курсовая работа. Учебное пособие по дисциплине технология разработки программного обеспечения специальность Программирование в компьютерных системах
 Скачать 7.57 Mb. Скачать 7.57 Mb.
|

|
2.2 Функционально-ориентированные метрики Функционально-ориентированные метрики косвенно измеряют программный продукт и процесс его разработки. Вместо подсчёта LOC-оценки рассматривается не размер, а функциональность или полезностьпроекта. Используется 5 информационных характеристик. Количество внешних вводов. Подсчитываются все вводы пользователя, по которым поступают разные прикладные данные. Вводы должны быть отделены от запросов, которые подсчитываются отдельно. Количество внешних выводов. Подсчитываются все выводы, по которым к пользователю поступают результаты, вычисленные программным приложением. В этом контексте выводы означают отчёты, экраны, распечатки, сообщения об ошибках. Индивидуальные единицы данных внутри отчёта отдельно не подсчитываются. Количество внешних запросов. Под запросом понимается диалоговый ввод, который приводит к немедленному программному отчёту в форме диалогового вывода. При этом диалоговый ввод в приложении не сохраняется, а диалоговый вывод не требует выполнения вычислений. Подсчитываются все запросы – каждый учитывается отдельно. Количество внутренних логических файлов. Подсчитываются все логические файлы (то есть логические группы данных, которые могут быть частью базы данных или отдельным файлом). Количество внешних интерфейсных файлов. Подсчитываются все логические файлы из других приложений, на которые ссылается данное приложение. Вводы, выводы и запросы относят к категории транзакция. Транзакция – это элементарный процесс, различаемый пользователем и перемещающий данные между внешней средой и программным приложением. В своей работе транзакции используют внутренние и внешние файлы. Приняты следующие определения. Внешний ввод – элементарный процесс, перемещающий данные из внешней среды в приложение. Данные могут поступать с экрана ввода или из другого приложения. Данные могут использоваться для обновления внутренних логических файлов. Данные могут содержать как управляющую, так и деловую информацию. Управляющие данные не должны модифицировать внутренний логический файл. Внешний вывод – элементарный процесс, перемещающий данные, вычисленные в приложении, во внешнюю среду. Кроме того, в этом процессе могут обновляться внутренние логические файлы. Данные создают отчёты или выходные файлы, посылаемые другим приложениям. Отчёты и файлы создаются на основе внутренних логических файлов и внешних интерфейсных файлов. Дополнительно этот процесс может использовать вводимые данные, их образуют критерии поиска и параметры, не поддерживаемые внутренними логическими файлами. Вводимые данные поступают извне, но носят временный характер и не сохраняются во внутреннем логическом файле. Внешний запрос – элементарный процесс, работающий как с вводимыми, так и с выводимыми данными. Его результат – данные, возвращаемые из внутренних логических файлов и внешних интерфейсных файлов. Входная часть процесса не модифицирует внутренние файлы, а выходная часть не несёт данных, вычисляемых приложением (в этом и состоит отличие запроса от вывода). Внутренний логический файл – распознаваемая пользователем группа логически связанных данных, которая размещена внутри приложения и обслуживается через внешние вводы. Внешний интерфейсный файл – распознаваемая пользователем группа логически связанных данных, которая размещена внутри другого приложения и поддерживается им. Внешний файл данного приложения является внутренним логическим файлом в другом приложении. Каждой из выявленных характеристик ставится в соответствие сложность. Для этого характеристике назначается низкий, средний или высокий ранг, а затем формируется числовая оценка ранга. Для транзакций ранжирование основано на количестве ссылок на файлы и количестве типов элементов данных. Для файлов ранжирования основано на количестве типов элементов-записей и типов элементов данных, входящих в файл. Тип элемента-записи – подгруппа элементов данных, распознаваемая пользователем в пределах файла. Тип элемента данных – уникальное не рекурсивное (неповторяемое) поле, распознаваемое пользователем.
Таблица 2. Пример для расчёта элементов данных
Примеры элементов данных для различных характеристик приведены в таблице 3, а таблица 4 содержит правила учёта данных из графического интерфейса пользователя (GUI). Таблица 3. Примеры элементов данных.
Таблица 4. Правила учёта элементов данных из графического интерфейса пользователя
Например, GUI для обслуживания клиентов может иметь поля Имя, Адрес, Город, Страна, Почтовый индекс, Телефон, E-mail. Таким образом, имеется 7 полей или семь элементов данных. Восьмым элементом данных может быть командная кнопка (добавить, изменить, удалить). В этом случае каждый из внешних вводов Добавить, Изменить, Удалить будет состоять из 8 элементов данных (7 полей плюс командная кнопка).Обычно одному экрану GUI соответствует несколько транзакций. Типичный экран включает несколько внешних запросов, сопровождающих внешний ввод. Обсудим порядок учёта сообщений. В приложении с GUI генерируется 3 типа сообщений: сообщения об ошибке, сообщения подтверждения и сообщения уведомления. Сообщения об ошибке (например, Требуется пароль) и сообщения подтверждения (например, Вы действительно хотите удалить клиента?) указывают, что произошла ошибка или что процесс может быть завершён. Эти сообщения не образуют самостоятельного процесса, они являются частью другого процесса, то есть считаются элементом данных соответствующей транзакции. С другой стороны, уведомление является независимым элементарным процессом. Например, при попытке получить из банкомата сумму денег, превышающую их количество на счёте, генерируется сообщение Не хватает средств для завершения транзакции. Оно является результатом чтения информации из файла счёта и формирования заключения. Сообщение уведомления рассматривается как внешний вывод. Данные для определения ранга и оценки сложности транзакций приведены в таблицах 5-9 (числовая оценка указана в круглых скобках). Использовать их очень просто. Например, внешнему вводу, который ссылается на 2 файла и имеет 7 элементов данных, по таблице 5 назначается средний рейтинг и оценка сложности 4. Таблица 5. Ранг и оценка внешних вводов
Таблица 6. Ранг и оценка сложности внешних выводов
Таблица 7. Ранг и сложности внешних запросов
Таблица 8. Ранг и оценка сложности внутренних логических файлов
Таблица 9. Ранг и оценка сложности внешних интерфейсных файлов
Отметим, что если во внешнем запросе ссылка на файл используется как на этапе ввода, так и на этапе вывода, она учитывается только один раз. Такое же правило распространяется и на элемент данных (однократный учёт). После сбора всей необходимой информации приступают к расчёту метрики – количества функциональных указателей FP (FunctionPoints). Автором этой метрики является А. Албрехт. Исходные данные для расчёта сводятся в таблицу 10. Таблица 10. Исходные данные для расчёта FP-метрик.
В таблицу заносится количественное значение характеристики каждого вида (по всем уровням сложности). Места подстановки значений отмечены прямоугольниками (прямоугольник играет роль метки-заполнителя). Количественные значения характеристик умножаются на числовые оценки сложности. Полученные в каждой строке значения суммируются, давая полное значение для данной характеристики. Эти полные значения затем суммируются по вертикали, формируя общее количество. Количество функциональных указателей вычисляется по формуле FP = Общее количество * (0,65 + 0,01 * ∑i=114 Fi), (1) где Fi – коэффициенты регулировки сложности. Каждый коэффициент может принимать следующие значения: 0 – нет влияния, 1 – случайное, 2 – небольшое, 3 – среднее, 4 – важное, 5 – основное. Значения выбираются эмпирически в результате ответа на 14 вопросов, которые характеризуют системные параметры приложения (таблица 11). Таблица 11. Определение системных параметров приложения
После вычисления FP на его основе формируются метрики: Производительность = ФункцУказатель / Затраты [FP / чел.-мес.]; Качество = Ошибки / ФункцУказатель [Единиц / FP]; Удельная стоимость = Стоимость / ФункцУказатель [Тыс. $ / FP]; Документированность = СтраницДокумента / ФункцУказатель [Страниц / FP] Область применения метода функциональных указателей – коммерческие информационные системы. Для продуктов с высокой алгоритмической сложностью используются метрики указателей свойств (FeauturePoints). Они применимы к системному и инженерному ПО, ПО реального времени и встроенному ПО. Для вычисления указателя свойств добавляется одна характеристика – количество алгоритмов. Алгоритм здесь определяется как ограниченная подпрограмма вычислений, которая включается в общую компьютерную программу. Примеры алгоритмов: обработка прерываний, инвертирование матрицы, расшифровка битовой строки. Для формирования указателя свойств составляется таблица 12. После заполнения таблицы по формуле (1) вычисляется значение указателя свойств. Для сложных систем реального времени это значение на 25 – 30% больше значения, вычисляемого по таблице для количества функциональных указателей. FP-оценки легко пересчитать в LOC-оценки. Как показано в таблице 13, результаты пересчёта зависят от языка программирования. Таблица 12. Исходные данные для расчёта указателя свойств
Таблица 13. Пересчёт FP-оценок в LOC-оценки
Достоинства функционально-ориентированных метрик: Не зависят от языка программирования. Легко вычисляются на любой стадии проекта. Недостаток функционально-ориентированных метрик: результаты основаны на субъективных данных, используются не прямые, а косвенные измерения. 3. Выполнение оценки в ходе руководства проектом 3.1.Оценка проекта на основе LOC- И FP-метрик Процесс руководства программным проектом начинается с множества действий, объединяемых общим названием планирование проекта. Первое их этих действий – выполнение оценки. Оно закладывает фундамент для других действий по планированию проекта. При оценке проекта чрезвычайно высока цена ошибок. Очень важно провести оценку с минимальным риском. Цель этой деятельности – сформировать предварительные оценки, которые позволят: предъявить заказчику корректные требования по стоимости и затратам на разработку программного продукта; составить план программного проекта. При выполнении оценки возможны два варианта использования LOC и FP-данных: в качестве оценочных переменных, определяющих размер каждого элемента продукта; в качестве метрик, собранных за прошлые проекты и входящих в метрический базис фирмы. Алгоритм процесса оценки: Шаг 1. Область назначения проектируемого продукта разбивается на ряд функций, каждую из которых можно оценить индивидуально: f1, f2,...,fn. Шаг 2. Для каждой функции fi планировщик формирует лучшую LOCлучш i (FPлучш i), худшую LOCхудш i (FPхудш i) и вероятную оценку LOCвероятн i (FPвероятн i). Используются опытные данные (их метрического базиса) или интуиция. Диапазон значения оценок соответствует степени предусмотренной неопределённости. Шаг 3. Для каждой fi в соответствииβ-распределением вычисляется ожидаемое значение LOC- (или FP) оценки: LOCож i = (LOCлучш i + LOCхудш i + 4 * LOCвероятн i) / 6. Шаг 4. Определяется значение LOC- или FP-производительности разработки функции. Используется один из трёх подходов: для всех функций принимается одна и та же метрика средней производительности ПРОИЗВср, взятая из метрического базиса; дляi-й функции на основе метрики средней производительности вычисляется настраиваемая величина производительности: ПРОИЗВi = ПРОИЗВср * (LOCср / LOCож i), где LOCср – средняя LOC-оценка, взятая из метрического базиса (соответствует средней производительности). для i-й функции настраиваемая величина производительности вычисляется по аналогу, взятому из метрического баланса: ПРОИЗВi = ПРОИЗВан i * (LOC ан i / LOCож i). Первый подход обеспечивает минимальную точность (при максимальной простоте вычислений), а третий подход – максимальную точность (при максимальной сложности вычислений). Шаг 5. Вычисляется общая оценка затрат на проект: для первого подхода ЗАТРАТЫ = ∑i=1n (LOCож i ) / ПРОИЗВср [чел.-мес]; для второго и третьего подходов ЗАТРАТЫ = ∑i=1n (LOCож i / ПРОИЗВi )[чел.-мес]. Шаг 6. Вычисляется общая оценка стоимости проекта: для первого и второго подхода СТОИМОСТЬ = ( ∑i=1n LOCож i ) * УД_СТОИМОСТЬср, где УД_СТОИМОСТЬср–метрика средней стоимости одной строки, взятая из метрического базиса. для третьего подхода СТОИМОСТЬ = ∑i=1n (LOCож i * УД_СТОИМОСТЬан i ), где УД_СТОИМОСТЬан i – метрика стоимости одной строки аналога, взятая из метрического базиса. 3.2.Конструктивная модель стоимости COCOMO В данной модели для вывода формул использовался статический подход – учитывались реальные результаты огромного количества проектов. Автор оригинальной модели – Барри Боэм (1981) – дал ей название COCOMO 81 (Constructive Cost Model) и ввёл в её состав три разные по сложности статические подмодели . Иерархию подмоделей Боэма (версии 1981 года) образуют базисная СОСОМО – статическая модель, вычисляет затраты разработки и её стоимость как функцию размера программы; промежуточная СОСОМО – дополнительно учитывает атрибуты стоимости, включающие основные оценки продукта, аппаратуры, персонала и проектной среды; усовершенствованная СОСОМО – объединяет все характеристики промежуточной модели, дополнительно учитывает влияние всех атрибутов стоимости на каждый этап процесса разработки ПО (анализ, проектирование, кодирование, тестирование и т. д.). Подмодели СОСОМО 81 могут применяться к трём типам программных проектов. По терминологии Боэма, их образуют: распространённый тип – небольшие программные проекты, над которыми работает небольшая группа разработчиков с хорошим стажем работы, устанавливаются мягкие требования к проекту; полунезависимый тип – средний по размеру проект, выполняется группой разработчиков с разным опытом, устанавливаются как мягкие, так и жёсткие требования к проекту; встроенный тип – программный проект разрабатывается в жёстких условиях аппаратных, программных и вычислительных ограничений. Уравнения базовой подмодели имеют вид E = ab * (KLOC)bb [чел-мес]; D = cb * (E)db [мес], где E – затраты в человеко-месяцах, D – время разработки, KLOC – количество строк в программном продукте. Коэффициенты ab, bb, cb, db берутся из таблицы 14. Таблица 14. Коэффициенты для базовой модели СОСОМО 81
В 1995 году Боэм ввёл более совершенную модель СОСОМО II, ориентированную на применения в программной инженерии XXI века. Контрольные вопросы Что такое метрика? Охарактеризуйте рекомендуемое правило распределения затрат проекта. Какие размерно-ориентированные метрики вы знаете? Для чего используются размерно-ориентированные метрики? Определите достоинства и недостатки размерно-ориентированных метрик. Что такое функциональный указатель? Что такое указатель свойств? От каких информационных характеристик зависит функциональный указатель? Как вычисляется количество функциональных указателей? От каких характеристик зависит указатель свойств? Что такое коэффициенты регулировки сложности в метрике функциональных указателей? В чем отличие расчета метрик для информационных и инженерных задач? Что показывает производительность, рассчитываемая с помощью LOC или FP? Что показывает качество, рассчитываемое с помощью LOC или FP? Из чего складываются затраты, учитываемые при расчете метрик? Определите достоинства и недостатки функционально-ориентированных метрик? Можно ли перейти от LOC-оценок к FP-оценкам? В чем суть предварительной оценки проекта с помощью LOCи FP-метрик? Что такое метрический базис? Что такое конструктивная модель стоимости и для чего она применяется? Глава 4. Структурное проектирование 1. Классические методы анализа. Структурный анализ Рассматриваются классические методы анализа требований, ориентированные на процедурную реализацию программных систем. Анализ требований служит мостом между неформальным описанием требований, выполняемым заказчиком, и проектированием систем. Методы анализа призваны формализовать обязанности системы, фактически их применение дает ответ на вопрос: что должна делать будущая система. 1.1 Диаграммы потоков данных Структурный анализ - один из формализованных методов анализа требований к ПО. Автор этого метода – Том Де Марко (1979). В этом методе программное изделие рассматривается как преобразователь информационного потока данных. Основной элемент структурного анализа – диаграмма потока данных. Диаграмма потоков данных ПДД – графическое средство для изображения информационного потока и преобразований, которым подвергаются данные при движении от входа к выходу систем. Элементы диаграммы имеют вид, показанный на рис.1. Диаграмма может использоваться для представления программного изделия на любом уровне абстракции. Пример систем взаимосвязанных диаграмм показан на рис. 2. Диаграмма высшего (нулевого) уровня представляет систему как единый овал со стрелкой, ее называют основной или контекстной моделью. Контекстная модель используется для указания внешних связей программного изделия. Для детализации (уточнения систем) вводится диаграмма 1-го уровня. Каждый из преобразователей этой диаграммы – подфункция этой системы. Таким образом, речь идет о замене преобразователя F на целую систему преобразователей. Дальше уточнение (например, преобразователя F3) приводит к диаграмме 2-го уровня. Говорят, что ППД1 разбивается на диаграммы 2-го уровня. Внешний объект Источник или потребитель информации  Преобразователь (принимает и обрабатывает данные) Скорость  Поток данных (должен иметь метку) Поток данных (должен иметь метку)  Хранилище данных Запоминает информацию, используемую преобразователем рис. 1. Элементы диаграммы потоков данныхВажно сохранить непрерывность информационного потока и его согласованность. Это значит, что входы и выходы у каждого преобразователя на любом уровне должны оставаться прежними. В диаграмме отсутствуют точные указания на последовательность обработки. Точные указания откладываются до этапа проектирования. Диаграмма потоков данных - это абстракция, граф. Для связи с графом проблемной областью (превращение в граф-модель) надо задать интерпретацию ее компонентов – дуг и вершин. Базовые средства диаграммы не обеспечивают полного описания требований к программному изделию. Очевидно, что должны быть описаны стрелки (потоки данных) и преобразователи (процессы). Для этих целей используется словарь требований (данных) и спецификации процессов. Внешний объект 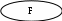 Внешний объект А В ПДД0    X Z X Z   А А   В ВПДД1  Y V Y1 Y Y2  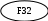  V V  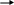 ПДД2 ПДД2Рис.2 Пример диаграммы потоков данных Словарь требований (данных) содержит описания потоков данных и хранилищ данных. Словарь требований является неотъемлемым элементом любой CASE-утилиты автоматизации анализа. Структура словаря зависит от особенностей конкретной CASE-утилиты. Тем не менее можно выделить базисную информацию типового словаря требований. Большинство словарей содержит информацию. Имя (основное имя элемента данных, хранилища или внешнего объекта.) Прозвище (Alias) – другие имена того же объекта. Где и как используется объект - список процессов, которые используют данный элемент, с указанием способа использования (ввод в процесс, вывод из процесса, как внешний объект или как память). Описание содержания – запись для представления содержания. дополнительная информация – дополнительные сведения о типах данных, допустимых значениях, ограничениях и т.д. Спецификация процесса – это описание преобразователя. Спецификация поясняет: ввод данных в преобразователь, алгоритм обработки, характеристики производительности преобразователя, формируемые результаты. Количество спецификаций равно количеству преобразователей диаграммы. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||