Базы данных. Уровни представления данных. Концептуальный уровень
 Скачать 156.57 Kb. Скачать 156.57 Kb.
|

|
Модели данных Уровни представления данных. Концептуальный уровень – архитектуры ANSI/SPARC служит для поддержки единого взгляда на базу данных, общего для всех ее приложений и независимого от них и от среды хранения. Концептуальный уровень представляет собой формализированную информационно-логическую модель ПО. Описание этого представления называется концептуальной. Внутренний уровень архитектуры поддерживает представление данных в среде хранения и пути доступа к ним. На этом архитектурном уровне БД представлена в полностью «материализованном» виде, тогда как на других уровнях идет работа на уровне отдельных экземпляров или множества экземпляров записей. Описание БД на внутреннем уровне называется внутренней схемой или схемой хранения. Внешний уровень архитектуры БД предназначим для различных групп пользователей. Описания таких представлений называются внешними схемами. В системе баз данных могут одновременно поддерживаться несколько внешних схем для различных групп пользователей или задач. Схемы базы данных – это описание базы данных в контексте конкретной модели данных. Модель данных Модель данных это комбинация трех составляющих: 1. Набора типов структур данных. Здесь можно провести аналогию с языками программирования, в которых тоже есть предопределенные типы структур данных, такие как скалярные данные, вектора, массивы, структуры (например, тип struct в языке C) и т.п. 2. Набора операторов или правил выводы, которые могут быть применены к любым правильным примерам типов данных, перечисленные к (1), чтобы находить, выводить или преобразовывать информацию, содержащуюся в любых частях этих структур в любых комбинациях. 3. Набора общих правил целостности, которые прямо или косвенно определяют множество непротиворечивых состояний базы данных и/или множество изменений ее состояния. Сетевая модель Сетевая модель позволяет организовывать БД, структура которых представляется графом общего вида. Организация данных в сетевой модели соответствует структуризации данных по версии CODASYL. Каждая вершина графа хранит экземпляры сущностей (записи одного типа) и сведения о групповых отношениях с сущностями других типов. Каждая запись может хранить произвольное количество атрибутов (элементов данных и агрегатов), соответствующих экземпляру сущности.   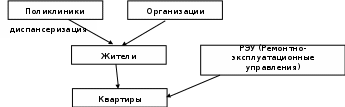 проживают обслуживают работают Характеристики СМД Групповые отношения характеризуют следующие признаки: 1. Способ упорядочения подчиненных записей. Поддерживаются три способа упорядочения: Очередь – добавление в конец списка (FIFO – first input, first output). Стек – добавление в начало списка (LIFO – last input, first output). Сортировка по значению ключа. При этом задается ключевое поле (поля), и вновь поступившая запись добавляется в упорядоченный список в соответствии со значением этого поля (значением ключа). 2. Режим включения подчиненных записей. Режимы бывают автоматические и ручные. При автоматическом режиме подчинённая запись связана с записью-владельцем обязательной связью, поэтому она включается в групповое отношение и прикрепляется к записи-владельцу в момент внесения в БД. (Из этого следует, что запись-владелец должна быть внесена в базу данных ДО внесения первого экземпляра подчиненной записи). При ручном режиме включения подчиненная запись может находиться в БД и не быть прикрепленной к записи-владельцу. Она вручную включается в групповое отношение тогда, когда это отношение(связь) возникает. 3. Режим исключения подчиненных записей. Режимом исключения определяется классом членства. Различают три класса членства – фиксированный, обязательный и необязательный: Записи с обязательным членством должны быть удалены до записи-владельца: владелец, к которому прикреплена хотя бы одна запись с обязательным членом, не может быть удален. Записи с фиксированным членством удаляются вместе с записью-владельцем. Записи с необязательным членством при удалении записи-владельца останутся в БД. Иерархическая модель Иерархическая модель позволяет строить древовидной структурой. Структура ИМД описывается в терминах, аналогичных терминам сетевой модели данных. В основе ИМД лежит понятие дерева. Дерево – это связанный неориентированный граф, который не содержит циклов. При работе с деревом выделяют какую-то конкретную вершину, определяют ее как корень дерева и рассматривают особо – в эту вершину не заходит ни одно ребро. Реляционная модель В основе РМД лежит понятие отношения, основанного на декартовые произведения доменов. Домен – это множество значений, которое может принимать элемент (например, множество целых чисел, множество комбинаций символов длиной N и т.п.) Элементы отношения называют кортежами. Элементы кортежа принято называть атрибутами. Отношения содержит информацию о сущностях одного типа. Каждый кортеж отношения соответствует одному экземпляру сущности. Общая характеристика базы данных и основные понятия Развитие технологий обработки данных Огромное значение автоматизация процессов обработки данных и управления ими занимает в общем процессе развития компьютерных технологий. Это развитие в ретроспективном анализе понимается необходимостью взгляда на проблемы, которые присущи ранним информационным системам. Соответственно тот опыт, который накоплен в данной области, позволяет глубже осознать задачи современного состояния и дальнейшего развития технологий баз данных, которые занимают основное положение в процессе обработки данных и управления ими. Рассмотрим основные факторы, предопределившие генеральное направление развития технологий баз данных. В компьютерных технологиях особое место занимает процесс решения информационных задач. Информационные задачи существенно отличаются от вычислительных. Вычислительные задачи имеют сложные алгоритмы обработки данных простой структуры. Информационные задачи характеризуются противоположными отправными моментами. Такими как: · обрабатывается информация больших объемов; · обрабатываемые данные имеют сложную структуру; · алгоритмы обработки относительно просты. Современный мир компьютерных технологий и его широчайшие возможности развивались постепенно. Поэтому простые алгоритмы обработки данных были восприняты компьютерными технологиями как некоторое облегчение в общем понимании информационных задач. Но первые два пункта отправных моментов, а именно большие объемы и сложная структура стали определять дополнительные требования: надежное хранение информации; обеспечение надежности хранения информации; высокая производительность. Эти дополнительные требования длительное время являлись некоторым сложным и нелегким участком в работе программистов. Достаточно продолжительный временной период перечисленные требования находились в противоречии друг с другом. Слабым звеном вычислительных средств, помимо всего, долгое время являлись существенно ограниченные возможности процесса информационного хранения. В то время возможность говорить об эффективном и долговременном хранении информации появлялась только при наличии запоминающих устройств, непосредственно сохраняющих информацию при снятии электрического питания с устройства. Тогда использовались в данном направлении, как долговременная память только магнитные ленты и магнитные барабаны. Магнитные ленты имели неограниченную емкость (так было принято считать), но использование их имело ряд существенных недостатков и накладывало дополнительное ограничение. Основными недостатками можно считать низкую скорость обмена информацией и существенно ограничивающая производительность вычислительных средств. Ограничение, применительно к информационным задачам, в использовании магнитных лент выделялся последовательный доступ к информации. Магнитные барабаны, в отличии от магнитных лент, были лишены недостатка последовательного доступа к памяти. Они давали возможность выборочного доступа к памяти, но при этом имели рад недостатков. Существенными недостатками магнитных барабанов являлись ограниченный объем памяти и низкая скорость обмена информацией. Эти недостатки не позволяли создавать адекватное отображение предметной области, которая формируется в реальном мире в виде множества взаимосвязанных объектов информатизации и главное не позволяли мгновенно реагировать информационной системе на пользовательские запросы. Итак, необходимо согласиться со следующим заключением: основным тормозом на пути развития технологии баз данных продолжительный период времени являлось отсутствие таких видов памяти, которые бы удовлетворяли всем вышеперечисленным требованиям. В процессе развития приведенные недостатки были ликвидированы за счет появления сменных магнитных дисков. Сменные магнитные диски являлись устройствами внешней памяти и обладали значительно большей емкостью. Именно сменность дисков делала их емкость неограниченной. Диски обеспечивали приемлемую скорость доступа к информации, и как уже говорилось, выборочный или произвольный доступ к информации. Как только была решена задача с хранением информации так сразу стартовал период развития баз данных, как технологического процесса. При рассмотрении истории развития технологий информационных систем следует обратить внимание на тот факт, что мощным локомотивом этого развития всегда служили нужды и потребности делового и производственного мира. С одной стороны, их роль можно сравнить с естественным отбором в генетике. Успешно приживались и в дальнейшем развивались те решения, внедрение которых обеспечивало превышение получаемой выгоды от внедрения над затратами на нее. С другой стороны, потребности этого локомотива росли параллельно с развитием технологий, постоянно ставя новые задачи и требуя их решения. Первые внедрения коммерческих компьютерных программ происходили там, где их особенно ждали – в бухгалтерских расчетах. Вполне объяснимо то, что эти программы на начальных стадиях своего развития осуществляли те же операции и выдавали те же документы, которые раньше выполнялись и формировались вручную. Определив основные сдерживающий и подталкивающий факторы развития информационных технологий, дадим более подробную характеристику различных его фаз. В период 60-х годов прошлого века, приходящийся на период ЭВМ второго поколения процесс обработки данных производился, как правило с помощью операций ввода-вывода. Файловая организация при данной обработке была последовательной. Физическая структура данных, при данном последовательном способе файловой организации совпадала с логической структурой файла. Конечным пользователям такой файл будет представлен как некоторая линейная последовательность записей. В этом случае запись файла и его структура может быть известна только непосредственной программе, которая с эти файлом функционирует, так как сама структура записи в этой программе только и обозначена. Изменения в структуре файла вносятся одновременно с изменениями в программе. Эта ситуация характеризует зависимость программ от данных. Сложность вопроса становится более сложной в случае когда в информационной системе присутствует большое число пользователей, которым необходимо пользоваться одинаковой информацией. При этом каждый пользователь имеет свой алгоритм обработки информации и изменения, вносимые в структуру данных одним пользователем неизбежно приводят к необходимости модифицировать абсолютно все программы. Существенная проблема описываемого периода развития систем обработки информации, в большой мере усложняющая ситуацию, – значительная степень избыточности данных в файлах. Дело в том, что при рассматриваемом способе организации даже в тех случаях, когда наборы данных создаются и оптимизируются для одной задачи, обеспечение нормальных условий функционирования обработки данных приводит к необходимости хранения нескольких копий одного и того же файла, отсортированных по различным полям записей. К нарисованной негативной картине нельзя не добавить еще несколько характеристик процесса создания и функционирования информационных систем: · отсутствие централизованных методов управления доступом к информации; · значительные затраты труда программистов как на создание приложения, так и на поддержание его работы; · сложности администрирования режимом доступа к файлу, а следовательно и сложность реализации многопользовательского режима работы. Указанные проблемы ранних систем обработки данных требовали своего решения и служили мощным толчком для поиска новых подходов к хранению и управлению информацией. Следующий этап развития информационных систем (ИС) характеризуется существенным изменением, как природы файлов, так и используемых для их хранения устройств. Подобная ситуация стала возможной с появлением файлов произвольного доступа к данным и особенно индексно-последовательных (ИП) файлов, широко распространившихся в 60-е годы. Помимо отсутствия в этом случае необходимости просмотра всех предшествующих записей, изменилась природа и методы хранения самих носителей информации, позволивших значительно сократить время обращения к памяти, а значит существенно увеличить производительность таких систем. Появилось некоторое различие логической и физической структур данных, правда, взаимосвязь между ними сохранялась все еще достаточно простая. Проявилась и кое-какая независимость программ от данных. Новые подходы позволили заменять запоминающие устройства без изменения прикладной программы, используя специальные языки заданий. Средства защиты данных в этот период развития уже определенны способом применялись. В случае применения средств защиты на практике был получен следующий вывод. Файлы с произвольным доступом не снимали полностью имеющуюся проблему лишь, так как при всех своих достоинствах любые файловые системы имеют врожденные недостатки. Определим их. Любое типовое программное обеспечение, в частности программное обеспечение информационной системы обработки данных, представляет не что иное. как методы доступа к информации. При это не представлен метод управление данными. Такая ситуация возникает из-за того что файловые системы не разрешают устанавливать связь между данными различных файлов. В файлах с таким доступом сохраняется значительная информационная избыточность. В этих файлах отсутствует централизованный контроль на уровне информационных элементов. Это связано с тем, часто один и тот же информационный элемент имеет несколько имен в зависимости от того, в какие файлы он входит. При этом требуются большие затраты труда программистов, которым постоянно приходится определять новые наборы данных для новых приложений, выполнять очень сложные манипулирования данными. Эти манипулирования требуют устранения сложности администрирования режимом доступа к файлу, а следовательно, и сложности реализации многопользовательского режима работы. Необходимость решения перечисленных проблем заставила разработчиков информационных систем предложить новые концепции: · хранения информации – базы данных; · управления информацией – системы управления базами данных. Дальнейшая история развития систем обработки данных – это эпоха развития баз данных и систем управления базами данных. Начало этой эпохи ознаменовалось 1968 годом, когда произошла разработка и внедрение фирмой IBM пионера промышленной системы управления базой данных – системы IMS. Можно с полной уверенностью утверждать, что рождение базы данных работающей под управлением СУБД, стало наиважнейшим достижением в области программного обеспечения. В то же время, именно это появление стало мощным катализатором многих значительных достижений не только в области создания программных продуктов, но и в других связанных с ней областях. Остановимся на краткой характеристике почти полувековой предыстории нынешнего состояния этой проблемы, ответив вначале на следующий вопрос. Так в чем же суть новых упомянутых взглядов, идей? База данных – это единое, вместительное хранилище разнообразных данных и описаний их структур, которое после своего определения, осуществляемого отдельно и независимо от приложений, используется одновременно многими приложениями. В базе данных хранимая информация организована в совместно используемый набор и логически связана между собой, точно также как в рассматриваемой соответствующей предметной области взаимосвязаны между собой объекты и явления. Поскольку структуры данных определяются средствами СУБД отдельно от приложений и хранятся в базе данных, то добавление новых структур данных или изменение существующих не влияет на приложения, не использующие измененные данные. Система управления базами данных – это программное обеспечение, с помощью которого можно: - определять базу данных, структуры ее данных, а также задавать ограничения для хранимых данных; - манипулировать данными, организуя выполнение разнообразных не фиксированных заранее запросов; - предоставлять контролируемый доступ к информации базы данных; - осуществлять поддержку обеспечения безопасности данных; - обеспечивать целостность данных; - управлять многопользовательским режимом работы, контролируя процессы совместного доступа к данным; - восстанавливать информацию базы данных, потерянную в результате различных аппаратных или программных сбоев. Надо заметить, что в полной мере эти взгляды (концепции) и их составляющие формировались не сразу, а со временем. Программное обеспечение первых СУБД связано с обработкой элементов или групп элементов данных. В подобной ситуации доступ к одним и тем же данным уже может осуществляться из разнообразных прикладных программ различными путями. Программное же обеспечение должно включать в себя некоторые средства ограничения избыточности. Из одних и тех же физических данных могут быть получены разные логические файлы. Для различных прикладных программ могут быть использованы общие элементы данных. Сами данные могут адресоваться на уровне полей и групп полей, а не на уровне записей. Поиск возможен по многим ключам. На прикладные программ не влияет усложнение форм организации данных. |