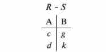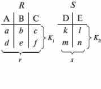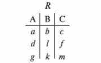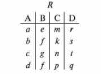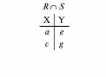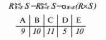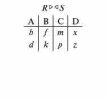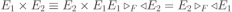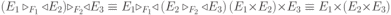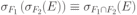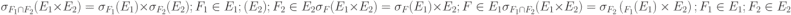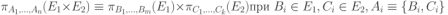Проетирование РЭС. Тема Сущность процесса проектирования
 Скачать 1.67 Mb. Скачать 1.67 Mb.
|

Тема 10. Информационное обеспечение САПРНазначение, сущность и составные части информационного обеспечения (ИО) САПРОсновное назначение ИО САПР — уменьшение объемов информации, требуемой в процессе проектирования от разработчика РЭС, иисключение дублирования данных в прикладном, программном и техническом обеспечении САПР [7]. ИО САПР состоит из описания стандартных проектных процедур, типовых проектных решений, типовых элементов РЭС, комплектующих изделий и их моделей, материалов, числовых значений параметров и других данных. Эти данные в закодированной форме записываются на машинных носителях: магнитных лентах и магнитных дисках. Кроме того, в ИО САПР входят правила и нормы проектирования, содержащиеся в соответствующей нормативно-технической документации, а также информация о правилах документирования результатов проектирования. Структура и содержание ИО САПР, а также характер его использования зависят от степени развития банка данных. Данные ИО обычно группируются в отдельные массивы, каждый из которых относится к определенному объекту описания. Такие массивы называются файлами. Вся совокупность файлов образует базу данных, которую можно многократно использовать при проектировании различных РЭС для различных этапов и уровней. Для создания, расширения, корректировки и коллективного использования данных создаются специальные системы управления базами данных (СУБД). Совокупность баз данных, систем управления файлами, а также относящихся к ним программных, языковых, технических и организационных средств называется банком данных. Следовательно, банки данных (БНД) являются составной частью ИО САПР и состоят из баз данных (БД) и систем управления базами данных (СУБД). БНД создаются как обслуживающие подсистемы САПР и предназначены для автоматизированного обеспечения необходимыми данными проектирующих подсистем САПР.По назначению СУБД является элементом информационного обеспечения, так как организует автоматизированное обеспечение проектировщика информацией, а по содержанию это комплекс программ, то есть элемент программного обеспечения. Состав БД определяют с учетом характеристик объектов проектирования (технических, метрологических, эксплуатационных), характеристик процесса проектирования (типовые проектные решения, описания технологических операций с вариантами их реализации), действующих нормативных и справочных данных, ранее созданных в организации информационных массивов. Основные требования к базам данных: установление многосторонних связей по производительности — пропускной способности; минимальная избыточность по затратам на создание и эксплуатацию БД; целостность и возможность поиска данных; безопасностьи секретность от несанкционированного доступа; связь с разработанными и проектируемыми БД; простота; возможность настройки и перемещения данных. Последние требования составляют концепцию автоматизированных информационных систем, обладающих адаптацией СУБД к данной предметной области с учетом динамики ее развития. База данных характеризуется двумя аспектами: информационным и манипуляционным. Первый отражает структуру данных, наиболее подходящую для данной предметной области; второй — действия над структурами данных: выборку, добавление, удаление, обновление и преобразование данных. При построении БД должен выполняться принцип информационного единства, то есть должны применяться термины, символы, условные обозначения, проблемно-ориентированные языки и другие способы представления информации, принятые в САПР. В качестве основных логических структур баз данных могут использоваться: иерархическая, сетевая, реляционная, смешанная (представляющая собой различные сочетания перечисленных выше структур). Содержание, структура и организация использования БД должны обеспечивать: объединение любого числа БД любого объема, допускающее совместное использование общих данных различными подсистемами САПР для разных задач; возможность наращивания БД, достоверность и непротиворечивость данных, минимальный объем памяти ЭВМ для их хранения; защиту и регулирование возможности доступа к БД ; многократное использование данных. Проблема согласования программ является прежде всего проблемой выбора структур данных и массивов в памяти ЭВМ. Если программы рассчитаны на работу с общими данными, сгруппированными по-разному, то такие программы не являются информационно согласованными и не могут непосредственно войти в сочетание программ, обслуживающих некоторый маршрут проектирования. Для обеспечения взаимодействия программ в маршрутах необходимо их информационное согласование, то есть приспособление к работе с информационными массивами одинаковой структуры. Информационная согласованность программ обеспечивается построением общей для согласуемых программ БД, то есть совокупности всех тех данных, которые обрабатываются в более чем одной программе (модуле). В БД можно выделить части, играющие различную роль в процессе проектирования. Первая часть — СПРАВОЧНИК — содержит справочные данные о ГОСТах, нормалях, унифицированных элементах, ранее выполненных типовых проектах. Эта часть изменяется наименее часто, характеризуется однократной записью и многократным считыванием и называется постоянной частью БД. Вторая часть — ПРОЕКТ — содержит сведения об аппаратуре, находящейся в процессе проектирования. В нее входят результаты решения проектных задач, полученные к текущему моменту (различного типа схемы, спецификации, таблицы соединений, тесты). ПРОЕКТ пополняется или изменяется по мере завершения очередных итераций на этапах проектирования и составляет полупеременную часть БД. Часто СПРАВОЧНИК и ПРОЕКТ объединяют под общим названием АРХИВ. Третья часть БД содержит массивы переменных, значения которых важны только в процессе совместного решения двумя (или более) программами конкретной задачи проектирования. Это переменная часть БД. Первый способ информационного согласования программ — построение централизованной БД, общей для всех модулей программного обеспечения ( рис. 16). В соответствии с этим способом при создании САПР сначала разрабатывается БД, а затем — программное обеспечение. Реализация централизованной БД — сложная задача, т. к. выбранная структура БД не всегда может обеспечить реализацию всех необходимых маршрутов проектирования. Например, ранее принятая структура БД может не удовлетворять требованиям новых элементов информационного и программного обеспечения. Поэтому второй способ информационного согласования программ — построение системы, в которой несколько частных баз данныхсопрягаются с помощью специального программного интерфейса, как показано на рис. 17. Интерфейс представляет собой программы перекомпоновки информационных массивов из форматов и структур одной БД в форматы и структуры, принятые в другой БД. Основные операции в БД — выборка данных прикладными программами, запись новых данных, удаление старых ненужных записей, перезапись файлов с одних машинных носителей на другие и так далее. Для выполнения большинства из этих операций требуется специальное программное обеспечение. 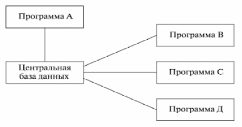 Рис. 16. Структура программного обеспечения при централизованной БД 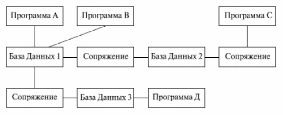 Рис. 17. Структура программного обеспечения при частных БД Совокупность программ, обслуживающих БД, называется системой управления базой данных СУБД. БД и СУБД вместе образуютБАНК ДАННЫХ. Логическое представление БД отображает только состав сведений и связи между элементами сведений, хранящихся в БД. Физическое представление БД отображает способ расположения информации на машинных носителях. Структуру БД можно представить в виде графа. Каждая вершина графа отображает группу однотипных записей (группы взаимосвязанных элементов данных), то есть каждой вершине можно поставить в соответствие таблицу, содержащую конкретные значения (экземпляры) записей. БД, для логического представления которых используются графы, называют СЕТЕВЫМИ. Обычно в сетевых БД в графах, изображающих структуру, можно указать те или иные циклы. В частном случае сетевых БД граф может представлять собой дерево. В частности, если устранить из БД все сведения, кроме одного номинального, то структура представляется деревом. Такую структуру называют ДРЕВОВИДНОЙ или ИЕРАРХИЧЕСКОЙ. Реализация древовидной структуры проще, чем сетевой структуры общего вида, однако чаще реальные данные имеют сложные сетевые структуры. Наряду с сетевым подходом к представлению БД существует другой подход, основанный на операции нормализации структуры. Этот подход приводит к логическому представлению БД в виде совокупности таблиц. Такие базы данных базы данных называютРЕЛЯЦИОННЫМИБ БД. Реляционная БД представляет собой совокупность таблиц при условии, что сведения о связях между таблицами удается включить в сами эти таблицы. Включение таких сведений обеспечивается нормализацией. Сетевые и реляционные базы данных имеют свои преимущества и недостатки. В настоящее время развиваются оба направления в логической организации БД. Уровни представления данныхСуществует три уровня представления данных: уровень пользователя (предметная область), логический и физический. Каждый объект предметной области характеризуется своими атрибутами, каждый атрибут имеет имя и значение. Например, объектосциллограф. Имена его атрибутов — частота повторения, чувствительность, полоса пропускания; значения атрибутов — соответствующие значения параметров. Или объект транзистор, имена его атрибутов — наименования параметров, значения атрибутов — значения параметров и т. д. Логический (концептуальный) уровень — это абстрактное представление (абстрактный уровень) данных, независимое от представления в ЭВМ. Физический уровень — это практическая реализация базы данных на том или ином носителе в ЭВМ. Сюда входят и программные средства управления этими носителями. Связь между этими тремя уровнями представления данных показана в таблице 1.
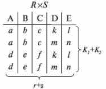
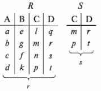
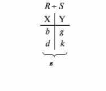
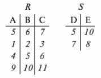
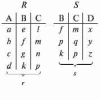
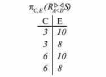
Вся совокупность информации, описывающей один объект предметной области на логическом уровне, называется записью. Записьполностью характеризует объект и все его атрибуты. Совокупность записей об одной и той же категории объектов образует файл. Запись состоит из полей, каждое поле соответствует одному из атрибутов. Содержание поля описывает имя и значение соответствующего атрибута. На физическом уровне каждой записи соответствует одна ячейка — область памяти на том или ином носителе, размер которой должен быть достаточен для хранения записи. Каждому полю, описывающему атрибут объекта, соответствует элемент на конкретном носителе; элемент может быть разделен на сегменты. Совокупность ячеек образует список, соответствующий одному файлу на логическом уровне. Каждая ячейка имеет ключевое поле; если номера ячеек возрастают, то файл называют ранжированным. Бывают пустые ячейки; тогда список называют неплотным. Совокупность файлов на логическом уровне называют библиотекой, соответствующей конкретной рассматриваемой предметной области. На физическом уровне библиотеке соответствует база данных. На логическом уровне данные могут быть представлены тремя способами. В настоящее время существует три модели данных: реляционная, сетевая и иерархическая. В основу реляционной модели положено понятие теоретико-множественного отношения (реляции), которое представляется в виде таблицы. Она является наиболее удобным инженерным представлением для пользователя (рис. 18 а). Каждый столбец ее соответствует атрибуту объекта, и ему присваивается соответствующее имя. В столбцах таблицы (отношения) вводятся значения атрибутов. Используя отношения связи и язык реляционной алгебры, можно осуществлять выбор любого подмножества информации: по строкам, столбцам или другим признакам. Применяя операции "разрезания" и "склеивания" отношений, можно получить разнообразные файлы в нужной форме (рис. 18 б). При использовании реляционной модели атрибут объекта может сам выступать как объект другой предметной области, т.е. задействуется относительность (отсюда — отношение) понятий объекта и его атрибутов. Иерархическая модель данных — это некоторая их совокупность, состоящая из отдельных деревьев, в которых все связи направлены от одного сегмента, называемого исходным, к нескольким порожденным, т. е. реализуются связи типа "один ко многим" (рис. 19 а). Сегмент — это одно или несколько полей, являющихся основной единицей обмена между прикладной программой и языком описания данных. При реализации иерархической системы каждое дерево описывается в виде отдельного файла данных. Сетевая модель данных является более общей структурой по сравнению с иерархической. Каждый отдельный сегмент (ячейка) может иметь произвольное число непосредственных исходных (старших) сегментов, а также и произвольное число порожденных (младших) (рис. 19 б). 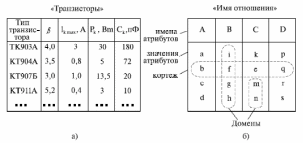 Рис. 18. Пример (а) и общий вид (б) реляционной модели данных Это обеспечивает представление отношения "многие к многим". Сетевые структуры могут быть описаны с помощью раскрашенныхфайлов. 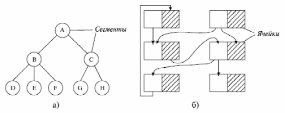 Рис. 19. Иерархическая (а) и сетевая (б) модели данных Модели данных необходимо сравнивать по следующим показателям: легкость применения для программиста и пользователя, эффективность реализации по объему памяти и времени поиска информации. Наиболее легка в использовании реляционная модель; сетевая требует от программиста и пользователя понимания типов записей, связей и их отношений. В то же время сетевая и иерархическая модели возникли исторически раньше и реализованы на языках низкого уровня (Ассемблер, Макрокод и др.). Примеры сетевых БД — КОДАСИЛ — ADABAS, Квант и др.; иерархической — IMS. Реляционные базы данных реализованы на языках высокого уровня и в ряде стран приняты в качестве национального стандарта. К ним относятся ALPHA, QBE, RISS, SEQVEI, dBASE, FRAMEWORK. Проектирование базы данныхПроцесс разработки структуры БД на основании требований пользователя называют проектированием БД (ПБД). Результатами ПБД являются структура БД, состоящая из логических и физических компонент, и руководство для прикладных программистов. Развитие системы БД во времени называют жизненным циклом. Последний делится на стадии анализа, проектирования и эксплуатации. Первая стадия включает в себя этапы формулирования и анализа требований, концептуального проектирования, проектирования реализации, физического проектирования. Анализ требований является полностью неформализованным этапом. Его основная цель — обеспечить согласованность целей пользователей и представлений об информационных потоках. Вторая стадия состоит из этапов реализации БД, анализа функционирования и поддержки, модификации и адаптации. Концептуальное проектирование обеспечивает выбор структуры организации информации на основе объединения информационных требований пользователей. Проектирование реализации (логическое проектирование) разделяют на две части: проектирование базы данных и проектирование программ. Результатом первой части является логическая структура БД. Результатом второй части считают функциональные описания программных модулей и наборы запросов к БД. Физическое проектирование разделяют также на две части: выбор физической структуры БД и отладку программных модулей, полученных при проектировании программ. Результатом этапа является подготовка к эксплуатации БД. На этапе реализации БД ставится задача разработки программ доступа к БД. Этап анализа функционирования и поддержки обеспечивает статистическую обработку данных о функционировании системы. Восстановление БД и ее целостности после сбоев обеспечивает поддержка БД. Этап модернизации и адаптации позволяет производить изменения, оптимизацию функционирования, модификацию программ. Языки, используемые в БД, делят на языки описания данных (ЯОД) и языки манипулирования данными (ЯМД). В общем случае ЯОД описывает различные типы записей, их имена и форматы, а также служит для определения: типов элементов данных, которые нужны в качестве ключей; отношений между записями или их частями и именования этих отношений; типа данных, которые используются в записях; диапазона их значений; числа элементов, их порядка и т. п.; секретности частей данных и режимов доступа к ним. Различают три уровня абстракции для описания данных: концептуальный (с позиции администратора); реализации (с позиции прикладного программиста и пользователя; физический (с позиции системного программиста). На концептуальном уровне описывают объекты, атрибуты и значения данных. На уровне реализации имеют дело с записями, элементами данных и связями между записями. На физическом уровне оперируют блоками, указателями, данными переполнения, группировкой данных. Обычно ЯМД дают возможность манипулирования данными без знания несущественных для программиста подробностей. Они могут реализоваться как расширение языков программирования общего назначения путем введения в них специальных операторов или путем реализации специального языка. При работе с БД используются несколько типов языков: манипулирования данными; программирования; описания физической организации данных. Языки программирования, применяемые в БД, представляют собой распространенные языки типа ФОРТРАН, КОБОЛ и многие новые языки. Языки описания логических схем пользователя реализуются средствами описания данных языка прикладного программирования, средствами СУБД, специальным языком. Наиболее широко распространен первый способ описания. Он имеет в основе операторы объявления (например, DECLARE в языкеPL/I, STRUCT в СИ, type в ADA). Языки описания схем БД предназначены для администратора БД. С их помощью определяют глобальные описания данных. Языки описания физической организации данных описывают физическую структуру размещения схемы на машинных носителях. С их помощью определяют методы доступа, предписывающие размещение данных на тех или иных носителях, и т. п. Наибольшими преимуществами обладают специальные языки, так как они не зависят от используемых языков программирования или технических средств. Следовательно, при переносе БД на другое ТО или смене языка программирования большинство описаний БДостанется без изменения. Процесс проектирования БД начинают с построения концептуальной модели (КМ). Концептуальная модель состоит из описания объектов и их взаимосвязей без указания способов физического хранения. Построение КМ начинается с анализа данных об объектах и связях между ними, сбора информации о данных в существующих и возможных прикладных программах. Другими словами, КМ — это модель предметной области. Версия КМ, обеспечиваемая СУБД, называется логической моделью (ЛМ). Подмножества ЛМ, которые выделяются для пользователей, называются внешними моделями (подсхемами). Логическая модель отображается в физическую, которая отображает размещение данных и методы доступа. Физическую модель называют еще внутренней. Внешние модели не связаны с используемыми ТС и методами доступа к БД. Они определяют первый уровень независимости данных. Второй уровень независимости данных связан с отсутствием изменений внешних моделей при изменении КМ. Важным инструментом при разработке и проектировании БД является словарь данных (СД), предназначенный для хранения сведений об объектах, атрибутах, значениях данных, взаимосвязях между ними, их источниках, значениях, форматах представления. Словарь данных позволяет получить однообразную и формализованную информацию обо всех ресурсах данных. Главное назначение СД состоит в документировании данных. Он должен обеспечивать централизованное введение и управление данными, взаимодействие между разработчиками любого проекта, например САПР. Существуют интегрированные и независимые СД. В первом случае СД — это часть пакета программ СУБД, а во втором — отдельный пакет программ в виде дополнения к СУБД. В настоящее время СД рассматривают как связующее звено в системе ПО обработки данных, включающей в себя процессор, СУБД, языки запросов, монитор телеобработки. В полном объеме СД обязан: поддерживать КМ, логическую, внутреннюю и внешнюю модели; быть интегрированным с СУБД, поддерживать тестовые и рабочие версии хранимых описаний; обеспечивать эффективный обмен информацией с СУБД и процесс изменения рабочей версии при изменении БД. Словарь данных должен иметь свою БД. Основные составляющие БД словаря данных: атрибут; объект; групповой элемент данных; выводимый объект данных; синонимы, т. е. атрибуты, имеющие одинаковое назначение, но различные идентификаторы; омонимы, т. е. атрибуты с различным назначением, но с одинаковыми идентификаторами; описание КМ, ЛМ, внешних и внутренних моделей; описание, позволяющее пользователям формально и однозначно выбирать атрибуты для решения задач. Контрольные вопросы и упражненияЧто такое система данных? Определите предметную область, объект, атрибут (элемент данных), значения данных и постройте таблицы связи между ними. Что такое идентификаторы объекта и ключевые атрибуты? Что такое запись данных? Приведите примеры. Что такое файл данных (набор данных)? Приведите пример взаимно однозначного соответствия между прикладными программами логического проектирования и файлами данных. Какие проблемы возникают при обработке данных с несколькими файлами? Приведите известные определения базы данных (БД). В чем сходство и различие между БД и файлом? Приведите основные определения системы управления базами данных (СУБД). Опишите основные функции СУБД и требования к ним. В чем заключается информационная согласованность в САПР? Что такое функция администрирования БД и кто такой администратор БД (АБД)? Какие функции выполняет АБД? Что такое независимость данных? Какие языки используются в БД? Что такое концептуальная модель (КМ)? Приведите определение логической, внешней, внутренней (физической) моделей. Что такое независимость данных? Опишите иерархическую модель данных (ИМД). Постройте пример. Опишите сетевую модель данных (СМД) и постройте пример. Опишите реляционную модель данных (РМД) и постройте пример. Реляционная модель баз данныхРеляционная база данных, разработанная Э.Ф. Коддом (Е. F. Codd) в 1970 г., – это конечный набор конечных отношений (таблиц) вида рис. 10.3,б. Над отношениями можно осуществлять различные алгебраические операции. Тем самым теория реляционных баз данных становится областью приложения математической логики и современной алгебры и опирается на точный математический формализм. Каждое отношение имеет свое имя; столбцы отношения соответствуют тому или иному атрибуту, имеющему имя и значения. Элементы отношения, соответствующие одной строке, составляют кортеж отношения ( рис. 10.3, б). Арность кортежа – число значений атрибутов в кортеже, т.е. число атрибутов в отношении [7,13, 31]. Схема отношения – список имен атрибутов вместе с именем отношения; так, для рис. 10.3,а схема отношения – ТРАНЗИСТОРЫ ( p, Iк max, Pк, Cк ), для рис. 10.3, б – ИМЯ ОТНОШЕНИЯ ( A, B, С, D ). Домен – множество значений атрибутов (в том числе и только одного атрибута – один столбец). Вообще столбцы не обязательно являются поименованными, а порядок следования элементов в кортежах также несущественен. Существует три подхода к анализу реляционных БД и формированию запросов в них: реляционная алгебра, реляционное исчисление на переменных-кортежах и реляционное исчисление на переменных- доменах. В реляционных базах данных основные операции – включение, удаление, модификация и запрос данных – применяются к кортежам и доменам. Для осуществления операции включения данных задаются новый кортеж и отношение, в которое он должен быть включен. Тогда значения нового кортежа образуют ключ файла включения данных. При удалении данных должны быть заданы отношение и значения атрибутов, образующих ключ удаляемых кортежей. При модификации данных задаются отношение, значения атрибутов ключа и новые значения для применяемых атрибутов. Преобразуются ключевые значения в значения полей. К файлу применяется процедура модификации. Запрос в реляционных базах данных может быть сформулирован к одному или нескольким отношениям (таблицам). Например имеется запрос: указать типы всех транзисторов и их Pк, для которых Ск > 15 пФ. Тогда значение атрибута Ск = 15 пФ. Затем напечать выдается новый файл-отношение 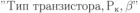 . Могут быть более сложные запросы: например, определить мощности рассеивания транзисторов, для которых . Могут быть более сложные запросы: например, определить мощности рассеивания транзисторов, для которых  , Iк max > 2а, Ск < 150 пФ и т. д. Тогда эти значения составляют ключ, и по ним составляется новое отношение Рк. , Iк max > 2а, Ск < 150 пФ и т. д. Тогда эти значения составляют ключ, и по ним составляется новое отношение Рк.Все эти запросы реализуются с помощью специальных языков манипулирования данными, ряд из которых основан на реляционной алгебре. Основные операции реляционной алгебры приведены в табл. 11.1. В ней даны исходные отношения, результаты операций, а также в ряде случаев теоретико-множественное представление операций. Первые пять операций являются основными, остальные – дополнительные, которые могут быть выражены через пять основных. Объединение отношений 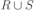 – это множество кортежей (отношений), принадлежащих отношениям R, S или им обоим; отношения R и S должны иметь одинаковую арность. – это множество кортежей (отношений), принадлежащих отношениям R, S или им обоим; отношения R и S должны иметь одинаковую арность.Разность отношений R – S – множество кортежей, принадлежащих R, но не принадлежащих S. Отношения R и S также должны иметь одинаковую арность. Декартово произведение отношений R x S – одна из основных операций по затратам машинного времени при формировании запросов к реляционной БД. При умножении отношений к каждому кортежу первого отношения ( R ) присоединяется каждый кортежвторого отношения ( S ) – конкатенация кортежей; при этом отношения R и S могут иметь одинаковую или различную арность. При декартовом умножении арности исходных отношений складываются, а количества кортежей – перемножаются. Проекция отношения 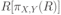 – операции выборки по столбцам (атрибутам), приведенным в обозначении проекции. – операции выборки по столбцам (атрибутам), приведенным в обозначении проекции.Например, 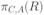 — отношение, составленное из атрибутов С и А отношения — отношение, составленное из атрибутов С и А отношения 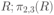 — отношение, составленное из 2-го и 3-го атрибутов отношения R, при этом арность проекции равна числу имен в ее обозначении. — отношение, составленное из 2-го и 3-го атрибутов отношения R, при этом арность проекции равна числу имен в ее обозначении.Селекция отношения  — операция выборки по строкам (кортежам), удовлетворяющим формуле F. В формулу входят операнды, являющиеся константами или номерами (именами) атрибутов, арифметические операторы сравнения: — операция выборки по строкам (кортежам), удовлетворяющим формуле F. В формулу входят операнды, являющиеся константами или номерами (именами) атрибутов, арифметические операторы сравнения: 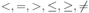 и логические операторы и логические операторы 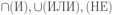 . .Например,  обозначает множество кортежей, в которых компоненты атрибута В равны f, или обозначает множество кортежей, в которых компоненты атрибута В равны f, или 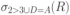 обозначает множество кортежей, в которых компоненты 2-го атрибута больше компонентов 3-го атрибута и одновременно равны компоненты атрибутов А и D ). обозначает множество кортежей, в которых компоненты 2-го атрибута больше компонентов 3-го атрибута и одновременно равны компоненты атрибутов А и D ).Пересечение отношений есть краткая запись для отношения R – (R – S) и обозначает множество кортежей, принадлежащих одновременно R и S.Частное отношений  — множество кортежей, содержащих r – s первых компонентов кортежей отношения R, в которых остальные (s) компонентов принадлежат отношению S. — множество кортежей, содержащих r – s первых компонентов кортежей отношения R, в которых остальные (s) компонентов принадлежат отношению S.Соединение (  -соединение) отношений -соединение) отношений 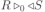 — это селекция (с формулой ) декартова произведения отношений R и S: — это селекция (с формулой ) декартова произведения отношений R и S:В частности,  означает, что сначала надо выполнить декартово произведение отношений R и S, а затем в новом отношении выполнить селекцию по формуле А < D. означает, что сначала надо выполнить декартово произведение отношений R и S, а затем в новом отношении выполнить селекцию по формуле А < D.Эквисоединение отношений  — это -соединение, если в формуле используются только равенства (см. таблицу 11.1, строку 9). — это -соединение, если в формуле используются только равенства (см. таблицу 11.1, строку 9).Естественное соединение 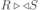 — это эквисоединение, которое выполняется для атрибутов отношений R и S с одинаковыми именами (см таблицу 11.1, строку 10). Так как для указанных атрибутов имена и значения полностью совпадают, то один из них в каждой паре в результирующем отношении устраняют. Естественное соединение — одна из основных операций при формировании запросов к реляционной БД. — это эквисоединение, которое выполняется для атрибутов отношений R и S с одинаковыми именами (см таблицу 11.1, строку 10). Так как для указанных атрибутов имена и значения полностью совпадают, то один из них в каждой паре в результирующем отношении устраняют. Естественное соединение — одна из основных операций при формировании запросов к реляционной БД.Композиция отношений — это проекция -соединения или проекции селекции декартова произведения. По сути, естественное соединение — тоже частный случай композиции. Декомпозиция отношений — это операция, обратная композиции, т. е. восстановление двух отношений из одного, естественное соединение которых образует исходное отношение.
В терминах реляционной алгебры легко записываются запросы к реляционной базе данных. Если задано несколько отношений, то запрос выражается в виде операции композиции к этим отношениям. Однако формальное применение композиции — последовательное применение декартова произведения всех отношений, селекции и проекции — приводит к неоправданным затратам машинного времени. Поскольку арность и число кортежей в исходных отношениях могут быть велики (десятки, сотни), нецелесообразно формировать сначала все декартово произведение, а только затем применять селекцию и проекцию. Так, если два отношения имеют по n кортежей и время доступа к каждой записи — t0, то общее время доступа к памяти для формирования полного декартова произведения Tдоступа = n2t0. Если n = 104, t0 = 10 мс, то Tдоступа = 106 11,5 сут. Поэтому с 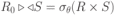 целью экономии машинного времени необходимо выполнять предварительную оптимизацию запросов к реляционной базе данных. Общая стратегия оптимизации заключается в следующем: выполнять селекции и проекции как можно раньше до декартова умножения (с целью сокращения арности и количества кортежей); собирать в каскады селекции и проекции, чтобы выполнять их за один просмотр файла; обрабатывать (сортировать, индексировать) файлы перед выполнением соединения; комбинировать проекции с предшествующими или последующими двуместными операциями. Для осуществления этой стратегии применяются эквивалентные выражения реляционной алгебры, приведенные в табл. 2. Законы коммутативности и ассоциативности означают произвольный выбор в очередности соединений и умножений. При перестановках проекции или селекции с декартовым произведением следует обращать внимание на принадлежность тех или иных имен атрибутов к исходным отношениям.
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||