Распределённые вычисления. Распределённые вычисления
 Скачать 3.38 Mb. Скачать 3.38 Mb.
|

|
Распределённые вычисления — способ решения трудоёмких вычислительных задач с использованием нескольких компьютеров, чаще всего объединённых в параллельную вычислительную систему.[1] Распределённые вычисления применимы также в распределённых системах управления.[2] Последовательные вычисления в распределённых системах выполняются с учётом одновременного решения многих задач. Особенностью распределённых многопроцессорных вычислительных систем, в отличие от локальных суперкомпьютеров, является возможность неограниченного наращивания производительности за счёт масштабирования.[2]:550 Слабосвязанные, гетерогенные вычислительные системы с высокой степенью распределения выделяют в отдельный класс распределённых систем — грид. Работы по распределённым вычислениям с весьма прикладной целью — для военных нужд, а именно автоматизации процессов секретной связи и обработки разведывательной информации, велись интенсивно в США с 1960-х гг. Разработкой технологий распределённых вычислений и созданием распределённых информационных систем в Соединённых Штатах по заказу Агентства по перспективным оборонным научно-исследовательским разработкам США, видов вооружённых сил и служб (агентств) в структуре Министерства обороны США занимались исследовательские подразделения компаний и университетов:[3] Bolt, Beranek and Newman, Кембридж, Массачусетс; Computer Corporation of America, Кембридж, Массачусетс; Network Analysis Corporation, Глен-Коув, Лонг-Айленд; System Development Corporation, Санта-Моника, Калифорния; Стэнфордский исследовательский институт, Менло-Парк, Калифорния; Национальный институт стандартов и технологий, Вашингтон, округ Колумбия; Калифорнийский университет в Лос-Анджелесе, Калифорния; Агентство военной связи, Скотт, Иллинойс. В рамках проводившихся фундаментальных исследований, НИР и ОКР, разрабатывались соответствующие программно-аппаратные комплексы под уже существующие низкоуровневые (машинно-ориентированные) языки программирования, специальное программное обеспечение с криптографической защитой и т. д.[3] В 1973 году Джон Шох и Джон Хапп из калифорнийского научно-исследовательского центра Xerox PARC написали программу, которая по ночам запускалась в локальную сеть PARC и заставляла работающие компьютеры выполнять вычисления[4]. В 1977 году в НЭТИ (НГТУ, Новосибирск) на кафедре вычислительной техники под руководством В. И. Жираткова была разработана распределённая вычислительная система из трёх ЭВМ «Минск-32» с оригинальным аппаратным и программным обеспечением, поддерживающим протоколы физического, канального и сетевого уровней, и обеспечивающим выполнение параллельных задач. Одна машина находилась на ВЦ НГТУ, а две другие — на ВЦ Института Математики СО РАН. Связь между НГТУ и ИМ СО РАН обеспечивалась по радиоканалу с использованием направленных антенн. Система тестировалась при решении оптимизационных задач в области экономики с использованием крупноблочного распараллеливания.[источник не указан 810 дней] В 1978 году советский математик Виктор Глушков работал над проблемой макроконвейерных распределённых вычислений. Он предложил ряд принципов распределения работы между процессорами.[2]:320 На базе этих принципов им была разработана ЭВМ ЕС-2701. В 1988 году Арьен Ленстра и Марк Менес написали программу для факторизации длинных чисел. Для ускорения процесса программа могла запускаться на нескольких машинах, каждая из которых обрабатывала свой небольшой фрагмент.[4]. В 1994 году Дэвидом Джиди была предложена идея по организации массового проекта распределённых вычислений, который использует компьютеры добровольцев (т. н. добровольные вычисления) — SETI@Home[5]. Научный план проекта, который разработали Дэвид Джиди и Крейг Каснофф из Сиэтла был представлен на пятой международной конференции по биоастрономии в июле 1996 года[6]. В январе 1996 года стартовал проект GIMPS по поиску простых чисел Мерсенна, также используя компьютеры простых пользователей как добровольную вычислительную сеть. 28 января 1997 года стартовал конкурс RSA Data Security на решение задачи взлома методом простого перебора 56-битного ключа шифрования информации RC5. Благодаря хорошей технической и организационной подготовке проект, организованный некоммерческим сообществом distributed.net, быстро получил широкую известность[4]. 17 мая 1999 года стартовал SETI@home на базе Grid, а в начале 2002 года завершилась разработка Калифорнийского Университета в Беркли открытой платформы BOINC (Berkeley Open Infrastructure for Network Computing), разрабатываемой с апреля 2000 года первоначально для SETI@Home, но первым на платформе BOINC стал проект Predictor@home запущенный 9 июня 2004 года. Управление вычислительными заданиями[править | править код] Проблема распределения различных вычислительных задач в рамках распределённой системы относится к проблеме принятия решений в условиях неопределённости. Данная проблема рассматривается в теории принятия решений и в теории неопределённости. Распределённые операционные системы[править | править код] Распределённая ОС, динамически и автоматически распределяя работы по различным машинам системы для обработки, заставляет набор сетевых машин обрабатывать информацию параллельно. Пользователь распределённой ОС, вообще говоря, не имеет сведений о том, на какой машине выполняется его работа.[1] Распределённая ОС существует как единая операционная система в масштабах вычислительной системы. Каждый компьютер сети, работающей под управлением распределённой ОС, выполняет часть функций этой глобальной ОС. Распределённая ОС объединяет все компьютеры сети в том смысле, что они работают в тесной кооперации друг с другом для эффективного использования всех ресурсов компьютерной сети. В результате сетевая ОС может рассматриваться как набор операционных систем отдельных компьютеров, составляющих сеть. На разных компьютерах сети могут выполняться одинаковые или разные ОС. Например, на всех компьютерах сети может работать одна и та же ОС UNIX. Более реалистичным вариантом является сеть, в которой работают разные ОС, например, часть компьютеров работает под управлением UNIX, часть — под управлением NetWare, а остальные — под управлением Windows NT и Windows 98. Все эти операционные системы функционируют независимо друг от друга в том смысле, что каждая из них принимает независимые решения о создании и завершении своих собственных процессов и управлении локальными ресурсами. Но в любом случае операционные системы компьютеров, работающих в сети, должны включать взаимно согласованный набор коммуникационных протоколов для организации взаимодействия процессов, выполняющихся на разных компьютерах сети, и разделения ресурсов этих компьютеров между пользователями сети. Если операционная система отдельного компьютера позволяет ему работать в сети, и может предоставлять свои ресурсы в общее пользование и/или использовать ресурсы других компьютеров сети, то такая операционная система отдельного компьютера также называется сетевой ОС. Таким образом, термин «сетевая операционная система» используется в двух значениях: как совокупность ОС всех компьютеров сети и как операционная система отдельного компьютера, способного работать в сети. Из этого определения следует, что такие операционные системы, как, например, Windows NT, NetWare, Solaris, HP-UX, являются сетевыми, поскольку все они обладают средствами, которые позволяют их пользователям работать в сети. 1. Отложенное (Lazy) вычисление значений Отложенное вычисление значения (lazy evaluation) – это стратегия программирования, откладывающая вычисление значения выражения или переменной до тех пор, пока это значение не понадобится. Это антипод прямого, или немедленного вычисления, при котором значения вычисляются сразу, когда вызывается расчет. Отложенные вычисления позволяют повысить уровень оптимизации вычислений и сократить нагрузку на память, избегая ненужных повторений расчетов. Давайте продемонстрируем это с помощью мысленного эксперимента. Познакомьтесь с Меркуцио, нашим Мышкетером Распределенных Вычислений: Изображение из twemoji (лицензия CC-BY 4.0) Меркуцио примет участие в эксперименте. По условиям эксперимента, Меркуцио должен найти кратчайший путь в лабиринте к конечной цели: вкусному кусочку сыра Чеддер. Путь в лабиринте будет отмечаться хлебными крошками, чтобы Меркуцио знал, куда идти. Цель эксперимента – добраться до сыра как можно быстрее, поэтому Меркуцио будет терять по 1 очку за каждую съеденную крошку. В сценарии 1 Меркуцио начинает идти (в компьютерных терминах – «вычислять») сразу же, когда вы положите первую крошку, и последует за вами от одной крошки до другой. При этом он, конечно, в конце концов доберется до своего Сыра Назначения. Но при этом он получит 5 отрицательных очков, по одной за каждую крошку, которую он прошел (и съел). Это верное решение задачи, но не оптимальное. 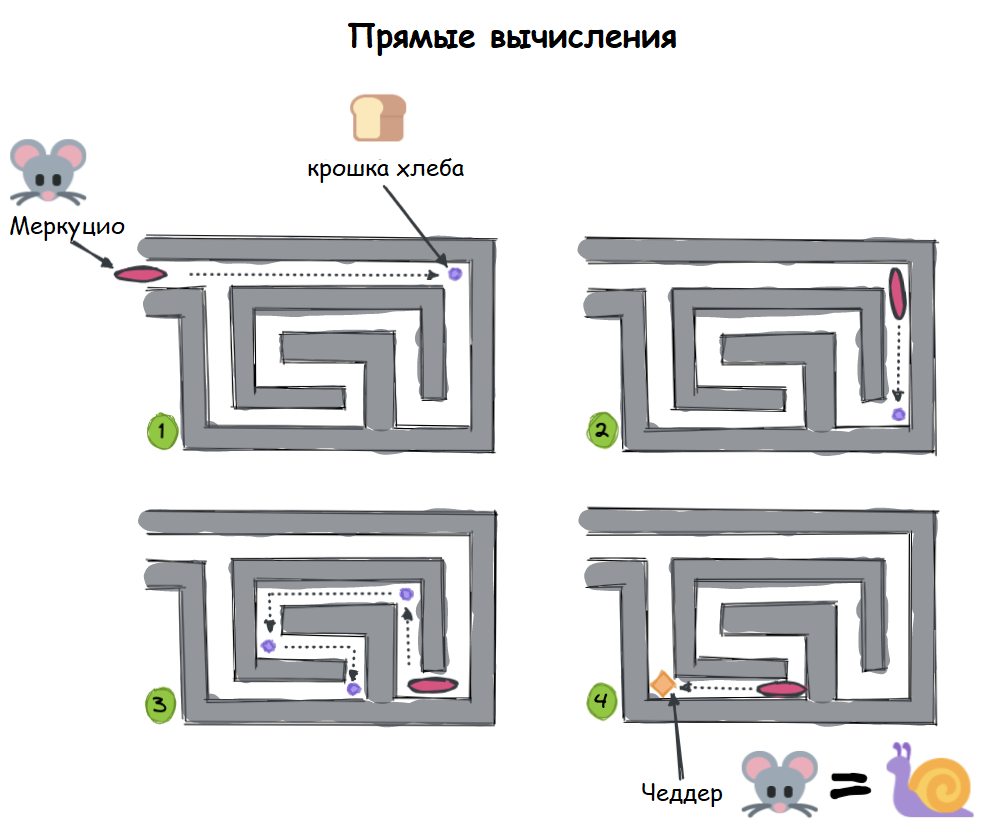 Изображение автора, эмоджи от twemoji А вот если бы Меркуцио задержал свой бег, пока вы не положите сыр, а потом оценил ситуацию, он сумел бы увидеть всю задачу целиком и нашел бы самый быстрый способ решить ее.  Изображение автора, эмоджи от twemoji Изображение автора, эмоджи от twemojiПример кода Давайте продемонстрируем это с помощью кода, использующего Pandas (прямые вычисления) и Dask (отложенные вычисления). В этом коде мы создадим DataFrame, вызовем его и зададим вычисление по группировке (groupby) по заданному столбцу. Заметьте, что Pandas возвращает результат немедленно, тогда как Dask делает это лишь тогда, когда вы явно скомандуете ему начать вычисления. import pandas as pd # Создаем dataframe df = pd.DataFrame({ "Name": ["Mercutio", "Tybalt", "Lady Montague"], "Age": [3, 2, 4], "Fur": ["Grey", "Grey", "White"]} ) # вызовем наш DataFrame df 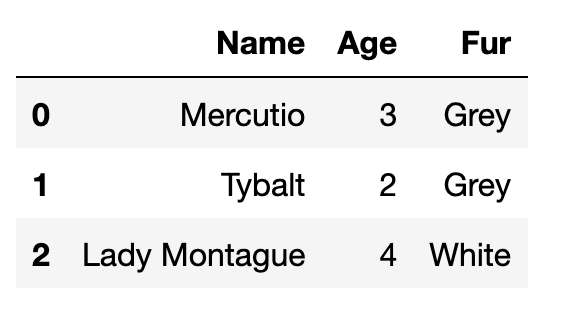 Pandas немедленно возвращает содержимое Dataframe (изображение автора) # Зададим вычисление по groupby df.groupby('Fur').Age.mean()  Pandas немедленно возвращает результат группировки (изображение автора) Pandas немедленно возвращает результат группировки (изображение автора)Мы видим, что Pandas немедленно выполняет каждую инструкцию, которую мы определяем. Как результат определения DataFrame, так и результат операции над groupby возвращаются немедленно. Именно такое поведение ожидается от Pandas, и оно вас устраивает, пока вы работаете над сравнительно небольшими наборами данных, полностью помещающимися в оперативную память вашего компьютера. Проблема возникает в том случае, если ваш DataFrame содержит больше данных, чем может поместиться в память вашего компьютера. У Pandas нет другого выбора, кроме как попытаться загрузить эти данные в память… и потерпеть неудачу. Вот почему библиотеки распределенных вычислений, вроде Dask, используют отложенное вычисление: import dask.dataframe as dd # Превращаем df в dataframe Dask dask_df = dd.from_pandas(df, npartitions=1) # Вызываем этот dataframe (содержимое не возвращается) dask_df  Dask «отложенно» возвращает только схему dataframe, но не его содержимое (изображение автора) Dask «отложенно» возвращает только схему dataframe, но не его содержимое (изображение автора)# Задаем тот же расчет на основе groupby, что и прежде (не возвращает результатов) dask_df.groupby('Fur').Age.mean()  Dask отложенно возвращает лишь схему groupby, но не его результаты (изображение автора) Dask отложенно возвращает лишь схему groupby, но не его результаты (изображение автора)Dask не возвращает результатов ни при вызове DataFrame, ни при определении вычисления groupby. Он возвращает только схему, или описание результата. Лишь тогда, когда мы явно вызываем compute(), Dask фактически производит вычисления и возвращает результаты. Таким образом, он может подождать, чтобы рассчитать оптимальный путь к результату, как это делал Меркуцио в нашем втором сценарии. # запустить вычисления dask_df.groupby('Fur').Age.mean().compute() Изображение автораОтложенные вычисления – это именно то, что позволяет библиотекам вроде Dask оптимизировать крупномасштабные вычисления, определяя «очевидно параллельные» (embarrassingly parallel) части расчета. Больше полезных материалов вы найдете на нашем телеграм-канале «Библиотека программиста» Интересно, перейти к каналу 2. Очевидная параллельность Термин «очевидно параллельные» (embarassingly parallel) применяется к расчетам или задачам, которые легко разбиваются на более мелкие задачи, каждую из которых можно рассчитывать независимо от других. Это означает, что между такими задачами нет зависимостей, и их можно рассчитывать параллельно или в любом порядке. Иногда такие задачи также называются «идеально параллельными» или «отлично параллелизуемыми».  Изображение взято с freesvg.org, находится в публичном доступе Изображение взято с freesvg.org, находится в публичном доступеДавайте вернемся к нашему мысленному эксперименту. К нашему старому другу Меркуцио присоединились еще два товарища, которые также примут участие в миссии поиска сыра с отложенными вычислениями. Мы проведем два разных эксперимента с нашими Тремя Мышкетерами. Теперь у нас не один лабиринт, а целых три. В Эксперименте 1 кусок сыра чеддер разделен на равные части, и каждая часть положена в собственный лабиринт. В Эксперименте 2 весь кусок кладется в конце Лабиринта 3, а в Лабиринтах 1 и 2 лежат закрытые ящики, в которых лежат ключи к ящикам из следующих лабиринтов. Это значит, что Мышь 1 должна будет достать ключ в Лабиринте 1, передать его Мыши 2, которая передаст уже второй ключ Мыши 3. Цель обоих Экспериментов – съесть весь сыр целиком. 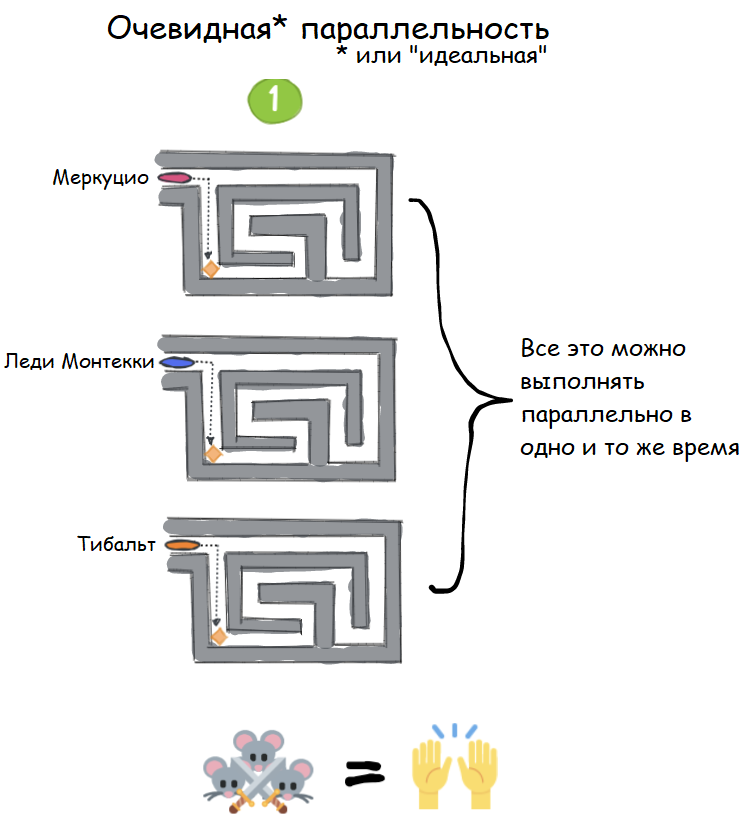 Рисунок автора, эмоджи взяты из twemoji Рисунок автора, эмоджи взяты из twemojiЭксперимент 1 (выше) – пример очевидно параллельной задачи: каждый Мышкетер может разбираться со своим лабиринтом независимо от других, так что их общая задача (съесть весь сыр) будет выполнена параллельно. Эксперимент 2 (ниже) – пример задачи, которую нельзя параллелизовать: решение каждой задачи зависит от решения предыдущей. Пример кода Широко встречающийся пример очевидно параллельной задачи – это цикл for: каждую итерацию цикла можно выполнять независимо от других. Более сложный пример – метод Монте-Карло: это моделирование, использующее повторение выборок случайной величины для оценки ее распределения. Каждая выборка генерируется независимо от других, и никак на них не влияет. # Простой цикл for - это очевидно параллельная задача for i in range(0,5): x = i + 5 print(x) Еще один пример очевидно параллельной задачи – чтение разделенного Parquet-файла в DataFrame Dask: df = dd.read_parquet("test.parquet") df.visualize() 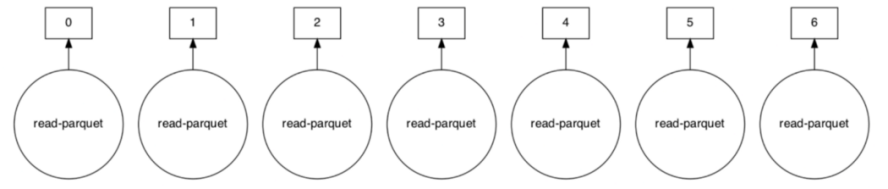 Изображение автора Изображение автораДля сравнения, вот вычислительный граф при расчете groupby на том же DataFrame df: 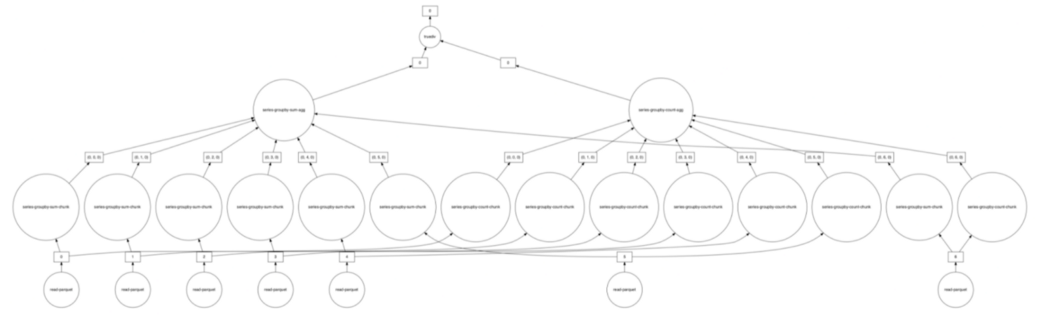 Изображение автора Изображение автораЯсно, что это не очевидно параллельная задача: некоторые шаги графа зависят от результатов предыдущих шагов. Но это не значит, что она вообще не может быть параллелизована; Dask все еще может распараллелить части этого расчета, разделив ваши данные на разбиения (partitions). 3. Разбиения (partitions) Разбиение – это логическое разделение данных, каждую часть которых можно обрабатывать независимо от других разбиений. Разбиения используются во многих областях сферы распределенных вычислений: файлы Parquet разделены на разбиения, так же как DataFrame в Dask и RDD в Spark. Такие пакеты данных иногда называются «кусками» (chunks). В очевидно параллельном Эксперименте 1, приведенном выше, мы «разбили» цель нашего эксперимента (большой кусок сыра) на три независимых разбиения (или «куска»). Каждый Мышкетер мог после этого выполнить необходимую работу над своим разбиением, и они вместе достигали своей общей цели – съесть весь сыр.  Рисунок автора, эмоджи взяты из twemoji Рисунок автора, эмоджи взяты из twemojiDataFrame Dask также разделены на разбиения. Каждое разбиение DataFrame Dask – это независимый DataFrame Pandas, который можно отправить для обработки отдельному обработчику (worker). 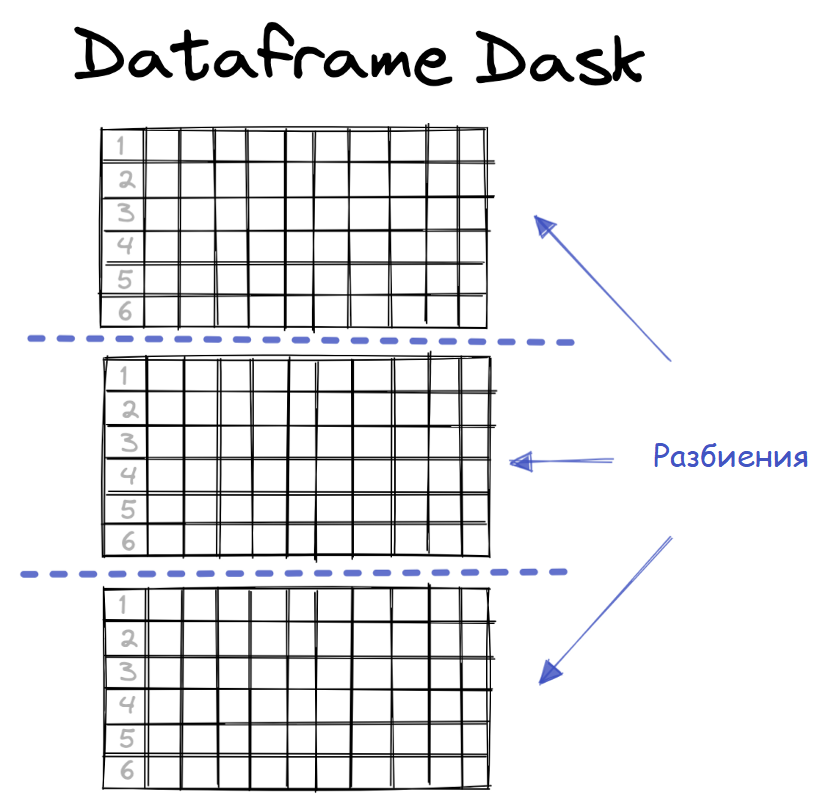 Рисунок автора Рисунок автораКогда вы пишете DataFrame Dask’а в Parquet, каждое разбиение DataFrame будет записано в отдельное разбиение Parquet. df = dask.datasets.timeseries( "2000-01-01", "2000-01-08", freq="1h", partition_freq="1d" ) df.npartitions >> 7 df 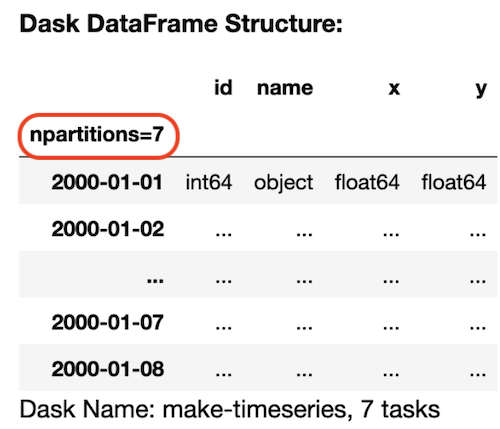 Изображение автора Изображение автора# Пишем каждое разбиение dask в отдельное разбиение Parquet df.to_parquet("test.parquet") И чтобы собрать воедино все концепции, о которых мы говорили, загрузка разбитого файла Parquet в DataFrame Dask будет очевидно параллельной задачей, поскольку каждое разбиение Parquet можно загрузить в отдельное разбиение DataFrame независимо от других разбиений. df = dd.read_parquet("test") df.visualize() 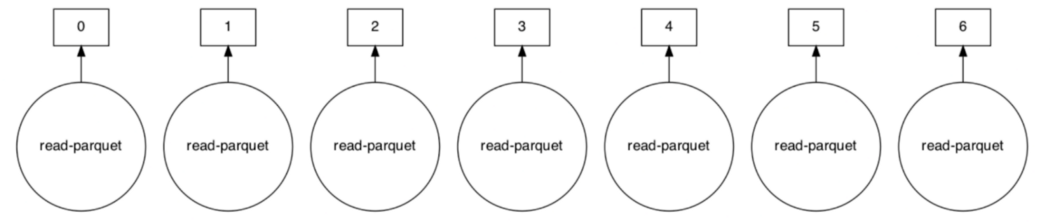 Изображение автора Изображение автораГрафы задач вроде приведенных выше создаются и рассылаются планировщиком (scheduler). 4. Планировщики (schedulers) Планировщик – это компьютерный процесс, управляющий распределением данных и синхронизацией вычислений, производимых с этими данными в вашей системе распределенных вычислений. Он следит за тем, чтобы данные обрабатывались эффективно и безопасно многими процессами одновременно, а также распределяет нагрузку на основе имеющихся ресурсов.  Изображение взято с giphy.com Изображение взято с giphy.comВ простой очевидно параллельной задаче вроде распараллеливания цикла for, достаточно просто отследить, кто что должен делать. Но это становится намного труднее делать в задачах, содержащих миллионы или даже миллиарды строк данных. На какой машине лежит каждая часть данных? Как мы будем избегать дубликатов? Если мы допускаем дубликаты, какую копию мы будем использовать? Как мы соберем все разбиения снова в единое целое? Возвращаясь к Меркуцио и его друзьям, давайте представим, что каждому из наших Трех Мышкетеров поручена своя независимая часть общего блюда: Меркуцио жарит лук, Тибальт натирает сыр, а Леди Монтекки тушит брокколи.  Рисунок автора, эмоджи взяты из twemoji Рисунок автора, эмоджи взяты из twemojiА теперь представьте, что на нашей кухне работают не 3, а 30 мышей, и их деятельность надо четко синхронизировать и координировать, чтобы использовать имеющиеся кухонные принадлежности наилучшим образом. Если мы оставим эту координацию самим мышам, вскоре наступит хаос: каждая мышь слишком занята своей частью работы, независимой от других, чтобы иметь четкую картину общей ситуации и распределять задачи и ресурсы наиболее эффективно. Мыши будут требовать одни и те же сковородки и ножи, и скорее всего, блюдо не будет приготовлено вовремя к обеду. Познакомьтесь с Мастер-Шефом.  Эмоджи взят из twemoji Эмоджи взят из twemojiМастер-Шеф (также известный как «Планировщик») хранит рецепт блюда, не терпящий отклонений, и будет распределять задачи и выделять ресурсы каждой готовящей мыши по необходимости. Когда индивидуальные компоненты блюда будут готовы, каждая мышь вернет результат своей работы Мастер-Шефу, который объединит их в готовый продукт.  Рисунок автора, эмоджи взяты из twemoji Рисунок автора, эмоджи взяты из twemojiСуществует множество различных видов планировщиков, и может быть полезно изучить доступные опции той платформы распределенных вычислений, которую вы собираетесь использовать. В зависимости от того, работаете вы на локальном или удаленном кластере, планировщики могут быть отдельными процессами на одной машине либо полностью автономными компьютерами. Планировщики – это центральная часть любого кластера распределенных вычислений. 5. Кластеры Кластер – это группа компьютеров или компьютерных процессов, работающих вместе как единое целое. Кластеры – это основа архитектуры любой системы распределенных вычислений. Независимо от конкретной реализации архитектуры кластера, все кластеры имеют общие элементы: клиентов, планировщиков и рабочих. Клиент – это то место, где вы пишете код, содержащий инструкции для вычисления. В случае Dask – это ваша сессия iPython или Jupyter Notebook (или любая среда, в которой вы пишете и запускаете свой код Python). Планировщик – это компьютерный процесс, координирующий вашу систему распределенных вычислений. Для локального кластера на вашем ноутбуке это просто отдельный процесс Python. Для большого кластера суперкомпьютеров или удаленного облачного кластера планировщик часто располагается на отдельном компьютере. Рабочие – это компьютерные процессы, выполняющие фактическую работу, запуская вычисления над разбиениями данных. В локальном кластере на вашем ноутбуке каждый рабочий – это процесс, занимающий одно из ядер вашего процессора. В удаленном кластере каждый рабочий зачастую представляет собой отдельную (возможно, виртуальную) машину. 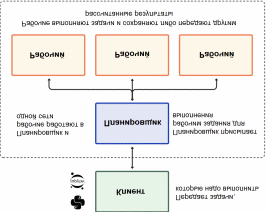 Изображение взято с dask.org Изображение взято с dask.orgКластеры могут существовать либо локально, на одной машине, либо удаленно, распределенными между несколькими различными (возможно, виртуальными) машинами, либо на облачном сервере. Таким образом, кластер может состоять из: Нескольких ядер внутри одной машины; Нескольких машин внутри одного физического пространства (высокопроизводительный суперкомпьютер); Нескольких виртуальных машин, распределенных в физическом пространстве (облачный кластер). 6. Улучшение (Scaling Up) против расширения (Scaling Out) При работе в мире распределенных вычислений вы будете часто слышать, как люди используют термины «улучшение» (Scaling Up) и «расширение» (Scaling Out). Это обычно относится к различиям между использованием локального и распределенного кластеров. Улучшение означает использование большего количества локальных ресурсов, а расширение – использование большего количества удаленных ресурсов. 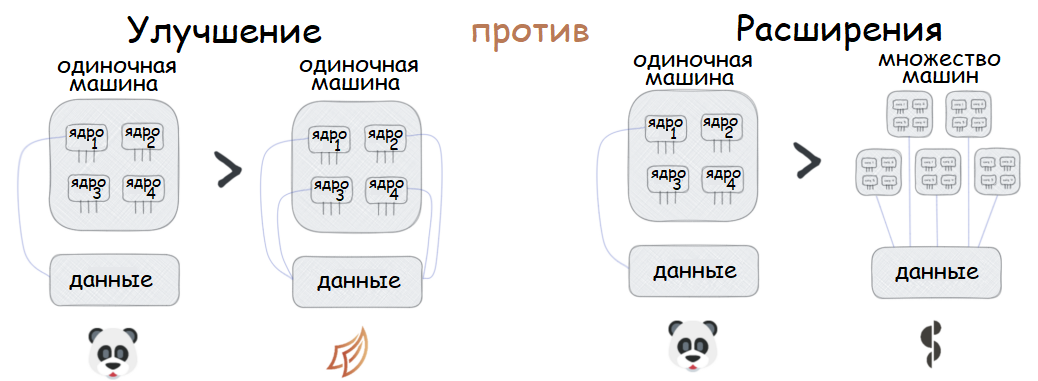 Рисунок автора, эмоджи взяты из twemoji Например, переход от вычислений с помощью pandas (использующей только одно ядро вашего компьютера) к использованию локального кластера Dask – это пример улучшения. А перенос тех же вычислений с pandas на удаленный кластер Dask через Coiled – это пример расширения. # РАСШИРЕНИЕ вычислений на облачный кластер # Запустить облачный кластер через Coiled import coiled cluster = coiled.Cluster(n_workers=20) # подключить кластер к Dask from dask.distributed import Client client = Client(cluster) # запустить вычисления над более чем 40 Гб данных на удаленном облачном кластере ddf = dd.read_parquet('s3://coiled-datasets/timeseries/20-years/parquet/') ddf.groupby('name').x.mean().compute() Улучшение может также включать переход с CPU на GPU, то есть «аппаратное ускорение». Dask может использовать cudf вместо pandas, чтобы перенести операции над вашими DataFram’ами на ваши GPU, чтобы ускорить эти операции во много раз. (Спасибо Джейкобу Томлинсону за уточнение этого вопроса). 7. Параллельные и распределенные вычисления Различие между параллельными и распределенными вычислениями состоит в том, используют ли вычислительные процессы одну и ту же память. 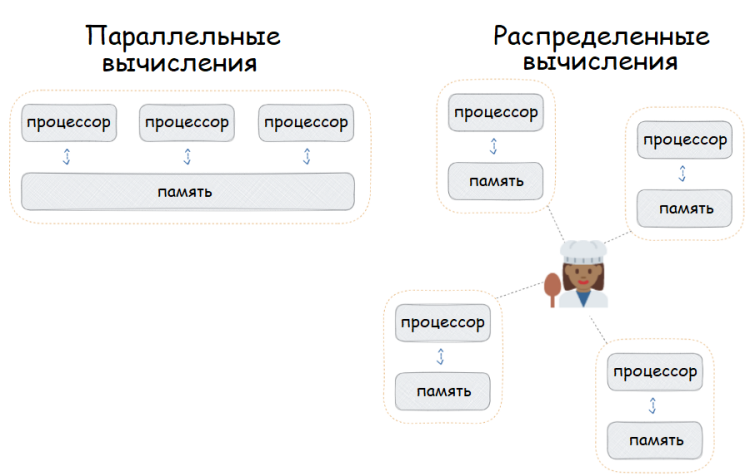 Рисунок автора, эмоджи взяты из twemoji Параллельные вычисления выполняют задачи, используя множество процессоров, разделяющих одну и ту же память. Эта разделяемая память необходима, поскольку отдельные процессы работают вместе над одной и той же задачей. Параллельные вычислительные системы ограничены количеством процессоров, способных работать с разделяемой памятью. С другой стороны, распределенные вычисления выполняют задачи на разных компьютерах, не имеющих общей памяти; эти компьютеры общаются друг с другом путем передачи сообщений. Это означает, что общая задача разбивается на несколько отдельных задач, центральный планировщик объединяет результаты всех индивидуальных задач и возвращает общий результат пользователю. Распределенные вычислительные системы теоретически можно расширять до бесконечности. Поехали! Семь концепций, представленных и разобранных в этой статье, дали вам необходимую базу для высадки в Великой Вселенной Распределенных Вычислений. Теперь для вас настало время пристегнуть ракетный ранец и продолжать исследования самостоятельно. Отличный путь для серьезного исследователя возможностей распределенных вычислений – это изучение Dask Tutorial. Это обучающий курс, который вы можете пройти за 1-2 часа в удобном для вас темпе. Спасибо за внимание! *** Материалы по теме |