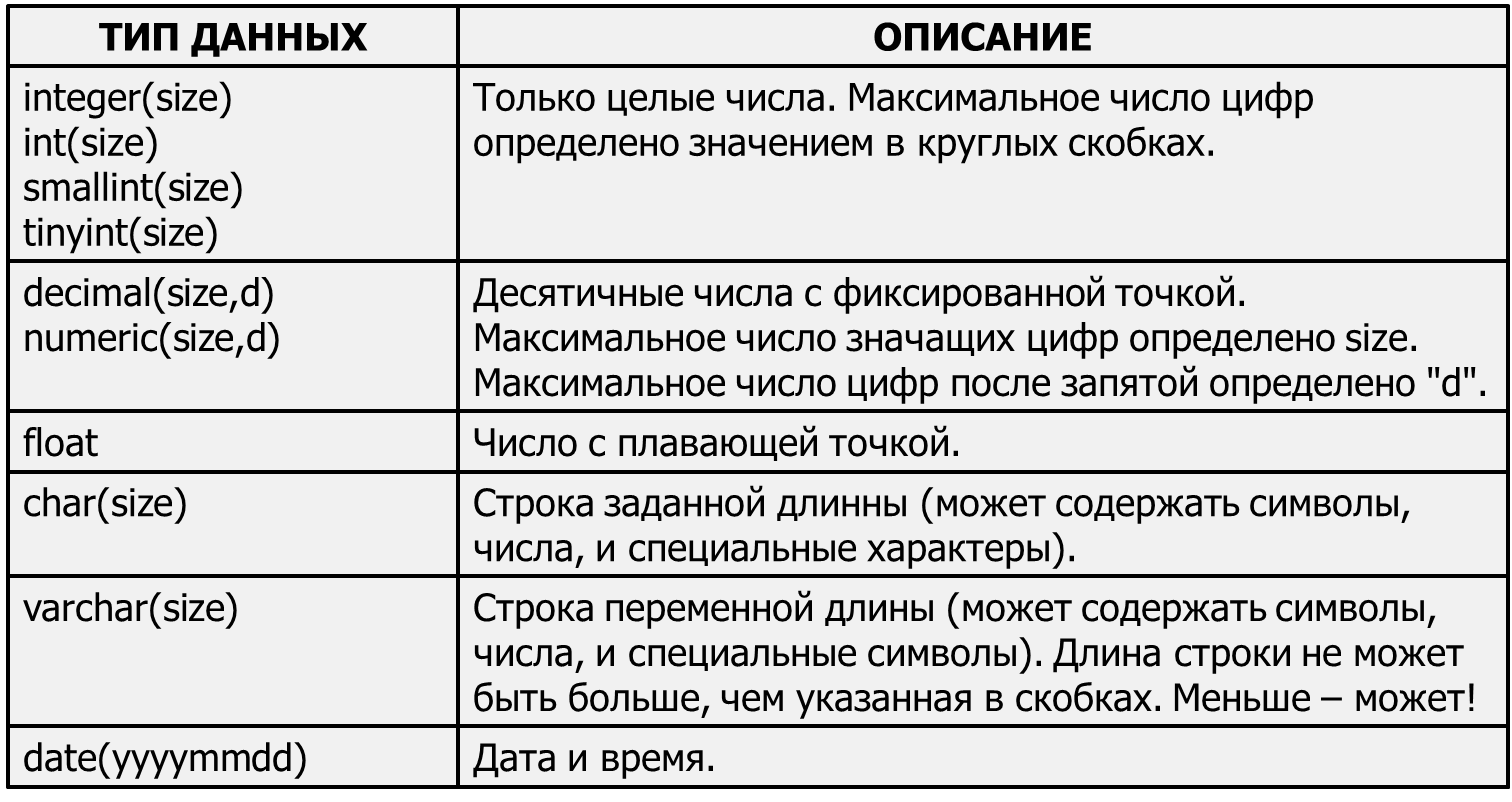
В СУБД используют протокол доступа к данным, позволяющий избежать проблемы параллелизма. Его суть заключается в следующем: • транзакция, результатом действия которой на строку данных в таблице является ее извлечение, обязана наложить блокировку чтения на эту строку; • транзакция, предназначенная для модификации строки данных, накладывает на нее блокировку записи; • если запрашиваемая блокировка на строку отвергается из-за уже имеющейся блокировки, то транзакция переводится в режим ожидания до тех пор, пока блокировка не будет снята; • блокировка записи сохраняется вплоть до конца выполнения транзакции. Если в системе управления базами данных не реализованы механизмы блокирования, то при одновременном чтении и изменении одних и тех же данных несколькими пользователями могут возникнуть следующие проблемы одновременного доступа: • проблема последнего изменения возникает, когда несколько пользователей изменяют одну и ту же строку, основываясь на ее начальном значении; тогда часть данных будет потеряна, т.к. каждая последующая транзакция перезапишет изменения, сделанные предыдущей. Выход из этой ситуации заключается в последовательном внесении изменений; • проблема "грязного" чтения возможна в том случае, если пользователь выполняет сложные операции обработки данных, требующие множественного изменения данных перед тем, как они обретут логически верное состояние. Если во время изменения данных другой пользователь будет считывать их, то может оказаться, что он получит логически неверную информацию. Для исключения подобных проблем необходимо производить считывание данных после окончания всех изменений; • проблема неповторяемого чтения является следствием неоднократного считывания транзакцией одних и тех же данных. Во время выполнения первой транзакции другая может внести в данные изменения, поэтому при повторном чтении первая транзакция получит уже иной набор данных, что приводит к нарушению их целостности или логической несогласованности; • проблема чтения фантомов появляется после того, как одна транзакция выбирает данные из таблицы, а другая вставляет или удаляет строки до завершения первой. Выбранные из таблицы значения будут некорректны. Для решения перечисленных проблем в специально разработанном стандарте определены четыре уровня блокирования. Уровень изоляции транзакции определяет, могут ли другие (конкурирующие) транзакции вносить изменения в данные, измененные текущей транзакцией, а также может ли текущая транзакция видеть изменения, произведенные конкурирующими транзакциями, и наоборот. Каждый последующий уровень поддерживает требования предыдущего и налагает дополнительные ограничения: • уровень 0 – запрещение "загрязнения" данных. Этот уровень требует, чтобы изменять данные могла только одна транзакция; если другойbтранзакции необходимо изменить те же данные, она должна ожидать завершения первой транзакции; • уровень 1 – запрещение "грязного" чтения. Если транзакция начала изменение данных, то никакая другая транзакция не сможет прочитать их до завершения первой; • уровень 2 – запрещение неповторяемого чтения. Если транзакция считывает данные, то никакая другая транзакция не сможет их изменить. Таким образом, при повторном чтении они будут находиться в первоначальном состоянии; • уровень 3 – запрещение фантомов. Если транзакция обращается к данным, то никакая другая транзакция не сможет добавить новые или удалить имеющие строки, которые могут быть считаны при выполнении транзакции. Реализация этого уровня блокирования выполняется путем использования блокировок диапазона ключей. Подобная блокировка накладывается не на конкретные строки таблицы, а на строки, удовлетворяющие определенному логическому условию. Блокировки, используемые уровнями изоляции, подразделяются на: • разделяемые блокировки (S-locks), которые могут одновременно устанавливаться несколькими пользователями; • исключительные блокировки (X-locks), которые устанавливаются только одним пользователем, получающим эксклюзивный доступ к данным. Существуют следующие логические и физические уровни блокировок: • блокировка на уровне таблицы (table-level locking); • блокировка на уровне строк (row-level locking); • блокировка на уровне элемента таблицы (item-level locking); • блокировка на уровне БД (dbspace-level locking); • блокировка на уровне табличного пространства (tablespace-level locking); блокировка на уровне страницы или блока (page-level locking). В большинстве СУБД создается механизм обработки транзакций, при инициировании которого все изменения данных будут рассматриваться как предварительные до тех пор, пока пользователь (реже система) не выдаст предложения: COMMIT (фиксировать), превращающее все предварительные обновления в окончательные (“зафиксированные”); ROLLBACK (откат), аннулирующее все предварительные обновления.
INSERT — осуществляет вставку строк в таблицу. INSERT INTO имя_таблицы [(<список столбцов>)] VALUES (<список значений>) INSERT INTO Customers (cust_id, cust_contact, cust_email, cust_name, cust_address, cust_city, cust_state, cust_ZIP) VALUES ('4000000006’, NULL, NULL, 'Toy Land', '123 Any Street', 'New York', 'NY’, '11111'); Преодолеть ограничение на вставку одной строки в операторе INSERT при использовании VALUES позволяет искусственный прием использования подзапроса, формирующего строку с предложением UNION ALL. Так если нам требуется вставить несколько строк при помощи одного оператора INSERT, можно написать: INSERT INTO Products SELECT ‘Стул’, 1200 UNION ALL SELECT ‘Стол', 3000 UNION ALL SELECT ‘Шкаф', 5000 Эта форма оператора INSERT с параметром SELECT позволяет скопировать множество строк из одной таблицы в другую Экзаменационный билет № 2
Оператор UPDATE применяется для изменения значений в группе записей или в одной записи указанной таблицы. UPDATE имя_таблицы SET имя_столбца=<выражение>[,...n] [WHERE <условие_отбора>] Предложение WHERE является необязательным. Если оно опущено, значения указанных столбцов будут изменены во всех строках таблицы. Если предложение WHERE присутствует, то обновлены будут только те строки, которые удовлетворяют условию отбора. UPDATE Customers SET cust_email = 'kim@thetoystore.com' WHERE cust_id = '10'; Обновление нескольких столбцов: UPDATE Customers SET cust_contact = 'Sam Roberts', cust_email = 'sam@toyland.com' WHERE cust_id = '10'; Или утроить цену всех продуктов таблицы поставки: UPDATE Поставки SET Цена = Цена * 3 WHERE ПР <> 17; Обновление с подзапросом: Установить вес деталей равным 10 для всех поставщиков из Лондона. UPDATE Детали SET Вес = 10 WHERE 'Лондон' = (SELECT Город FROM Поставщики WHERE Поставщики.НОМЕР_ПОСТАВЩИКА = Детали. НОМЕР_ПОСТАВЩИКА); Невозможно обновить более одной таблицы в единственном запросе. Иными словами, в предложении UPDATE должна специфицироваться в точности одна таблица. Поэтому в данном примере мы сталкиваемся со следующей проблемой целостности (точнее, с проблемой целостности по ссылкам): база данных становится противоречивой после выполнения первого предложения UPDATE - она включает теперь некоторые поставки, для которых не имеется соответствующей записи о поставщике, и остается в таком состоянии до тех пор, пока не будет выполнено второе предложение UPDATE. Изменение порядка предложений UPDATE, конечно, не решает эту проблему. Поэтому важно обеспечить выполнение обоих этих предложений, а не только одного.
Предложение DELETE имеет следующий общий формат: Удаляются все записи в "таблице", которые удовлетворяют "условию". DELETE FROM таблица [WHERE Условие]; Удаление множества записей: Удалить поставщика с фамилией Адамс. DELETE FROM Поставщики WHERE Фамилия = 'Адамс'; Удаление множества записей: Удалить всех поставщиков из Лондона. DELETE FROM Поставщики WHERE Город = 'Лондон'; Удаление с подзапросом: Удалить все детали из Лондона для поставщиков. DELETE FROM Детали WHERE 'Лондон' = (SELECT Город FROM Поставщики WHERE Поставщики.Номер_Поставщика = Детали.Номер_Поставщика);
Детерминант − любой атрибут, от которого полностью функционально зависит некоторый другой атрибут. БОЙС-КОДД − Отношение R находится в нормальной форме Бойса-Кодда (BCNF) в том и только в том случае, если каждый детерминант является возможным ключом. Вариант третьей нормальной формы, в котором требуется, чтобы каждый столбец, от которого зависит другой столбец, сам должен быть уникальным ключом. Отношение находится в нормальной форме Бойса – Кодда, когда оно находится в третьей нормальной форме и в нём отсутствуют функциональные зависимости атрибутов первичного ключа от неключевых атрибутов. ЧЕТВЁРТАЯ ФОРМА − Отношение R находится в четвертой нормальной форме (4NF), если в случае существования многозначной зависимости A −> −> B все остальные атрибуты R функционально зависят от A. Четвёртая нормальная форма запрещает существование многозначных зависимостей между столбцами. Если столбец вместо того, чтобы уникально идентифицировать другой столбец, ограничивает его значения некоторым предопределённым множеством значений – это означает, что между ними существует многозначная зависимость. Отношение находится в четвёртой нормальной форме если оно находится в нормальной форме Бойса – Кодда и не содержит нетривиальных многозначных зависимостей, равно как и нефункциональных многозначных зависимостей. Экзаменационный билет № 3
SELECT — осуществляет выборку данных из таблиц по запросу. SELECT */{DISTINCT/ALL]<список полей>.,…} FROM {<имя таблицы>/[<алиас>]}.,... [WHERE <предикат> GROUP BY {<имя столбца>/<целое>}, .. HAVING <предикат> ORDER BY {<имя столбца>/<целое>}.,..] Оператор IN используется для сравнения некоторого значения со списком заданных значений, при этом проверяется, соответствует ли результат вычисления выражения одному из значений в предоставленном списке. При помощи оператора IN может быть достигнут тот же результат, что и в случае применения оператора OR, однако оператор IN выполняется быстрее. NOT IN используется для отбора любых значений, кроме тех, которые указаны в представленном списке. IN – “принадлежит” Пример. Вывести список клиентов из Москвы или из Самары: SELECT column_name FROM table_name WHERE column_name IN (value1,value2,..); SELECT Фамилия, ГородКлиента FROM Клиент WHERE ГородКлиента IN ("Москва", "Самара") Простые вложенные подзапросы используются для представления множества значений, исследование которых должно осуществляться в каком-либо предикате IN, что иллюстрируется в следующем примере: выдать название и статус поставщиков продукта с номером 11, т.е. помидоров.  SELECT Название, Статус FROM Поставщики WHERE ПС IN ( SELECT ПС FROM Поставки WHERE ПР = 11 ) Подзапрос с несколькими уровнями вложенности можно проиллюстрировать на том же примере. Пусть требуется узнать не поставщиков продукта 11, как это делалось в предыдущих запросах, а поставщиков помидоров, являющихся продуктом с номером 11. Для этого можно дать запрос SELECT Название, Статус FROM Поставщики WHERE ПС IN ( SELECT ПС FROM Поставки WHERE ПР IN ( SELECT ПР FROM Продукты WHERE Продукт = 'Помидоры' )); Коррелированный подзапрос - это такой подзапрос, результат которого зависит от некоторой переменной. Эта переменная принимает свое значение в некотором внешнем запросе. Обработка такого подзапроса, следовательно, должна повторяться для каждого значения переменной в запросе, а не выполняться раз навсегда. Выдать название и статус поставщиков продукта с номером 11. SELECT Название, Статус FROM Поставщики WHERE 11 IN ( SELECT ПР FROM Поставки WHERE ПС = Поставщики.ПС );
Нормальная форма — свойство отношения в реляционной модели данных, характеризующее его с точки зрения избыточности, которая потенциально может привести к логически ошибочным результатам выборки или изменения данных. Нормальная форма определяется как совокупность требований, которым должно удовлетворять отношение. Процесс преобразования базы данных к виду, отвечающему нормальным формам, называется нормализацией. Нормализация предназначена для приведения структуры базы данных к виду, обеспечивающему минимальную избыточность, то есть нормализация не имеет целью уменьшение или увеличение производительности работы или же уменьшение, или увеличение объёма БД. Конечной целью нормализации является уменьшение потенциальной противоречивости хранимой в БД информации. Цель нормализации - минимизировать повторения данных и возможные структурные изменения БД при процедурах обновления. Это достигается разделением (декомпозицией) одной таблицы в две или несколько с последующим использованием при запросах операции навигации. Функциональная зависимость - в отношении R атрибут Y функционально зависит от атрибута X (X и Y могут быть составными) в том и только в том случае, если каждому значению X соответствует в точности одно значение Y: R.X (r) R.Y. Множество атрибутов X называется детерминантом функциональной зависимости, а множество атрибутов Y называется зависимой частью. Функциональная зависимость атрибутов утверждает лишь то, что для каждого конкретного состояния базы данных по значению одного атрибута (детерминанта) можно однозначно определить значение другого атрибута (зависимой части). Но конкретные значение зависимой части могут быть различны в различных состояниях базы данных. ПЕРВАЯ ФОРМА − Отношение R находится в первой нормальной форме (1НФ), если значения каждого его атрибута являются атомарными, т.е. такими значениями, которые не являются множеством значений или повторяющейся группой. В определении реляционной модели Кодда все отношения всегда находятся в 1НФ. Каждый атрибут отношения должен хранить одно-единственное значение и не являться ни списком, ни множеством значений. ВТОРАЯ ФОРМА − Отношение R находится во второй нормальной форме (2НФ), если никакие не ключевые атрибуты не являются функционально зависимыми лишь от части ключа. Таким образом, 2НФ может оказаться нарушена только в том случае, когда ключ составной. Каждый не ключевой столбец в таблице должен уникально идентифицироваться по первичному ключу ТРЕТЬЯ ФОРМА − Отношение R находится в третьей нормальной форме (3NF) в том и только в том случае, если находится в 2NF и каждый не ключевой атрибут не транзитивно зависит от первичного ключа. Кроме удовлетворения требованиям второй нормальной формы, каждый не ключевой столбец таблицы должен быть независимым от других не ключевых столбцов |