Курсовая работа Теория вероятностей. Курсовая, Теория вероятностей, Степанов Е.С.. В соответствии со своим вариантом решить задание по программированию. Описать современные языки программирования, на которых возможно решить данную задачу.
 Скачать 487.21 Kb. Скачать 487.21 Kb.
|

|
Министерство науки и высшего образования Российской Федерации Тверской государственный технический университет Кафедра информационных систем КУРСОВАЯ РАБОТА Тема работы «В соответствии со своим вариантом решить задание по программированию. Описать современные языки программирования, на которых возможно решить данную задачу.» Студент 2 курса ФИТ факультета Б.ИСТ.РВС.19.35 группы заочного отделения Степанов Е.С. Проверил: к.т.н. Ветров А.Н. Тверь 2021 ОГЛАВЛЕНИЕ1.РАСЧЕТ ОСНОВНЫХ ПОКАЗАТЕЛЕЙ СТАТИСТИКИ 4 2. Построение гистограммы 8 3. Проверка соответствия закона распределения наблюдаемым данным 9 4. Проверка гипотезы о равенстве средних величин при известной дисперсии 10 5. Проверка гипотезы о равенстве дисперсий 11 6. Проверка гипотезы о равенстве средних величин при неизвестной дисперсии 12 7. ОДНОФАКТОРНЫЙ ДИСПЕРСИОННЫЙЙ АНАЛИЗ 15 8. ДВУХФАКТОРНЫЙ ДИСПЕРСИОННЫЙЙ АНАЛИЗ 18 9.ПРОСТАЯ ЛИНЕЙНАЯ РЕГРЕССИЯ 20 Введение Курсовая работа выполнена в системе EXCEL с использованием статистических функций и пакета анализа. Данная работа состоит из 9 разделов: Расчет основных показателей статистики. Построение гистограммы. Проверка соответствия закона распределения наблюдаемым данным. Проверка гипотезы о равенстве средних величин при известной дисперсии. Проверка гипотезы о равенстве средних величин при неизвестной дисперсии. Проверка гипотезы о равенстве дисперсий. Однофакторный дисперсионный анализ. Двухфакторный дисперсионный анализ без повторений и с повторениями. Простая линейная регрессия. Работа выполнялась в табличном процессоре MS Excel с использованием статистических функций и пакета анализа. Статистическая информация для выполнения заданий генерируется самостоятельно с помощью инструмента анализа «Генерация» пакета EXCEL в соответствии с вариантом задания. В соответствии с вариантом задания установлены следующие значения: 1. Математическое ожидание mx = 70; 2. Стандартное отклонение σx = 14. РАСЧЕТ ОСНОВНЫХ ПОКАЗАТЕЛЕЙ СТАТИСТИКИПоказатели описательной статистики делятся на несколько групп. 1. Показатели положения описывают положение данных на числовой оси. Примеры таких показателей: средняя арифметическая, средняя гармоническая, медиана и другие характеристики. 2. Показатели разброса описывают степень разброса данных относительно своего центра. К этой группе относятся: дисперсия, стандартное отклонение, размах выборки, эксцесс и т.п. Эти показатели определяют, насколько кучно основная масса данных группируется около центра. 3. Показатели асимметрии характеризуют симметрию распределения данных около своего центра. К ним можно относятся коэффициент асимметрии, положение медианы относительно среднего и т.п. 4. Показатели, описывающие закон распределения, дают представление о законе распределения данных. К ним относятся таблицы частот, средняя арифметическая, медиана, дисперсия, стандартное отклонение, гистограмма. Задание: 1. Сгенерировать 100 значений нормально распределенной случайной величины с параметрами mx, σx 2. Рассчитать значения показателей описательной статистики. 3. Рассчитанные значения свести в таблицу вида Ход работы: 1. Генерируем 100 значений нормально распределенной случайной величины с параметрами mx, σx 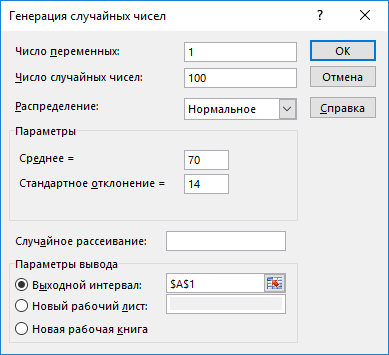 Рисунок 1. Генерация случайных чисел Рассчитаем значения показателей описательной статистики 1. Среднее. Функция СРЗНАЧ рассчитывает значение средней арифметической величины по формуле  где xi – i-ое значение выборки, n – число наблюдаемых значений выборки. 2. Медианой называется значение признака, приходящееся на середину упорядоченной совокупности. Используется функция МЕДИАНА. 3. Модой называется чаще всего встречающаяся варианта или то значение признака, которое соответствует максимальной точке теоретической кривой распределения. Используется функция МОДА. 4. Выборочная дисперсия рассчитывается по выборочным данным. Для этого используется выражение, где  – среднее арифметическое выборки. – среднее арифметическое выборки. Используется функция ДИСП. 5. Выборочное стандартное отклонение оценивает разброс возможных значений случайной величины вокруг её среднего. Формула для расчета стандартного отклонения 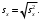 Для определения в Excel использовалась функция СТАНДОТКЛОН. 6. Стандартная (средняя) ошибка повторной собственно-случайной выборки определяется по формуле  где sx – выборочная дисперсия, n – число наблюдаемых значений выборки. 7. Эксцесс характеризует так называемую «крутость», т.е. островершинность или плосковершинность кривой распределения. Для определения в Excel используется функция ЭКСЦЕСС, которая рассчитывает значение эксцесса как для симметричных, так и для асимметричных распределений. 8. Симметричным является распределение, в котором частоты любых двух вариант, равноотстоящих в обе стороны от центра распределения, равны между собой. Для симметричных распределений средняя арифметическая, мода и медиана равны между собой. С учетом этого показатель асимметрии основан на соотношении показателей центра распределения: чем больше разница между х, Mo, Me, тем больше асимметрия ряда. При этом если Mo < Me, асимметрия правосторонняя, если Mo > Me – асимметрия левосторонняя. Функция СКОС определяет величину асимметрии по выборочной совокупности. При этом если As > О – асимметрия правосторонняя (положительная), если As < О — асимметрия левосторонняя 9. Функции МИН и МАКС используются для определения минимального и максимального значений признака в выборке. 10. Интервалрассчитываются как разность между наибольшим (хmах) и наименьшим (хmin) значениями выборки, т.е. и называется размах вариации. R = xmax– xmin 11. Функция СЧЕТ используется для определения величины n. 12. Функции НАИБОЛЬШИЙ и НАИМЕНЬШИЙ определяют k-ое максимальное и минимальное значения в выборке. 13. Уровень надёжности. Предельная ошибка выборки связана со средней ошибкой выборки соотношением  где t – коэффициент доверия, который определяется в зависимости от того, с какой доверительной вероятностью нужно гарантировать результаты выборочного обследования. В Excel коэффициент доверия t рассчитывался через функцию СТЬЮДРАСПОБР, в которой в качестве аргументов задаются уровень значимости и число степеней свободы df. Число степеней свободы df зависит от объема выборки n и связано с ним выражением df = n – 1. Границы доверительного интервала для математического ожидания находятся из выражения  2. Рассчитанные значения вставляем в таблицу.  Рисунок 2. Расчет показателей описательной статистики 2. Построение гистограммыЗадание: Сгенерировать 100 значений нормально распределенной случайной величины с параметрами mx, σx Построить гистограмму Построить нормированную эмпирическую функцию распределения Ход работы: Берем из 1 задания 100 значений нормально распределенной случайной величины с параметрами mx, σx. Строим гистограмму частот и гистограмму относительны частот.  Рисунок 3. Расчет показателей 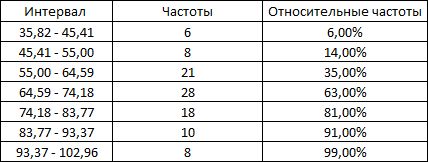 Рисунок 4. Частоты и относительные частоты  Рисунок 5. Гистограмма частот 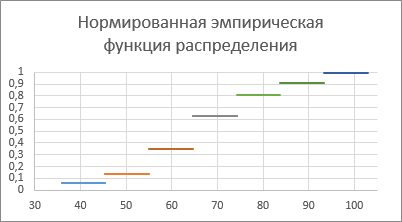 Рисунок 6. Нормированная эмпирическая функция распределения Проверка соответствия закона распределения наблюдаемым даннымХод работы: 1. Определяем число значений признака, попадающих в j – ый интервал 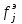 и среднее значение признака и среднее значение признака 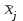 для каждого интервала. для каждого интервала.2. Вычисляем среднее значение вариационного ряда x. 3. Вычисляем выборочную дисперсию  и стандартное отклонение и стандартное отклонение  вариационного ряда. вариационного ряда.4. Вычисляем значения функции плотности нормального распределения для каждого интервала по формуле pj = НОРМРАСП(), в качестве x используем среднее значение на интервале, параметр ИНТЕГРАЛЬНАЯ = 0. 5. Рассчитываем теоретические частоты нормального распределения по формуле  где h – длина интервала, n – общее число наблюдаемых значений признака. где h – длина интервала, n – общее число наблюдаемых значений признака.6. Рассчитываем значение критерия c2 по формуле 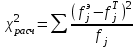  Рисунок 7. Проверка соответствия закона распределения Вывод: Так как 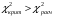 , то гипотеза о нормальности распределения СВ принимается. , то гипотеза о нормальности распределения СВ принимается.4. Проверка гипотезы о равенстве средних величин при известной дисперсииЗадание: 1. Сгенерировать 2 нормально распределенные переменные. Первая переменная генерируется в соответствии с Вашим вариантом. При генерации второй переменной математическое ожидание увеличивается на 2, а стандартное отклонение в 1,5 раза. 2. Проверить гипотезу о равенстве средних величин Ход работы 1: Вычисляем статистику Z. 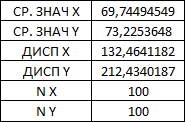 Рисунок 8. Статистика Z Задаёмся уровнем значимости 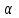 . .Рисунок 9. Уровень значимости Определяем критические точки. Сравниваем рассчитанное в пункте 1 значение Zсо значением критических точек  Рисунок 10. Двухвыборочный Z-тест для средних Вывод: z расч. < z крит., следовательно, гипотеза о равенстве средних значений при известной дисперсии принимается. 5. Проверка гипотезы о равенстве дисперсийЗадание: Используя данные задания 4 проверить гипотезу о равенстве дисперсий Ход работы: В математической статистике доказывается, что если гипотеза о равенстве дисперсий двух случайных величин выполняется: H0:  = =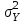 , то величина , то величина 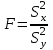 распределена в соответствии с законом распределения Фишера. распределена в соответствии с законом распределения Фишера.Это отношение F называют дисперсионным отношением Фишера и используют в качестве критерия проверки нулевой гипотезы. Распределение Фишера характеризуется наличием степеней свободы, которые вычисляются по формулам: 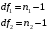 Поскольку величина F – неотрицательная, то критическая область данной величины будет принадлежать интервалу (0;+¥). Альтернативными являются гипотезы: Н1: > при  > > Н2: < при < Используем «Двух выборочный F-тест для дисперсии» Анализ данных MS Exсel.  Рисунок 11. Двух выборочный F-тест для дисперсии Вывод: Удвоенное значение р (уровень для одностороннего критерия P(F<=f)) будет больше, чем уровень значимости (0,05), следовательно, нулевая гипотеза о равенстве дисперсий не отклоняется. 6. Проверка гипотезы о равенстве средних величин при неизвестной дисперсииЗадание: Требуется для вашего варианта проверить гипотезу H0: mx=my, предположив, что соответствующие генеральные совокупности имеют нормальное распределение с одинаковыми дисперсиями; с различными дисперсиями. Ход работы: Для проверки гипотезы о равенстве средних (математических ожиданий) двух независимых нормальных распределений с неизвестными дисперсиями и используется t-тест Относительно дисперсий и можно выдвинуть следующие два предположения:1) Обе дисперсии неизвестны, но предполагается, что они равны между собой, т.е. = .2) Обе дисперсии неизвестны и предполагается, что они не равны между собой, т.е. ≠ .В случае, когда обе дисперсии неизвестны, но предполагается, что они равны между собой, мы имеем дело с двумя оценками и одной и той же дисперсии = .То в этом случае строится объединённая оценка:  Где S2 – это объединённая оценка дисперсии 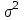 = = . = = .В математической статистике доказывается, что если нулевая гипотеза о равенстве математических ожиданий H0: mx=myвыполняется, то величина tвычисляется по формуле:  Где  и и  – средние арифметические величины, n1 – число наблюдений в первой выборке, n2 – число наблюдений во второй выборке, S – выборочное стандартное отклонение. – средние арифметические величины, n1 – число наблюдений в первой выборке, n2 – число наблюдений во второй выборке, S – выборочное стандартное отклонение.Статистика tимеет распределение Стьюдента. Число степеней свободы определяется по формуле:  Эту t-статистику и используем в качестве критерия при проверке нулевой гипотезы о равенстве математических ожиданий. Схема проверки аналогична проверке при использовании Z-теста.  Рисунок 12. Расчет данных Используем «Двухвыборочный t-тест с одинаковыми дисперсиями» Анализ данных MS Exсel.  Рисунок 13. Двухвыборочный t-тест с одинаковыми дисперсиями В случае, когда дисперсии неизвестны и предполагается, что они равны, используем аналог Z-теста с заменой дисперсий их оценками.  - это распределение близко к распределению Стьюдента. - это распределение близко к распределению Стьюдента.Число степеней свободы вычисляем по следующей формуле:  В данном случае t-статистику, используем для проверки нулевой гипотезы о равенстве средних величин при различных неизвестных дисперсиях, называют критерием Фишера-Беренса. Рисунок 14. Расчет данных Используем «Двухвыборочный t-тест с различными дисперсиями» Анализ данных MS Exсel. 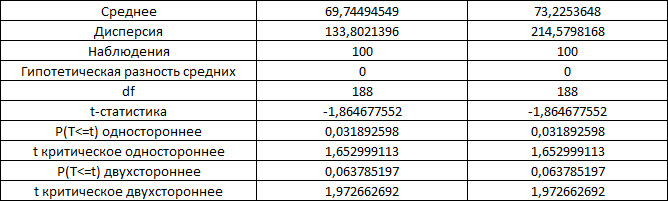 Рисунок 15. Двухвыборочный t-тест с различными дисперсиями В данном случае t-статистику, используемую для проверки нулевой гипотезы о равенстве средних величин при различных неизвестных дисперсиях, называют критерием Фишера-Беренса. Вывод: t расч. < t критич. Следовательно, гипотеза о равенстве средних значений при неизвестной дисперсии подтверждается. 7. ОДНОФАКТОРНЫЙ ДИСПЕРСИОННЫЙЙ АНАЛИЗЗадание: Сгенерировать 4 нормально распределенные переменные. Первые 3 переменные генерируется в соответствии с Вашим вариантом. При генерации четвертой переменной математическое ожидание увеличивается на 2, а стандартное отклонение не изменяется Используя модифицированный критерий Левенэ проверить гипотезу о равенстве дисперсий. Используя инструмент анализа «Однофакторный дисперсионный анализ» проверить гипотезу о равенстве математических ожиданий. При обнаружении значительных различий между математическими ожиданиями необходимо определить, какие именно группы отличаются друг от друга, используя процедуру множественного сравнения Тьюки – Крамера Ход работы: Генерируем 4 нормально распределенные переменные, в соответствии с заданием. Поскольку математические ожидания не известны, необходимо подтвердить гипотезу об их равенстве на основе выборочных данных. Если выполняются следующие условия: наблюдения должны быть случайными, независимы и проводиться в одинаковых условиях. экспериментальные данные должны иметь нормальный закон распределения их дисперсии должны быть одинаковыми; то можно приступать непосредственно к процедуре дисперсионного анализа, т.е. к проверке гипотезы о равенстве средних величин: Н0: m1 = m2=…= mс Используем модифицированный критерий Левенэ для проверки гипотезы о равенстве дисперсий.  Рисунок 16. Четыре нормально распределенные переменные Вычисляем абсолютные величины разностей между наблюдениями и медианами в каждой группе. Далее выполняем однофакторный дисперсионный анализ полученных значений абсолютных разностей.  Рисунок 17. Расчет значений Используем инструмент анализа «Однофакторный дисперсионный анализ» MS Exсel.  Рисунок 18. Дисперсионный анализ Вывод: Поскольку Fрасч = 2,261827429 < Fкрит = 2,62744077, нулевая гипотеза о равенстве дисперсий не отклоняется. Между дисперсиями внутри каждой группы существенной разницы нет, т.е. условие об однородности данных выполняется. 8. ДВУХФАКТОРНЫЙ ДИСПЕРСИОННЫЙЙ АНАЛИЗАналогично задаче однофакторного дисперсионного анализа можно рассмотреть задачу о действии на результативный признак Y двух факторов – A и B. Логика однофакторного и двухфакторного дисперсионного анализа во многом схожа и состоит в следующем. Задание: Сгенерировать 4 нормально распределенные переменные. Первые 3 переменные генерируется в соответствии с Вашим вариантом. При генерации четвертой переменной математическое ожидание увеличивается на 2, а стандартное отклонение не изменяется Проверить гипотезу  Проверить гипотезу  Ход работы: Используем модифицированный критерий Левенэ для проверки гипотезы о равенстве дисперсий.  Рисунок 19. Формирование переменных и групп Используем инструмент анализа «Двухфакторный дисперсионный анализ с повторениями» MS Exсel.  Рисунок 20. Дисперсионный анализ ПРОСТАЯ ЛИНЕЙНАЯ РЕГРЕССИЯУравнение простой линейной регрессии имеет вид yi = b0 + b1xi + i Для выполнения работы проведем эксперимент по методу Монте-Карло. Он состоит из 3 частей. Выбираются истинные значения b0 и b1; В каждом наблюдении выбирается значение xi; Используется генератор случайных чисел для получения значений случайного фактора. ЧАСТЬ ПЕРВАЯ Истинные значения коэффициентов b0 = N и b1 = 0,14N, где N - номер по списку. Случайная компонента ε распределена нормально с нулевым математическим ожиданием и единичной дисперсией. Для вычисления 45 значений ε используйте генератор случайных чисел Excel. В таблице 1 приведены 45 значения xi.  Рисунок 21. Заданные значения Задание: Рассчитайте 45 значений Y, используя имитационную модель Yi = N + (0,14N) xi + εi На основе полученных данных постройте таблицу пар (Y, X). С помощью инструмента анализа Excel «РЕГРЕССИЯ», используя данные таблицы (Y,X) рассчитайте оценки коэффициентов , а также коэффициент корреляции ryx и запишите уравнение регрессии. Сделайте вывод о тесноте связи, используя шкалу Чеддока. Рассчитайте F – статистику Фишера и сделать вывод о статистической значимости коэффициента корреляции. ЧАСТЬ ВТОРАЯ Проделайте то же самое задание, используя имитационную модель вида Yi = N + (0,14N)xi + 2εi Сравните точность полученных оценок Ход работы Сгенерируем 1,…n- независимые одинаково распределенные случайные величины, определяющие действие различных неучтенных факторов на изменение результирующего показателя Y. Рассчитаем Y = 11,5 + (0,14N)x + 2ε после генерации ε.  Рисунок 22. E, X, Y Используя данные таблицы (Y,X) рассчитаем коэффициенты a0 и a1,  Тесноту связи изучаемых явлений оценивает линейный коэффициент парной корреляции ryx. Для линейной регрессии  , ,По шкале Чеддока степень связи очень высокая. Уравнение простой линейной регрессии: Проверка гипотезы о существенности связи результирующей и факторных переменных в уравнения регрессии осуществляется с помощью F-критерия Фишера. Для проверки вычисляется F-статистика: 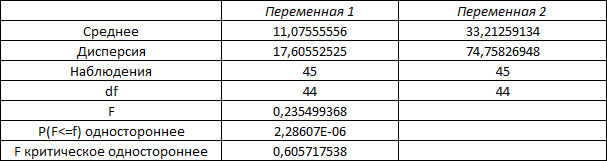 Рисунок 23. Двухвыборочный F-тест для дисперсии Вывод: Fpасч > Fкрит Следует, что полученное значение множественного коэффициента корреляции можно считать статистически значимым. |