Обзор исследований распознавания рукописных текстов с помощью сп. Обзор исследований распознавания рукописных текстов
 Скачать 110.39 Kb. Скачать 110.39 Kb.
|

|
ОБЗОР ИССЛЕДОВАНИЙ РАСПОЗНАВАНИЯ РУКОПИСНЫХ ТЕКСТОВ Ключевые слова: методы распознавания изображений,распознавания рукописных текстов, искусственные нейронные сети В настоящее время распознавание рукописных текста является всё более обсуждаемой и актуальной темой. В современном мире работа с текстами является частью практически всех сфер деятельности человека. Печать отредактированных цифровых текстов – постоянная практика, не требующая изучения. Однако в последнее время своё распространение получила обратная процедура – считывание текста с отсканированного изображения или документа и последующее его редактирование. Цель: Обзор исследований распознавания рукописных текстов с помощью специальных программ. Задачи: · Рассмотреть проблемы распознавания рукописного текста. · Изучить существующие методы распознавания. · Проанализировать способы работы с рукописным текстом. · Охарактеризовать существующие программы по распознаванию рукописного текста и выявить их проблемы. Различают три основных группы методов распознавания:
Использование статистических методов классификации в распознавании образов возможно, когда для распознавания данных достаточно простых численных и символических признаков для описания объекта, таких как площадь символа, высота ширина описывающего прямоугольника, чтобы установить меры сходства образов.
Методы структурного анализа применимы в тех задачах, в которых важна информация, описывающая структуру каждого объекта, а от процедуры распознавания требуется, чтобы она давала возможность не только отнести объект к определенному классу (классифицировать его), но и описать те стороны объекта, которые исключают его отнесение к другому классу. Типичным примером таких задач служит распознавание изображений. В случае, когда объекты сложны и число требуемых признаков часто велико, описание сложного объекта в виде иерархической структуры более простых подобразов становится обоснованным. Перспективной альтернативой традиционным методам решения задач распознавания образов являются нейронные сети (НС). Это активно развивающееся направление на сегодняшний день. Растут области применения нейронных сетей, появляются новые модели НС, существующие модели адаптируются для решения новых задач и т.д [2]. 3. Искусственные нейронные сети – это математические модели, построенные по принципу организации и функционирования биологических нейронных сетей – сетей нервных клеток живого организма [3]. Основные преимущества нейронных сетей:
Устойчивость к шумам входных данных. Нейронные сети могут быть обучены сложной структуре образов с меньшими затратами памяти, чем требуется для классификации структурными методами. Параллельность работы нейронов обеспечивает быстрое и качественное распознавание текстов. Анализ методов распознавания и указанные в литературе многочисленные случаи успешного использования искусственных нейронных сетей, а также перспективность их развития привели к выбору нейросетевого метода. Распознавание рукописного ввода и его проблемы Распознавание рукописного ввода – это способность компьютера получать и интерпретировать интеллектуальный рукописный ввод. Одной из лучших программ распознавания рукописных текстов для мобильных устройств сегодня является PenReader. PenReader - единственная в мире система, полноценно работающая с русским и белорусским (!) рукописным вводом на Pocket PC/Windows Mobile. PenReader для качества распознавания рукописного ввода в использует 500,000 различных образцов почерка. PenReader применяет графический и орфографический анализ. PenReader в режиме динамического самообучения анализирует надежность распознавания и при необходимости выводит окно подсказки, содержащее возможные варианты ответов. Пользователю остается только подтвердить правильный вариант. Нескольких таких подтверждений (обычно 7-9) достаточно, чтобы система запомнила трудное или новое написание. Существующие системы распознавания Система распознавания текста предполагает наличие на входе изображения с текстом (в формате данных графического файла). На выходе системы должен сформироваться текст, выделенный из этого изображения. Распознавание текста включает в себя следующие подзадачи и подпроцессы. 1. Поступающее на вход системы изображение должно быть очищено от шума и приведено к виду, позволяющему эффективно выделять символы и распознавать их. 2. Система должна разбить изображение на блоки текста, основываясь на особенностях его выравнивания и распределения по нескольким колонкам. 3. Изображение с текстом должно быть разделено на изображения строк, а затем на изображения символов для того, чтобы в дальнейшем обработать каждый символ по отдельности. После данного шага разные системы распознавания работают по своим специфическим алгоритмам. 4. Изображение символа может обрабатываться целиком, для этого оно сравнивается с имеющимися шаблонами. Другим вариантом является выделение характеристик изображаемого символа: отбор характерных признаков, и классификация данных признаков по имеющимся в системе критериям. На выходе четвертого шага появляется возможный вариант буквы. Однако обычно системы на этом не останавливаются и продолжают работу на основе других методов, уточняя полученный результат. 5. Результат распознавания может быть не удовлетворительным. Для получения более хороших результатов в системе может быть встроен блок обучения. С помощью этого блока можно задать системе примеры начертания разных букв в данном шрифте. После процесса обучения предполагается лучшее качество распознавания текста. Система распознавания текста не всегда должна следовать всем описанным шагам, но основные действия процесса распознавания являются общими для любого алгоритма. 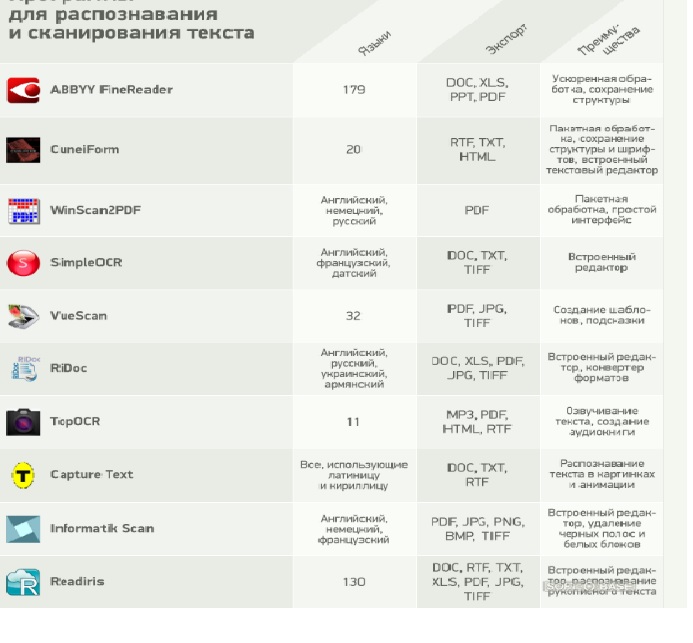 Характеристики программы и её особенности Единственным серьёзным производителем на IT-рынке считается корпорация АВВУУ с программой FineReader, которая поддерживает как печатный, так и рукописный текст. В ней распознать текст можно со сканера и МФУ, снимков с камер мобильных устройств. Примечательна функция добавления неизвестного слова в словарь программы. Но не стоит упускать, что программы распознавания в этой компании создаются с уклоном на стандартную документацию компаний, так как именно они и являются основными её потребителями. Продукты АВВУУ не рассчитаны на нестандартные форматы и не способны дать высокий уровень достоверности распознавания рукописей. У АВВУУ FineReader имеются такие версии программы, в которых она приобретает свойство распознавания рукописного текста после обучения, однако, если пользователь будет пытаться распознать в одной программе несколько образцов почерка разных людей, он не сможет получить результат. Новая версия программы для автоматического распознавания символов FineReaderEngine 11 OCRSDK, которая позволяет использовать функции OCR (оптического распознавания текста), OMR (оптического распознавания меток) и ICR (распознавания рукопечатных символов), работа с рукописями художественных и исторических произведений и документов, отличающихся сложностью почерков, едва ли возможна. Такие проекты, как GoogleDocs и GoogleBooks имеют аналогичную проблему. Заключение Основные иностранные разработки в области распознавания рукописного текста направлены главным образом на решение проблем, связанных с сегментацией текста, ускорением обработки информации и избавлением от шумов. Они ориентированы и на увеличение количества языков, с которыми можно работать в системах распознавания. Однако в настоящее время нерешенных прикладных и теоретических проблем значительно больше, чем достижений. Рукописный текст распознать крайне непросто, так как на распознавание приходится лишь небольшая часть. Основная часть этой задачи заключается в понимании компьютером смысла документа. Решить задачу распознавания текста с высоким результатом можно будет только когда компьютер сможет, подобно человеку, анализировать и понимать информацию в тексте. Библиографический список Шамис А.Л. Принципы интеллектуализации автоматического распознавания изображений и их реализация в системах оптического распознавания символов//Новости искусственного интеллекта – 2000. Гайдуков Н.П., Савкова Е.О. Обзор методов распознавания рукописного текста – 2012. StatSoft – сайт, посвященный нейронным сетям. Jürgen Schmidhuber. Winning Handwriting Recognition Competitions Through Deep Learning, 2009-2013. Dan Cires¸an and Jurgen Schmidhuber. Multi-Column Deep Neural Networks for Offline Handwritten Chinese Character Classification – 2013. |