Реферат Параллельные вычисления. Высшего профессионального образования
 Скачать 216.52 Kb. Скачать 216.52 Kb.
|

|
Министерство образования и науки Российской Федерации ФЕДЕРАЛЬНОЕ ГОСУДАРСТВЕННОЕ БЮДЖЕТНОЕ ОБРАЗОВАТЕЛЬНОЕ УЧРЕЖДЕНИЕ ВЫСШЕГО ПРОФЕССИОНАЛЬНОГО ОБРАЗОВАНИЯ «САРАТОВСКИЙ ГОСУДАРСТВЕННЫЙ УНИВЕРСИТЕТ ИМЕНИ Н. Г. ЧЕРНЫШЕВСКОГО» Кафедра математической кибернетики и компьютерных наук Параллельные вычисления РЕФЕРАТ магистра 1 курса 171 группы направления 09.04.01 «Информатика и вычислительная техника» факультета компьютерных наук и информационных технологий Белякова Михаила Алексеевича по предмету «Теория построения отказоустойчивых систем» Преподаватель Абросимов Михаил Борисович Содержание
1.Введение Поначалу существовал однопрограммный режим работы ЭВМ, но затем в 1964 году фирма IBM выпустила операционную систему - OS 360. Появившаяся у компьютера операционная система стала его полновластным хозяином - распорядителем всех его ресурсов. Теперь программа пользователя могла быть выполнена только под управлением операционной системы. Операционная система позволяла решить две важные задачи - с одной стороны обеспечить необходимый сервис всем программам, одновременно выполняемым на компьютере, с другой - эффективно использовать и распределять существующие ресурсы между программами, претендующими на эти ресурсы. Появление операционных систем привело к переходу от однопрограммного режима работы к мультипрограммному, когда на одном компьютере одновременно выполняются несколько программ. Создавать параллельные программы стало возможно с появлением в операционных системах механизма порождения потоков или нитей (threads), называемых еще легковесными процессами (light-weightprocess). Где нить - это независимый поток управления, выполняемый в контексте некоторого процесса совместно с другими нитями или процессами. Нити имеют общее адресное пространство, но разные потоки команд. В простейшем случае, процесс состоит из одной нити. Однако, если эти потоки (процессы) совместно используют некоторые ресурсы, к примеру область памяти, то при обращении к этим ресурсам они должны синхронизовать свои действия. Мультипрограммирование это еще не параллельное программирование, но это шаг в направлении параллельных вычислений. Мультипрограммирование - параллельное выполнение нескольких программ, оно позволяет уменьшить общее время их выполнения. Под параллельными вычислениями понимается параллельное выполнение одной и той же программы. Параллельные вычисления позволяют уменьшить время выполнения одной программы. Поэтому имеет место быть следующее определение. Параллельные вычисления — способ организации компьютерных вычислений, при котором программы разрабатываются как набор взаимодействующих вычислительных процессов, работающих параллельно (одновременно). Заметим, что наличие у компьютера нескольких процессоров является необходимым условием для мультипрограммирования. Существование операционной системы, организующей взаимную работу процессоров, достаточно для реализации мультипрограммирования. Для параллельных вычислений накладывается дополнительное требование - это требование к самой программе, - программа должна допускать возможность распараллеливания вычислений. 2.Общая информация о параллельных вычислениях Существуют различные способы реализации параллельных вычислений. Например, каждый вычислительный процесс может быть реализован в виде процесса операционной системы, либо же вычислительные процессы могут представлять собой набор потоков выполнения внутри одного процесса ОС. Параллельные программы могут физически исполняться либо последовательно на единственном процессоре — перемежая по очереди шаги выполнения каждого вычислительного процесса, либо параллельно — выделяя каждому вычислительному процессу один или несколько процессоров (находящихся рядом или распределённых в компьютерную сеть). Основная сложность при проектировании параллельных программ — обеспечить правильное взаимодействий между различными вычислительными процессами, а также координацию ресурсов, разделяемых между процессами. 3.Классификация многопроцессорных вычислительных систем, используемых для параллельных вычислений Для реализации параллельных вычислений применяется MIMD (Multiple Instruction, Multiple Data) – система с множественным потоком команд и множественным потоком данных; Все виды параллельных систем относятся к одной группе MIMD. Дальнейшее разделение типов многопроцессорных систем основывается на способах организации памяти: системы на общей и распределенной памяти. Существующие параллельные ВС класса MIMD образуют два технических подкласса:
Рассмотрение: – Мультипроцессорные вычислительные комплексы (общая память) - это компьютеры, обладающие множеством процессоров, работающих на общей памяти. Наличие общей памяти сильно упрощает взаимодействие процессоров между собой, однако накладывает сильные ограничения на их число. Вся система работает под управлением единой ОС. В этот класс входит большинство продаваемых сегодня на рынке многоядерных компьютеров. – Мультикомпьютерные вычислительные комплексы (распределенная память, передача сообщений) - представляют множество узлов, которыми являются компьютеры, соединенных высокоскоростными линиями связи (медные провода, коаксиальный кабель, волоконно-оптический кабель). Каждый компьютер обладает собственной памятью и обменивается сообщениями с другими компьютерами системы для передачи данных. Здесь может применяться Message Passing Interface (MPI, интерфейс передачи сообщений) — программный интерфейс (API) для передачи информации, который позволяет обмениваться сообщениями между процессами, выполняющими одну задачу. В этот класс входят кластеры. Под кластером понимается вычислительный комплекс, рассматриваемый как единое целое, с некоторым выделенным компьютером, играющим роль сервера. Каждый компьютер работает под управлением своей копии операционной системы. Состав и мощность узлов может меняться в рамках одного кластера, давая возможность создавать неоднородные системы. Поскольку компьютеры, входящие в состав кластера, могут быть обычными компьютерами, то кластеры относительно недороги. Большинство входящих в Top 500 суперкомпьютеров являются кластерами. Самым мощным суперкомпьютером в 2016 году является [Sunway TaihuLight], работающий в национальном суперкомпьютерном центре Китая. Скорость вычислений, производимых им, составляет 93 петафлопс (10 в 15 степени вычислительных операций с плавающей запятой в секунду). Для кластерных систем в соответствии с сетевым законом Амдаля характеристики коммуникационных сетей имеют принципиальное значение. Коммуникационные сетиимеют две основные характеристики: латентность− время начальной задержки при посылке сообщений и пропускную способность сети, определяющую скорость передачи информации по каналам связи. При выполнении функции передачи данных, прежде чем покинуть процессор, последовательно выполняется набор операций, определяемый особенностями программного обеспечения и аппаратуры. 4.Достоинства и недостатки организации параллельных вычислений на данных ВС
Пре иму ще ства:
Не до стат ки:
Достоинства организации параллельных вычислений на распределенной памяти: 1.Использование распределенной памяти упрощает задачу создания мультипроцессорных вычислительных систем. 2.Каждый процесс обладает собственными ресурсами и выполняется в собственном адресном пространстве, таким образом, данные, находящиеся на каждом процессе защищены от неконтролируемого доступа. 3. Универсальность, т.к. алгоритмы с передачей сообщений могут выполняться на большинстве сегодняшних суперкомпьютеров. 4.Легкость отладки.Отладка параллельных программ все еще остается сложной задачей. Однако процесс отладки происходит легче в программах с передачей сообщений. Это связано с тем, что самая распространенная причина ошибок заключается в неконтролируемой перезаписи данных в памяти. Модель с передачей сообщений, явно управляет обращением к памяти, и, тем самым, облегчает локализацию ошибочного чтения или записи в память. Недостатки организации параллельных вычислений на распределенной памяти: 1.Каждый процессор вычислительной системы может использовать только свою локальную память, поэтому для доступа к данным, располагаемым на других процессорах, необходимо явно выполнять операции передачи сообщений (message passing operations). 2.Проблема эффективного использования распределенной памяти приводят к существенному повышению сложности параллельных вычислений. 5.Модель параллельного выполнения программы Архитектура комплекса - это лишь одно из требований, необходимых для реализации подлинного параллелизма. Другие два требования связаны с требованиями к операционной системе и к самой программе. Не всякую программу можно распараллелить независимо о того, на каком суперкомпьютерном комплексе она будет выполняться. Для большего понимания рассмотрим одну из моделей параллельного вычисления. Итак, у нас имеется программа P, состоящая из n модулей: Будем предполагать, что программа P выполняется на компьютере, обладающим некоторым числом процессоров, работающих на общей памяти. Выходные данные, полученные в результате работы модуля Модуль уровня i с номером k будем обозначать как Модули, принадлежащие уровню 1, имеют все необходимые данные, полученные от внешних источников. Они не требуют завершения работы других модулей и в принципе могут выполняться параллельно, будучи запущенными в начальный момент выполнения программы. Свяжем с программой P ориентированный граф зависимостей модулей. Граф не содержит циклов и отражает разбиение модулей на уровни. Модули являются вершинами графа, а дуги отражают зависимости между модулями. Дуга ведет от модуля  Рис. 1.1. Пример графа зависимостей Обозначим через В случае одного процессора происходит последовательное выполнение модулей одного уровня, затем переход к выполнению модулей следующего уровня. Для случая неограниченного числа процессоров оптимальным является такое расписание, когда каждый модуль начинает выполняться, как только завершены все модули, необходимые для его работы. Для случая p процессоров можно распределить модули по процессорам, задав для каждого процессора Распределение модулей по процессорам совместно с графом зависимостей однозначно определяет расписание работ и время выполнения программы при данном расписании. Предполагается, что каждый процессор выполняет модули из распределения Теперь же рассмотрим 2 ситуации: А) Модули программы имеют одинаковое время выполнения; Б) Модули программы имеют разное время выполнения; Первый случай А) 1)При наличии единственного процессора нетрудно видеть, что Действительно, один процессор должен выполнить все модули программы, проходя, например, последовательно один уровень за другим. 2)Для неограниченного количества процессоров: 3)Для ограниченного количества процессоров: Понятно, что p процессоров, начав одновременно работать, могут выполнить вычисление Отсюда следует, что общее время работы  Или та же самая формула, но в упрощенном варианте: 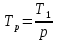 Второй случай Б) Рассмотрим теперь более интересный для практики случай, когда модули программы для своего выполнения требуют разного времени. Пусть
Для каждого из этих модулей известно время, требуемое на его выполнение - 1)При наличии единственного процессора
2)В случае неограниченного количества процессоров Т.е. теперь имеется 2 термина:
Где под временем окончания работы модуля понимается время выполнения того подграфа который ведет к данному модулю, т.е. этот подграф включает в себя все те модули необходимые для выполнения данного модуля. Так как подграфы ведущие к i-м вершинам графа могут пересекаться, то и была введена величина окончания работы модуля для того чтобы упростить задачу оценки времени работы программы на данной системе. Само же время окончания работы модуля рассчитывается по следующей формуле:
Здесь
Тогда время
И теперь становится ясно что время 3)Если же имеет место ограниченное количество процессоров Сложнее получить формулу для вычисления  6.Показатели качества параллельного алгоритма
Ускорение |



 Отношение ускорения к количеству процессоров.
Отношение ускорения к количеству процессоров.