СР 1 ПиДИС. Занятие 28. Тема Базы данных. Тема Понятие базы данных Понятие баз данных Модели данных и структура баз данных
 Скачать 160.5 Kb. Скачать 160.5 Kb.
|

|
Занятие № 28. Тема 7. Базы данных. Тема 7.1. Понятие базы данных Понятие баз данных Модели данных и структура баз данных Реляционная модель данных и реляционная алгебра Структура баз данных Классы систем управления базами данных Множество функций управления данными ФС оказывается недостаточным для решения задач поддержки информационных систем. Предположим, что мы хотим реализовать простую информационную систему, осуществляющую учет сотрудников некоторой организации. Система должна выдавать списки сотрудников в соответствии с указанными номерами отделов, поддерживать функции регистрации перевода сотрудника из одного отдела в другой, приема на работу новых сотрудников и увольнения работающих. Для каждого отдела должна поддерживаться возможность получения имени руководителя этого отдела, обшей численности отдела, общей суммы выплаченной в последний раз зарплаты и т. д. Для каждого сотрудника должна поддерживаться возможность выдачи номера удостоверения по полному имени сотрудника, выдачи полного имени по номеру удостоверения, получения информации о текущем соответствии занимаемой должности сотрудника и о размере зарплаты. Предположим, что мы решили реализовать эту информационную систему на основе файловой системы и пользоваться при этом одним файлом, расширив базовые возможности файловой системы за счет специальной библиотеки функций. Поскольку минимальной информационной единицей в нашем случае является сотрудник, естественно потребовать, чтобы в этом файле содержалась одна запись для каждого сотрудника. Очевидно, что поля таких записей должны содержать полное имя сотрудника (сотр_имя), номер его удостоверения (сотр_номер), информацию о его соответствии занимаемой должности (сотр_статус — для простоты «да» или «нет»), размер зарплаты (СОТР_ЗАРП), номер отдела (сотр_отд_номер). Поскольку мы хотим ограничиться одним файлом, эта же запись должна содержать имя руководителя отдела (сотр_отд_рук). Для выполнения функций нашей информационной системы требуется возможность многоключевого доступа к этому файлу по уникальным ключам (не дублируемым в разных записях) сотр_имя и сотр_номер. Кроме того, должна обеспечиваться возможность выбора всех записей с общим заданным значением сотр_отд_номер, т. е. доступ по неуникальному ключу. Чтобы получить численность отдела или общий размер зарплаты, информационная система должна будет каждый раз выбирать все записи о сотрудниках отдела и подсчитывать соответствующие общие значения. Таким образом, для реализации даже такой простой системы на базе файловой системы: во-первых, требуется создание достаточно сложной надстройки, обеспечивающей многоключевой доступ к файлам; во-вторых, неизбежны существенная избыточность хранения (для каждого сотрудника данного отдела повторяется мя руководителя отдела) и выполнение массовой выборки и вычислений для получения сводной информации об отделах. Вообще, согласованность данных является ключевым понятием баз данных. На самом деле, если информационная система поддерживает согласованное хранение информации в нескольких файлах, можно говорить о том, что она поддерживает базу данных. Если же некоторая вспомогательная система управления данными позволяет работать с несколькими файлами, обеспечивая их согласованность, можно назвать ее системой управления базами данных. Уже только требование поддержания согласованности данных в нескольких файлах не позволяет обойтись библиотекой функций: такая система должна обладать некоторыми собственными данными (метаданными) и даже знаниями, определяющими целостность данных. Далее, представим себе, что в первоначальной реализации информационной системы, основанной на использовании библиотек расширенных методов доступа к файлам, обрабатывается операция регистрации нового сотрудника. Следуя требованиям согласованного изменения файлов, информационная система вставила новую запись в файл сотрудники и приступает к модификации файла отделы, но именно в этот момент произошло аварийное выключение электрического питания. Очевидно, что после перезапуска системы ее база данных будет находиться в рассогласованном состоянии. Потребуется выяснить это (а для этого нужно явно проверить соответствие информации в файлах сотрудники и отделы) и привести информацию в согласованное состояние. Системы управления базами данных (СУБД) берут такую работу на себя. Прикладная система обязана знать, какое состояние данных является корректным, но всю техническую работу принимает на себя СУБД. Наконец, представим себе, что мы хотим обеспечить параллельную (например, многотерминальную) работу с базой данных сотрудников. Если опираться только на использование файлов, то для обеспечения корректности изменений на все время модификации любого из двух файлов доступ других пользователей к этому файлу будет блокирован (вспомните возможности файловых систем для синхронизации параллельного доступа). Таким образом, зачисление на работу Петра Ивановича Сидорова существенно затормозит получение информации о сотруднике Иване Сидоровиче Петрове, даже если ОНИ будут работать в разных отделах. Реальные СУБД обеспечивают гораздо более тонкую синхронизацию параллельного доступа к данным. Таким образом, СУБД решают множество проблем, которые затруднительно или вообще невозможно решить при использовании файловых систем. При этом существуют: приложения, для которых вполне достаточно файлов; приложения, для которых необходимо решать, какой уровень работы с данными во внешней памяти для них требуется; приложения, для которых безусловно нужны базы данных. Модели данных и структура БД Понятие МД в первую очередь относится к фактографическим или табличным БД. Поскольку в данном случае БД является информационной моделью определенной предметной области, существенной особенностью всякой БД является структура или, как принято говорить, модель данных (МД). Рассмотрим некоторые наиболее известные (или «замечательные») модели данных — иерархическую, сетевую, реляционную. Иерархическая МД (НМД). Впервые реализована в СУБД IBM — IMS (Information Management System), разработанной для поддержки банка данных по программе Apollo. При данном подходе предметная область представляется в виде совокупности структур иерархического типа (граф — «дерево»). Основные понятия НМД: поле — минимальная единица данных; сегмент (узел) — совокупность полей, являющаяся единицей обмена между БД и прикладной программой. Сегмент (узел иерархического графа) более высокого уровня называется исходным (родительским) по отношению к ниже расположенному порожденному (отпрыску). Может использоваться также терминология «узел, принадлежащий вышестоящему узлу». Конкретные данные, входящие в сегмент, называются экземпляром сегмента. В ИМД существуют также следующие понятия: брат — узел, имеющий того же родителя, что и другой узел; ветвь — узел дерева вместе со всеми его отпрысками, отдаленными потомками и родительскими источниками; лист — узел, у которого нет отпрысков; обход дерева — процесс обследования по очереди каждого узла дерева в иерархической модели данных, и пр. Преимущества IMS и реализованной в ней иерархической модели: простота модели. Принцип построения IMS легок для понимания. Иерархия базы данных напоминает структуру компании или генеалогическое дерево; использование отношений предок/потомок. СУБД IMS позволяла легко представлять отношения предок—потомок (или часть—целое, причина—следствие), например: «А является частью В» ИЛИ «А владеет В»; быстродействие. В СУБД IMS отношения предок/потомок были реализованы в виде физических указателей от одной записи к другой, вследствие чего перемещение по базе данных происходило быстро. Поскольку структура данных в этой СУБД отличалась простотой, IMS могла размещать записи предков и потомков на диске рядом друг с другом, что позволяло свести к минимуму количество операций записи-чтения. Существенно то, что физическая организация БД в этом случае такова, что выбрать конкретные сведения об объектах можно, лишь пройдя всю цепочку групп (сегментов) сверху вниз (путь на иерархическом дереве). Данная схема наиболее проста, но не лишена очевидных недостатков. В частности, в связи с полииерархичностью связей объектов в реальном мире в подобных БД необходимо создавать и поддерживать несколько иерархических отношений, что нарушает основную идею модели данных. Сетевая модель данных (модель CODASYL). В предложенной CODASYL модификации иерархической модели одна запись могла участвовать в нескольких отношениях предок/потомок. В сетевой модели такие отношения называются множествами (set). В 70-е гг. независимые производители программного обеспечения реализовали сетевую модель в таких продуктах, как IDMS компании Cullinet, Total компании Cincom, которые приобрели большую популярность. Сетевые БД обладали рядом преимуществ: • гибкость — множественные отношения предок—потомок позволяют сетевой БД хранить данные, структура которых сложнее обычной иерархии; стандартизованностъ — соответствие стандарту CODASYL; быстродействие — вопреки своей сложности, сетевые БД достигали быстродействия, сравнимого с быстродействием иерархических БД. Множества были представлены указателями на физические записи данных, и в некоторых системах администратор мог задать кластеризацию данных на основе множества отношений. Недостаток — жесткость БД, наборы отношений и структуру записей приходилось задавать заранее. Изменение структуры данных означало перестройку всей БД. Реляционная модель данных и операции над отношениями В то время как иерархическая модель в своей основе является формализацией и обобщением пользовательских свойств некоторой конкретной системы (IMS), в случае реляционной модели сначала были разработаны некоторые математические основы и лишь через 5—10 лет появились первые коммерчески эффективные системы. Реляционная модель предложена сотрудником компании IBM Е. Ф. Коддом в 1970 г. В настоящее время эта модель является фактическим стандартом, на который ориентируются практически все современные коммерческие СУБД. В реляционной модели достигается гораздо более высокий уровень абстракции данных, чем в иерархической или сетевой. Это обеспечивается за счет использования математической теории отношений (само название «реляционная» происходит от английского relation — «отношение»). Определения. Перейдем к рассмотрению структурной части реляционной модели данных. Прежде всего необходимо дать несколько определений. Декартово произведение: для заданных конечных множеств D1, D2, ..., DN(не обязательно различных) декартовым (прямым) произведением Например, если даны два множества Отношение: отношением R, определенным на множествах D1, D2, ..., DNназывается подмножество декартова произведения множества D1, D2, ..., DNназываются доменами отношения; элементы декартова произведения {d1, d2, ..., dN] называются кортежами; число N определяет степень отношения (N= 1 — унарное, N= 2 — бинарное, ..., N-арное); количество кортежей называется мощностью отношения; На множестве С из предыдущего примера могут быть определены отношения Отношения удобно представлять в виде таблиц. Строки таблицы называются экземплярами отношения, столбцы — атрибутами; каждый атрибут имеет область значений, называемую доменом. На рис.1 представлена таблица (отношение степени 5), содержащая некоторые сведения о деталях автомобилей. 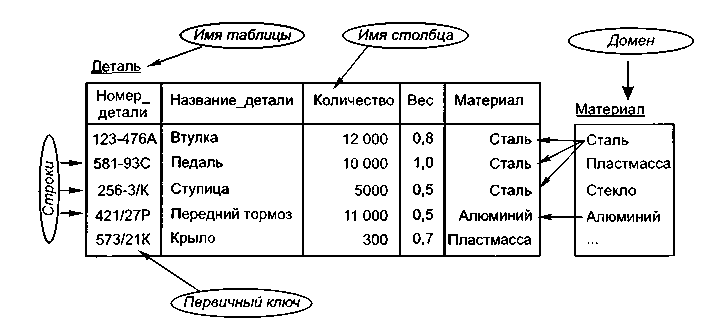 Рис.1. Таблица (отношение) реляционной модели данных Так, таблица Деталь содержит сведения обо всех деталях, хранящихся на складе, а ее строки являются наборами значений атрибутов конкретных деталей. Каждый столбец таблицы — это совокупность значений конкретного атрибута объекта. Столбец Материал может содержать конечный перечень значений — Сталь, Олово, Цинк, Никель и т. д. В столбце Количество содержатся целые неотрицательные числа. Значения в столбце Вес — вещественные числа, равные весу детали в килограммах. Каждый атрибут определен на домене, поэтому домен (domain) можно рассматривать как множество допустимых значений данного атрибута. Так, значения в столбце Материал выбираются из множества имен всех возможных материалов — пластмасс, древесины, металлов и т. д. Следовательно, в столбце Материал невозможно появление значения, которого нет в соответствующем домене, например, Вода или Песок. Каждый столбец имеет имя, которое обычно записывается в верхней части таблицы (рис. 1). Оно должно быть уникальным в таблице, однако различные таблицы могут иметь столбцы с одинаковыми именами. Любая таблица должна иметь по крайней мере один столбец; столбцы расположены в таблице в соответствии с порядком следования их имен при ее создании. В отличие от столбцов, строки не имеют имен; порядок их следования в таблице не определен, а количество логически не ограничено. Так как строки в таблице не упорядочены, невозможно выбрать строку по ее позиции — среди них не существует «первой», «второй», «последней». Любая таблица имеет один или несколько столбцов, значения в которых однозначно идентифицируют каждую ее строку. Такой столбец (или комбинация столбцов) называется первичным ключом (primary key). В таблице Деталь первичный ключ — это столбец Номер_детали. В нашем примере каждая деталь на складе имеет единственный номер, по которому из таблицы Деталь извлекается необходимая информация. Следовательно, в этой таблице первичный ключ — это столбец Номер_детали. В этом столбце значения не могут дублироваться — в таблице Деталь не должно быть строк, имеющих одно и то же значение в столбце Номер_детали. Если таблица удовлетворяет этому требованию, она называется отношением (relation). Взаимосвязь таблиц является важнейшим элементом реляционной модели данных. Она поддерживается внешними ключами (external). Рассмотрим пример, в котором база данных хранит информацию о рядовых служащих (таблица Служащий) и руководителях (таблица Руководитель) в некоторой организации (рис. 2). Первичный ключ таблицы Руководитель — столбец 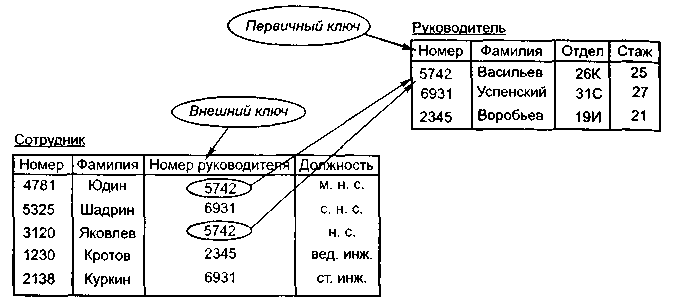 Рис. 2. Взаимосвязь таблиц базы данных Номер (например, табельный номер). Столбец Фамилия не может выполнять роль первичного ключа, так как в одной организации могут работать два руководителя с одинаковыми фамилиями. Любой служащий подчинен единственному руководителю, что должно быть отражено в базе данных. Таблица Служащий содержит столбец Номер_руководителя, и значения в этом столбце выбираются из столбца Номер таблицы Руководитель (см. рис. 2). Столбец Номер_Руководителя является внешним ключом в таблице Служащий. Таблицы невозможно хранить и обрабатывать, если в базе данных отсутствуют «данные о данных» (метаданные), например, описатели таблиц, столбцов и т. д. Метаданные также представлены в табличной форме и хранятся в словаре данных (DD — data dictionary) или описателе БД (DBD — data base definition) — служебном файле или системной таблице БД. Помимо таблиц в базе данных могут храниться и другие объекты, такие, как экранные формы, отчеты (reports), представления (views) и прикладные программы, работающие с базой данных. Для пользователей информационной системы недостаточно, чтобы база данных просто отражала объекты реального мира. Важно, чтобы такое отражение было однозначным и непротиворечивым. В этом случае говорят, что база данных удовлетворяет условию целостности (integrity). Для того чтобы гарантировать корректность и взаимную непротиворечивость данных, на базу данных накладываются некоторые ограничения, которые называют ограничениями целостности (data integrity constraints). Существует несколько типов ограничений целостности. Требуется, например, чтобы значения в столбце таблицы выбирались только из соответствующего домена. На практике учитывают и более сложные ограничения целостности, например целостность по ссылкам (referential integrity). Ее суть заключается в том, что внешний ключ не может быть указателем на несуществующую строку в таблице. Свойства отношений. Отсутствие кортежей-дубликатов. Из этого свойства вытекает наличие у каждого кортежа первичного ключа. Для каждого отношения, по крайней мере, полный набор его атрибутов является первичным ключом. Однако при определении первичного ключа должно соблюдаться требование минимальности, т. е. в него не должны входить те атрибуты, которые можно отбросить без ущерба для основного свойства первичного ключа — однозначно определять кортеж. Отсутствие упорядоченности атрибутов. Для ссылки на значение атрибута всегда используется имя атрибута. Атомарность значений атрибутов, т. е. среди значений домена не могут содержаться множества значений (отношения). Реляционная алгебра. Важным отличием РМД является возможность применения формального аппарата, описывающего преобразование и обработку данных в РМД — реляционной алгебры. Операндами реляционной алгебры являются отношения как постоянные, так и переменные. Операции реляционной алгебры включают следующие преобразования отношений. А. Теоретико-множественные операции над несколькими подобными (имеющими одинаковую структуру: число атрибутов, их имен, домены и т. д.), отношениями, в том числе объединение, пересечение, разность. Б. Операции над одним отношением: • селекция, или построение отношения-результата из отношения-источника путем отбора экземпляров, удовлетворяющих некоторому критерию отбора. Операция селекции соответствует поиску информации в БД по логическим условиям; (find ... with, find...where, locate); • проекция, или построение результирующего отношения путем отбора части атрибутов всех экземпляров исходного отношения. Данной операции в реальных СУБД соответствует понятие пользовательской подсхемы и операции выдачи необходимых данных (display, view, set form то, report form...). В. Операции над несколькими различными отношениями. Назовем только естественное соединение (соединение). Операция заключается в поиске в паре (или большем числе) отношений строк, содержащих общий атрибут, и создания из этих строк экземпляра результирующего отношения. В СУБД соединению соответствует поиск связанных данных или логическое (физическое) связывание файлов (find. . .coupled, set relation то, join). Реляционная алгебра позволяет рассматривать операции ввода, вывода, поиска коррекции и удаления данных в БД как вычисление отношений-результатов через исходные отношения. При этом исходным отношением может быть внешний (входной) формат данных, а результирующим — внутренний (хранимый) или, наоборот, исходным — внутренний, а результирующим — внешний (выходной). Структуры баз данных Рассмотрим вкратце обобщенные логическую и физическую структуры БД. Логическая структура БД (рис. 5.9) предполагает следующие уровни рассмотрения БД: • база данных (database) — включает одну или несколько подбаз (файлов, таблиц, массивов), каждая из которых состоит из агрегатов данных (записей, документов) — record. Запись идентифицируется внутренним номером (ISN — internal sequential number, BH3 — внутренний номер записи, SDN — sequential document number и пр.); запись (документ) — совокупность разнотипных и разноструктурных данных, описывающих (относящихся к) объект реального мира, элемент предметной области АИС. Запись состоит из полей (field); поле — именованный элементарный или составной фрагмент записи (документа), содержащий информацию об определенном аспекте (аспектах) элемента (элементов) предметной области. элементарные (имеющие фиксированную или ограниченную длину) и не содержащие входящих в них структур данных; составные (групповые) поля, образующиеся как агрегаты элементарных и также имеющие фиксированную и ограниченную длину (реже — переменную или неопределенную, что связано с количеством вхождений элемента в агрегат); текстовые — поля переменной (неопределенной) длины и сложной внутренней структуры (обычно это иерархическая последовательность типа раздел – подраздел – предложение - слово); бинарные — данные, интерпретируемые как поля, однако обычно физически не входящие в состав записей БД. Необходимо отметить, что поля данного типа (BLOB — Binary Large Object) фактически являются данными, до обработки которых данная СУБД еще «не доросла» и поэтому работа с ними возлагается на пользователя (прикладные программы). В частности, в системах FoxBase и Clipper большие текстовые (так называемые MEMO) поля также не обрабатываются системой и фактически оказываются в статусе BLOB; типы данных, определяемые пользователем. Далеко не все современные СУБД поддерживают типы данных, определенные пользователем. Пока только СУБД Ingres включает такой механизм. Эта система предоставляет программисту возможность определять собственные типы данных и операции над ними и использовать их в операторах SQL. Для определения нового типа данных необходимо написать и откомпилировать функции на языке Си, после чего собрать редактором связей некоторые модули Ingres. Отметим, что введение новых типов данных является, по сути, изменением ядра СУБД. Важно также то, что в Ingres типы данных, определяемые пользователем, могут быть параметризованными. Определение нового типа данных сводится к указанию его имени, размера и идентификатора в глобальной структуре, описывающей типы данных. Чтобы с новым типом данных можно было использовать функции, которые реализуют стандартные операции (сравнение, преобразование в различные форматы, и т. д.), программист должен разработать их самостоятельно (интерфейс функций предопределен). Указатели на эти функции являются элементами глобальной структуры. Как только новый тип данных определен, то все операции выполняются над ним, как над данными стандартного типа. Разрешение пользователю создавать собственные типы данных по сути является одним из шагов развития реляционных СУБД в направлении объектно-реляционных систем. Поля, указанные в заштрихованных прямоугольниках относятся к фактографическим АИС, остальные — к документальным. Физическая структура БД в общем случае имеет вид, приведенный на , и включает следующие компоненты: • файл (файлы) исходных (первичных) данных (текстов, бинарных данных) содержит собственно объекты, подлежащие поиску, обработке и пр.; файл (файлы) вторичной (справочной) информации (регистрационные карты, библиографические реестры и пр.) содержит описания исходных элементов (объектов). Важным видом справочных файлов являются классификаторы, кодификаторы, тезаурусы, обеспечивающие полноту и компактность представления информации в БД; индекс — файл (файлы), связывающий адрес (номер) объекта с его содержанием (значением атрибута объекта), обычно состоит из инверсного списка и частотного словаря, который облегчает составление запросов на поиск и повышает обозримость БД; словарь данных — файл, содержащий составленное с необходимой степенью подробности описание состава БД, документов, записей, агрегатов данных, их имена, типы и структуры, способы интерпретации и обработки. Изменение содержания БД может осуществляться как в режиме конечного пользователя (диалоговый ввод или коррекция записей/документов по полям) — обычный для СУБД и редкий для АИПС, так и в режиме администратора БД (обычный для АИПС и реже для СУБД), при этом происходит массовый ввод или загрузка записей / документов. При любом виде добавления документа/записи для каждого поля осуществляется анализ, обработка и согласованное помещение документа и его фрагментов в соответствующие физические файлы БД. В конкретных случаях возможна менее полная комплектность приведенной физической схемы: в фактографических (табличных) БД вторичный файл может являться основным накопителем информации, а текстовые и бинарные данные фигурируют в качестве необязательного приложения; в справочно-библиографических БД текстовые данные находятся во вторичном файле, а первичный отсутствует; в БД с полнотекстовым поиском может отсутствовать вторичный файл, а индексирование (построение частотных словарей и инверсных списков) проводится по первичному файлу (страницы или абзацы полных текстов); может отсутствовать частотный словарь или инверсный список. Надо отметить также вариативность физической реализации и взаимосвязи лингвистического и информационного обеспечения АИС: словарь данных может физически входить в информационные файлы (первичный или вторичный); классификаторы, кодификаторы, тезаурусы могут быть оформлены как физическими файлами (файлами ОС), так и входить в состав БД в виде отдельных таблиц (файлов БД, массивов и пр.) на логическом уровне и т. п. Классы и структуры систем управления базами данных Проблемы совместного использования данных и периферийных устройств компьютеров и рабочих станций породили модель вычислений, основанную на концепции файлового сервера — сеть создает основу для коллективной обработки, сохраняя простоту использования персонального компьютера, позволяет совместно использовать данные и периферию. В этом смысле главной отличительной чертой БД является использование централизованной системы управления данными, причем как на уровне файлов, так и на уровне элементов данных. Централизованное хранение совместно используемых данных приводит не только к сокращению затрат на создание и поддержание данных в актуальном состоянии, но и к сокращению избыточности информации, упрощению процедур поддержания непротиворечивости и целостности данных. СУБД (DBMS — database management system) — комплекс языков и программ, позволяющий создавать БД и управлять ее работой. СУБД обрабатывает поступающие от пользователей и прикладных процессов обращения к БД, а затем выдает необходимые им сведения. СУБД характеризуется используемой моделью и средствами администрирования, разработки прикладных процессов, работы в информационной сети. Эффективное управление внешней памятью является основной функцией СУБД. Эти, обычно специализированные, средства определяют эффективность системы. Без них она не сможет выполнять некоторые задачи уже потому, что их выполнение будет занимать слишком много времени. При этом ни одна из таких специализированных функций, как построение индексов, буферизация данных, организация доступа и оптимизация запросов, не является видимой для пользователя и обеспечивает независимость между логическим и физическим уровнями системы. СУБД обеспечивает: описание и контроль данных; манипулирование данными (запись, поиск, выдачу, изменение содержания); физическое размещение (изменение размеров блоков данных, записей, использование занимаемого пространства, сортировку, сжатие, кодирование и пр.); защиту от сбоев, поддержку целостности и восстановление; работу с транзакциями и файлами; безопасность данных. Существует несколько типов СУБД. Эволюционно они прошли путь от систем, использовавших иерархическую и сетевую модели данных к реляционным и объектно-ориентированным. В иерархической системе управления базой данных данные в соответствии с ветвящимся деревом их признаков располагаются в двухмерных файлах и образуют деревья признаков. Соответственно этому происходит и поиск необходимых сведений. В реляционных системах управления базами данных данные представляются в форме таблиц, определяющих взаимосвязь записей. Реляционные СУБД характеризуются простотой, гибкостью и точностью. Каждая из них одновременно работает с данными, размещенными в нескольких таблицах. Поэтому, реляционные БД ориентированы на быстрый доступ к небольшим объемам данных. Объектно-ориентированные системы управления базами данных основываются на объектно-ориентированной архитектуре. Они позволяют работать со сложными типами данных, хранимых в виде объектов; отличаются высокой производительностью при обработке транзакций (особенно эффективны при обработке изображений). Их возникновение обусловлено потребностями разработки сложных информационных систем, неудовлетворенных технологиями предшествующих БД. В таких СУБД должны быть решены проблемы поддержки иерархии и наследования типов, управления сложными объектами. Решение этих задач сталкивается с ограничениями: отсутствием общепринятой объектно-ориентированной модели данных, декларативного языка запросов и т. п. Гибридные системы управления базами данных объединяют положительные качества реляционных и объектно-ориентированных систем. Они соединяют средства обработки транзакций реляционных СУБД с поддержкой многочисленных типов данных объектно-ориентированных СУБД. Кроме этого, системы управления базами данных можно классифицировать: По используемому языку общения: замкнутые, имеющие собственные самостоятельные языки общения пользователей с БД. Они обеспечивают непосредственное общение с системой в режиме диалога, позволяют работать без программистов; открытые, в которых для общения с БД используется язык программирования, «расширенный» операторами языка манипулирования данными (ЯМД). В этом случае необходимо участие квалифицированного программиста. По числу поддерживаемых СУБД уровней моделей данных: одно-, двух-, трехуровневые системы. Теоретически обоснован выбор трехуровневой архитектуры данных, однако на практике СУБД для персональных ЭВМ часто объединяют концептуальный и внутренний уровни представления. По выполняемым функциям: операционные, предполагающие иные виды обработки по получению информации, не хранящейся в явном виде в БД; информационные, позволяющие организовать хранение данных, поиск и выдачу нужных данных из БД и поддерживать их целесообразность и актуальность. По сфере применения: универсальные, настраиваемые на любую предметную область путем создания соответствующей БД и прикладных программ; проблемно-ориентированные на определенные процедуры обработки данных, присущих конкретной области применения. В структурном составе СУБД могут быть выделены ядро и среда (рис.3). Ядро СУБД — программный комплекс (модуль или модули), обеспечивающий непосредственное выполнение физических операций над БД (в ранних системах функции Ядра выполняли программы методов доступа ОС ЭВМ). Среда — совокупность интерфейсных модулей, обеспечивающих связь пользователей с Ядром и через него с БД. Среда включает в себя пользовательские интерфейсы и утилиты администратора БД (АБД).  Рис. 3. Типичная структура системы управления базами данных Утилиты АБД образуют библиотеку программ обслуживания БД в привилегированном режиме (работа пользовательских средств параллельно утилитам не разрешена) и выполняют основные функции, к которым относятся: физическая подготовка дисковой памяти к размещению БД; подготовка справок о составе БД, структуре файлов, количестве данных и занимаемом объеме; загрузка файла БД из последовательного набора данных ОС; дозагрузка (расширение существующего файла); модификация БД: расширение или перемещение физических наборов данных, реорганизация; модификация файла (таблицы, группы таблиц): добавление новых полей в структуру записи; инвертирование полей или освобождение (превращение инвертированных полей в сканируемые); выгрузка образа БД (файла таблицы) для сохранения в архивном наборе данных; создание и ведение словаря данных и др. Средства пользователя. Стандартными средствами этого типа, предоставляемыми фирмой-разработчиком, являются следующие: диалоговые интерфейсы; генераторы отчетов; система конструирования и поддержки интерактивных технологий в информационных системах (ЯП АИС). Контрольные вопросы Понятие баз данных Модели данных и структура баз данных Реляционная модель данных и реляционная алгебра Структура баз данных Классы систем управления базами данных |