купукпукп. Виртуальные топологии
 Скачать 103.86 Kb. Скачать 103.86 Kb.
|

|
МИНОБРНАУКИ РОССИИ САНКТ-ПЕТЕРБУРГСКИЙ ГОСУДАРСТВЕННЫЙ ЭЛЕКТРОТЕХНИЧЕСКИЙ УНИВЕРСИТЕТ «ЛЭТИ» ИМ. В.И. УЛЬЯНОВА (ЛЕНИНА) Кафедра МО ЭВМ ОТЧЕТ по лабораторной работе № 5 по дисциплине «Параллельные алгоритмы» Тема: Виртуальные топологии
Санкт-Петербург 2021 Цель работы.Освоить виртуальные топологии, научиться работать с декартовыми топологиями. Задание. Вариант 7. Количество процессов K равно 8 или 12, в каждом процессе дано вещественное число. Определить для всех процессов декартову топологию в виде трехмерной решетки размера 2 × 2 × K/4 (порядок нумерации процессов оставить прежним). Интерпретируя эту решетку как две матрицы размера 2 × K/4 (в одну матрицу входят процессы с одинаковой первой координатой), расщепить каждую матрицу процессов на K/4 одномерных столбцов. Используя одну коллективную операцию редукции, для каждого столбца процессов найти произведение исходных чисел и вывести найденные произведения в главных процессах каждого столбца. Выполнение работы. Краткое описание выбранного алгоритма решения задачи. Если количество процессов равно 8 или 12, определяется для всех процессов декартова топология в виде трехмерной решетки размера 2 × 2 × K/4. (MPI_Cart_create). Эта решётка интерпретируется как 2 матрицы 2*(k/4). dims[0] = 2; // матрицы dims[1] = 3; // столбцы dims[2] = 2; // строки Матрица расщепляется на k/4 одномерных столбцов ( MPI_Cart_sub). Для каждого столбца процессов выводится произведение исходных чисел и выводятся найденные произведения в главных процессах каждого столбца. 3. Формальное описание алгоритма с использованием аппарата Сетей Петри. 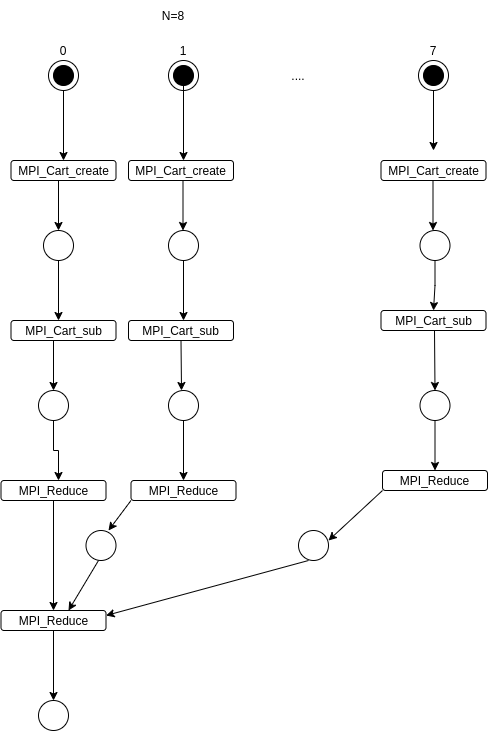 4. Листинг программы. #include #include #include #include #include #define N 2 using namespace std; void freeArrays(const int * dims, const int * dimsFlags, const int * periods){ delete [] dimsFlags; delete [] dims; delete [] periods; } // Вариант 7 int main(int argc, char* argv[]) { int ProcNum, ProcRank; int newRank; const int ndims = 3; int * dims = nullptr; int * dimsFlags = nullptr; int * periods = nullptr; int coords[3]; float num; float mult = 1; MPI_Status Status; MPI_Init(&argc, &argv); MPI_Comm_size(MPI_COMM_WORLD, &ProcNum); MPI_Comm_rank(MPI_COMM_WORLD, &ProcRank); MPI_Comm comm_3D; // для формаирования решёток MPI_Comm comm_2D; // для расщепления MPI_Comm commCol; num = (float)(ProcRank+1); double tStart = MPI_Wtime(); double tEnd = 0; if(ProcNum != 8 & ProcNum != 12){ cout << "Количество процессов не соответствует условиям варианта\n"; MPI_Finalize(); return 0; } dims = new int[ndims]; periods = new int[ndims]; dimsFlags = new int [ndims]; if(ProcNum == 8){ dims[0] = 2; dims[1] = 2; dims[2] = 2; dimsFlags[0] = 1; dimsFlags[1] = 1; dimsFlags[2] = 0; } else if(ProcNum == 12){ dims[0] = 2; dims[1] = 3; dims[2] = 2; dimsFlags[0] = 1; dimsFlags[1] = 1; dimsFlags[2] = 0; } periods[0] = 0; periods[1] = 0; periods[2] = 0; MPI_Cart_create(MPI_COMM_WORLD, ndims, dims, periods, 0, &comm_3D); MPI_Cart_coords(comm_3D, ProcRank, ndims, coords); MPI_Cart_sub(comm_3D, dimsFlags, &comm_2D); MPI_Cart_rank(comm_2D, coords, &newRank); cout << "Proc: " << ProcRank << "(" << coords[0] << "," << coords[1] << "," << coords[2] << ");" << "NewColRank:"<< newRank <<", number = " << num << endl; MPI_Reduce(&num, &mult, 1,MPI_FLOAT,MPI_PROD, 0, comm_2D); if(newRank == 0){ cout << "Главный столбец столбца: Произведение исходных чисел = " << mult; } MPI_Comm_free(&comm_2D); MPI_Comm_free(&comm_3D); tEnd = MPI_Wtime(); printf("Time of performing program: %g; ProcRank: %d\n\n", tEnd - tStart, ProcRank); freeArrays(dims, dimsFlags, periods); MPI_Finalize(); return 0; } 5. Результаты работы программы на 1,2 …. N процессорах. Рис. 1. N = 8. 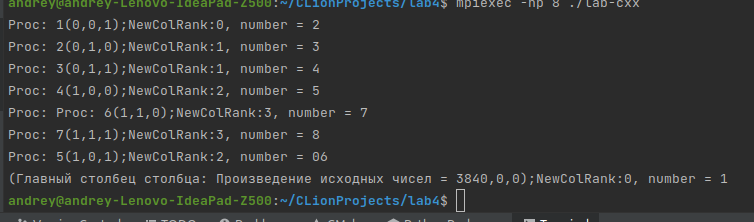 Рис. 2. N = 12. 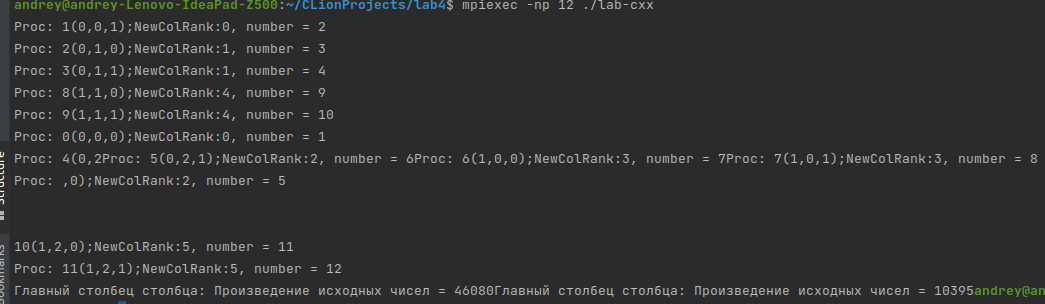 6. График зависимости времени выполнения программы от числа процессов. 7. График ускорения. 6-7 пункты опущены, так как программа запускается только при n =8 и n = 12. n = 8. Время выполнения: 0.000562429 мс. n = 12. Время выполнения: 0.121399 мс. Выводы. Освоил виртуальные топологии, научился работать с декартовыми топологиями. Написана программа, выполняющая поставленную задачу. Ключевым в формировании топологии и её подмножеств является согласованность размерности и массива флагов (флагов того, включать ли данное измерение в данное подмножество топологии). |