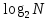курсовая ПЛИС. курсовая богов (автовосстановление). 1 тематический обзор
 Скачать 0.92 Mb. Скачать 0.92 Mb.
|

 ВВЕДЕНИЕ Первой предпосылкой к появлению программируемых логических интегральных схем стало появление первых постоянных запоминающих устройств в 70-х годах прошлого столетия.После этого в истории микроэлектроники осуществляется планомерное развитие устройств с программируемой логикой как вычислительных устройств, применимых для решения обширного круга задач цифровой обработки информации. Наиболее яркий след в развитии цифровых вычислительных устройств оказало появление первых микропроцессоров. Данное событие открыло двери широкому применению цифровых технологий обработки информации. Однако микропроцессоры не всегда актуальны при решении задач в цифровой схемотехнике: принцип работы микропроцессора основан на микропрограмме и представляет собой последовательность шагов конечной длительности, в то время как для многих задач требуются устройства, у которых задержка при выполнении логических функций будет минимальной. Наиболее удобным способом решения данных задач и являются логические программируемые интегральные схемы (ПЛИС). Программируемая логическая интегральная схема — электронный компонент, предназначенный для создания цифровых интегральных схем. Принципиальное отличие ПЛИС от обычных цифровых микросхем, заключается в том, что логика работы ПЛИС, задаётся посредством программирования, а не определяется при изготовлении. На данный момент лидерами в сфере программируемых логических интегральных схем являются три фирмы: Xilinx, Inc, компания Actel Corporation и фирма Altera Corporation. На долю этих трех гигантов приходится львиная доля рынка ПЛИС. 1 ТЕМАТИЧЕСКИЙ ОБЗОР Программируемые логические интегральные схемы При программировании на ПЛИС можно задавать разную структуру цифрового устройства. Цифровое устройство можно задать в виде программы на специальных языках описания аппаратуры или в качестве принципиальной электрической схемы. В качестве языков описания аппаратуры используются например: Verilog, VHDL, AHDL. Программируемые логические интегральные схемы — являются одним из наиболее перспективных и динамично развивающихся сегментов цифровой схемотехники. ПЛИС является кристаллом, с расположенными на нем простыми логическими элементами, не соединенными между собой. Соединение данных логических элементов, то есть формирование электрической схемы, происходит благодаря электронным ключам, которые расположены в этом же кристалле. Управление электронными ключами происходит посредством специальной памяти. Принцип работы специальной памяти заключается в помещении кода конфигурации цифровой схемы в её ячейки, и записав данные коды в память ПЛИС можно собрать цифровое устройство различной степени сложности и с необходимыми параметрами, а также с разным количеством элементов на кристалле. Одним из отличий ПЛИС от микропроцессоров заключается в том, что алгоритмы цифровой обработки можно организовать на аппаратном уровне. В данном случае быстродействие цифровой обработки увеличиться. Разберем классификацию ПЛИС по структуре. Основным критерием данной классификации является наличие логических матриц, а также их вид и способ коммутации. Согласно данной классификации выделяют следующие классы ПЛИС: – Программируемые логические матрицы — самый ранний тип ПЛИС, появившийся в 70-е года прошлого века, в котором и матрицы «И», и матрицы «ИЛИ» являются программируемыми. – Программируемая матричная логика — это тип ПЛИС, имеющих программируемую матрицу «И» и фиксированную матрицу «ИЛИ». – Программируемая макрологика — это ПЛИС, в которых есть одна программируемая матрица «И-НЕ» или «ИЛИ-НЕ», при этом способные формировать сложные логические функции благодаря инверсным обратным связям. – Программируемые коммутируемые матричные блоки — ПЛИС, которые содержат, объединенные коммутационной матрицей, матричные логические блоки, обычно в количестве 4–8 штук. – Программируемые вентильные матрицы — состоят из логических блоков, включающие в свой состав несколько более простых логических элементов, на базе таблицы перекодировки, программируемого мультиплексора, D-триггера, цепи управления. А также коммутирующих путей — программируемых матриц соединений. Программируемые логические интегральные схемы являются более совершенными нежели обычные цифровые микросхемы и микропроцессоры, и поэтому обладает целым рядом преимуществ, такими как: минимальное время разработки схемы, так как требуется всего лишь занести в память ПЛИС конфигурационный код, возможность быстрого изменения в цифровой схеме, отсутствие потребности в разработке и изготовлении сложных печатных плат, а также в сложном технологическом производстве и оборудовании. ПЛИС конфигурируется с помощью обычного персонального компьютера. В качестве недостатка ПЛИС можно указать лишь их более высокую стоимость по сравнению с аналогами, такими как микропроцессоры и обычные цифровые микросхемы. Основной сферой применения ПЛИС является создание цифровых устройств с различными возможностями и степенями сложности, например: устройств, требующих высокую скорость передачи данных, а также сложных устройств, требующих большое количество портов ввода-вывода. Устройств для выполнения цифровой обработки сигналов. Различных видов цифровой видеоаппаратуры и аудиоаппаратуры. Устройств, предназначенных для системы защиты информации, и для проектирования интегральных схем специального назначения. Коммутирующих устройств, задачей которых является обеспечения взаимодействия между системами с различной логикой и напряжением питания. Устройств, нашедших применение при обработке радиолокационной информации и моделировании квантовых вычислений. Также при помощи ПЛИС могут реализовываться нейрочипы. В данное время программируемые логические интегральные схемы охватывают множество областей, в которых находят широкое применение. Одной из таких областей является цифровая обработка сигналов. ПЛИС помогают разработчикам создавать цифровую электронную аппаратуру, принцип работы которых основан на реализации алгоритмов цифровой обработки сигналов. 2 РАЗРАБОТКА СТРУКТУРЫ МИКРОПРОЦЕССОРНОЙ СИСТЕМЫ Проектирование микропроцессорной системы включает в себя четыре этапа. Первый этап. Системный – производится описание функций, выполняемых будущей микропроцессорной системой, составляется спецификация на систему (определяется структура, номенклатура и особенности построения программных и микропрограммных средств). Второй этап. Производится разработка структуры микропроцессорной системы, выбор микропроцессорных наборов на базе которых будет реализовываться микропроцессорная система, определяются связи между программным и аппаратным обеспечением. Третий этап. Разработка и изготовление опытного образца, разработка соответствующего программного обеспечения, разработка системы ввода/вывода. Разработка программ состоит из: разработки алгоритмов вычислений, написания текста исходных программ, трансляции исходных программ в исходный код, автономной отладки программного обеспечения. Четвертый этап. Комплексная отладка программного и аппаратного обеспечения микропроцессорной системы. Процесс отладки представляет собой процесс обнаружения ошибок и определения источника их появления по результатам тестирования. Для проведения отладки проектируемая микропроцессорная система должна обладать свойствами управляемости, наблюдаемости и предсказуемости. 2.1 Разработка общей структуры вычислительного устройства При построении вычислительного устройства, как правило, используется модульный принцип организации, при этом в минимальный состав должны входить: операционный автомат; устройство управления; память; устройство ввода/вывода информации. Для организации связи между модулями вычислительного устройства используется магистральный способ, который обеспечивает минимальный набор связей между модулями и, как следствие, высокое быстродействие системы. На рисунке 1 представим обобщенную структурную схему вычислительного устройства между узлами которой связи осуществляются по системной магистрали. 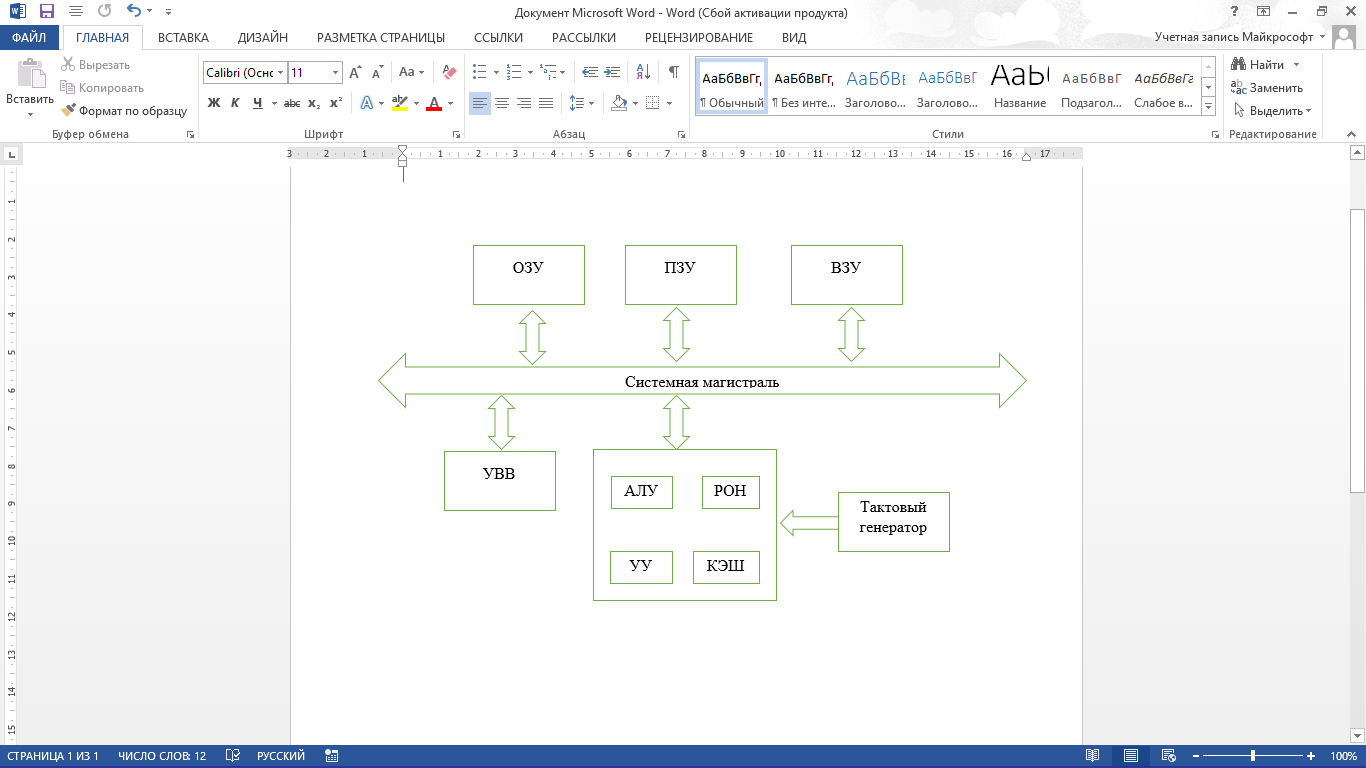 Рисунок 1 – Обобщенная структурная схема ЭВМ с шиной организации На данной схеме использованы следующие сокращения: ОЗУ – оперативное запоминающее устройство; ПЗУ – постоянное запоминающее устройство; ВЗУ – внешнее запоминающее устройство; УВВ – устройство ввода-вывода; АЛУ – арифметико-логическое устройство; РОН – регистры общего назначения; УУ – управляющее устройство; КЭШ – промежуточный буфер с быстрым доступом к содержащейся в нем информации. Системная магистраль микропроцессорной системы представляет собой совокупность стандартного набора сигналов, проводов по которым они передаются и правил обмена между устройствами подключенных к магистрали. На физическом уровне системная магистраль состоит из трех шин: шины данных, шины адреса и шины управления. Шина данных (ШД) используется для передачи информационных кодов между всеми устройствами микропроцессорной системы. Число проводников, составляющих шину данных называют ее разрядностью.2 Шина адреса (ША) используется для передачи адресов ячеек памяти и портов ввода-вывода с которыми процессор обменивается информацией в данный момент. Шина управления (ШУ) состоит из отдельных проводов по каждому из которых передаются отдельные управляющие сигналы. Производительность цифрового устройства определяется разрядностью шины данных, а объем адресного пространства – разрядностью шины адреса. Рассчитаем разрядность шины адреса используя формулу:
где N – емкость ОЗУ в битах. Вычислим: N = 128 Кбайт = 1048576 бит, m = 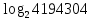 = 20 бит = 20 битБазовым элементом любого вычислительного устройства является программно-управляемый модуль. Структурную схему которого представим на рисунке 2. 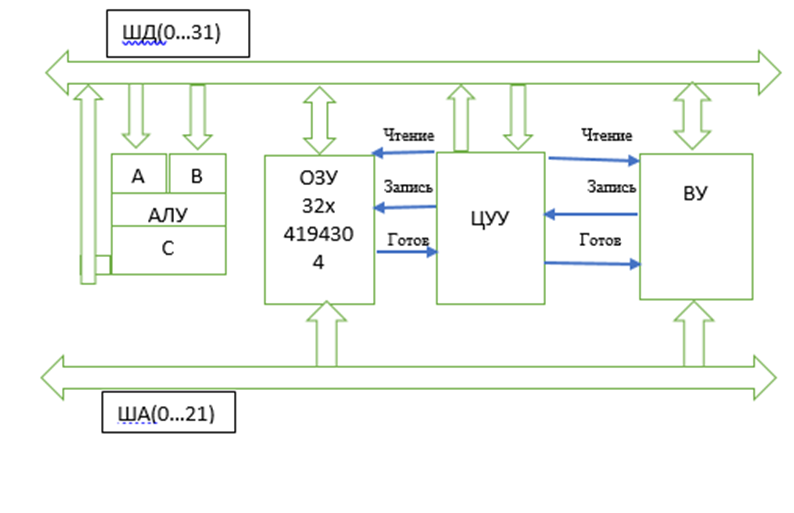 Рисунок 2 – Структурная схема программно-управляемого модуля 2.2 Разработка арифметико-логического устройства Все основные операции по преобразованию данных производятся в операционных блоках, составляющих арифметико-логическое устройство (АЛУ). В зависимости от выполняемых функций АЛУ можно разделить на две части: устройство управления, которое задает последовательность микрокоманд; операционное устройство, в котором реализуется заданная последовательность микрокоманд. АЛУ представляет собой функционально и логически законченный блок процессора, который под управлением устройства управления и синхроимпульса (УУ и С) служит для выполнения арифметических и логических преобразований над данными, называемых операндами. В любом АЛУ предусмотрена возможность выполнения четырех основных арифметических операций, нескольких логических операций, а также сдвигов. В составе АЛУ можно выделить четыре основные группы узлов. Первая группа - узлы хранения: регистры, обеспечивающие хранение операндов, промежуточных и окончательных данных; триггеры, позволяющие хранить различные признаки результатов. Вторая группа – узлы передач: мультиплексоры, обеспечивающие выполнение передач по выбранному маршруту; шины соединяющие отдельные блоки АЛУ; блоки вентилей, обеспечивающие передачу информации в определенный момент времени. Третья группа – узлы преобразования: сумматоры, выполняющие различные микрооперации; схемы выполнения логических операций; схемы сдвига; счетчики, используемые для вспомогательных преобразований. Четвертая группа – узлы управления: дешифраторы управляющих сигналов; блок управления АЛУ; схемы формирований логических условий. Структуру простейшего типового АЛУ представим на рисунке 3. 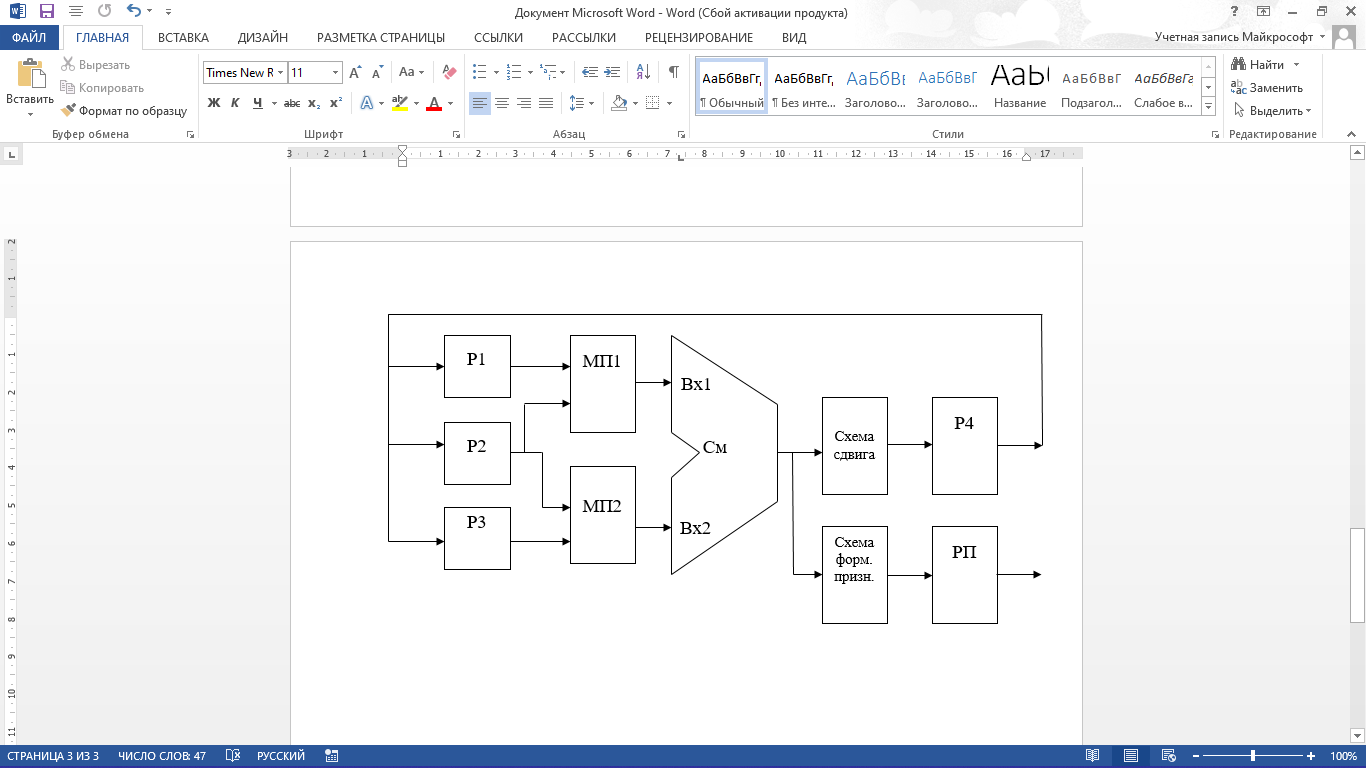 Рисунок 3 – Схема простейшего АЛУ На данной схеме используются следующие обозначения: Р1, Р2, Р3, Р4 – регистры; МП1, МП2 – мультиплексоры; См – сумматор; РП – регистр признака. Обрабатываемая в АЛУ информация представляет собой численные или логические величины. Это проявляется в используемых формах представления данных, системах счисления, разрядности, применяемых кодах. На рисунке 4 представим схему классификации АЛУ. 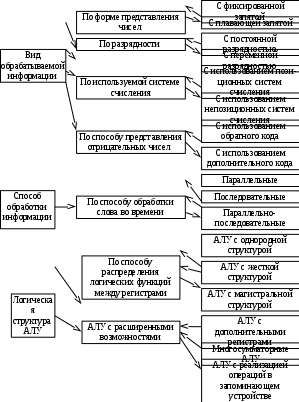 Рисунок 4 – Классификация АЛУ 2.3 Разработка алгоритмов арифметических и логических операций 2.3.1 Алгоритм операции сложения/вычитания При сложении двух чисел, представленных в прямом и обратном коде, соблюдаются правила двоичной арифметики. Единица переноса, возникающая в старшем знаковом разряде суммы, отбрасывается, если число представляется в формате с фиксированной запятой. При вычитании возникает необходимость занимать единицу из старшего разряда. Операции сложения/вычитания выполняются за один такт операционного автомата. Рассмотрим операцию сложения/вычитания на примере чисел А = 6 (0110) и В =2 (0010) Для формата RR: в регистр АХ пометим число 0111, в регистр ВХ – 0010, а результат вычисления поместив в регистр СХ. Для формата SS: в регистр АХ пометим число 0111, в регистр ВХ – 0010, а результат вычисления поместив в регистр СХ. Произведем вычисления суммы и разности: С = А + В = 0110 + 0010 = 1000 С = А - В = 0111 - 0010 =0100 Реализуем инструкции сложения и вычитания на ассемблере, используя регистры общего назначения. Операция сложения для формата RR: mov AX, 0110; помещаем в регистр АХ значение 0110 mov BX, 0010; помещаем в регистр BX значение 0010 ADD AX, BX; складываем значение регистров mov CX, AX; в регистр СХ помещаем содержимое регистра АХ Операция вычитания для формата RR: mov AX, 0110; помещаем в регистр АХ значение 0110 mov BX, 0010; помещаем в регистр BX значение 0010 SUB AX, BX; вычитание значение регистров mov CX,AX; в регистр СХ помещаем содержимое регистра АХ Операция сложения для формата SS: mov AX, 0110; помещаем в регистр АХ значение 0110 mov BX, 0010; помещаем в регистр BX значение 0010 ADD AX, BX; складываем значение регистров mov CX, AX; в регистр СХ помещаем содержимое регистра АХ Операция вычитания для формата SS: mov AX, 0110; помещаем в регистр АХ значение 0110 mov BX, 0010; помещаем в регистр BX значение 0010 SUB AX, BX; вычитание значение регистров mov CX, AX; в регистр СХ помещаем содержимое регистра АХ 2.3.2 Алгоритм операции произведения Операция произведения выполняется за несколько тактов операционного автомата. Умножение вычисления как сумма частичных произведений, каждая из которых получается последовательными сдвигами и умножением множимого на соответствующий разряд множителя. Рассмотрим выполнение алгоритма умножения двоичных чисел в прямом коде, начиная с младших разрядов со сдвигом частичного произведения. А = 0111, Апр = 0,0110 В = 0010, Впр = 0,0010 Sign[A] = 0; Sign[B] = 0 C1 = Апр * B1 * 2-1 = 0,0111*0*2-1 = 0,0110*0*0,1 = 0 C2 = Апр * B2 * 2-2 = 0,0111*1*2-2 = 0,0110*1*0,01 =110 C3 = Апр * B3 * 2-3 = 0,0111*0*2-3 = 0,0110*0*0,001 = 0 C4 = Апр * B4 * 2-4 = 0,0111*0*2-4 = 0,0110*0*0,0001 = 0 С = С1+С2+С3+С4 = 0+0,000110+0+0 = 0,00001110 Проверка 0,0110 0,0010 00000 00111 0,00001100 Операция умножения в ассемблере выполняется с помощью инструкции MUL, которая может работать только с регистрами общего назначения или памятью и не может работать непосредственно с числами. Данная инструкция имеет одинаковый синтаксис для всех форматов: mov AX, 0110; помещаем в регистр АХ значение 0110 mov BX, 0010; помещаем в регистр BX значение 0010 MUL AX, BX; перемножаем содержимое регистров АХ и ВХ, результат помещаем в АХ. Если в результате вычисления получается число более 8 бит, то для хранения результата вычисления будет использоваться пара регистров DX и AX. 2.3.3 Алгоритм операции деления Операция деления выполняется за несколько тактов операционного автомата. Для операндов с фиксированной запятой она осуществляется путем последовательного вычисления кода делителя из кода делимого и определения знака остатка. Реализовать операцию деления можно двумя способами: ˗ деление с неподвижным делимым и сдвигаемым вправо делителем; ˗ деление с неподвижным делителем и сдвигаемым влево делимым. Произведем операцию деления с неподвижным делителем и сдвигаемым влево делимым без восстановления остатка. Для реализации данной операции для чисел А и В запишем прямой код, а для делителя В запишем еще дополнительный код. А=0110 Апр=0,0110 В=0010 Впр=0,0010 Вдоп.=1,1101+0,0001=1,1110 Частное 0,0110 1,1101 1 0,0011 0,1010  1,1101 11 1,1101 110,0011 0,0110 1,1101 111 0,0011 0,0110 1,1101 1110 0,0011 0,0110 0,0010 11100 1,1000 За четыре сдвига мы получаем целую часть частного 10111 и положительный остаток 0,0001. Деление ассемблере выполняется с помощью инструкции DIV, которая реализуется за несколько тактов операционного автомата. Данная команда не работает непосредственно с числами или сегментными регистрами, а только с регистрами общего назначения или областью памяти. Данная инструкция имеет одинаковый синтаксис для всех форматов: mov AX, 0110; помещаем в регистр АХ значение 0110 mov BX, 0010; помещаем в регистр BX значение 0010 DIV AX, BX; выполняется деление чисел А/В, результат операции заносится в регистр АХ. Если при делении получается остаток, то его записывают в регистр АН. 2.3.4 Алгоритм логических операций Логические операции под соответствующими операндами выполняются комбинационными схемами АЛУ. Основными логическими операциями являются: инверсия, конъюнкция, дизъюнкция и эквивалентность. Данные операции перечислены в сложном логическом выражении, для соблюдения которого используют скобки. Логические операции выполняются за 1 такт операционного автомата. Инверсия – битовая операция, при выполнении которой результат отрицания всегда противоположен значению аргумента. Конъюнкция – это функция двух, трех и более переменных и выполняется по правилу: результат равен 1, если все операнды равны 1, во всех остальных случаях результат равен 0. Дизъюнкция – функция двух, трех и более переменных, выполняет логическое сложение и работает по правилу: результат равен 0, если все операнды равны 0, во всех остальных случаях результат будет равен 1. Импликация – функция двух переменных, которые могут принимать значение из множества (0,1), при этом результат так же принадлежит множеству (0,1) и работает по правилу: функция ложная лишь тогда, когда посылка истина, а следствие ложное. Эквивалентность – логическое выражение, которое является истинным тогда, когда оба простых логических выражения имеют одинаковую истинность. Приведем таблицу истинности для перечисленных выше логических операций. На рисунке 5 представим таблицу истинности для инверсии. 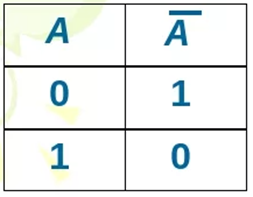 Рисунок 5 – Таблица истинности «Инверсия» На рисунке 6 представим таблицу истинности для конъюнкции. 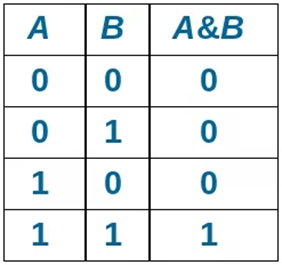 Рисунок 6 – Таблица истинности «Конъюнкция» На рисунке 7 представим таблицу истинности дизъюнкции. 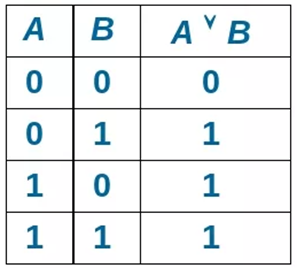 Рисунок 7 – Таблица истинности «Дизъюнкция» На рисунке 8 представим таблицу истинности импликации. 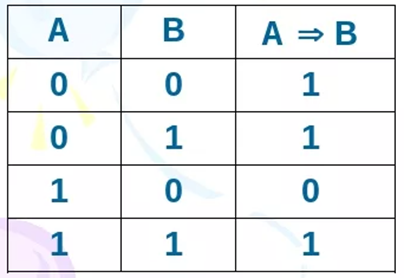 Рисунок 8 – Таблица истинности «Импликация» На рисунке 9 представим таблицу истинности эквивалентности. 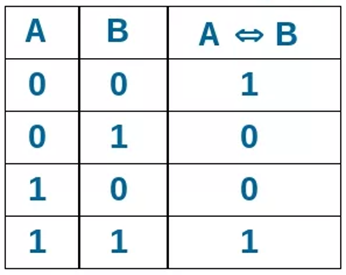 Рисунок 9 – Таблица истинности «Эквивалентность» Условные обозначения элементов, приведенных выше логических операций, представим на рисунке 10. 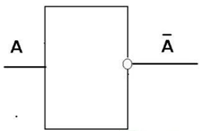 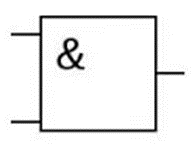 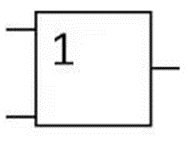 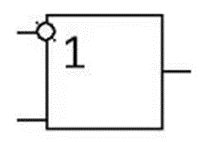 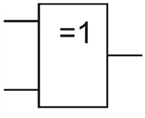 а) б) в) г) д) Рисунок 10 – Логические элементы На рисунке представлены: а) – инверсия; б) – конъюнкция; в) – дизъюнкция; г) – импликация; д) – эквивалентность. 2.3.5 Команды пересылки Команды пересылки предназначены для операций над словами и строками. Основными командами являются команды MOV и MOVS. Команда MOV пересчитывает 1 байт или слово из памяти в регистр, из регистра в память или из регистра в регистр. Она имеет следующий синтаксис: MOV <получатель>,<источник> При использовании данной команды необходимо учитывать следующие правила: ˗ оба операнда должны иметь одинаковую длину; ˗ в качестве одного из операндов обязательно должен использоваться регистр; ˗ нельзя пересылать непосредственно заданное значение в сегментный регистр. Команда MOVS предназначена для работы над строками, которые представляют собой последовательность байт. В данной команде в качестве операнда могут использоваться регистры разной длины, но при этом должно выполняться следующее правило: содержимое исходного операнда копируется в больший по размеру регистр получателя данных. На рисунке 11 представим различные способы, которыми в процессе можно пересылать данные из одного места в другое. 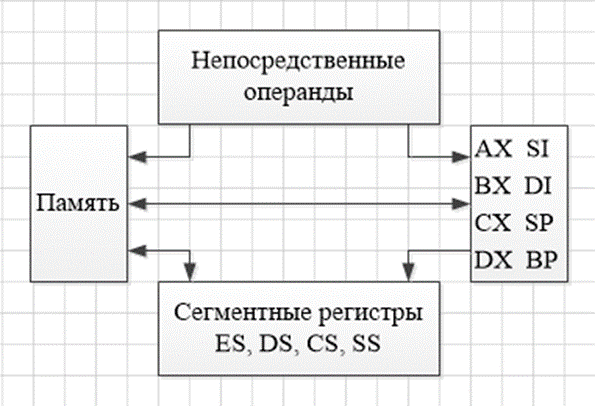 Рисунок 11 – Пути пересылки данных 2.4 Разработка управляющего устройства Для обеспечения работы всех устройств и узлов вычислительной машины в соответствии с заданной программой обеспечивается центральным устройством управления (ЦУУ), которая вырабатывает управляющие сигналы необходимые для выполнения. Основными функциями устройства управления являются: ˗ определение очередности выборки команд из оперативной памяти; ˗ формирование физических адресов операндов; ˗ формирование сигналов для выполнения арифметических, логических и иных операций при выполнении программы; ˗ операция пуска и остановки вычислительного устройства; ˗ обеспечение работы вычислительного устройства в различных режимах. На рисунке 12 представим структурную схему управляющего устройства. 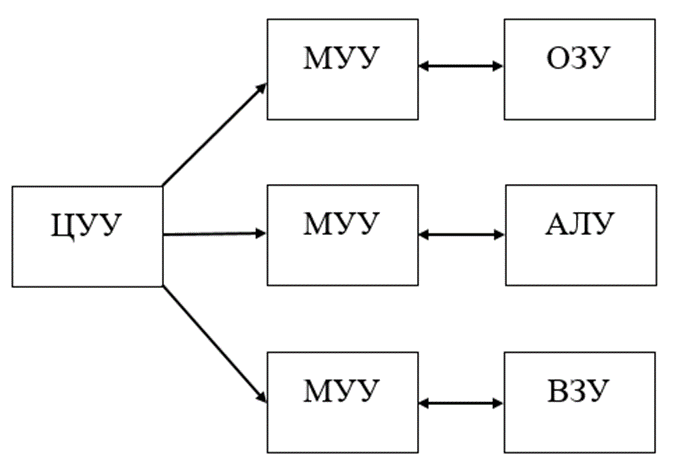 Рисунок 12 – Структурная схема управляющего устройства ЦУУ – центральное устройство управления, которое выполняет основные функции по реализации программ. Эти функции оно выполняет через МУУ – местное устройство управления, находящиеся при каждом из устройств, входящих в состав вычислительной машины. Оно реализует специальные алгоритмы, соответствующие принципам действия разных внешних устройств. Последовательность управляющих сигналов, вырабатываемых устройством управления зависит от числа выполняемых арифметических, логических операций и формата используемых команд. 2.4.1 Разработка формата команд Формат команды – это структура команды с разметкой номеров разрядов, определяющих границы отдельных полей команды. Структура любой команды состоит из нескольких полей, основные из которых представим на рисунке 13.  Рисунок 13 – Структура команды Код операции (КОП) указывает какая именно операция (арифметическая, логическая и т.п.) выполняется. В адресной части команды указываются адреса операндов. В зависимости от структуры адресной части различают следующие типы команд: безадресные; одноадресные двухадресные; трехадресные; четырехадресные. Безадресная структура фиксирует адреса обоих операндов и результата операции, например, при работе со стековой памятью. Одноадресная структура. Подразумеваемые адреса имеют результат операции и один из операндов. При этом один из операндов и результат операции размещаются в одном фиксированном регистре. Выделенный для этой цели внутренний регистр процессора получил название аккумулятор. Адрес другого операнда указывается в команде. Двухадресная структура. Используется в вычислительных машинах, построенных так, что результат операции будет всегда помещаться в фиксированный регистр процессора, например, на место первого операнда. Трехадресная структура. Используется в вычислительных машинах, построенных так, что после выполнения команды по адресу K (команда занимает L ячеек памяти) выполняется команда по адресу K+L. Такой порядок выборки команд называется естественным. Он нарушается только специальными командами передачи управления. При естественном порядке выборки адрес следующей команды формируется в устройстве, называемом счетчик адреса команд. В этом случае команда становится трехадресной. Четырехадресная структура. Содержит наиболее полную информацию о выполняемой операции, включает поле кода операции и четыре адреса для указания ячеек памяти двух операндов, ячейки результата операции, и ячейки, содержащей адрес следующей команды. Такой порядок выборки команд называется принудительным. Он использовался в первых моделях вычислительных машин, имеющих небольшое число команд и очень незначительный объем ОП, поскольку длина такой команды зависит от разрядности адресов операндов и результата. Общую длину команды определим по формуле: где Rк – количество бит, отводимое под команду; RAi – количество разрядов для записи i – того адреса; l – количество адресов в команде; RКОП – разрядность поля кода операции; RCA – разрядность поля способа адресации. Так как система команд разрабатываемого устройства предполагает 22 различных операций, то минимальную разрядность поля кода операции определим по формуле: где int – округление в большую сторону до целого; NКОП – число операций. Вычислим Rкоп =int(log229)= 4 бит Число разрядов, отводимых под поле способа адресации вычислим по формуле: где NCA – число способов адресации. Вычислим Rca = int(log24)= 2 бит В адресной части команды содержится информация об исходных данных, их месте нахождения и месте сохранения результата операции. Обычно место нахождения каждого из операндов и результата задается в команде путем указания адреса соответствующей ячейки основной памяти или номером регистра процессора. Принципы использования информации из адресной части определяет система адресации, которая задает число адресов в команде. Разрядность поля адреса вычислим по формуле: Вычислим: RA =int(log2 20)=5 бит Для указанных в задании форматов команд рассчитаем общую длину команды, учитывая, что число адресов в команде равно: Для формата RR l=2: Rk =2*5+5+1=16 Для формата SS l=4: Rk =4*5+5+1=26 Для рассчитанных форматов составим таблицу команд. Таблица 1 – Таблица команд.
2.4.2 Расчет производительности устройства Оценка производительности вычислительных систем может осуществляться по различным методикам. Одной из таких методик является определение производительности по весу арифметических действий, выполняемых процессором: 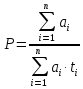 , (6) , (6)где ai – вес арифметического действия; ti – среднее время выполнения арифметического действия. На примере универсального микропроцессорного комплекта, оценим производительность устройства согласно исходным данным приведенным в таблице 2. Таблица 2 – Веса и время выполнения арифметических действий
Р=74+12+40+15+14+13+19+40+20/74*0,379+12*0,420+40*0,372+15*0,356+14*0,356+13*0,374+19*0,368+40*0,503+20*0,4=247/98,264=2,51 2.4.3 Разработка операционного автомата Любая операция в вычислительном устройстве рассматривается, как сложное действие, которое разделяется на последовательность элементарных операций над словами информации. Для хранения слов информации, выполнения набора микроопераций и вычисления значений логических условий используется операционный автомат. Его структура определяется общей длиной команды и форматом выполняемых операций. Управление работой операционного автомата осуществляется с помощью управляющего автомата, который генерирует последовательность управляющих сигналов, т.е. задает порядок действий в операционном автомате. Операционный и управляющий автоматы составляют блок операционного устройства служащий для обработки цифровой информации. На рисунке 14 показано операционное устройство. 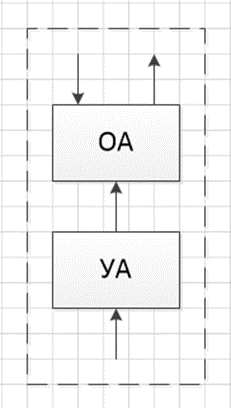 Рисунок 14 – Операционное устройство Основными узлами операционного устройства являются: регистр команд (RK), счетчик команд (PC), регистр адреса (RA), регистр стека (SP), управляющий автомат (YA). 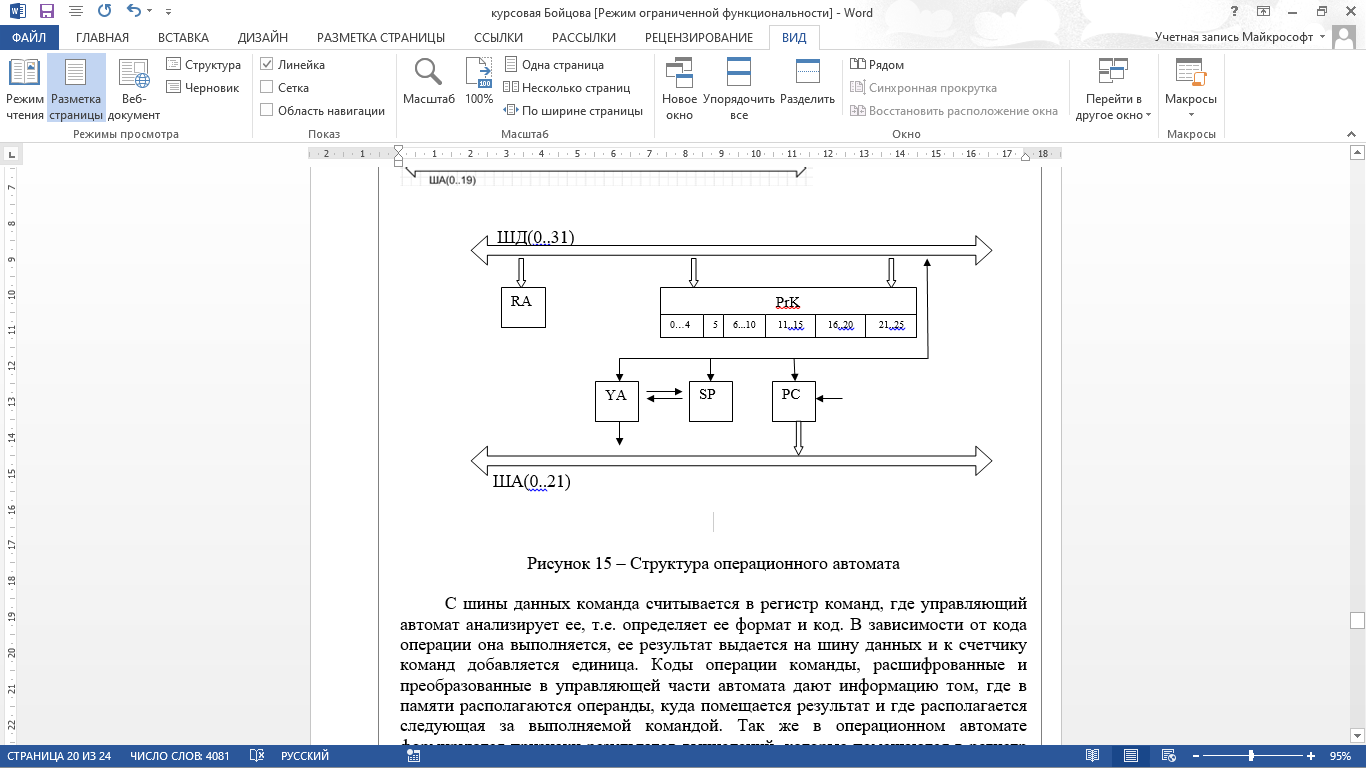 Рисунок 15 – Структура операционного автомата С шины данных команда считывается в регистр команд, где управляющий автомат анализирует ее, т.е. определяет ее формат и код. В зависимости от кода операции она выполняется, ее результат выдается на шину данных и к счетчику команд добавляется единица. Коды операции команды, расшифрованные и преобразованные в управляющей части автомата дают информацию том, где в памяти располагаются операнды, куда помещается результат и где располагается следующая за выполняемой командой. Так же в операционном автомате формируются признаки результатов вычислений, которые помещаются в регистр стека. 2.5 Структура запоминающего устройства Запоминающее устройство вспоминает запись, хранение и считывание произвольной двоичной информации. Оно является основным устройством памяти цифровых систем, в котором хранятся программы, определяющие процесс текущей обработки информации. Связь с запоминающим устройством осуществляется по системной магистрали. По шине данных передается информация, записываемая в память и считываемая из нее. По шине адреса передается адрес, участвующий в обмене элемента памяти. Согласно заданию: емкость 512 – 4194304 бит; разрядность ЗУ – 24 бит; разрядность ША – 20 бит; разрядность ШД – 16 бит. На рисунке 16 представим структурную схему ЗУ. 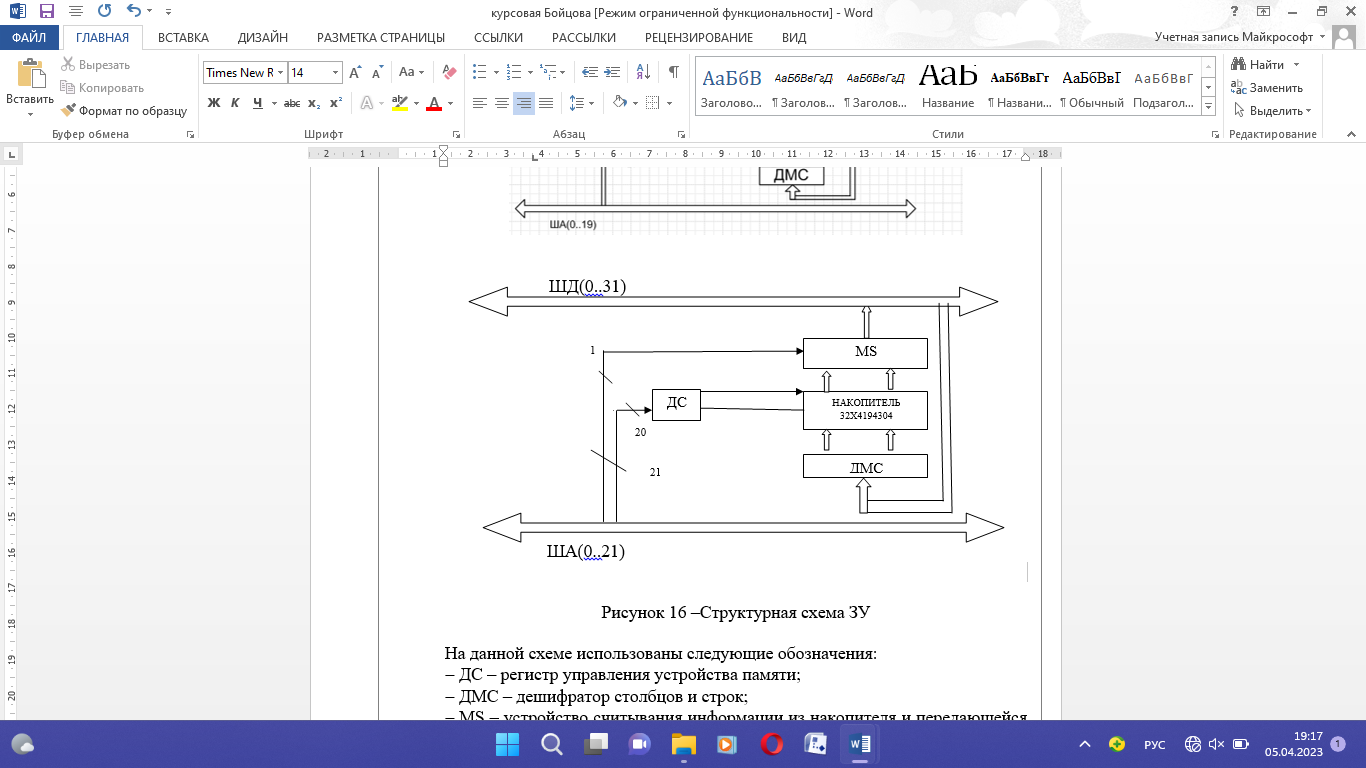 Рисунок 16 –Структурная схема ЗУ На данной схеме использованы следующие обозначения: ДС – регистр управления устройства памяти; ДМС – дешифратор столбцов и строк; MS – устройство считывания информации из накопителя и передающейся на ШД. ЗАКЛЮЧЕНИЕ Благодаря основным признакам проектирования МПС: модульности, микропрограммируемости и магистральности можно разработать вычислительное устройство по отдельным модулям, а затем объединить их в единое целое. Основным узлом таких устройств является центральная вычислительная машина в структуре, которой можно выделить АЛУ, управляющие и операционные автоматы и шины, соединяющие эти узлы между собой. Внедрение микропроцессорных комплектов открыло возможность построения многофункциональных приборов с гибким программным обеспечением, сделало такие приборы более экономичными и облегчило задачи ввода/вывода данных на стандартную интерфейсную шину и управление самим интерфейсом. В данном курсовом проекте были рассмотрены принципы построения основных узлов вычислительного устройства, выполняющего основные арифметические и логические операции, а также команды пересылки данных. При изучении основных принципов разработки вычислительного устройства с указанным набором команд была описана структура устройства, операционный автомат АЛУ, работы управляющего автомата, выполнен алгоритм реализации основных операций, рассмотрена структура запоминающего устройства. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||