ИПЗ информатика 3 вариант. ИПЗ_ПЕД-Б-0-З-2021-2_ДИСТАНТ _3_Крепина И.С.. Представление и обработка информации из Интернета
 Скачать 231.21 Kb. Скачать 231.21 Kb.
|

ИТОГОВОЕ ПРАКТИЧЕСКОЕ ЗАДАНИЕ по дисциплине «Информатика и основы информационно-коммуникационных технологий» Представление и обработка информации из Интернета
Москва Вариант № 3. Задания. Реализуйте проект по информатике "Представление и обработка информации из Интернета". 1. Скачайте по ссылке https://www.kaggle.com/zynicide/wine-reviews датасет с названием Wine Reviews. 2. Очистите данные 3. Рассчитайте основные описательные статистики 4. Проведите визуальный анализ, построив несколько графиков и диаграмм (2-5) 5. (в данный курс проверка гипотез не входит, но на практике обязательна) Сформулируйте несколько гипотез (3-6) относительно как количественных, так и качественных признаков и проверьте их. 6. Сделайте презентацию и кратко опишите в ней, что интересного Вы увидели из графиков (гипотезы). Введение. Анализ проводился над датасетом, в котором описывались различные сорта вин из разных стран, цен и категорий. Файл был скачан из источника: https://www.kaggle.com/zynicide/wine-reviews. Так же в источнике была информация о наборе данных (Рис.1) 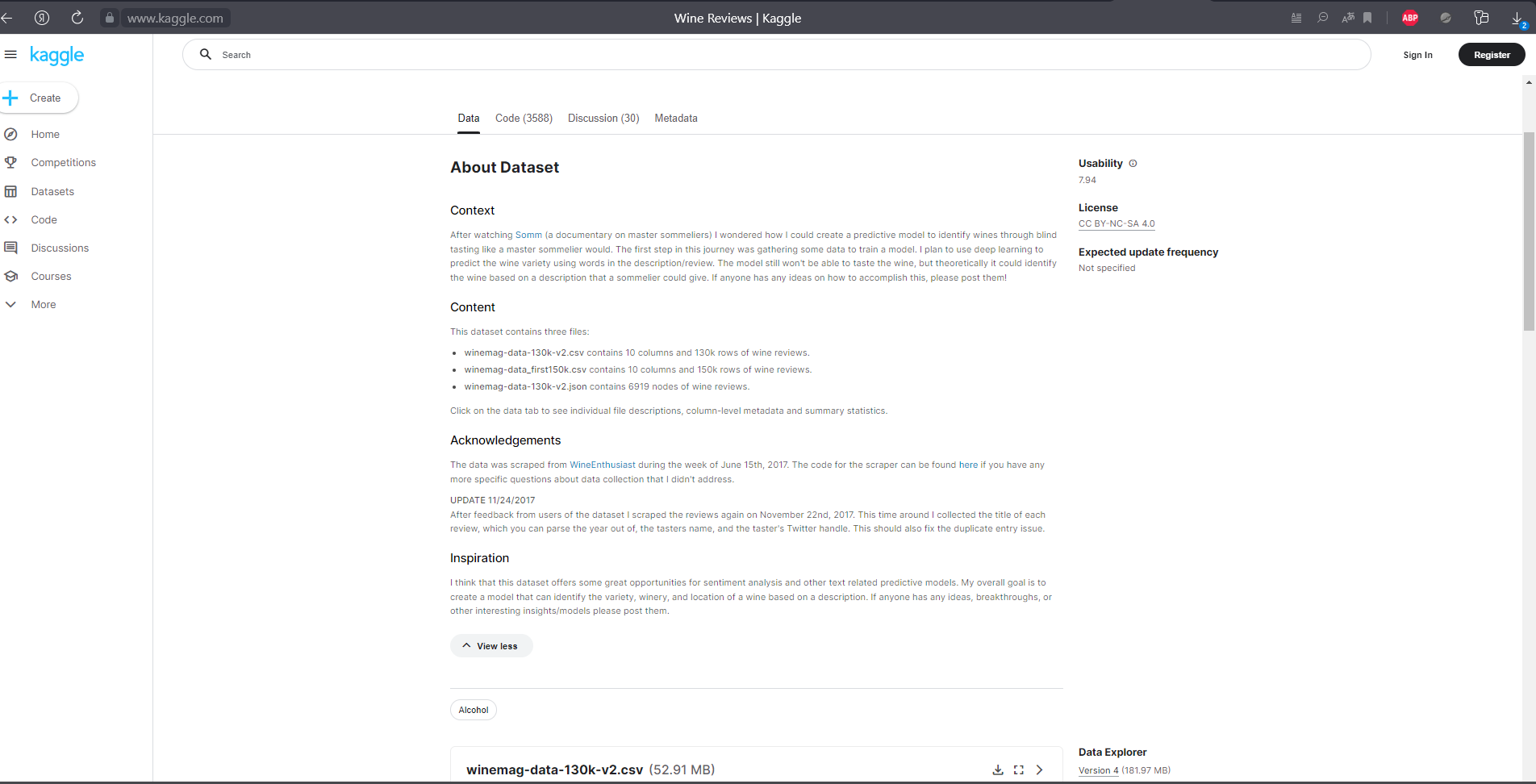 Рис.1 Переводим данные. Context После просмотра Somm (документальный фильм о мастерах сомелье) Я задавался вопросом, как я мог бы создать прогностическую модель для идентификации вин через слепую дегустацию, как мастер-сомелье. Первым шагом в этом путешествии был сбор некоторых данных для обучения модели. Я планирую использовать глубокое обучение для прогнозирования сорта вина, используя слова в описании / обзоре. Модель по-прежнему не сможет попробовать вино, но теоретически она может идентифицировать вино на основе описания, которое может дать сомелье. Если у кого-то есть идеи о том, как это сделать, пожалуйста, опубликуйте их! Content Этот набор данных содержит три файла: winemag-data-130k-v2.csv содержит 10 столбцов и 130k строк винных обзоров. winemag-data_first150k.csv содержит 10 столбцов и 150 строк отзывов о вине. winemag-data-130k-v2.json содержит 6919 узлов винных обзоров. Перейдите на вкладку данные, чтобы просмотреть описания отдельных файлов, метаданные на уровне столбцов и сводную статистику. Acknowledgements Данные были получены из WineEnthusiast в течение недели 15 июня 2017 года. Код для скребка можно найти здесь, если у вас есть более конкретные вопросы о сборе данных, которые я не рассматривал. ОБНОВЛЕНИЕ 24.11.2017 После отзывов пользователей набора данных я снова очистил обзоры 22 ноября 2017 года. На этот раз я собрал название каждого обзора, из которого вы можете разобрать год, имя дегустатора и ручку Twitter дегустатора. Это также должно исправить проблему с дублированием записи. Inspiration Я думаю, что этот набор данных предлагает отличные возможности для анализа настроений и других прогностических моделей, связанных с текстом. Моя общая цель - создать модель, которая может идентифицировать сорт, винодельню и местоположение вина на основе описания. Если у кого-то есть какие-либо идеи, прорывы или другие интересные идеи / модели, пожалуйста, опубликуйте их. В скачанном файле содержится 813 145 строк и 13 столбцов. Для удобства расчетов сокращаем информацию. Столбцов оставляем 4 шт с наименованиями (Рис. 2): Country – Страна; Points – Баллы; Price – Цена; Тaster_name – Имя сомелье.  Рис.2 Для удобства дальнейшей сортировки в столбце Price при помощи функции «Найти и заменить», меняем точку на запятую. Строки сортируем «Настраиваемой сортировкой». (Рис.3) 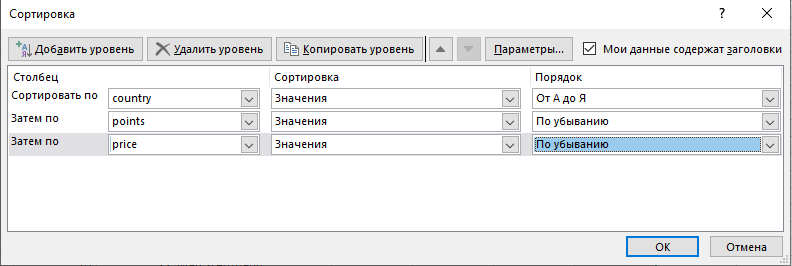 Рис.3 Числовым фильтром в столбце Pointsотбираем данные, которые менее 97. Их удаляем, очищаем фильтр. При помощи функции «Найти и выделить» в столбце Price удаляем строки в которых нет информации. Оставляем по одной стране с самым дорогим вином и самым высоким баллом. (Рис. 4)  Рис.4 При помощи анализа данных создаем описательную статистику по полю Price(Рис 5).  Рис. 5 Ставим вопросы к датасету и находим ответы при помощи диаграмм и гистограмм. В какой стране низкий балл, но дороге вино?  В какой стране самое дорогое вино? 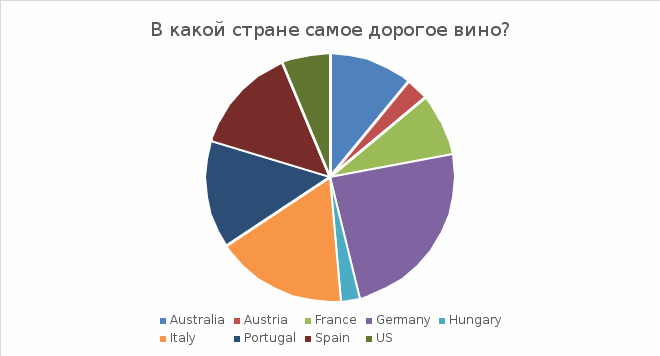 Кто из сомелье пил самое дорогое вино?  Выводы: В какой стране низкий балл, но дороге вино? – Германия В какой стране самое дорогое вино? - Германия Кто из сомелье пил самое дорогое вино? - Anna Lee C. Iijima |
