Курсовая Гущин. Статические и динамические данные по идентификаторам программы при лексическом анализе
 Скачать 192.58 Kb. Скачать 192.58 Kb.
|

|
МИНИСТЕРСТВО ТРАНСПОРТА РОССИЙСКОЙ ФЕДЕРАЦИИ ФЕДЕРАЛЬНОЕ АГЕНТСТВО ЖЕЛЕЗНОДОРОЖНОГО ТРАНСПОРТА ФЕДЕРАЛЬНОЕ ГОСУДАРСТВЕННОЕ БЮДЖЕТНОЕ ОБРАЗОВАТЕЛЬНОЕ УЧРЕЖДЕНИЕ ВЫСШЕГО ПРОФЕССИОНАЛЬНОГО ОБРАЗОВАНИЯ САМАРСКИЙ ГОСУДАРСТВЕННЫЙ УНИВЕРСИТЕТ ПУТЕЙ СООБЩЕНИЯ Кафедра «Мехатроника, автоматизация и управление на транспорте»Курсовая работа по дисциплине «Системное программное обеспечение» Направление подготовки 09.03.01 Тема: «Статические и динамические данные по идентификаторам программы при лексическом анализе» Выполнил: обучающийся гр. ИВТ-91 Малышев А. А. Проверил: доц. Гущин А. В. Самара 2022 СамГУПС кафедра МАУТ ЗАДАНИЕ НА КУРСОВУЮ РАБОТУ Обучающемуся (ФИО) _________________________________________________________________ по дисциплине «Системное программное обеспечение» курс 3, группа ИВТб-91, направление подготовки 09.03.01 "Информатика и вычислительная техника" Тема курсовой работы _________________________________________________________________ _________________________________________________________________ Срок сдачи законченной работы 28.04.202----__ Исходные данные Компилятор исполнительной программы _________________________ Лексический набор данных языка транслятора Строка транслируемой пользовательской программы __________________________________________________________________ __________________________________________________________________ Состав курсовой работы Описание теории трансляторов входных языков. Предметные области применения трансляторов. Системные процессы, связанные с трансляторами. Разработка структурной схемы взаимодействия подсистем транслятора. Обоснование выбора технического обеспечения, языка программирования с описанием возможностей языка по организации динамических структур памяти, связанных списков (цепочек), ветвлений (деревьев). Построение бинарных деревьев идентификаторов языка и идентификаторов пользовательской программы. Хэш-функции, статическая и динамическая таблица адресации. Лексический анализатор вводимой пользователем строки программного кода. Литература А. Ю. Молчанов. Системное программное обеспечение : Учебник для ВУЗов. 3-е изд. – СПБ.: Питер, 2010. – 400 с. : ил. А. Ю. Молчанов. Системное программное обеспечение. Лабораторный практикум. – СПБ.: Питер, 2005. – 284 с. : ил. Подпись студента ________________/_____________________/ Подпись преподавателя ________________/ Гущин А. В. / Дата 1.Бинарные деревья поиска и рекурсияБинарное дерево — это иерархическая структура данных, в которой каждый узел имеет значение (оно же является в данном случае и ключом) и ссылки на левого и правого потомка. Узел, находящийся на самом верхнем уровне (не являющийся чьим-либо потомком), называется корнем. Узлы, не имеющие потомков, называют листьями. 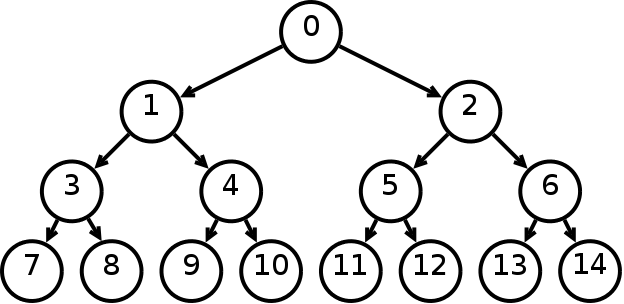 Рисунок 1- Бинарное деревно. Бинарное дерево поиска — это бинарное дерево, обладающее дополнительными свойствами: значение левого потомка меньше значения родителя, а значение правого потомка больше значения родителя для каждого узла дерева. То есть, данные в бинарном дереве поиска хранятся в отсортированном виде. При каждой операции вставки нового или удаления существующего узла отсортированный порядок дерева сохраняется. При поиске элемента сравнивается искомое значение с корнем. Если искомое больше корня, то поиск продолжается в правом потомке корня, если меньше, то в левом, если равно, то значение найдено и поиск прекращается. Сбалансированное бинарное дерево поиска — это бинарное дерево поиска с логарифмической высотой. Данное определение скорее идейное, чем строгое. Строгое определение оперирует разницей глубины самого глубокого и самого неглубокого листа (в AVL-деревьях) или отношением глубины самого глубокого и самого неглубокого листа (в красно-черных деревьях). 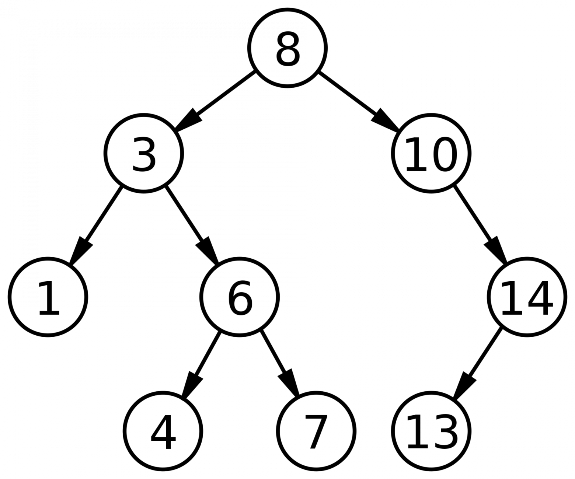 Рисунок 2- Сбалансированное бинарное дерево поиска Сбалансированное бинарное дерево поиска применяется, когда необходимо осуществлять быстрый поиск элементов, чередующийся со вставками новых элементов и удалениями существующих. В случае, если набор элементов, хранящийся в структуре данных фиксирован и нет новых вставок и удалений, то массив предпочтительнее. Потому что поиск можно осуществлять алгоритмом бинарного поиска за то же логарифмическое время, но отсутствуют дополнительные издержки по хранению и использованию указателей. Например, в С++ ассоциативные контейнеры set и map представляют собой сбалансированное бинарное дерево поиска. 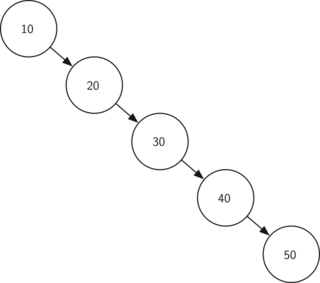 Рисунок3 - Экстремально несбалансированное бинарное дерево поиска Рекурсия в программировании – это вызов функцией самой себя с другими аргументами. В принципе, рекурсивная функция может вызывать сама себя и с теми же самыми аргументами, но в этом случае будет бесконечный цикл рекурсии, который закончится переполнением стека. Внутри любой рекурсивной функции должен быть базовый случай, при котором происходит выход из функции, а также вызов или вызовы самой себя с другими аргументами. Аргументы не просто должны быть другими, а должны приближать вызов функции к базовому случаю. 2 . Концепции хешированияМетод организации хэш-файлов - это метод, при котором данные хранятся в блоках данных, адрес которых генерируется с помощью хэш-функции. Ячейка памяти, в которой хранятся эти записи, называется блоком данных или ведром данных. Это хранилище данных способно хранить одну или несколько записей. Хэш-функция может использовать любое значение столбца для генерации адреса. В большинстве случаев хеш–функция использует первичный ключ для генерации хеш-индекса - адреса блока данных. Хэш-функция может быть простой математической функцией для любой сложной математической функции. Мы даже можем рассматривать сам первичный ключ как адрес блока данных. Это означает, что каждая строка будет храниться в блоке данных, адрес которого будет совпадать с первичным ключом. Это подразумевает, насколько простой может быть хэш-функция в базе данных. 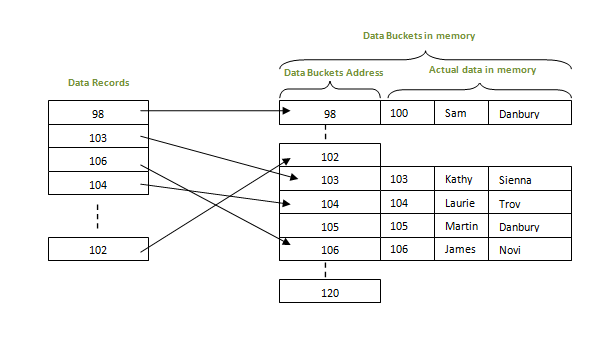 Рисунок 3- Хэш функция На приведенной выше диаграмме показан адрес блока данных, такой же, как и значение первичного ключа. Эта хэш-функция также может быть простой математической функцией, такой как mod, sin, cos, экспоненциальная и т. Д. Представьте, что у нас есть хэш-функция mod (5) для определения адреса блока данных. Так что же происходит с приведенным выше случаем? Он применяет mod (5) к первичным ключам и генерирует 3,3,1,4 и 2 соответственно, а записи хранятся в этих адресах блоков данных. 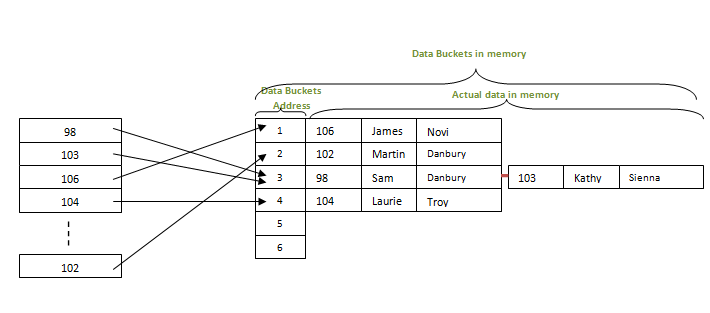 Pin PinИз приведенных выше двух диаграмм теперь ясно, как работает хэш-функция. Существует два типа организации хэш–файлов - статическое и динамическое хэширование. Статическое хеширование В этом методе хеширования результирующий адрес корзины данных всегда будет одинаковым. Это означает, что если мы хотим сгенерировать адрес для EMP_ID = 103 с помощью хэш-функции mod (5), это всегда приводит к одному и тому же адресу ведра 3. Здесь не будет никаких изменений в адресе корзины. Следовательно, количество ведер данных в памяти для этого статического хеширования остается постоянным во всем. В нашем примере у нас будет пять ведер данных в памяти, используемой для хранения данных. 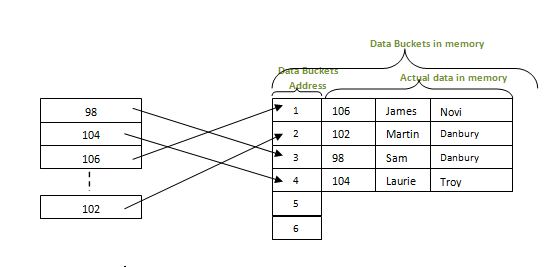 Двойное хеширование – это также еще один метод линейного зондирования. Здесь разница фиксируется, как при линейном зондировании, но эта фиксированная разница вычисляется с помощью другой хэш-функции. Отсюда и название - двойное хеширование. Динамическое хеширование – этот метод хеширования используется для преодоления проблемы статического хеширования – переполнения ведра. При этом методе хеширования ведра данных растут или сжимаются по мере увеличения или уменьшения количества записей. Этот метод хеширования также известен как расширяемый метод хеширования. Давайте рассмотрим пример, чтобы понять этот метод. Рассмотрим, что в таблице есть три записи R1, R2 и R4. Эти записи генерируют адреса 100100, 010110 и 110110 соответственно. Этот метод хранения учитывает только часть этого адреса – особенно только первый бит для хранения данных. Поэтому он пытается загрузить три из них по адресам 0 и 1. 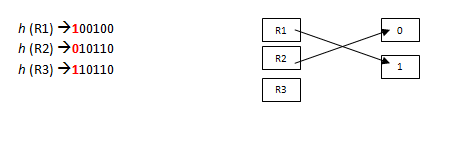 Рисунок 4- Динамическое хэширование Недостатки динамического хеширования По мере увеличения размера данных увеличивается и размер ведра. Эти адреса будут храниться в таблицах адресов ведра. Это связано с тем, что адрес данных будет постоянно меняться по мере роста и сокращения ведер. Когда происходит огромное увеличение объема данных, ведение этой адресной таблицы становится утомительным. В этом случае также произойдет ситуация переполнения ведра. Но для достижения этой ситуации может потребоваться меньше времени, чем статическое хеширование. 3. Схема работы транслятора Каждая вычислительная машина имеет свой собственный язык программирования – язык команд или машинный язык – и может исполнять программы, записанные только на этом языке. С помощью машинного языка, в принципе, можно описать любой алгоритм, но затраты на программирование будут чрезвычайно велики. Это обусловлено тем, что машинный язык позволяет описывать и обрабатывать лишь примитивные структуры данных – бит, байт, слово. Программирование в машинных кодах требует чрезмерной детализации программы и доступно лишь программистам, хорошо знающим устройство и функционирование ЭВМ. Преодолеть эту трудность и позволили языки высокого уровня (Фортран, ПЛ/1, Паскаль, Си, Ада и др.) с развитыми структурами данных и средствами их обработки, не зависящими от языка конкретной ЭВМ. Алгоритмические языки высокого уровня дают возможность программисту достаточно просто и удобно описывать алгоритмы решения многих прикладных задач. Такое описание называют исходной программой, а язык высокого уровня — входным языком. Языковым процессором называют программу на машинном языке, позволяющую вычислительной машине понимать и выполнять программы на входном языке. Различают два основных типа языковых процессоров: интерпретаторы и трансляторы. Интерпретатор – это программа, которая в качестве входа допускает программу на входном языке и по мере распознавания конструкций входного языка реализует их, выдавая на выходе результаты вычислений, предписанные исходной программой. Транслятор – это программа, которая допускает на входе исходную программу и порождает на своем выходе программу, функционально-эквивалентную исходной, называемую объектной. Объектная программа записывается на объектном языке. В частном случае, объектным языком может служить машинный язык, и в этом случае, полученную на выходе транслятора программу можно сразу же выполнить на ЭВМ (проинтерпретировать). При этом ЭВМ является интерпретатором объектной программы в машинных кодах. В общем случае объектный язык не обязательно должен быть машинным или близким к нему (автокодом). В качестве объектного языка может служить некоторый промежуточный язык – язык, лежащий между входным и машинным языками. Если в качестве объектного языка используется промежуточный язык, то возможны два варианта построения транслятора. • Первый вариант – для промежуточного языка имеется (или разрабатывается) другой транслятор с промежуточного языка на машинный, и он используется в качестве последнего блока проектируемого транслятора. • Второй вариант построения транслятора с использованием промежуточного языка – построить интерпретатор команд промежуточного языка и использовать его в качестве последнего блока транслятора. Преимущество интерпретаторов проявляется в отладочных и диалоговых трансляторах, обеспечивающих работу пользователя в диалоговом режиме, вплоть до внесений изменений в программу без ее повторной полной перетрансляции. Интерпретаторы используются также и при эмуляции программ – исполнении на технологической машине программ, составленных для другой (объектной) машины. Данный вариант, в частности, используется при отладке на универсальной ЭВМ программ, которые будут выполняться на специализированной ЭВМ. Транслятор, использующий в качестве входного языка язык, близкий к машинному (автокод или ассемблер), традиционно называют ассемблером. Транслятор для языка высокого уровня называют компилятором. Фактическим выходом синтаксического анализа может быть последовательность команд, необходимых для того, чтобы строить промежуточную программу, обращаться к таблицам справочника, выдавать, когда это требуется, диагностическое сообщение. 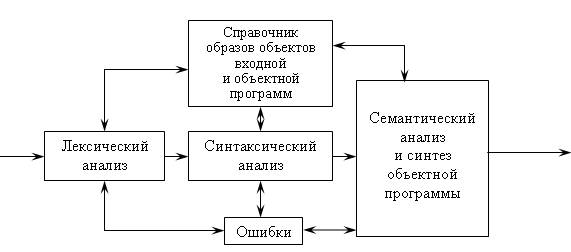 Рисунок 5- Упрощенная функциональная модель транслятора Синтез объектной программы начинается, как правило, с распределения и выделения памяти для основных программных объектов. Затем производится исследование каждого предложения исходной программы и генерируется семантически эквивалентные предложения объектного языка. В качестве входной информации здесь используется синтаксическое дерево программы и выходные таблицы лексического анализатора – таблица идентификаторов, таблица констант и другие. Анализ дерева позволяет выявить последовательность генерируемых команд объектной программы, а по таблице идентификаторов определяются типы команд, которые допустимы для значений операндов в генерируемых командах (например, какие требуется породить команды: с фиксированной или плавающей точкой и т.д.). Непосредственно генерации объектной программы часто предшествует семантический анализ, который включает различные виды семантической обработки. Один из видов – проверка семантических соглашений в программе. Примеры таких соглашений: единственность описания каждого идентификатора в программе, определение переменной производится до ее использования и т.д. Семантический анализ может выполняться на более поздних фазах трансляции, например, на фазе оптимизации программы, которая тоже может включаться в транслятор. Цель оптимизации – сокращение временных ресурсов или ресурсов оперативной памяти, требуемых для выполнения объектной программы. Таковы основные аспекты процесса трансляции с языков высокого уровня. Подробнее организация различных фаз трансляции и связанные с ними практические способы их математического описания рассматриваются ниже. ЗАКЛЮЧЕНИЕ Решение задач в объеме курсовой работы по курсу «Курс» закрепляет теоретические и практические знания и навыки самостоятельного решения. Поставленная цель достигнута с теоретическим обзором проблемы автоматизации и практическим решением по моделям с использованием производственных функций. В процессе решения поставленных задач изучались и анализировались следующие дисциплинарные темы: производственные функции и их роль в автоматизированных системах; методы линейного программирования; методы нелинейного программирования; задачи оптимизации с седловой функцией; построение нелинейных регрессионных зависимостей. СПИСОК ИСПОЛЬЗОВАННЫХ ИСТОЧНИКОВ 1. Основная литература 1.1 А. Ю. Молчанов. Системное программное обеспечение : Учебник для ВУЗов. 3-е изд. – СПБ.: Питер, 2010. – 400 с. : ил. 1.2 А. Ю. Молчанов. Системное программное обеспечение. Лабораторный практикум. – СПБ.: Питер, 2005. – 284 с. : ил. 1.3 https://libraryno.ru/1-1-shema-raboty-translyatora-petrova_tyap_ch1/ 1.4 https://www.tutorialcup.com/dbms/hashing-concepts.htm 1.5 https://habr.com/ru/post/267855/ Добавить алгоритмы И деревья |