Образец отчёа по учебной практике. Отчет по учебной практике Обзор методов распознавания языка произвольного текста тема студента(ки) Иванниковой Ольги Валерьевны группы авт фио студента(ки)
 Скачать 311.33 Kb. Скачать 311.33 Kb.
|

|
МИНИСТЕРСТВО НАУКИ И ВЫСШЕГО ОБРАЗОВАНИЯ РОССИЙСКОЙ ФЕДЕРАЦИИ ФЕДЕРАЛЬНОЕ ГОСУДАРСТВЕННОЕ БЮДЖЕТНОЕ ОБРАЗОВАТЕЛЬНОЕ УЧРЕЖДЕНИЕ ВЫСШЕГО ОБРАЗОВАНИЯ «НОВОСИБИРСКИЙ ГОСУДАРСТВЕННЫЙ ТЕХНИЧЕСКИЙ УНИВЕРСИТЕТ» ФАКУЛЬТЕТ АВТОМАТИКИ И ВЫЧИСЛИТЕЛЬНОЙ ТЕХНИКИ КАФЕДРА ВЫЧИСЛИТЕЛЬНОЙ ТЕХНИКИ ОТЧЕТ по учебной практике Обзор методов распознавания языка произвольного текста тема студента(ки) Иванниковой Ольги Валерьевны группы АВТ- ФИО студента(ки) Место проведения практики: Новосибирский государственный технический полное наименование предприятия (организации) университет Сроки практики по учебному плану: с 1.09.2020 по 30.12.2020 Руководитель практики от университета: Коршикова Лариса Александровна подпись , оценка к.т.н., доцент кафедры ВТ ФИО, должность Оценка по итогам аттестации студента НОВОСИБИРСК 2020 СодержаниеФАКУЛЬТЕТ АВТОМАТИКИ И ВЫЧИСЛИТЕЛЬНОЙ ТЕХНИКИ 1 КАФЕДРА ВЫЧИСЛИТЕЛЬНОЙ ТЕХНИКИ 1 Введение 3 1 Описание кафедры вычислительной техники 4 1.1 Современное состояние материально-технической базы кафедры ВТ 4 1.2 Организация учебного процесса на кафедре ВТ 5 1.3 Организация НИР на кафедре ВТ 9 2 ОСНОВНАЯ ЧАСТЬ. ТЕМА РЕФЕРАТА - Обзор методов распознавания языка произвольного текста 13 2.1 Определение языка с помощью наивного Байесовского классификатора 13 2.1.1 Понятие N-граммы 16 2.1.2 Оценка точности классификатора на основе наивного Байесовского классификатора 17 2.1.3 Выводы по использованию наивного Байесовского классификатора в задаче по распознаванию языка текста 20 2.2 Определение языка с помощью нейронных сетей 20 2.2.1 Эвристика в категоризации веб-документов 20 2.2.2 Описание эксперимента по определению языка нейронными сетями 22 2.2.3 Выводы по использованию нейронных сетей в задаче по распознаванию языка текста 25 Заключение 27 Список источников 28 ВведениеЗадача Учебной Практики – Войти в проблему « УЧЕБНЫЙ ПРОЦЕСС ». Познакомиться со структурами – ФАКУЛЬТЕТ, КАФЕДРА, с учебными аудиториями, с терминальными классами, с техническим обеспечением учебного процесса. В виде отчетности – получить ( выбрать) индивидуальное задание по тематике, связанной с направлением обучения в Университете. В ходе данной работы необходимо произвести поиск, детальный анализ и структурирование информации о существующих методах реализации данной проблемы. Необходимо составление библиографического списка по заданной теме, его анализ. Необходимо также составить описание кафедры вычислительной техники НГТУ, включая современное состояние материально-технической базы, организацию учебного процесса и научно-исследовательской работы на кафедре. Во время прохождения практики необходимо вести дневник практики, самостоятельно составив себе план работы (план прохождения практике в шаблоне Дневника подробно расписан!), а по её результатам – составить отчёт. 1 Описание кафедры вычислительной техники1.1 Современное состояние материально-технической базы кафедры ВТВ настоящее время кафедра вычислительной техники располагает парком персональных компьютеров из более 70-ти машин, имеет свой кафедральный сервер с автономным энергообеспечением для защиты имеющихся информационных материалов, а также 1-й сегмент суперкомпьютерной грид-системы с включением в нее терминальных классов «Тонкий клиент» (ауд 301, 302) и лабораторий (ауд. 304, 307, 320). Все аудитории кафедры обеспечены мультимедийными проекторами, как стационарными, так и переносными, а аудитории 303, 318 – интерактивными досками. В дополнение к существующему оборудованию для занятий по дополнительному образованию (подготовка «Web-дизайнеров») кафедрой закуплено и используется специальное художественное оборудование в ауд. 313. Всего в настоящее время установлено оборудования на сумму, превышающую 21 млн. рублей. В перспективе предстоит расширение лабораторных комплексов на базе «Grid System» и «Cisco Systems», что позволит значительно улучшить качество преподавания и расширить возможности научно-исследовательской работы. Приказом №162 от 11 июня 2010 г. на кафедре ВТ образован научно-образовательный центр «Прикладной анализ данных». Основные его задачи: оказание различных научно-исследовательских и образовательных услуг, не предусмотренных университетскими планами научных работ и основными учебными планами направлений и специальностей, по которым ведется обучение в НГТУ. За время работы центра подготовлено 56 специалистов в области «Web-дизайн» и в сетевых специалистов «Cisco Systems». По итогам выполнения ИОП «Высокие технологии» приказом по университету №205 от 2 марта 2009 г. на базе средств «Grid System» был создан центр коллективного пользования «Распределенные вычислительные системы». Основными направлениями его деятельности являются: предоставление доступа сотрудников, студентов и сторонних лиц к высокопроизводительным вычислительным ресурсам, развитие совместно с другими подразделения университета информационно-вычислительной среды и связь ее с глобальными грид-сетями, обучение и переобучение студентов и специалистов суперкомпьютерной технике, распределенным и параллельным информационным технологиям, проведение НИР в этом направлении. Приказом №2129 от 27 декабря 2011 г. в рамках инновационного гранта на кафедре был создан «Информационно-аналитический центр информационных технологий и цифровых систем», основными задачами которого являются: обеспечение инновационных подразделений НГТУ и других внутренних и внешних потребителей профильной аналитической научно-технической информацией, касающейся мониторинга и анализа текущего состояния дел по тематике центра, прогноз ее развития, экспертиза инноваций в отрасли информационных технологий и цифровых систем, оказание помощи в участии в профильных платформах и образовательных услуг. [12] На базе кафедры не создано никаких научных школ [13]. 1.2 Организация учебного процесса на кафедре ВТБогатая материально-техническая база кафедры позволяет обеспечить студентов возможностями обучения разнородным средствам вычислительной техники и телекоммуникаций. Так, например, установленный сегмент грид-системы позволяет студентам обучаться и работать на типовых персональных компьютерах, рабочих станциях, как отдельных элементах, так и встроенных в грид-систему. Кафедра вычислительной техники предоставляет обучение студентов по направлениям бакалавриата [14], магистратуры [15] и аспирантуры [16], представленным в таблице 1.2.1. Кафедра не ведёт подготовку специалистов. Таблица 1.2.1 Направления обучения на кафедре ВТ
С 2016 г. кафедра ВТ совместно с кафедрой ЗИ открыла направление магистратуры с профилем «Кибербезопасность информационных систем»: дисциплины, относящиеся к информационным технологиям, ведут преподаватели кафедры ВТ, а дисциплины, относящиеся к безопасности – преподаватели кафедры ЗИ. В рамках образовательной работы кафедра осуществляет следующую деятельность: Обеспечение лабораторных работ, практических занятий, семинаров, лекций, презентаций по проблемам сетевых технологий и защите информации в рамках образовательных программ. В настоящее время существует 252 учебных курса. Адаптация учебных и сертификационных материалов Cisco для образовательных целей. Разработка учебно-методических комплексов для дисциплин, по которым в лабораториях будут проводиться занятия. В связи с появлением в университете двухуровневой системы подготовки выпускников (бакалавр - магистр), кафедра проводит большую работу по разработке соответствующих учебных планов, рабочих программ и учебно-методических комплексов по всем двум уровням обучения: бакалавриат, магистратура. Создание филиала академии Cisco Systems с целью подготовки сертифицированных специалистов в соответствии с требованиями уровня CCNA. Организация академии Microsoft и создание международного центра сертификации VUE. Подготовка кадров высшей квалификации. Центр «Прикладной анализ данных», созданный при кафедре в 2010 г., осуществляет повышение квалификации по программам: «Компьютерная графика и веб-дизайн» (240 часов), «Сетевой специалист, сертифицированный Cisco» (72 часа), «Средства и технологии презентации в образовательном процессе» (72 часа). Переподготовка кадров. [12] В 2003 г. на кафедре была открыта подготовка по 2-годничной программе дополнительного к высшему образованию «Специалист в области компьютерной графики и веб-дизайна», а с 2011 г. также «Системный инженер (специалист по эксплуатации аппаратно-программных комплексов, персональных ЭВМ и сетей на их основе)» (срок обучения 1,5 года), «Разработчик профессионально ориентированных компьютерных технологий» (2,5 года), «Преподаватель информатики» (1,5 года). [12] Кафедрой было опубликовано 33 монографии [17] и 175 методических работ [18]. 1.3 Организация НИР на кафедре ВТНИР студентов подразделяются на: а) учебно-исследовательскую работу студентов – работу, включаемую в учебный процесс; б) собственно НИРС – работу, выполняемую во внеучебное время. Научно-исследовательская работа студентов, включаемая в учебный процесс, осуществляется кафедрой в следующих формах: а) выполнение лабораторных работ, домашних работ, курсовых и дипломных работ, содержащих элементы научных исследований; б) введение элементов научного поиска в практические и семинарские занятия; в) выполнение конкретных нетиповых заданий научно-исследовательского характера в период производственной и преддипломной практик; г) ознакомление с теоретическими основами методики, постановки, организации и выполнения научных исследований, планирования и проведения научного эксперимента и обработки полученных данных; д) участие в работе студенческих научных семинаров. Учебная научно-исследовательская работа студентов (УИРС) является одним из важнейших средств повышения качества подготовки и воспитания специалистов с высшим образованием, обладающих навыками исследования и способных творчески применять в практической деятельности. Научно-исследовательская работа студентов (НИРС), организуемая во внеучебное время, включает следующие формы: а) участие в работе студенческих научных коллективов; б) участие в работе проблемных научных групп на профилирующих (выпускающих) кафедрах; в) участие в выполнении хоздоговорной тематики кафедры. Формы и методы НИРС зависят от уровня подготовки студентов. На младших курсах преобладают такие формы НИРС как написание рефератов, выполнение расчетных работ, перевод литературы и др. На старших курсах – реальное курсовое и дипломное проектирование, постановка и модернизация лабораторных работ, участие студентов в подготовке и проведении научных экспериментов, выполнение хоздоговорных научно-исследовательских работ. [12] Первый договор на выполнение научно-исследовательской работы был заключен кафедрой с Сибирским филиалом Всесоюзного института механизации сельского хозяйства (СибВИМ). Целью работы являлась разработка электронного коррелятора, чем было положено начало научному направлению по разработке электронной аппаратуры для статистической обработки информации (научные руководители: Ю.К.Постоенко, В.В.Губарев). В 1969г. на кафедре сложилось научное направление по исследованию и построению распределенных вычислительных систем (научный руководитель - к.т.н., доцент В.И.Жиратков), а в 1974г. - направление по разработке специализированных вычислительных устройств для автоматизации научных исследований (научный руководитель - к.т.н., доцент В.И.Соболев). [12] В настоящее время научные исследования на кафедре ведутся в направлениях, указанных в таблице 1.3.1. [20] Таблица 1.3.1 Направления научных исследований
В рамках научно-исследовательской работы кафедра обеспечивает следующие направления научно-исследовательской и производственной деятельности: Исследование и разработка современных систем и средств для построения глобальных информационно-коммуникационных сетей. Теоретическое и экспериментальное исследование принципов работы и организации глобальных сетей, алгоритмов, протоколов, аппаратно-программных реализаций и систем сетевых технологий. Разработка, создание и исследование сетевого программного обеспечения и алгоритмов. Выбор и применение средств защиты информации в корпоративных информационных системах и сетях. Исследование и разработка методов и средств проектирования архитектуры аппаратно-программных сетевых комплексов и их компонентов. [12] За период с 2001 г. по 2011 г. штатными сотрудниками и совместителями было опубликовано более 760 научных работ, получено 7 патентов, 9 свидетельств о регистрации программ для ЭВМ и 1 – баз данных. Кроме того, 199 работ опубликовали аспиранты и студенты без соавторства с руководителями. [12] Ежегодно представители кафедры участвуют в организации и проведении не менее пяти различных отечественных и международных научных мероприятий в качестве председателей и/или членов оргкомитетов, руководителей секций. Все профессора кафедры ежегодно являются членами диссертационных советов в НГТУ, НГУ, СибГУТИ, других НИИ и вузов. [12] За последние 5 лет кафедра имеет более 775 научных публикаций [19]. НЕОБХОДИМО СКОРРЕКТИРОВАТЬ ЭТУ ИНФОРМАЦИЮ!!! Если будет ПОВТОР, то этот раздел не зачту! 2 ОСНОВНАЯ ЧАСТЬ. ТЕМА РЕФЕРАТА - Обзор методов распознавания языка произвольного текстаОдной из задач автоматизированной обработки текстов является распознавание языка текста [1-5]. Под текстом будем понимать связное и цельное сообщение на естественном языке, которым могут быть письмо, статья, книга и т.п. Тексты могут быть представлены в разных формах, наиболее распространённой и важной из которых в современных условиях является электронная форма представления. Это связано с тем, что хранение, обработка и передача текстов в информационно-коммуникативной среде происходит именно в такой форме, причём в различных кодировках, которые не всегда известны. Кроме того, электронные коммуникации могут происходить на различных языках, что поддерживается современным развитием средств машинного перевода сообщений. В связи с этим в целях защиты информации в телекоммуникационных сетях важно формально и оперативно распознавать язык сообщения. Кроме того, в криптоанализе распознавание языка требуется для определения типа сообщения (открытый, закрытый или иной), что обуславливает применяемые методы обработки [6,7]. Большинство существующих методов решают задачу по определению языка текста как задачу по классификации текстов на основе нейронных сетей [8,9] и наивного Байесовского классификатора [10,11]. 2.1 Определение языка с помощью наивного Байесовского классификатораВ основе НБК (Naive Bayes Classifier) лежит теорема Байеса, которая выражается формулой: 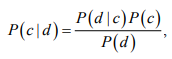 где P(c|d) — вероятность что текст d принадлежит классу c, P(d|c) — вероятность встретить текст d среди всех документов класса c; P(c) — безусловная вероятность встретить текст класса c в корпусе текстов; P(d)— безусловная вероятность текста d в корпусе текстов и 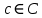 , где С – множество классов. , где С – множество классов.Для определения наиболее вероятного класса байесовский классификатор использует оценку апостериорного максимума (Maximum Aposteriori Estimation): 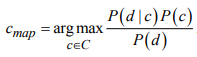 Таким образом, рассчитывается вероятность для каждого класса и выбирается класс с максимальным значением аргумента функции. Стоит отметить, что знаменатель является константой и на вычисления не влияет. Формула принимает вид: Далее делается допущение, благодаря которому алгоритм получил название «наивный»: все слова в документе считаются независимыми друг от друга, т.е. существование устойчивых выражений, идиом и контекста в расчёт не принимается. Этот подход ещё называется «мешок слов» (bag of words model). Как следствие, условная вероятность документа аппроксимируетсядо вида: Этот подход также называется униграмной языковой моделью (Unigram Language Model). Языковые модели играют очень важную роль в задачах обработки натуральных языков. После подстановки полученного выражения в формулу (1) получается: 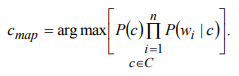 Однако при достаточно большой длине документа придётся умножать большое количество очень маленьких чисел. Для того, чтобы при этом избежать арифметического переполнения снизу, зачастую пользуются свойством логарифма произведения 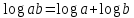 . Так как логарифм – функция монотонная, ее применение к обоим частям выражения изменит только его численное значение, но не параметры, при которых достигается максимум. При этом, логарифм от числа близкого к нулю будет числом отрицательным, но в абсолютном значении существенно большим, чем исходное число, что делает логарифмические значения вероятностей более удобными для анализа. Тогда формула приобретает вид: . Так как логарифм – функция монотонная, ее применение к обоим частям выражения изменит только его численное значение, но не параметры, при которых достигается максимум. При этом, логарифм от числа близкого к нулю будет числом отрицательным, но в абсолютном значении существенно большим, чем исходное число, что делает логарифмические значения вероятностей более удобными для анализа. Тогда формула приобретает вид: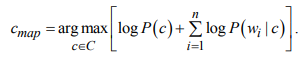 (2) (2)Основание логарифма в данном случае не имеет значения. Можно использовать как натуральный, так и любой другой логарифм. Оценка вероятностей осуществляется на обучающей выборке. Вероятность можно оценить как:  где Dc – количество документов, принадлежащих классу c, а D – общее количество документов в обучающей выборке. Оценка вероятности слова в классе может делаться несколькими путями. Здесь приведена мультиномиальная байевская модель (Multinomial Bayes Model): 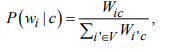 (3) (3)где Wic — количество раз, которое i-ое слово встречается в документах класса c; V — словарь корпуса документов (список всех уникальных слов). Другими словами, числитель описывает сколько раз слово встречается в документах класса (включая повторы), а знаменатель – это суммарное количество слов во всех документах этого класса. С формулой (3) есть некоторая проблема. Если нам встретится незнакомое слово, т.е. слово, отсутствующее в словаре, то P(wi|c) становится равным нулю и документ становится невозможно отнести как какому-либо классу. При этом, обучать выборку, включающую в себя все слова, не представляется возможным. Типичным решением этой проблемы является сглаживание Лапласа. Делается предположение, что каждое слово встречается на один раз больше, то есть прибавляется единицу к частоте каждого слова: 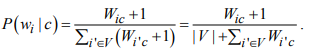 Логически, данный подход смещает оценку вероятностей в сторону менее вероятных исходов. Таким образом, слова, которые мы не видели на этапе обучения модели, получают пусть маленькую, но все же не нулевую вероятность. [10] После подстановки оценок в формулу (2), получается окончательная формулу байесовской классификации: 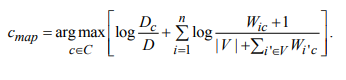 (4) (4)2.1.1 Понятие N-граммыN-грамма – это непрерывная последовательность из n элементов (звуков, слогов, слов или букв). Последовательность из двух элементов – биграмма, из трех элементов – триграмма, четыре и более элементов – N-грамма, где N заменяют на количество последовательных элементов. N-грамма как ряд слов или устойчивых словосочетаний употребляется для расчёта вероятности появления того или иного предложения, составленного из N-грамм. Большим недостатком N-грамм является то, что качественный перевод возможен только для фраз, которые целиком помещаются в N-граммную модель. Другим же недостатком в использовании N-грамм для задачи идентификации языка будет то, что не всегда тексты попадаются без грамматических ошибок. Методы, применяемые при анализе N-грамм, основаны на байесовской вероятности. N-граммы используются в следующих областях машинного анализа естественного языка: 1. Машинный перевод 2. Подсказывание следующего слова (например, в поисковой строке) 3. Распознавание текста или речи 4. Установление авторства 5. Распознавание позитивного или негативного тона отзывов 6. Определение рыночного настроения (например, для финансовых рынков) 7. Поиск и коррекция ошибок 8. Анализ и извлечение информации из неструктурированных текстов [10] 2.1.2 Оценка точности классификатора на основе наивного Байесовского классификатораТестирование программы происходило на реальной базе данных для 1000 электронных писем. Результат работы программы представлен в табл. 2.1.2.1, в которой приведены встречаемые в текстах языки и сколько раз они определялись. Как видно из табл. 1, программы показали на некоторых языках различные результаты. Это объясняется различной реализацией программного продукта, различными языковыми профилями. В ходе работы, также были замечены некоторые проблемы. Например, для некоторых мультиязычных текстов определяется только один язык. Одним из решений определения языков и переводов текста является разбиение исходного текста на логические части, что позволяет более точно определить язык и даёт возможность перевести почти весь текст, потому что такие сервисы, как translate.yandex.ru переводят только одноязычные тексты. Логическое разбиение текста подразумевает под собой разделение текста по знакам препинания, как восклицательные и вопросительные знаки, точки, двоеточия и т. д. Данный метод прост и существенно увеличивает объём переводимого текста, но 100% перевода не даёт, потому что текст не всегда пишется с соблюдением всех грамматических норм. [10] Таблица 2.1.2.1 Результаты работы программ идентификации языков
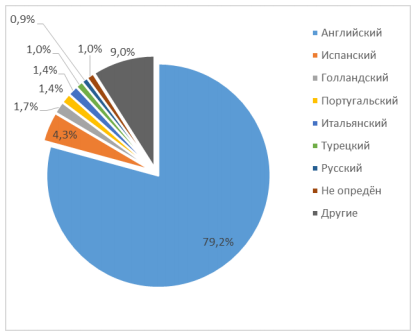 Рис. 2.1.2.1 Диаграмма, иллюстрирующая работу программы, использующей Language Detection для Java 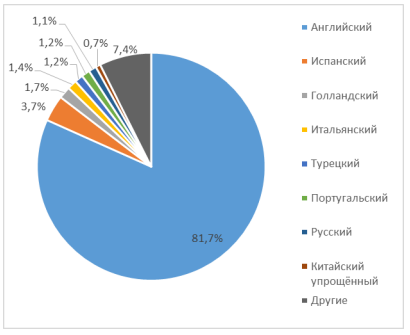 Рис. 2.1.2.2 Диаграмма, иллюстрирующая работу программы, использующей Langdetect для Python 2.1.3 Выводы по использованию наивного Байесовского классификатора в задаче по распознаванию языка текстаВ исследовании использовались готовые библиотеки для языков. Подготовленные выборки содержали недостаточное количество текстов языков, отличных от английского, что не даёт возможности судить о правильности распознавания языка, отличного от английского. Кроме того, не приведены данные по точности распознавания языка: не описаны ошибки первого и второго рода при идентификации языка. 2.2 Определение языка с помощью нейронных сетейНиже представлена система определения языка, основанная на хорошо известном алгоритме, измеряющем сходство в соответствии с предикацией коротких буквенных последовательностей (n-грамм). [9] 2.2.1 Эвристика в категоризации веб-документовНесмотря на то, что подход на основе n-граммах довольно прост и очень хорошо работает даже на небольшом текстах, некоторые вопросы всё же необходимо решить при применении этого подхода к веб-документам: 1. Извлечь текст, информацию о метках и метаданных. 2. Применить информацию о метаданных, если она доступна и действительна. 3. Фильтровать общие или «автоматически сгенерированные» строки. 4. Оценить n-граммов в соответствии с разметкой HTML. 5. Разрешить ситуации, где имеются недостаточные данные. 6. Обработать многоязычные и трудные вопросы. Необходимость удаления тегов и комментариев из документов HTML перед выполнением категоризации, а обработка вопросов, связанных с HTMLcharacter, очевидна. Тем не менее, работа с большим разнообразием и источников информации через Интернет добавляет новые проблемы. Наличие мощного парсера, способного переносить распространенные ошибки, связанные с искаженными документов HTML, является очень важным аспектом работы с веб-данными. Некоторые HTML-страницы включают метатег языка, определяющий его язык. Однако многие инструменты редактирования HTML автоматически устанавливают значение английского языка по умолчанию. В результате информация метатега не всегда надежнп. Также нет единого способа задания языка метатега (например, португальский язык может быть определен как pt, pt-pt, por, portugues, pt-portuguese и т. д.), поэтому инструментальные средства не всегда могут обрабатываться эти данные. Если удастся сопоставить информацию о метатеге языка с именами набора известных языков, и предоставленное значение соответствует языку, отличному от английского, мы возвращаем систему классификации на основе n-грамм вместо языка. Другая проблема связана с тем, что строки, такие как «This page uses frames» или «Made for Internet Explorer», встречаются очень часто и не обязательно означают, что данный веб-ресурс содержит контент на английском языке. Например, при большом сканировании Portuguese Web (около 3,5 миллионов документов) было обнаружено, что вышеописанные строки встречаются примерно 35 000 раз. Мы сохраняем небольшого словарик таких предложений, которые заполняются на этапе предварительной обработки. Комбинированные слова в Интернете, такие как «applet» или «java», также распознаются в этом процессе, поскольку они попадаются по всему Интернету, независимо от языка. Страницы, содержащие таблицы с числовыми данными, также очень удобны. Чтобы лучше справляться с этими случаями, предлагается игнорировать все n-граммы, состоящие только из числовых и / или пробельных символов. N-граммы также находятся в соответствии с информацией о разметке. HTML определяет набор полей, которым может быть назначен текст в документе. Термины, появляющиеся в разных полях, интуитивно различаются по значимости (т. е. текст из названия страницы в принципе должен быть более значительным). В системе эти поля служат мультипликативными факторами для подсчёта частоты n-грамм в пределах их объема, т.е.: n-граммы в названии подсчитываются три раза n-граммы в описательных метатегах подсчитываются дважды. Иная эвристика относится к страницам с очень маленьким текстом. Когда текст, извлеченный из веб-страницы, имеет объём менее 40 символов, документу присваивается ярлык «неизвестный язык». Некоторые документы не будут классифицированы вообще, но шанс присвоить правильную метку увеличивается. Наконец, многоязычные документы также очень распространены в Интернете. Это представляет собой проблему, если мы хотим присвоить полный контекст данного документа одному языку. Например, домашние страницы для людей с иностранными именами очень распространены в португальском сети, по крайней мере, внутри крупных институциональных сайтов. Для этого используется простая эвристика: когда документ не классифицируется как португальский или английский (два самых современных языка в нашей коллекции документов), алгоритм вряд ли допустит ошибку. В этих случаях мы пытаемся повторно применить алгоритм n-грамм, взвешивая самый большой непрерывный текстовый блок в документе (блоки идентифицируются на этапе синтаксического анализа HTML, принимая информацию о разметке), в три раза более важный, чем обычный текст. Обоснованием для этого является то, что самый длинный блок с очень большой вероятностью соответствует описанию страницы на её основном языке. 2.2.2 Описание эксперимента по определению языка нейронными сетямиДля эксперимента были использована языковые профили для разных языков, построенные из текстовой информации, извлеченной из новостей и Интернета. Поскольку мы не смогли найти подходящую коллекцию веб-страниц для использования в качестве «золотого стандарта», мы также организовали тестовую коллекцию, вручную присваивая HTML-документам один из двенадцати разных языков (датский, голландский, английский, финский, французский, немецкий, итальянский, японский, португальский, русский, испанский и шведский). Общее количество документов в коллекции составляет 6000, по 500 документов для каждого языка. Страницы в коллекции были сканированы с таких сайтов, как онлайн газеты или веб-порталы. Как правило, они содержат большое количество страниц на одном языке, поэтому сбор тестовой коллекции упрощается и проверяется на наличие ошибок в процессе выделения языка. С помощью этой коллекции документов мы протестировали систему идентификации языка с разными настройками, используя три различных меры сходства и эвристику, описанную выше. Результаты представлены на рисунке 2.2.2.1. Мера Лин дала наиболее точный результат. По прошествии времени она превзошла первоначальную меру «ранга», предложенную Кавнаром и Трекле, на 32%. Результаты также подтверждают, что предлагаемые эвристики улучшают точность системы. Использование меры сходства Лин без эвристики приводит к уменьшению производительности на 2,8%. В будущем планируется провести статистические тесты для оценки достоверности прогнозируемых улучшений. Это особенно важно для оценки выгоды, введенной нашей эвристикой, поскольку улучшение намного меньше, чем в случае аналогичных мер. 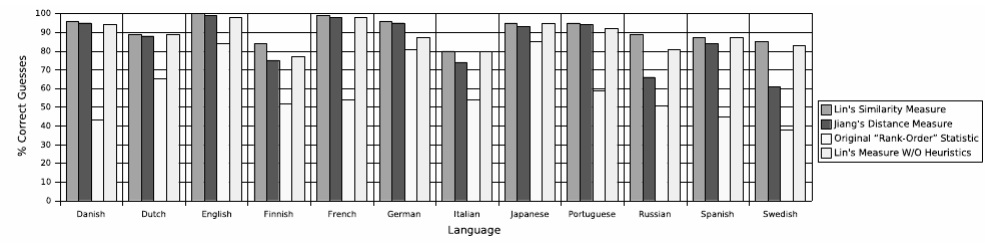 Рис. 2.2.2.1. Результаты применения алгоритма по идентификации языка с различными настройками. Таблица 2.2.2.2 детализирует результаты, полученные в наилучшей настройке для системы (мера Лин с эвристикой). Хотя приведенные значения достаточно хороши для эффективного использования системы, они ниже, чем в других исследованиях с аналогичными системами. Мы полагаем, что это связано в основном с гораздо более шумным характером обрабатываемых текстов. Общепринятое поведение классифицировалось также достаточно плохо. Например, похожие европейские северные языки постоянно путались. При обнаружении только португальских документов система достигает точности в 99% (см. Таблицу 2.2.2.1). Таблица 2.2.2.1. Результаты идентификации португальских документов.  Таблица 2.2.2.2. Результаты для алгоритма идентификации языка с использованием меры сходства Лин. 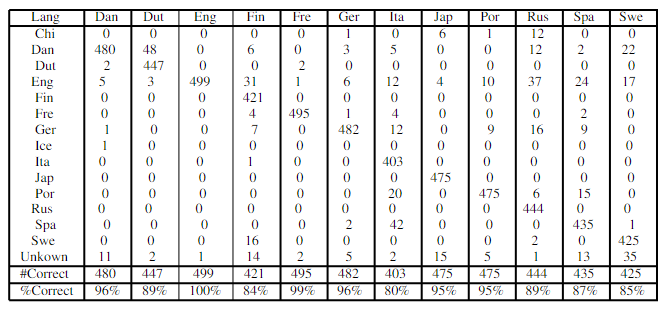 Во время работы использован сервер Pentium IV 2.66 ГГц с основной памятью 896 МБ, ОС – RedHat Linux 9.0 с установленной версией Java Development Kit 1.4.2 (программное обеспечение для категорирования n-грамм было реализовано на Java). Для 6000 документов в нашей тестовой коллекции и для каждого параметра системы языкового обучения общее время загрузки языковых профилей из диска, загрузки и разбора HTML, извлечения текста и классификации его в соответствии с языком было меньше, чем двадцать минут, что соответствует примерно пяти документам в секунду. Также интересны результаты выполнения этого алгоритма на сборке около 3,5 миллионов страниц из португальского Интернета, индексированных нашей поисковой системой - см. рисунок 2.2.2.2. Учитывая высокую точность нашей системы распознавания языка, мы можем констатировать, что значительная часть страниц, размещенных в домене «.PT», часто написана на иностранных языках, особенно на английском языке.  Рисунок 2.2.2.2. Распределение языков в португальском сегменте сети Интернет. 2.2.3 Выводы по использованию нейронных сетей в задаче по распознаванию языка текстаПоскольку веб-документы имеют особые характеристики, этот метод был дополнен набором эвристик, чтобы лучше справляться с этой информацией. Несмотря на то, что система уже продемонстрировала хорошую производительность на реалистичной установке, есть еще возможности для дальнейших улучшений. Например, лучшая настройка профилей, используемых для классификации новых документов, может повысить производительность до значений, близких к тем, которые были перенесены в другие эксперименты с использованием классифицированных на основе n-грамм систем. Использование ссылочной информации и текстов из гипертекстового тега также могло бы улучшить общие результаты. ЗаключениеВ ходе учебной практики, проводимой на кафедре вычислительной техники, было составление описание кафедры, включая современное состояние её материально-технической базы и организацию учебного процесса и НИР на кафедре. В рамках второй части задания были изучены существующие методы определения языка текста: произведён поиск, детальный анализ и структурирование информации о существующих методах. Во время работы был составлен библиографический список, заполнен дневник практики. Поиск методов осуществлён в научных публикациях различных авторов, в том числе на иностранных языках. Составленный отчёт по учебной практике содержит 27 стр., включая титульный лист. Было проанализировано 11 источников по теме «Определение языка произвольного текста» и 9 источников для сбора информации о кафедре вычислительной техники. Работа содержит 20 источников, 4 рисунка, 5 таблиц, 10 формул, 31 ссылку. В рамках работы было выяснено, что большинство существующих методов решают задачу по определению языка текста как задачу по классификации текстов на основе нейронных сетей и наивного Байесовского классификатора. Данные методы достаточно вычислительно затратны, требуют наличия обучающей выборки и недостаточно используют существующие закономерности языка. Полученные сведения и библиографический список могут быть использованы в дальнейшем в учебном процессе. Список источников1. И.А. Шалимов, М.А. Бессонов. Анализ состояния и перспектив развития технологий определения языка аудиосообщения // «Труды НИИР», 2013, №3. 2. H. Li, B. Ma and K. A. Lee. Spoken Language Recognition: From Fundamentals to Practice // Proceedings of the IEEE, 2013. V. 101. No. 5. pp. 1136-1159. 3. Q. Ye and D. Doermann. Text Detection and Recognition in Imagery: A Survey // IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015. V. 37. No. 7. pp. 1480-1500. 4. Daniel Lopresti. Optical character recognition errors and their effects on natural language processing // International Journal on Document Analysis and Recognition (IJDAR), 2009, V. 12, Issue 3, pp. 141–151. 5. M. T. Chowdhury, M. S. Islam, B. H. Bipul and M. K. Rhaman. Implementation of an Optical Character Reader (OCR) for Bengali language. // Proceedings of 2015 International Conference on Data and Software Engineering, ICODSE 2015, 2015. pp. 126-131. 6. Ю. А. Котов. Детерминированная идентификация буквенных биграмм в русскоязычных текстах // Труды СПИИРАН, 2016, № 1, С. 181-197. 7. Ю. А. Котов. Аппроксимация распределений частот буквенных биграмм текста для идентификации букв // Труды СПИИРАН, 2017, № 1 (50), С. 190-208. 8. Zazo R, Lozano-Diez A, Gonzalez-Dominguez J, T. Toledano D, Gonzalez-Rodriguez J. Language Identification in Short Utterances Using Long Short-Term Memory (LSTM) Recurrent Neural Networks // PLOS ONE, 2016. No. 11(1). 9. Bruno Martins, Mário J. Silva. Language identification in web pages // Proceedings of the 2005 ACM symposium on Applied computing, March 13-17, 2005, Santa Fe, New Mexico, 2005. pp. 764-768. 10. Т.А. Гультяева, Ю. Р. Савицкий, Н. Л. Эльвейн. Автоматическое определение языка электронных писем // Обработка информации и математическое моделирование : материалы Рос. науч.-техн. конф., 2017, Новосибирск : СибГУТИ, С. 19-25. 11. Marco Lui , Jey Han Lau , Timothy Baldwin. Automatic detection and language identification of multilingual documents // Transactions of the Association for Computational Linguistics, 2014. Vol. 2. pp. 27-40. 12. Учебная практика — Теоретические материалы — DiSpace. URL: https://dispace.edu.nstu.ru/didesk/course/show/4498/0 (дата обращения: 25.11.2018). 13. НГТУ. Научные школы. URL: https://www.nstu.ru/science/schools (дата обращения: 25.11.2018). 14. НГТУ. Направления, специальности, экзамены 2019. URL: https://www.nstu.ru/enrollee/exams (дата обращения: 25.11.2018). 15. НГТУ. Направления подготовки, вступительные испытания 2019. URL: https://www.nstu.ru/magistracy/master_exams (дата обращения: 25.11.2018). 16. НГТУ. Научные направления, специальности, руководители. URL: https://www.nstu.ru/post_grad/asp_supervisor (дата обращения: 25.11.2018). 17. НГТУ - ВТ - Список монографий. URL: https://ciu.nstu.ru/kaf/vt/nauchnaya_deyatelnost/monograflist_new (дата обращения: 25.11.2018). 18. НГТУ - ВТ - Список учебно-методических работ. URL: https://ciu.nstu.ru/kaf/vt/study_activity/stmateriallist_new (дата обращения: 25.11.2018). 19. НГТУ - ВТ - Список научных публикаций. URL: https://ciu.nstu.ru/kaf/vt/nauchnaya_deyatelnost/publicationlist_new (дата обращения: 25.11.2018). 20. НГТУ - ВТ - Направления научных исследований. URL: https://ciu.nstu.ru/kaf/vt/nauchnaya_deyatelnost/issled (дата обращения: 25.11.2018). | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||