отчет по практике. Содержание роль проектирования данных в жизненном цикле информационных систем 5
 Скачать 294.92 Kb. Скачать 294.92 Kb.
|

|
СОДЕРЖАНИЕ 1.Роль проектирования данных в жизненном цикле информационных систем: 5 2.Составные части процесса проектирования данных: 5 Логическое моделирование: 6 3.Физическое проектирование данных: 8 4.Наиболее популярные средства проектирования данных: 10 Представим подборку бесплатных/платных CASE-средств для проектирования баз данных: 11 1. MySQLWorkbenchCommunityEdition – интегрированная среда для проектировщиков, разработчиков и администраторов баз данных, реализующая функции визуального проектирования, разработки и эксплуатации баз данных MySQL . 11 2. dbForgeStudioforMySQL – профессиональный инструмент для разработки, администрирования и управления базами данных MySQL и Maria DB от компании Devart. С его помощью автоматизируются задачи проектирования, разработки и администрирования БД MySQL . 11 3. HeidiSQL – бесплатное ПО с открытым исходным кодом, для управления базами данных MySQL, Microsoft SQL Server, PostgreSQL. 11 4. AllFusionERwinDataModeler (ранее ERwin) — CASE-средство для проектирования и документирования баз данных, которое позволяет создавать, документировать и сопровождать БД, хранилища и витрины данных. Модели данных помогают визуализировать структуру данных . 11 5. Конструктор БД Руна — простой и удобный конструктор для создания баз данных и программ учёта. Позволяет самостоятельно создать программу учета товаров, базу данных клиентов или личный справочник. Поддерживает многопользовательскую работу в локальной сети и Интернет . 11 6. Navicat (разработка компании PremiumSoftCyberTechLtd) — инструмент для разработки и администрирования БД, который работает на любом сервере MySQL, начиная с версии 3.21. Для MySQLNavicatдоступен для работы на платформах Microsoft Windows, Mac OS X и Linux . 11 7. ApexSQLDiff предоставляет администраторам баз данных и разработчикам интегрированную среду инструментов, позволяющую осуществлять: дизайн и моделирование БД, разработку SQL, управление БД, миграциюБД . 12 8. AquaDataStudio — универсальная утилита для создания, управления, поддержки реляционных БД, гибкое многоплатформенное приложение, предоставляющее ИТ-специалистам широчайшие возможности управления базами данных от различных производителей (Oracle, DB2, Microsoft SQL Server, MySQL, Sybase, Informix и PostgreSQL). Программа разработана на Java, что позволяет ей работать на различных ОС . 12 9. Data Express– это конструктор приложений баз данных. DX позволяет создать качественную простую программу учета, ничем не уступающую такому же приложению, написанному на языке программирования. 12 5 Моделирование данных 15 5.1 Case-метод Баркера 15 Заключение: 28 ВВЕДЕНИЕ CASE-средства (от Computer Aided Software/System Engineering) набор инструментов и методов программной инженерии для проектирования программного обеспечения, который помогает обеспечить высокое качество программ, отсутствие ошибок и простоту в обслуживании программных продуктов. Также под CASE понимают совокупность методов и средств проектирования информационных систем с интегрированными автоматизированными инструментами, которые могут быть использованы в процессе разработки программного обеспечения. В функции CASE входят средства анализа, проектирования и программирования. С помощью CASE автоматизируются процессы проектирования интерфейсов, документирования и производства структурированного кода на желаемом языке программирования. Выделяют две основные концепции компьютерного программного обеспечения системы CASE: простые и «прозрачные» методы упрощения разработки программного обеспечения и/или его технического обслуживания; инженерный подход к разработке программного обеспечения и/или его технического обслуживания. Типичными CASE инструментами являются: инструменты управления конфигурацией; инструменты моделирования данных; инструменты анализа и проектирования; инструменты преобразования моделей; инструменты редактирования программного кода; инструменты рефакторинга кода; генераторы кода. CASE-средства позволяют моделировать бизнес-процессы, базы данных, компоненты программного обеспечения, деятельность и структуру организаций. Применимы практически во всех сферах деятельности. Результат применения CASE-средств - оптимизация систем, снижение расходов, повышение эффективности, снижение вероятности ошибок. Программные продукты: Computer Associates. IBM Rational Software. CA ERwin Modeling Suite. Oracle Designer (входит в Oracle9i Developer Suite). В связи с наглядностью представления концептуальных схем баз данных ER-модели получили широкое распространение в CASE-средствах. Эти средства предназначены для автоматизированного проектирования реляционных баз данных. Широко распространены CASE-системы, позволяющие выполнять ER-диаграммы в соответствии со стандартом IDEF1X. К ним относятся, в частности, Erwin, Design/IDEF, Power Designer. CASE-средства позволяют строить ER-диаграммы в реальном масштабе времени, что дает возможность наглядно изучать концептуальную модель данных и перестраивать ее соответственно поставленным целям и имеющимся ограничениям. Роль проектирования данных в жизненном цикле информационных систем: Жизненный цикл информационной системы в общем случае начинается в момент принятия решения о ее создании и заканчивается в момент выведения ее из эксплуатации. Основными его этапами обычно являются: проведение предпроектного обследования; проектирование данных; разработка приложений, тестирование, написание документации; внедрение созданной информационной системы и обучение пользователей; эксплуатация и сопровождение; выведение из эксплуатации и утилизация. Многие современные СУБД содержат визуальные средства (нередко входящие в состав утилит администрирования), позволяющие создать новую схему базы данных или просмотреть уже имеющуюся. Существуют также и утилиты (поставляемые отдельно от СУБД), позволяющие разрабатывать или редактировать метаданные. Однако в последнее время все более популярными становятся CASE-средства (Computer-Aided System Engineering). Существует несколько типов CASE-средств, но для создания баз данных чаще всего используются те из них, что содержат в своем составе инструменты для создания диаграмм «сущность-связь» и проектирования данных. Ниже мы рассмотрим процесс проектирования данных с помощью подобных инструментов. Составные части процесса проектирования данных:Процесс проектирования данных можно условно разделить на два этапа: логическое моделирование и физическое проектирование. Результатом первого из них является так называемая логическая (или концептуальная) модель данных, выражаемая обычно диаграммой «сущность-связь» или ER (Entity-Relationship) диаграммой, которая представлена в одной из стандартных нотаций, принятых для отображения подобных диаграмм. Результатом второго этапа является готовая база данных либо DDL-скрипт для ее создания. Логическое моделирование:Логическая модель данных описывает факты и объекты, подлежащие регистрации в будущей базе данных. Основными компонентами такой модели являются сущности, их атрибуты и связи между ними. Как правило, физическим аналогом сущности в будущей базе данных является таблица, а физическим аналогом атрибута — поле этой таблицы. С логической точки зрения сущность представляет собой совокупность однотипных объектов или фактов, называемых экземплярами этой сущности. Физическим аналогом экземпляра обычно является запись в таблице базы данных. Как и записи в таблице реляционной СУБД, экземпляры сущности должны быть уникальными, то есть полный набор значений их атрибутов не должен дублироваться. И так же, как и поля в таблице, атрибуты могут быть ключевыми и неключевыми На этапе логического проектирования для каждого атрибута обычно определяется примерный тип данных (строковый, числовой, BLOB и др.). Конкретизация происходит на этапе физического проектирования, так как различные СУБД поддерживают разные типы данных и ограничения на их длину или точность. Связь с логической точки зрения представляет собой соотношение между сущностями, которое нередко может быть выражено обычными фразами, где существительными являются названия связанных между собой сущностей. Подавляющее большинство средств проектирования данных позволяют создавать ER-диаграммы визуально, изображая сущности и соединяя их связями с помощью мыши. Интерфейс таких средств нередко настолько прост, что позволяет освоить логическое проектирование данных не только разработчику, но и пользователю-непрограммисту, если таковой участвует в проектировании данных как эксперт в предметной области на этапе логического проектирования можно описать поведение СУБД при нарушении правил ссылочной целостности, определяемых данной связью. Для этого многие (но не все!) средства проектирования данных обладают языком шаблонов, не зависящим от СУБД, на котором можно описать алгоритм обработки подобной ситуации, например с помощью соответствующих триггеров или иных объектов базы данных, а также набором стандартных шаблонов, реализующих некоторые типовые алгоритмы подобной обработки. В процессе создания физической модели эти шаблоны преобразуются в код на процедурном расширении языка SQL, применяемом в конкретной СУБД. Ряд публикаций проводит градацию категорий логических моделей по степени детализации описания сущностей, атрибутов и связей. Модель, обсуждаемая с заказчиком, являющимся обычно экспертом в подлежащей автоматизации предметной области, а не программистом или аналитиком, должна содержать, например, основные сущности и связи, но не обязана иметь их детальную техническую проработку .В то же время модель, служащая основой технического задания на разработку клиентских приложений, обязана содержать детальное представление структуры данных, ключевых атрибутов, их текстовое описание, а также представлять сущности в нормализованном виде (иногда такая модель называется полной атрибутивной моделью). Иными словами, нормализация модели данных обычно происходит на этапе логического проектирования. Отметим, что логическая модель данных, как правило, не связана с конкретной СУБД и не учитывает технические особенности конкретных платформ, применяемых при ее последующей физической реализации. Физическое проектирование данных:Физическое проектирование данных осуществляется на основе логической модели. Результатом этого процесса является физическая модель, содержащая полную информацию, необходимую для генерации всех необходимых объектов в базе данных. Для СУБД, поддерживающих системный каталог, физическая модель соответствует его содержимому. Обычно на основании физической модели создается DDL -скрипт для создания объектов базы данных либо эти объекты создаются непосредственно из CASE-средства — подавляющее большинство современных средств такого класса поддерживает различные механизмы доступа к данным и может выступать в роли клиентского приложения, инициирующего выполнение DDL-скриптов. В процессе физического проектирования следует определить наименования таблиц и типы данных для всех полей. Если необходимо, на этом же этапе описываются представления (если таковые будут создаваться) и может быть создан код хранимых процедур. Далее обычно полагается определить, какие именно объекты и как будут создаваться: например, с помощью каких SQL-предложений создаются индексы, с помощью каких объектов — триггеров или серверных ограничений — реализуется ссылочная целостность, создаются ли индексы для альтернативных ключей и т.д. Как правило, современные средства проектирования данных поддерживают несколько типов СУБД (например, ERwin фирмы Computer Associates поддерживает более 20 различных СУБД). Уровень поддержки той или иной платформы в разных средствах проектирования данных может быть различен. Например, конкретное средство может поддерживать или не поддерживать для данной СУБД такие особенности, как создание хранимых процедур, генерация объектов физической памяти (табличных пространств, сегментов отката и др.), задание местоположения объектов базы данных в физических объектах и т.д. Поэтому, выбирая средство проектирования данных для решения конкретной задачи, стоит поинтересоваться, каковы его возможности с точки зрения поддержки особенностей той или иной платформы — при удачном раскладе можно сэкономить немало времени на «ручное» доведение создаваемой базы данных (или DDL-скрипта для ее генерации) до необходимого состояния. При этом, естественно, чем больше возможностей и платформ поддерживает конкретное средство проектирования данных, тем дороже оно стоит. физическое проектирование может включать и дополнительную «ручную» работу по доведению базы данных или скрипта для ее генерации до «товарного» вида. Например, нередко в скрипт также включаются SQL-предложения для заполнения некоторых таблиц, данные которых более или менее постоянны, таких, например, как список субъектов Российской Федерации или справочник телефонных кодов различных стран, а также нестандартные триггеры и процедуры. В последнее время в техническое задание на разработку приложений нередко включается полное описание физической модели данных или ее части, с которой должно иметь дело разрабатываемое приложение. Подавляющее большинство современных средств проектирования данных предоставляют возможность не только документировать модель, но и создавать по ней отчеты, содержащие те или иные сведения о модели, в том числе сведения, необходимые для разработки приложений. Некоторые средства проектирования данных позволяют хранить их модели в специальных репозитариях, а также осуществлять коллективное проектирование. Нередко средства проектирования данных дают возможность также присваивать таблицам и полям так называемые расширенные атрибуты, то есть свойства, связанные с отображением их в клиентских приложениях, созданных с помощью какого-либо средства разработки, а также генерировать код приложений для ввода и отображения данных. Кроме того, подавляющее большинство средств проектирования данных позволяют восстанавливать физическую модель данных их системного каталога и представлять ее в виде ER-диаграммы (этот процесс называется обратным проектированием — reverse engineering), а также производить синхронизацию системного каталога и физической модели. При создании информационной системы, которая должна использовать унаследованные от предшествующих ей систем данные, такая особенность весьма полезна — в этом случае логическое проектирование можно начать с модификации уже имеющейся модели (этот процесс получил название round-trip engineering). Обсудив, что представляет собой процесс проектирования данных, мы можем перейти к рассмотрению наиболее популярных продуктов, с помощью которых можно его осуществить. Наиболее популярные средства проектирования данных:Представим подборку бесплатных/платных CASE-средств для проектирования баз данных:1. MySQLWorkbenchCommunityEdition – интегрированная среда для проектировщиков, разработчиков и администраторов баз данных, реализующая функции визуального проектирования, разработки и эксплуатации баз данных MySQL . 2. dbForgeStudioforMySQL – профессиональный инструмент для разработки, администрирования и управления базами данных MySQL и Maria DB от компании Devart. С его помощью автоматизируются задачи проектирования, разработки и администрирования БД MySQL . 3. HeidiSQL – бесплатное ПО с открытым исходным кодом, для управления базами данных MySQL, Microsoft SQL Server, PostgreSQL. 4. AllFusionERwinDataModeler (ранее ERwin) — CASE-средство для проектирования и документирования баз данных, которое позволяет создавать, документировать и сопровождать БД, хранилища и витрины данных. Модели данных помогают визуализировать структуру данных . 5. Конструктор БД Руна — простой и удобный конструктор для создания баз данных и программ учёта. Позволяет самостоятельно создать программу учета товаров, базу данных клиентов или личный справочник. Поддерживает многопользовательскую работу в локальной сети и Интернет . 6. Navicat (разработка компании PremiumSoftCyberTechLtd) — инструмент для разработки и администрирования БД, который работает на любом сервере MySQL, начиная с версии 3.21. Для MySQLNavicatдоступен для работы на платформах Microsoft Windows, Mac OS X и Linux . 7. ApexSQLDiff предоставляет администраторам баз данных и разработчикам интегрированную среду инструментов, позволяющую осуществлять: дизайн и моделирование БД, разработку SQL, управление БД, миграциюБД . 8. AquaDataStudio — универсальная утилита для создания, управления, поддержки реляционных БД, гибкое многоплатформенное приложение, предоставляющее ИТ-специалистам широчайшие возможности управления базами данных от различных производителей (Oracle, DB2, Microsoft SQL Server, MySQL, Sybase, Informix и PostgreSQL). Программа разработана на Java, что позволяет ей работать на различных ОС . 9. Data Express– это конструктор приложений баз данных. DX позволяет создать качественную простую программу учета, ничем не уступающую такому же приложению, написанному на языке программирования.Сравнительная характеристика средств автоматизации проектирования баз данных представлена в таблице 1.
Table 1 Сравнительная характеристика средств автоматизации проектирования баз данных 5 Моделирование данных 5.1 Case-метод Баркера Цель моделирования данных состоит в обеспечении разработчика ИС концептуальной схемой базы данных в форме одной модели или нескольких локальных моделей, которые относительно легко могут быть отображены в любую систему баз данных. Наиболее распространенным средством моделирования данных являются диаграммы "сущность-связь" (ERD). С их помощью определяются важные для предметной области объекты (сущности), их свойства (атрибуты) и отношения друг с другом (связи). ERD непосредственно используются для проектирования реляционных баз данных. Нотация ERD была впервые введена П. Ченом (Chen) и получила дальнейшее развитие в работах Баркера . Метод Баркера будет излагаться на примере моделирования деятельности компании по торговле автомобилями. Ниже приведены выдержки из интервью, проведенного с персоналом компании. Главный менеджер: одна из основных обязанностей - содержание автомобильного имущества. Он должен знать, сколько заплачено за машины и каковы накладные расходы. Обладая этой информацией, он может установить нижнюю цену, за которую мог бы продать данный экземпляр. Кроме того, он несет ответственность за продавцов и ему нужно знать, кто что продает и сколько машин продал каждый из них. Продавец: ему нужно знать, какую цену запрашивать и какова нижняя цена, за которую можно совершить сделку. Кроме того, ему нужна основная информация о машинах: год выпуска, марка, модель и т.п. Администратор: его задача сводится к составлению контрактов, для чего нужна информация о покупателе, автомашине и продавце, поскольку именно контракты приносят продавцам вознаграждения за продажи. Первый шаг моделирования - извлечение информации из интервью и выделение сущностей. Сущность (Entity) - реальный либо воображаемый объект, имеющий существенное значение для рассматриваемой предметной области, информация о котором подлежит хранению (рисунок 5.1). 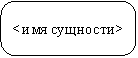 Рис. 5.1. Графическое изображение сущности Каждая сущность должна обладать уникальным идентификатором. Каждый экземпляр сущности должен однозначно идентифицироваться и отличаться от всех других экземпляров данного типа сущности. Каждая сущность должна обладать некоторыми свойствами: каждая сущность должна иметь уникальное имя, и к одному и тому же имени должна всегда применяться одна и та же интерпретация. Одна и та же интерпретация не может применяться к различным именам, если только они не являются псевдонимами; сущность обладает одним или несколькими атрибутами, которые либо принадлежат сущности, либо наследуются через связь; сущность обладает одним или несколькими атрибутами, которые однозначно идентифицируют каждый экземпляр сущности; каждая сущность может обладать любым количеством связей с другими сущностями модели. Обращаясь к приведенным выше выдержкам из интервью, видно, что сущности, которые могут быть идентифицированы с главным менеджером - это автомашины и продавцы. Продавцу важны автомашины и связанные с их продажей данные. Для администратора важны покупатели, автомашины, продавцы и контракты. Исходя из этого, выделяются 4 сущности (автомашина, продавец, покупатель, контракт), которые изображаются на диаграмме следующим образом (рисунок 5.2). 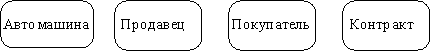 Рис. 5.2. выделяются 4 сущности диаграмме Следующим шагом моделирования является идентификация связей. Связь (Relationship) - поименованная ассоциация между двумя сущностями, значимая для рассматриваемой предметной области. Связь - это ассоциация между сущностями, при которой, как правило, каждый экземпляр одной сущности, называемой родительской сущностью, ассоциирован с произвольным (в том числе нулевым) количеством экземпляров второй сущности, называемой сущностью-потомком, а каждый экземпляр сущности-потомка ассоциирован в точности с одним экземпляром сущности-родителя. Таким образом, экземпляр сущности-потомка может существовать только при существовании сущности родителя. Связи может даваться имя, выражаемое грамматическим оборотом глагола и помещаемое возле линии связи. Имя каждой связи между двумя данными сущностями должно быть уникальным, но имена связей в модели не обязаны быть уникальными. Имя связи всегда формируется с точки зрения родителя, так что предложение может быть образовано соединением имени сущности-родителя, имени связи, выражения степени и имени сущности-потомка. Например, связь продавца с контрактом может быть выражена следующим образом: продавец может получить вознаграждение за 1 или более контрактов; контракт должен быть инициирован ровно одним продавцом. Степень связи и обязательность графически изображаются следующим образом (рисунок 5.3).  Рис. 5.3. Степень связи и обязательность графически Таким образом, 2 предложения, описывающие связь продавца с контрактом, графически будут выражены следующим образом (рисунок 5.4). Рис. 5.4. описывающие связь продавца с контрактом Описав также связи остальных сущностей, получим следующую схему (рисунок 5.5). 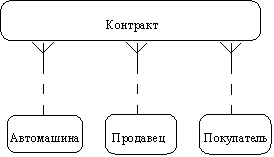 Рис. 5.5. Описав также связи остальных сущностей Последним шагом моделирования является идентификация атрибутов. Атрибут - любая характеристика сущности, значимая для рассматриваемой предметной области и предназначенная для квалификации, идентификации, классификации, количественной характеристики или выражения состояния сущности. Атрибут представляет тип характеристик или свойств, ассоциированных со множеством реальных или абстрактных объектов (людей, мест, событий, состояний, идей, пар предметов и т.д.). Экземпляр атрибута - это определенная характеристика отдельного элемента множества. Экземпляр атрибута определяется типом характеристики и ее значением, называемым значением атрибута. В ER-модели атрибуты ассоциируются с конкретными сущностями. Таким образом, экземпляр сущности должен обладать единственным определенным значением для ассоциированного атрибута. Атрибут может быть либо обязательным, либо необязательным (рисунок 5.6). Обязательность означает, что атрибут не может принимать неопределенных значений (null values). Атрибут может быть либо описательным (т.е. обычным дескриптором сущности), либо входить в состав уникального идентификатора (первичного ключа). Уникальный идентификатор - это атрибут или совокупность атрибутов и/или связей, предназначенная для уникальной идентификации каждого экземпляра данного типа сущности. В случае полной идентификации каждый экземпляр данного типа сущности полностью идентифицируется своими собственными ключевыми атрибутами, в противном случае в его идентификации участвуют также атрибуты другой сущности-родителя (рисунок 5.7). 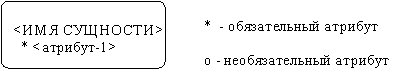 Рис. 5.6. Атрибут может быть либо обязательным, либо необязательным 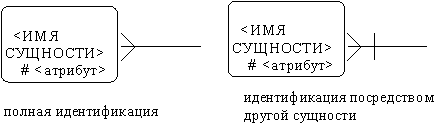 Рис. 5.7. атрибуты другой сущности-родителя Каждый атрибут идентифицируется уникальным именем, выражаемым грамматическим оборотом существительного, описывающим представляемую атрибутом характеристику. Атрибуты изображаются в виде списка имен внутри блока ассоциированной сущности, причем каждый атрибут занимает отдельную строку. Атрибуты, определяющие первичный ключ, размещаются наверху списка и выделяются знаком "#". Каждая сущность должна обладать хотя бы одним возможным ключом. Возможный ключ сущности - это один или несколько атрибутов, чьи значения однозначно определяют каждый экземпляр сущности. При существовании нескольких возможных ключей один из них обозначается в качестве первичного ключа, а остальные - как альтернативные ключи. С учетом имеющейся информации дополним построенную ранее диаграмму (рисунок 5.8). Помимо перечисленных основных конструкций модель данных может содержать ряд дополнительных. Подтипы и супертипы: одна сущность является обобщающим понятием для группы подобных сущностей (рисунок 5.9). Взаимно исключающие связи: каждый экземпляр сущности участвует только в одной связи из группы взаимно исключающих связей (рисунок 5.10). 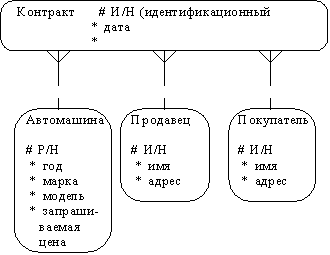 Рис. 5.8. первичный ключ 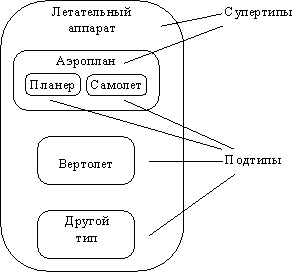 Рис. 5.9. Подтипы и супертипы 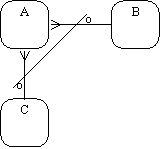 Рис. 5.10. Взаимно исключающие связи Рекурсивная связь: сущность может быть связана сама с собой (рисунок 5.11). Неперемещаемые (non-transferrable) связи: экземпляр сущности не может быть перенесен из одного экземпляра связи в другой (рисунок 5.12).  Рис. 5.11. Рекурсивная связь Рис. 5.12. Неперемещаемая связь 5.2 Пример система аренды автомобилей: В качестве примера создадим модель базы данных для системы аренды автомобилей. Следующий этап - поиск столов. Ищем основные сущности в системе. Для начала у вас должно быть как минимум следующее: автомобиль, клиент, местоположение, город, оборудование, категория (автомобиль), страховка. Помещаем их на схему. Я добавил столбец id в каждую таблицу, потому что каждая таблица должна иметь какой-то идентификатор ( Figure 5.13). 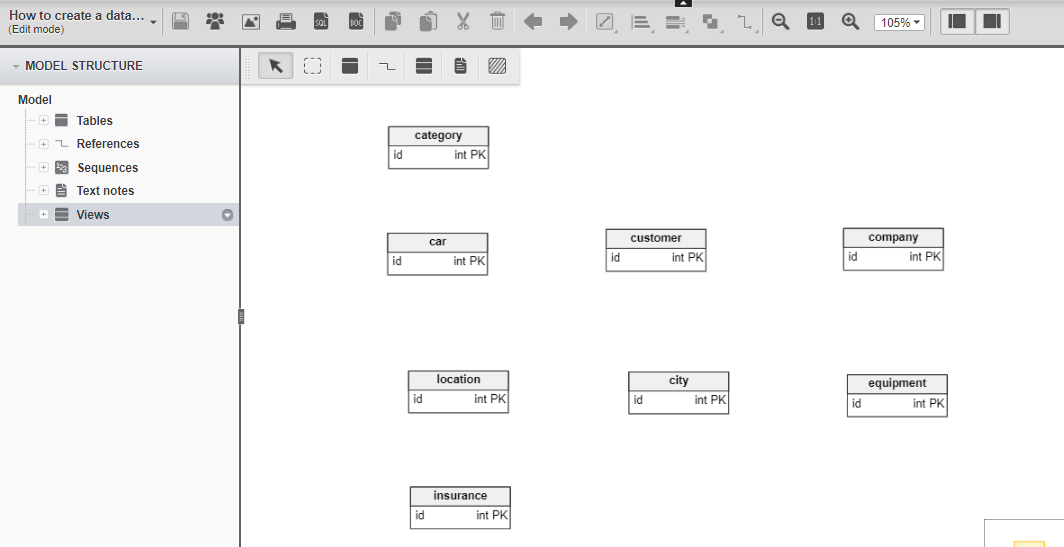 Figure 5.13 Ищем основные сущности в системе В модели присутствуют основные системные объекты, но вы должны заметить, что нам не хватает основных функций системы: аренды автомобилей и бронирования( Figure 5.14). 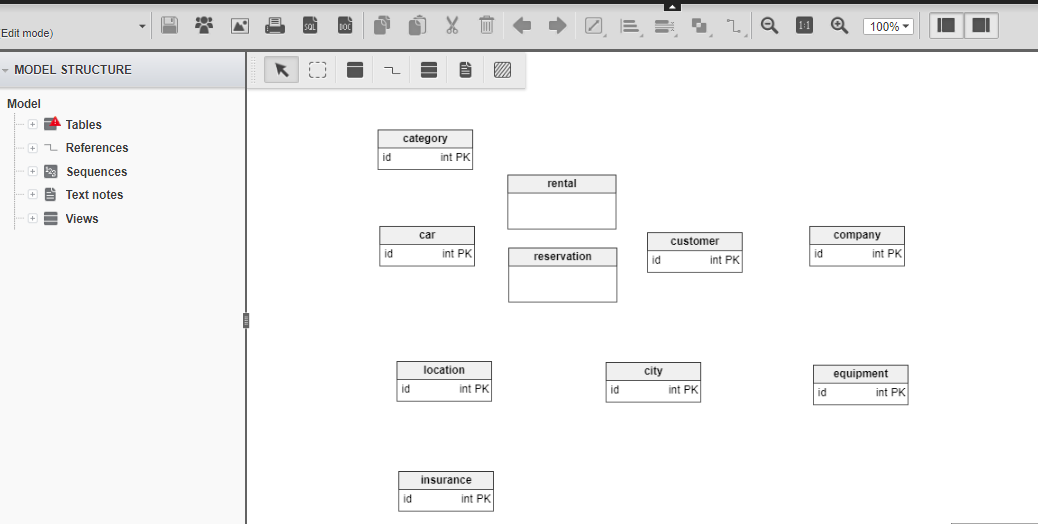 Figure 5.14 аренды автомобилей и бронирования Примечание рядом с каждой ссылкой сообщает вам, когда она была добавлена: 1. Каждый автомобиль относится к определенной категории, 2. Каждое бронирование относится к категории автомобилей, 3. Каждое место в городе, 4. В каждом бронировании указано место посадки и высадки. 5. Каждое бронирование осуществляется клиентом, 6. Каждая аренда осуществляется заказчиком, 7. Каждая аренда рассчитана на определенный автомобиль, 8. Каждая аренда имеет место получения и возврата. 9. Каждая аренда связана с определенной страховкой. Но есть ли только одна страховка на каждую аренду? Нет. С арендой может быть связано множество видов страхования (страхование от повреждений транспортного средства, от травм, от травм чужого автомобиля и т. Д.). Я добавил промежуточную таблицу под названием rental_insuranceconnected to rental and insurance tables (Figure 5.15). 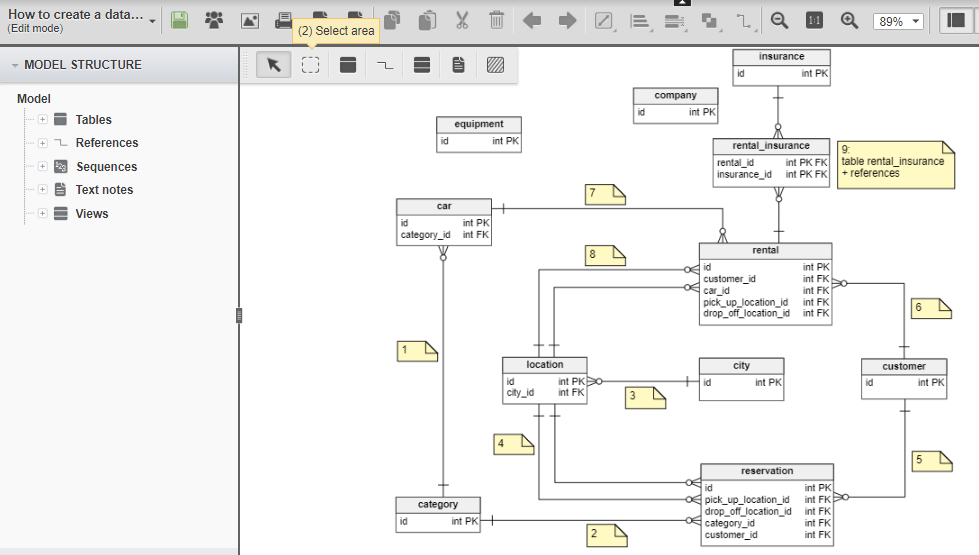 Figure 5.15 добавил промежуточную таблицу под названием rental_insuranceconnected to rental and insurance tables Наконец, мы добавляем столбцы и их типы данных. Мы также замечаем, что нет никакой связи между reservation and equipment. Но делается ли оговорка для конкретной единицы оборудования? Нет, это сделано для типа оборудования: добавляем таблицу equipment_category and connect the tables reservation and equipment to it ( Figure 5.16). 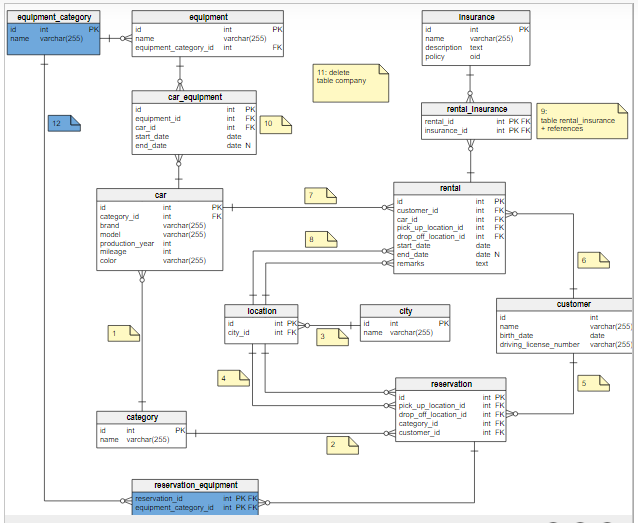 Figure 5.16 добавляем таблицу equipment_category and connect the tables reservation and equipment Заключение: В настоящей статье мы рассмотрели жизненный цикл информационных систем и убедились, что проектирование данных играет в нем ключевую роль. Мы также узнали, что представляют собой процессы логического (концептуального) и физического моделирования данных. Помимо этого мы рассмотрели несколько наиболее популярных средств проектирования данных — как специализированных, так и входящих в состав комплексных CASE-средств. Изучение возможностей этих продуктов свидетельствует о том, что все они, обладая своими особенностями и имея в определенной степени различающиеся сферы применения, как правило, имеют и сходные черты, в число которых входят: Поддержка создания логических моделей, не зависящих от СУБД, и генерации физических моделей на их основе. Поддержка нескольких типов СУБД, включая не только серверные, но и настольные. Поддержка специфических особенностей тех или иных СУБД ведущих производителей (генерация триггеров, управление физическим хранением данных). Возможность генерации отчетов и проектной документации на основе созданной модели. Возможность сохранения модели в репозитарии, который во многих случаях может быть разделяемым. Поддержка генерации кода для одного или нескольких средств разработки или языков программирования Список литературы: 1 Выбор средств разработки и создания баз данных. Режим доступа URL: https://studopedia.info/8-78448.html (дата обращения: 04.10.2020). 2 Десять лучших инструментов для разработки и администрирования MySQL. Режим доступа URL: https://habrahabr.ru/post/142385 (дата обращения: 04.10.2020). 3 Конструктор баз данных Руна. Режим доступа URL: http://runabase.ru/ (дата обращения: 04.10.2020). 4 Лучший инструмент для работы с базами данных MySQL. Режим доступа URL: https://www.devart.com/ru/dbforge/mysql/studio/ (дата обращения: 04.10.2020). 5 Назарова О. Б. Разработка реляционных баз данных с использованием CASE-средства ALL FUSION DATA MODELER: учеб.пособие / О. Б. Назарова, О. Е. Масленникова. — Магнитогорск, 2013. 6 Обзор средств проектирования информационных систем. Режим доступа URL: http://citforum.ru/database/kbd96/42.shtml (дата обращения: 04.10.2020). 7 Обзор программных средств для создания баз данных. Режим доступа URL: https://videouroki.net/razrabotki/obzor-programmnykh-sriedstv-dliasozdaniia-baz-dannykh.html (дата обращения: 04.10.2020). 8 Основные возможности Getreport. Режим доступа URL: http://getreport.pro/Home/BasicFeatures (дата обращения: 04.10.2020). 9 Коннолли, Т. Базы данных. Проектирование, реализация и сопровождение. Теория и практика : учебное пособие / Т. Коннолли, К. Бегг – Вильямс, 2017. – 1440 с.  |