|
|
курсовая. 1. Анализ предметной области
ВВЕДЕНИЕ
Использование электронно-вычислительных машин для переработки информации явилось коренным этапом в совершенствовании систем планирования и управления на всех уровнях народного хозяйства. Однако при этом, в отличие от обычных способов сбора и обработки информации, возникли проблемы преобразования информации в символы, понятные для машины. Неотъемлемым элементом этого процесса является кодирование информации.
1. Анализ предметной области
Паскаль - именно тот язык программирования, с которого многие начинали свой тернистый путь. Он относительно легок в изучении, прост в понимании и был одним из первых языков программирования со строгой типизацией и наличием средств процедурного программирования. Моё мнение - Pascal дисциплинирует программиста и приучает его мыслить логически.
Арифметическое кодирование
Обеспечивает почти оптимальную степень сжатия с точки зрения энтропийной оценки кодирования Шеннона. На каждый символ требуется почти H бит, где H — информационная энтропия источника.
В отличие от алгоритма Хаффмана, метод арифметического кодирования показывает высокую эффективность для дробных неравномерных интервалов распределения вероятностей кодируемых символов. Однако в случае равновероятного распределения символов, например для строки бит 010101...0101 длины s метод арифметического кодирования приближается к префиксному коду Хаффмана и даже может занимать на один бит больше.
Принцип действия
Пусть у нас есть некий алфавит, а также данные о частотности использования символов (опционально). Тогда рассмотрим на координатной прямой отрезок от 0 до 1.
Назовём этот отрезок рабочим. Расположим на нём точки таким образом, что длины образованных отрезков будут равны частоте использования символа и каждый такой отрезок будет соответствовать одному символу.
Теперь возьмём символ из потока и найдём для него отрезок, среди только что сформированных, теперь отрезок для этого символа стал рабочим. Разобьём его таким же образом, как разбили отрезок от 0 до 1. Выполним эту операцию для некоторого числа последовательных символов. Затем выберем любое число из рабочего отрезка. Биты этого числа вместе с длиной его битовой записи и есть результат арифметического кодирования использованных символов потока.
Пример работы метода арифметического кодирования
Используя метод арифметического кодирования можно достичь почти оптимального представления для заданного набора символов и их вероятностей (согласно теории энтропийного кодирования источника Шеннона оптимальное представление будет стремится к числу −log2P бит на каждый символ, вероятность которого P). Алгоритмы сжатия данных, использующие в своей работе метод арифметического кодирования перед непосредственным кодированием формируют модель входных данных на основании количественных или статистических характеристик, а также, найденных в кодируемой последовательности повторений или паттернов - любой дополнительной информации позволяющей уточнить вероятность появления символа P в процессе кодирования. Очевидно, что чем точнее определена или предсказана вероятность символа, тем выше эффективность сжатия.
Рассмотрим простейший случай статической модели для кодирования информации поступающей с системы обработки сигнала. Типы сигналов и соответствующие им вероятности распределены следующим образом:
60% вероятность нейтрального значения сигнала или NEUTRAL
20% вероятность положительного значения сигнала или POSITIVE
10% вероятность отрицательного значения сигнала или NEGATIVE
10% вероятность признака конца кодируемой последовательности или END-OF-DATA.
Появление последнего символа для декодера означает, что вся последовательность была успешно декодирована. (В качестве альтернативного подхода, но необязательно более успешно, можно использовать блочный алгоритм фиксированной длины.)
Следует также отметить, что в качестве алфавита вероятностной модели метода можно рассматривать любой набор символов, исходя из особенностей решаемой задачи. Более эвристические подходы, использующие основную схему метода арифметического кодирования, применяют динамические или адаптивные модели. Идея данных методов заключается в уточнении вероятности кодируемого символа, за счет учёта вероятности предшествующего или будущего контекста (т.е. вероятность появления кодируемого символа после определённого k-го числа символов слева или справа, где k - это порядок контекста).
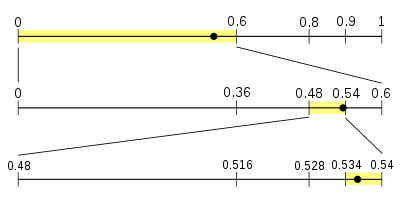
На диаграмме представлено декодирование итогового интервального значения 0.538 согласно модели в приведённом примере. Область интервала разбивается на под интервальные области согласно вероятностным характеристикам появления соответствующих символов. Затем, очередной выбранный интервал разбивается аналогичным способом.
Предположим, что нам необходимо раскодировать сообщение методом арифметического кодирования согласно описанной выше модели. Сообщение в закодированном виде представлено дробным значением 0.538 (для простоты используется десятичное представление дроби, вместо двоичного основания). Предполагается, что закодированное сообщение содержит ровно столько знаков в рассматриваемом числе, сколько необходимо для однозначного восстановления первоначальных данных.
Начальное состояние процесса декодирования совпадает с процессом кодирования и рассматривается интервал [0,1). На основании известной вероятностной модели дробное значение 0.538 попадает в интервал [0, 0.6). Это позволяет определить первый символ, который был выбран кодировщиком, поэтому его значение выводиться как первый символ декодированного сообщения.
Кодирование двоичных файлов
Большинство существующих сетей не позволяет помещать содержимое двоичных файлов непосредственно в тело письма (стандартно гарантируется только передача 7-битного кода). Поэтому, чтобы переслать такой файл (например, полученный в результате архивации и упаковки) по почте, его приходится сначала перекодировать, например, с помощью программы ullencode, а получателю потом раскодировать программой ulldecode. Результат работы программы tmencode, если пытаться просматривать его на экране как обычный текст, имеет определенные текстовые ярлыки в начале (begin X filename) и в конце (end) сообщения. А все то, что расположено между этими ярлыками - невообразимая путаница различных символов. Тем не менее, это текстовый файл: он разбит на строки определенной длины, каждая из которых имеет “конец строки” и может обрабатываться текстовыми редакторами. Операцию преобразования двоичного файла в текстовый принято называть кодированием, а обратную операцию - раскодированием. Кодирование осуществляется таким образом, чтобы полученный файл можно было послать в любую сеть мира. В связи с тем, что ряд зарубежных сетей использует не восьмибитное (байтовое) представление, а семибитное, кодирование осуществляется в семибитное представление. Это, в частности, приводит к тому, что результат (по сравнению с исходным двоичным файлом) имеет несколько больший размер: для uuencode – примернона30%.
Письма, представленные стандартным набором символов без использования кириллицы, автоматически оказываются представленными в семибитной кодировке и, таким образом, их не требуется кодировать. К таким же относятся и письма, представленные в коде Волапюк.
Форматы файлов
GIF
'GIF' (tm) - это стандарт фирмы CompuServe для определения растровых цветных изображений. Этот формат позволяет высвечивать на различном оборудовании графические высококачественные изображения с большим разрешением и подразумевает механизм обмена и высвечивания изображений. Описанный в настоящем документе формат изображений был разработан для поддержки настоящей и будущей технологии обработки изображений и будет в дальнейшем служить основой для будущих графических продуктов CompuServe.
JPG
В алгоритме JPEG исходное изображение представляется двумерной матрицей размера N*N, элементами которой являются цвет или яркость пикселя. Упаковка значений матрицы выполняется за три этапа.
TIFF
Просмотр TIFF изображений. Исходный текст на паскале.
Создание Export плагина для 3D Studio MAX
Все, наверняка, учились геймдевелоперскому делу, пробуя писать, пусть небольшую, но собственную игру. В процессе разработки оттачивали полученные в процессе чтения книг и статей навыки. Начинают обычно с достаточно простых вещей: система частиц, менеджер ресурсов, подсистема ввода, вывод текста. Но, в конце-концов, наступал момент, когда на экране хотелось видеть что-то более красивое, чем затекстурированный кубик вращающийся в центре. :) Каждый выходил из положения по-своему. Кто-то качал из Интернета готовый лоадер популярного формата 3D файлов, кто-то писал сам, а самые настойчивые, рвущиеся к знаниям и большему опыту геймдевелоперы, решали создать собственный экспортер из одного из распространенных 3D редакторов. Естественно (никто и не утверждает обратного), тем, кто только начинает, за достаточно сложное дело написания экспортера, браться не стоит. А вот для тех, кто уже уверен в своих силах, и готов попробовать их на новом поприще, данная статья может стать хорошей базой для воплощения своих задумок в жизнь. Как можно понять из заголовка, я выбрал в качестве «подопытного» 3D Studio MAX.
Описание формата CHR-шpифтов
Описание формата CHR-шpифтов от Turbo Pascal. Письмо из конференции NICE.SOURCES.
FLI, FLC, CEL
Анимационные файлы FLI, FLC и CEL используются Autodesk Animator Pro. Они позволяют проигрывать на экране компьютера подобие кинофильмов. В них не содержится звука и обеспечивается передача всего 256 цветов. Но их простота и быстрота проигрывания сделали данный формат популярным среди разработчиков игр и художников-аниматоров. Файлы FLI использовались первоначально в Animator. Файлы FLC затем стали использоваться в Animator Pro.
PCX
Формат файла изображения (.PCX) Декодирование файлов в формате .PCX Описание информации о палитре Примеры программ на C Формат файла изображений (.PCX) Информация данного раздела будет полезна для вас, если вы хотите написать программу для чтения или записи PCX файлов. Если вы хотите написать программу для изображений строго определенного формата, вы должны быть в состоянии...
Формат 3DS-файла
Основная идея вот: файл 3DS состоит из блоков (chunks), каждый из которых содержит какие-то полезные данные и, возможно, подблоки. Большинство блоков содержит либо данные, либо под блоки, хотя есть и смешанные блоки. Общий формат каждого блока такой...
Формат JPEG
Алгоритм JPEG В алгоритме JPEG исходное изображение представляется двумерной матрицей размера N*N, элементами которой являются цвет или яркость пикселя. Упаковка значений матрицы выполняется за три этапа. Дискретное косинус преобразование Этап Квантования Этап Вторичного Сжатия Высокая эффективность сжатия, которую дает этот алгоритм, основана на том факте, что в матрице частотных...
Кодирование информации
Код — это набор условных обозначений (или сигналов) для записи (или передачи) некоторых заранее определенных понятий.
Кодирование информации – это процесс формирования определенного представления информации. В более узком смысле под термином «кодирование» часто понимают переход от одной формы представления информации к другой, более удобной для хранения, передачи или обработки.
Обычно каждый образ при кодировании (иногда говорят — шифровке) представлении отдельным знаком.
Знак - это элемент конечного множества отличных друг от друга элементов.
В более узком смысле под термином "кодирование" часто понимают переход от одной формы представления информации к другой, более удобной для хранения, передачи или обработки.
Компьютер может обрабатывать только информацию, представленную в числовой форме. Вся другая информация (например, звуки, изображения, показания приборов и т. д.) для обработки на компьютере должна быть преобразована в числовую форму. Например, чтобы перевести в числовую форму музыкальный звук, можно через небольшие промежутки времени измерять интенсивность звука на определенных частотах, представляя результаты каждого измерения в числовой форме. С помощью программ для компьютера можно выполнить преобразования полученной информации, например "наложить" друг на друга звуки от разных источников.
Аналогичным образом на компьютере можно обрабатывать текстовую информацию. При вводе в компьютер каждая буква кодируется определенным числом, а при выводе на внешние устройства (экран или печать) для восприятия человеком по этим числам строятся изображения букв. Соответствие между набором букв и числами называется кодировкой символов.
Как правило, все числа в компьютере представляются с помощью нулей и единиц (а не десяти цифр, как это привычно для людей). Иными словами, компьютеры обычно работают в двоичной системе счисления, поскольку при этом устройства для их обработки получаются значительно более простыми. Ввод чисел в компьютер и вывод их для чтения человеком может осуществляться в привычной десятичной форме, а все необходимые преобразования выполняют программы, работающие на компьютере.
Способы кодирования информации.
Одна и та же информация может быть представлена (закодирована) в нескольких формах. C появлением компьютеров возникла необходимость кодирования всех видов информации, с которыми имеет дело и отдельный человек, и человечество в целом. Но решать задачу кодирования информации человечество начало задолго до появления компьютеров. Грандиозные достижения человечества - письменность и арифметика - есть не что иное, как система кодирования речи и числовой информации. Информация никогда не появляется в чистом виде, она всегда как-то представлена, как-то закодирована.
Двоичное кодирование – один из распространенных способов представления информации. В вычислительных машинах, в роботах и станках с числовым программным управлением, как правило, вся информация, с которой имеет дело устройство, кодируется в виде слов двоичного алфавита.
Кодирование символьной (текстовой) информации.
Основная операция, производимая над отдельными символами текста - сравнение символов.
При сравнении символов наиболее важными аспектами являются уникальность кода для каждого символа и длина этого кода, а сам выбор принципа кодирования практически не имеет значения.
Для кодирования текстов используются различные таблицы перекодировки. Важно, чтобы при кодировании и декодировании одного и того же текста использовалась одна и та же таблица.
Таблица перекодировки - таблица, содержащая упорядоченный некоторым образом перечень кодируемых символов, в соответствии с которой происходит преобразование символа в его двоичный код и обратно.
Наиболее популярные таблицы перекодировки: ДКОИ-8, ASCII, CP1251, Unicode.
Исторически сложилось, что в качестве длины кода для кодирования символов было выбрано 8 бит или 1 байт. Поэтому чаще всего одному символу текста, хранимому в компьютере, соответствует один байт памяти.
Различных комбинаций из 0 и 1 при длине кода 8 бит может быть 28 = 256, поэтому с помощью одной таблицы перекодировки можно закодировать не более 256 символов. При длине кода в 2 байта (16 бит) можно закодировать 65536 символов.
Кодирование числовой информации.
Сходство в кодировании числовой и текстовой информации состоит в следующем: чтобы можно было сравнивать данные этого типа, у разных чисел (как и у разных символов) должен быть различный код. Основное отличие числовых данных от символьных заключается в том, что над числами кроме операции сравнения производятся разнообразные математические операции: сложение, умножение, извлечение корня, вычисление логарифма и пр. Правила выполнения этих операций в математике подробно разработаны для чисел, представленных в позиционной системе счисления.
Основной системой счисления для представления чисел в компьютере является двоичная позиционная система счисления.
Кодирование текстовой информации
В настоящее время, большая часть пользователей, при помощи компьютера обрабатывает текстовую информацию, которая состоит из символов: букв, цифр, знаков препинания и др. Подсчитаем, сколько всего символов и какое количество бит нам нужно.
10 цифр, 12 знаков препинания, 15 знаков арифметических действий, буквы русского и латинского алфавита, ВСЕГО: 155 символов, что соответствует 8 бит информации.
Единицы измерения информации.
1 байт = 8 бит
1 Кбайт = 1024 байтам
1 Мбайт = 1024 Кбайтам
1 Гбайт = 1024 Мбайтам
1 Тбайт = 1024 Гбайтам
Суть кодирования заключается в том, что каждому символу ставят в соответствие двоичный код от 00000000 до 11111111 или соответствующий ему десятичный код от 0 до 255.
Необходимо помнить, что в настоящее время для кодировки русских букв используют пять различных кодовых таблиц (КОИ - 8, СР1251, СР866, Мас, ISO), причем тексты, закодированные при помощи одной таблицы не будут правильно отображаться в другой
Основным отображением кодирования символов является код ASCII - American Standard Code for Information Interchange- американский стандартный код обмена информацией, который представляет из себя таблицу 16 на 16, где символы закодированы в шестнадцатеричной системе счисления.
Кодирование графической информации.
Важным этапом кодирования графического изображения является разбиение его на дискретные элементы (дискретизация).
Основными способами представления графики для ее хранения и обработки с помощью компьютера являются растровые и векторные изображения
Векторное изображение представляет собой графический объект, состоящий из элементарных геометрических фигур (чаще всего отрезков и дуг). Положение этих элементарных отрезков определяется координатами точек и величиной радиуса. Для каждой линии указывается двоичные коды типа линии (сплошная, пунктирная, штрихпунктирная), толщины и цвета.
Растровое изображение представляет собой совокупность точек (пикселей), полученных в результате дискретизации изображения в соответствии с матричным принципом.
Матричный принцип кодирования графических изображений заключается в том, что изображение разбивается на заданное количество строк и столбцов. Затем каждый элемент полученной сетки кодируется по выбранному правилу.
Pixel (picture element - элемент рисунка) - минимальная единица изображения, цвет и яркость которой можно задать независимо от остального изображения.
В соответствии с матричным принципом строятся изображения, выводимые на принтер, отображаемые на экране дисплея, получаемые с помощью сканера.
Качество изображения будет тем выше, чем "плотнее" расположены пиксели, то есть чем больше разрешающая способность устройства, и чем точнее закодирован цвет каждого из них.
Для черно-белого изображения код цвета каждого пикселя задается одним битом.
Если рисунок цветной, то для каждой точки задается двоичный код ее цвета.
Поскольку и цвета кодируются в двоичном коде, то если, например, вы хотите использовать 16-цветный рисунок, то для кодирования каждого пикселя вам потребуется 4 бита (16=24), а если есть возможность использовать 16 бит (2 байта) для кодирования цвета одного пикселя, то вы можете передать тогда 216 = 65536 различных цветов. Использование трех байтов (24 битов) для кодирования цвета одной точки позволяет отразить 16777216 (или около 17 миллионов) различных оттенков цвета - так называемый режим “истинного цвета” (True Color). Заметим, что это используемые в настоящее время, но далеко не предельные возможности современных компьютеров.
Кодирование звуковой информации.
Из курса физики вам известно, что звук - это колебания воздуха. По своей природе звук является непрерывным сигналом. Если преобразовать звук в электрический сигнал (например, с помощью микрофона), мы увидим плавно изменяющееся с течением времени напряжение.
Для компьютерной обработки аналоговый сигнал нужно каким-то образом преобразовать в последовательность двоичных чисел, а для этого его необходимо дискретизировать и оцифровать.
Можно поступить следующим образом: измерять амплитуду сигнала через равные промежутки времени и записывать полученные числовые значения в память компьютера.
АБСТРАКТНЫЙ АЛФАВИТ
Информация передается в виде сообщений. Дискретная информация записывается с помощью некоторого конечного набора знаков, которые будем называть буквами, не вкладывая в это слово привычного ограниченного значения (типа «русские буквы» или «латинские буквы»). Буква в данном расширенном понимании - любой из знаков, которые некоторым соглашением установлены для общения. Например, при привычной передаче сообщений на русском языке такими знаками будут русские буквы - прописные и строчные, знаки препинания, пробел; если в тексте есть числа - то и цифры. Вообще, буквой будем называть элемент некоторого конечного множества (набора) отличных друг от друга знаков. Множество знаков, в котором определен их порядок, назовем алфавитом (общеизвестен порядок знаков в русском алфавите: А, Б,..., Я).
Алфавит клавиатурных символов ПЭВМ IBM (русифицированная клавиатура):

Алфавит шестнадцатеричных цифр:
0123456789ABCDEF
Этот пример, в частности, показывает, что знаки одного алфавита могут образовываться из знаков других алфавитов.
Алфавит двоичных цифр:
0 1
Алфавит двоичных цифр является одним из примеров, так называемых, «двоичных» алфавитов, т.е. алфавитов, состоящих из двух знаков. Другими примерами являются двоичные алфавиты 8 и 9:
Алфавит языка блок-схем изображения алгоритмов:

1.1 Постановка задачи
В канале связи сообщение, составленное из символов (букв) одного алфавита, может преобразовываться в сообщение из символов (букв) другого алфавита. Правило, описывающее однозначное соответствие букв алфавитов при таком преобразовании, называют кодом. Саму процедуру преобразования сообщения называют перекодировкой. Подобное преобразование сообщения может осуществляться в момент поступления сообщения от источника в канал связи (кодирование) и в момент приема сообщения получателем (декодирование). Устройства, обеспечивающие кодирование и декодирование, будем называть соответственно кодировщиком и декодировщиком.
На рис. 1.5 приведена схема, иллюстрирующая процесс передачи сообщения в случае перекодировки, а также воздействия помех (см. следующий пункт).
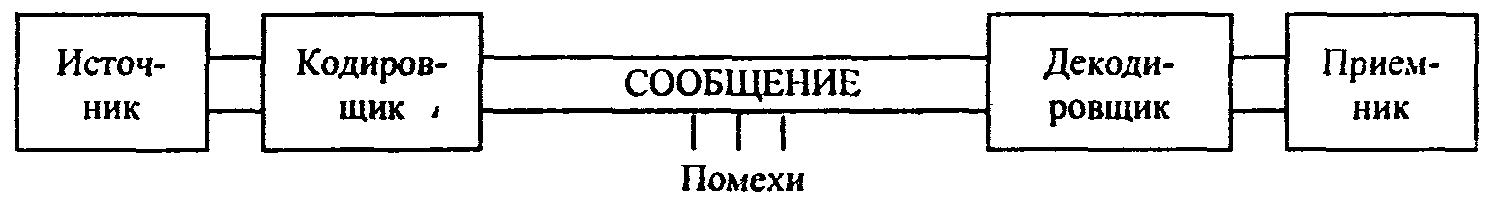
Рис. 1.5. Процесс передачи сообщения от источника к приемнику
Код Трисиме (знакам латинского алфавита ставятся в соответствие комбинации из трех знаков: 1,2,3):
Код Трисиме является примером, так называемого, равномерного кода (такого, в котором все кодовые комбинации содержат одинаковое число знаков - в данном случае три). Пример неравномерного кода - азбука Морзе.
МЕЖДУНАРОДНЫЕ СИСТЕМЫ БАЙТОВОГО КОДИРОВАНИЯ
Информатика и ее приложения интернациональны. Это связано как с объективными потребностями человечества в единых правилах и законах хранения, передачи и обработки информации, так и с тем, что в этой сфере деятельности (особенно в ее прикладной части) заметен приоритет одной страны, которая благодаря этому получает возможность «диктовать моду».
Компьютер считают универсальным преобразователем информации. Тексты на естественных языках и числа, математические и специальные символы - одним словом все, что в быту или в профессиональной деятельности может быть необходимо человеку, должно иметь возможность быть введенным в компьютер.
В силу безусловного приоритета двоичной системы счисления при внутреннем представлении информации в компьютере кодирование «внешних» символов основывается на сопоставлении каждому из них определенной группы двоичных знаков. При этом из технических соображений и из соображений удобства кодирования-декодирования следует пользоваться равномерными кодами, т.е. двоичными группами равной длины.
Попробуем подсчитать наиболее короткую длину такой комбинации с точки зрения человека, заинтересованного в использовании лишь одного естественного алфавита - скажем, английского: 26 букв следует умножить на 2 (прописные и строчные) - итого 52; 10 цифр, будем считать, 10 знаков препинания; 10 разделительных знаков (три вида скобок, пробел и др.), знаки привычных математических действий, несколько специальных символов (типа #, $, & и др.) — итого 100. Точный подсчет здесь не нужен, поскольку нам предстоит решить простейшую задачу: имея, скажем, равномерный код из групп по N двоичных знаков, сколько можно образовать разных кодовых комбинаций. Ответ очевиден К = 2N. Итак, при N = 6 К = 64 - явно мало, при N = 7 К = 128 - вполне достаточно.
Однако, для кодирования нескольких (хотя бы двух) естественных алфавитов (плюс все отмеченные выше знаки) и этого недостаточно. Минимально достаточное значение N в этом случае 8; имея 256 комбинаций двоичных символов, вполне можно решить указанную задачу. Поскольку 8 двоичных символов составляют 1 байт, то говорят о системах «байтового» кодирования.
Наиболее распространены две такие системы: EBCDIC (Extended Binary Coded Decimal Interchange Code) и ASCII (American Standard Information Interchange).
Первая - исторически тяготеет к «большим» машинам, вторая чаще используется на мини- и микро-ЭВМ (включая персональные компьютеры). Ознакомимся подробнее именно с ASCII, созданной в 1963 г.
В своей первоначальной версии это - система семибитного кодирования. Она ограничивалась одним естественным алфавитом (английским), цифрами и набором различных символов, включая «символы пишущей машинки» (привычные знаки препинания, знаки математических действий и др.) и «управляющие символы». Примеры последних легко найти на клавиатуре компьютера: для микро-ЭВМ, например, DEL - знак удаления символа.
В следующей версии фирма IBM перешла на расширенную 8-битную кодировку. В ней первые 128 символов совпадают с исходными и имеют коды со старшим битом равным нулю, а остальные коды отданы под буквы некоторых европейских языков, в основе которых лежит латиница, греческие буквы, математические символы (скажем, знак квадратного корня) и символы псевдографики. С помощью последних можно создавать таблицы, несложные схемы и др.
Для представления букв русского языка (кириллицы) в рамках ASCII было предложено несколько версий. Первоначально был разработан ГОСТ под названием КОИ-7, оказавшийся по ряду причин крайне неудачным; ныне он практически не используется.
В табл. 1.9 приведена часто используемая в нашей стране модифицированная альтернативная кодировка. В левую часть входят исходные коды ASCII; в правую часть (расширение ASCII) вставлены буквы кириллицы взамен букв, немецкого, французского алфавитов (не совпадающих по написанию с английскими), греческих букв, некоторых спецсимволов.
Знакам алфавита ПЭВМ ставятся в соответствие шестнадцатеричные числа по правилу: первая - номер столбца, вторая - номер строки. Например: английская 'А' - код 41, русская 'и' - код А8.
Таблица кодов ASCII (расширенная)

Одним из достоинств этой системы кодировки русских букв является их естественное упорядочение, т.е. номера букв следуют друг за другом в том же порядке, в каком сами буквы стоят в русском алфавите. Это очень существенно при решении ряда задач обработки текстов, когда требуется выполнить или использовать лексикографическое упорядочение слов.
Из сказанного выше следует, что даже 8-битная кодировка недостаточна для кодирования всех символов, которые хотелось бы иметь в расширенном алфавите. Все препятствия могут быть сняты при переходе на 16-битную кодировку Unicode, допускающую 65536 кодовых комбинаций.
Понятие кодирования и декодирования.
Использование электронно-вычислительных машин для переработки информации явилось коренным этапом в совершенствовании систем планирования и управления на всех уровнях народного хозяйства. Однако при этом, в отличие от обычных способов сбора и обработки информации, возникли проблемы преобразования информации в символы, понятные для машины. Неотъемлемым элементом этого процесса является кодирование информации.
Кодом принято называть совокупность символов, соответствующих элементам информации или ее характеристикам. Сам процесс составления кода в виде совокупности символов или списка сокращений для соответствующих элементов и характеристик называется кодированием. В литературе термин код иногда заменяется идентичным ему термином шифр
Цель кодирования состоит в том, чтобы представить информацию в более компактной и удобной форме для оперирования при передаче и обработке информации ; приспособить кодированную информацию к обработке на вычислительных устройствах ; обеспечить использование некоторого определенного метода поиска , сортировки и упорядочения информации.
Принципиальная схема обработки информации состоит из поиска, сортировки и упорядочения , в которой кодирование является частью операции ввода данных в виде входных кодов. В результате обработки информации получаются выходные коды, которые после их декодирования выдаются как результат проведенной обработке.
Декодирование является операцией , обратной кодированию. Если при кодировании происходит преобразование информации в сигналы в виде определенного сочетания символов , соответствующих данному объекту или его характеристике , то при декодировании , наоборот , по заданному коду определяется соответствующий объект или его признаки. Например, в телефонном справочнике указан код , т.е. номер телефона , связанный с некоторым элементом (лицом или учреждением ). Операция декодирования состоит из набора кода номера телефона , который в виде сигналов поступает в АТС, где декодируется с помощью электрической схемы.
Процесс кодирования.
Процесс кодирования информации может производиться либо ручным , либо автоматическим способом. При ручном , неавтоматическом способе кодирования вручную отыскивается нужный код в предварительно составленном каталоге кодов и записывается в документе в виде цифровых или алфавитно-цифровых символов. Затем документ поступает в вычислительный центр , где оператор с помощью клавишного устройства перфорирует записанную информацию на перфокарте или перфоленте. Затем перфокарты или перфоленты вводятся в ЭВМ , информация кодируется в машинный (двоичный) код. Таким образом информация дважды кодируется вручную : при записи ее на документ и при переноски данных на машинные носители.
При автоматическом способе кодирования человек производит запись на естественном языке в виде слов, цифр и общепринятых обозначений в документе , который читается специальным автоматом. Этот автомат предварительно кодирует документ и записывает все данные на магнитную ленту в двойном коде. Лента затем вводится в ЭВМ, где информация с помощью “машинного словаря “ снова кодируется в более короткий машинный код, удобный для ее поиска, сортировки и обработки.
Ввод информации в ЭВМ в виде буквенно-цифрового текста на естественном языке и кодировании в машине требует хранения в памяти ЭВМ словаря, в котором каждому слову соответствует определенный код. По этому словарю машина сама кодирует текст. При этом отпадает необходимость в классификации и кодировании информации по ее смысловому содержанию, так как котируются сами слова, выражающие определенные характеристики предметов.
Большое разнообразие технических характеристик и других данных, относящихся к производству и потреблению многочисленных видов продукции, не позволяет включить все необходимые данные для их производства в код продукции, так как этот код содержал бы большое число символов.
Поэтому задача кодирования продукции заключается в том, чтобы иметь возможно более короткий код, по которому в памяти машины можно было бы найти подробную информацию о всех необходимых данных, относящихся к каждому изделию. Таким кодом является ключевой код. Для каждого ключевого кода в памяти ЭВМ должен храниться массив данных, которые извлекаются из памяти и используются для решения различных задач. Этот массив информации должен быть единым для всех решаемых задач, например каталогом продукции, где в одном месте хранятся все необходимые данные о каждом предмете. Разделение его на ряд отдельных массивов, записанных, например, на различных участках магнитной ленты, нецелесообразно, так как это привело бы к повторению одной и той же информации и увеличению объема хранимой информации.
Основное требование к ключевому коду - однозначный поиск ЭВМ признаков, относящихся к данному предмету, для которого ключевой код является адресом.
Ключевой код может быть просто порядковым регистрационным номером и не нести какой-либо конкретной информации о продукции или, наоборот, может быть построен по определенной системе классификации и содержать конкретную информацию об основных признаках продукции, вполне ее определяющих.
Второй способ кодирования более эффективен, так как регистрационный код не дает возможности осуществить предварительную сортировку информации по ее содержанию.
Ключевой код позволяет производить сортировку карточек продукции по главным определяющим признакам. Детальная спецификация и ее остальные характеристики находятся в предварительно отсортированных карточках.
Виды кодов.
Код, символы которого соответствуют определенным предметам или характеристикам, называется прямым кодом. Если код непосредственно не содержит информацию о предмете или его признаках, а представляет адрес, указывающий местоположение информации, где содержится необходимые сведения, то он называется адресным кодом. Адресный код применяется для сокращения кода и быстрого поиска больших массивов информации.
За единицу количества информации принимается 1 бит, т.е. один двоичный разряд (0 или 1). Буквы, десятичные цифры и другие символы внутри ЭВМ представляются в виде групп двоичных разрядов. Операция представления их в таком виде называется двоичным кодированием. Группа из n двоичных чисел позволяет закодировать 2n различных символов. Такая группа называется байтом.
Более крупной единицей информацией является машинное слово, представляющее собой последовательность символов , занимающих одну ячейку в памяти машины. В зависимости от ЭВМ машинного слова может колебаться в пределах— от 16 до 64 двоичных разрядов. машинное слово может быть командой , числом или буквенно-цифровой последовательностью. Обычно машинное слово используется как единое целое в ЭВМ, хотя на некоторых машинах допускается обработка частей машинного слова.
Массив информации, содержащий 1024 машинных слова, называется страницей. Каждый отдельный блок памяти содержит обычно 16 и более страниц. Местоположение (адрес) слова в памяти определяется кодом адреса, содержащим номер блока, страницы и номера слова в этой странице.
Для упорядочения информации о множестве объектов, а также для облегчения их поиска и сортировки по заданным признакам или характеристикам применяется классификация этого множества. Классификация—это условное разбиение множества на ряд классов , подклассов и других группировок по принятой системе счисления и по заданным признакам и характеристикам. Классификационный код—это такой код , в котором отдельными символами или группой символов представлен каждый из классифицируемых признаков или каждая конкретная характеристика предмета.
Структура и число символов классификационного кода целиком определяется принятой классификацией множества, которая, в свою очередь, зависит от поставленных целей и задач. В классификационном коде каждый символ заключает в себе определенную информацию о конкретном признаке или характеристике предмета. В отличии от этого порядковый ,или регистрационный код , содержащий присвоенный данному предмету порядковый номер при его регистрации без учета его признаков и характеристик, может служить только адресом для поиска местоположения информации о данном предмете. Во многих случаях применяются смешанные коды, в которых имеется как классификационная часть, так и порядковые номера для списка классифицируемых предметов множества.
Обмен информацией.
Передатчик и приемник.
Источник (передатчик) и получатель (приемник) служат для обмена некоторой
информацией. В одном случае отправителем и получателем информации служит
человек, в другом случае это может быть компьютер (так называемая телеметрия).
При передаче сообщения, сигнал поступает на кодирующее устройство (кодер), в
котором происходит преобразование последовательности элементов сообщения в
некоторую последовательность кодовых символов. Далее закодированный сигнал
проходит через модулятор, в котором первичный (НЧ) сигнал преобразуется во
вторичный (ВЧ) сигнал, пригодный для передачи по каналу связи на большие
расстояния. Линия связи – это среда, используемая для передачи модулированного
сигнала от передатчика к приемнику. Такой средой служат: провод, волновод,
эфир).
Для компьютерной обработки аналоговый сигнал нужно каким-то образом преобразовать в последовательность двоичных чисел, а для этого его необходимо дискретизировать и оцифровать.
1.2 Описание решения
Поскольку и цвета кодируются в двоичном коде, то если, например, вы хотите использовать 16-цветный рисунок, то для кодирования каждого пикселя вам потребуется 4 бита (16=24), а если есть возможность использовать 16 бит (2 байта) для кодирования цвета одного пикселя, то вы можете передать тогда 216 = 65536 различных цветов. Использование трех байтов (24 битов) для кодирования цвета одной точки позволяет отразить 16777216 (или около 17 миллионов) различных оттенков цвета - так называемый режим “истинного цвета” (True Color). Заметим, что это используемые в настоящее время, но далеко не предельные возможности современных компьютеров.
Начальное состояние процесса декодирования совпадает с процессом кодирования и рассматривается интервал [0,1). На основании известной вероятностной модели дробное значение 0.538 попадает в интервал [0, 0.6). Это позволяет определить первый символ, который был выбран кодировщиком, поэтому его значение выводиться как первый символ декодированного сообщения.
1.3 Минимальные требования к программного обеспечения
Для выполнения программы достаточно вычислительной установки типа PC с процессором i386 и выше и 8 Мбайт оперативной памяти, оснащенной любой из следующих операционных систем: MS DOS (начиная с версии 5.0), Windows 95, Windows NT версий 4.0.
2. Листинг программы
function GronsfeldEncipher(toCode, K: string): string;
var i, T, _T: integer;
begin
for i := 1 to length(toCode) do begin
_T := ord(toCode[ i ]);
T := (Ord(toCode[ i ])
+
(Ord(K[(pred(i) mod length(K)) + 1]) - Ord('0')));
if T >= 256 then dec(T, 256);
toCode[ i ] := Chr(T);
end;
GronsfeldEncipher := toCode;
end;
function GronsfeldDecipher(toDecode, K: string): string;
var i, T: integer;
begin
for i := 1 to length(toDecode) do begin
T := (Ord(toDecode[i])
-
(Ord(K[(pred(i) mod length(K)) + 1]) - Ord('0')));
if T < 0 then Inc(T, 256);
toDecode[ i ] := Chr(T);
end;
GronsfeldDecipher := toDecode;
end;
var
s: string;
f_in, f_out: text;
begin
if (paramcount < 3) or ((paramstr(1) <> '/e') and (paramstr(1) <> '/d')) then exit;
assign(f_in, paramstr(2));
reset(f_in);
assign(f_out, paramstr(3));
rewrite(f_out);
while not eof(f_in) do begin
readln(f_in, s);
if paramstr(1) = '/e' then
s := GronsfeldEncipher(s, '2178')
else
s := GronsfeldDecipher(s, '2178');
writeln(f_out, s);
end;
close(f_out);
close(f_in);
end.
program Coding_and_decoding_of_the_text_information_by_method_Gronsfelds;
uses crt,dos;
{Procedures and function}
function getnum(c: char): integer;
var
n: integer;
{Show title}
procedure title;
begin
window(1,1,1,80);
textbackground(2);
clrscr;
gotoxy(27,1);
textbackground(5);
textcolor(133); write('CODETIMEG');
end;
{Main change}
const
N1 = 5; { The maximum quantity of lines in a file }
N2 = 3; { Quantity of alphabets }
var
f,f1: text;
s,ne,s1: string;
i,j,k,l,m: integer;
ce: integer; { The counter of a position in a line of a code }
w : array [1..N1] of string; { Lines }
w1 : array [1..N1] of string; { Lines }
abc : array [1..N2] of string; { Alphabets }
sign : string;
label menugame,coding,decoding,help;
{Main part}
begin
clrscr;
{Menu programm}
menugame:
while 1>0 do
begin
title;
gotoxy(30,18);
textcolor(1);
write('Press C for coding');
gotoxy(30,20);
textcolor(1);
write('Press D for decoding');
gotoxy(30,22);
textcolor(1);
write('Press H for help');
gotoxy(30,24);
textcolor(1);
write('Press E for exit');
case readkey of
#99 : goto coding;
#100 : goto decoding;
#104 : goto help;
#101 : exit;
end;
end;
{Coding}
coding:
begin
case c of
'0': n := 0;
'1': n := 1;
'2': n := 2;
'3': n := 3;
'4': n := 4;
'5': n := 5;
'6': n := 6;
'7': n := 7;
'8': n := 8;
'9': n := 9;
else
n := -1;
end;
getnum := n;
end;
begin
abc[1] := 'ABCDEFGHIJKLMNOPQRSTUVWXYZ';
abc[2] := 'abcdefghijklmnopqrstuvwxyz';
abc[3] := '0123456789';
writeln(' *** An encryption method Gronsfeld ***');
write('Enter a full way to a file from which it is readable: '); readln(s);
write('Enter a full way to a file in which we write: '); readln(s1);
write('Enter a digital key (4 figures or less): '); readln(n);
assign(f,s); assign(f1,s1);
reset(f); rewrite(f1);
i := 1;
{ Reads a file }
while not EOF(f) and (i<=N1) do begin
readln(f,w[i]); w1[i]:=w[i];
inc(i);
end;
{ We code }
{ 1-st cycle - in the lines from a file }
{ 2-nd cycle - on elements in line from a file }
{ 3-rd cycle - under alphabets }
{ 4-th cycle - on elements of the alphabet }
ce := 1;
for i := 1 to N1 do if ord(w[i][0])<>0 then
for j := 1 to (ord(w[i][0])+1) do
for k := 1 to N2 do
for l := 1 to (ord(abc[k][0])+1) do begin
if abc[k][l]=w[i][j] then begin
m := l+getnum(ne[ce]); inc(ce); if ce>ord(ne[0]) then ce := 1;
if m>ord(abc[k][0]) then m := m-ord(abc[k][0]);
w1[i][j] := abc[k][m];
end;
end;
for i:=1 to N1 do begin
writeln(w[i]);
writeln(w1[i]);
end;
for i := 1 to N1 do begin
for j := 1 to ord(w1[i][0]) do write(f1,w1[i][j]);
writeln(f1,s1,'');
end;
begin
title;
gotoxy(30,18);
textcolor(1);
write('Press C for coding');
gotoxy(30,20);
textcolor(1);
write('Press D for decoding');
gotoxy(30,22);
textcolor(1);
write('Press H for help');
gotoxy(30,24);
textcolor(1);
write('Press E for exit');
case readkey of
#99 : goto coding;
#100 : goto decoding;
#104 : goto help;
#101 : exit;
end;
end;
read(s);
end;
{Decoding}
decoding:
begin
case c of
'0': n := 0;
'1': n := 1;
'2': n := 2;
'3': n := 3;
'4': n := 4;
'5': n := 5;
'6': n := 6;
'7': n := 7;
'8': n := 8;
'9': n := 9;
else
n := -1;
end;
getnum := n;
end;
begin
abc[1] := 'ABCDEFGHIJKLMNOPQRSTUVWXYZ';
abc[2] := 'abcdefghijklmnopqrstuvwxyz';
abc[3] := '0123456789';
writeln(' *** An encryption method Gronsfeld ***');
write('Enter a full way to a file from which it is readable: '); readln(s);
write('Enter a full way to a file in which we write: '); readln(s1);
write('Enter a digital key (4 figures or less): '); readln(n);
assign(f,s); assign(f1,s1);
reset(f); rewrite(f1);
i := 1;
{ Reads a file }
while not EOF(f) and (i<=N1) do begin
readln(f,w[i]); w1[i]:=w[i];
inc(i);
end;
{ We code }
{ 1-st cycle - in the lines from a file }
{ 2-nd cycle - on elements in line from a file }
{ 3-rd cycle - under alphabets }
{ 4-th cycle - on elements of the alphabet }
ce := 1;
for i := 1 to N1 do if ord(w[i][0])<>0 then
for j := 1 to (ord(w[i][0])+1) do
for k := 1 to N2 do
for l := 1 to (ord(abc[k][0])+1) do begin
if abc[k][l]=w[i][j] then begin
m := l-getnum(ne[ce]); inc(ce); if ce>ord(ne[0]) then ce := 1;
if m<1 then m := m+ord(abc[k][0]);
w1[i][j] := abc[k][m];
end;
end;
for i:=1 to N1 do begin
writeln(w[i]);
writeln(w1[i]);
end;
for i := 1 to N1 do begin
for j := 1 to ord(w[i][0]) do write(f1,w1[i][j]);
writeln(f1,s1,'');
end;
begin
gotoxy(30,18);
textcolor(1);
write('Press C for coding');
gotoxy(30,20);
textcolor(1);
write('Press D for decoding');
gotoxy(30,22);
textcolor(1);
write('Press H for help');
gotoxy(30,24);
textcolor(1);
write('Press E for exit');
case readkey of
#99 : goto coding;
#100 : goto decoding;
#104 : goto help;
#101 : exit;
end;
end;
read(s);
end;
{Help}
help:
begin
write('This is help');
end;
begin
gotoxy(30,18);
textcolor(1);
write('Press C for coding');
gotoxy(30,20);
textcolor(1);
write('Press D for decoding');
gotoxy(30,22);
textcolor(1);
write('Press H for help');
gotoxy(30,24);
textcolor(1);
write('Press E for exit');
case readkey of
#99 : goto coding;
#100 : goto decoding;
#104 : goto help;
#101 : exit;
end;
end.
ЗАКЛЮЧЕНИЕ
Использование электронно-вычислительных машин для переработки информации явилось коренным этапом в совершенствовании систем планирования и управления на всех уровнях народного хозяйства. Однако при этом, в отличие от обычных способов сбора и обработки информации, возникли проблемы преобразования информации в символы, понятные для машины. Неотъемлемым элементом этого процесса является кодирование информации.
СПИСОК ИСПОЛЬЗОВАННОЙ ЛИТЕРАТУРЫ
1.Учебное пособие по Turbo Pascal 7.0;
2.Владимир Попов. Паскаль и Дельфи. Самоучитель. – Питер, 2003 г., 544 с.;
3.Потопахин В.В. Turbo Pascal: решение сложных задач.
4.Шпак Ю.А. Turbo Pascal 7.0 на примерах. – Издательство "Юниор", 2003,498 с.;
5.Фаронов В.В. Turbo Pascal Наиболее полное руководство в подлиннике.
6.Авен О. Н. Оценка и выбор вычислительного оборудования для асу.
7. Delphi 6. Программирование на Компонент Pascal.. Под ред. Б, Б. Тимофеева. Киев.
8. Отраслью приборостроения, «АСУ-Прибор». Каталог. М., ЦНИИ ТЭИ Минприбор
|
|
|
 Скачать 213.5 Kb.
Скачать 213.5 Kb.