Generics и коллекции. 6 блок. Generics. Collections
 Скачать 0.76 Mb. Скачать 0.76 Mb.
|

| Параметризация методов. |
| Параметризированные классы? |
| Обобщенный класс может быть объявлен с любым количеством параметров типа. Java не создает разные версии класса или любого другого параметризованного класса. Имеется только одна версия класса, которая существует в прикладной программе. Параметризованные классы могут быть частью иерархии классов так же, как и любые другие не параметризованные классы. То есть параметризованный класс может выступать в качестве суперкласса или подкласса. Ключевое отличие между параметризованными и не параметризованными иерархиями состоит в том, что в параметризованной иерархии любые аргументы типов, необходимые параметризованному суперклассу, всеми подклассами должны передаваться по иерархии вверх. |
| Параметризированные интерфейсы? |
| Параметризованные интерфейсы специфицируются так же, как и обобщенные классы. |
| Параметризованные методы и конструкторы |
| В методах параметризованного класса можно использовать параметр типа, а следовательно, они становятся параметризованными относительно параметра типа. Можно объявить параметризованный метод, в котором непосредственно используется один или несколько параметров типа. Более того, можно объявить параметризованный метод, входящий в не параметризованный класс. Конструкторы также могут быть обобщенными, даже если их классы таковыми не являются |
| 1. Можно ли параметризировать статические методы? |
| Нельзя создавать обобщенные статические переменные и методы. Но объявить статические обобщенные методы со своими параметрами типа всё же можно: public class GenericWrongStatic public static Т оb; // Неверно, нельзя создать статические переменные типа Т. public static T getOb() { return оb; }// Неверно, ни один статический метод не может использовать Т. public static System.out.println(v); } // Объявить статические обобщенные методы с параметрами типа можно } |
| КОЛЛЕКЦИИ (Java Collection Framework) (Основы) |
| 1. Какие структуры данных вы знаете? |
| 1 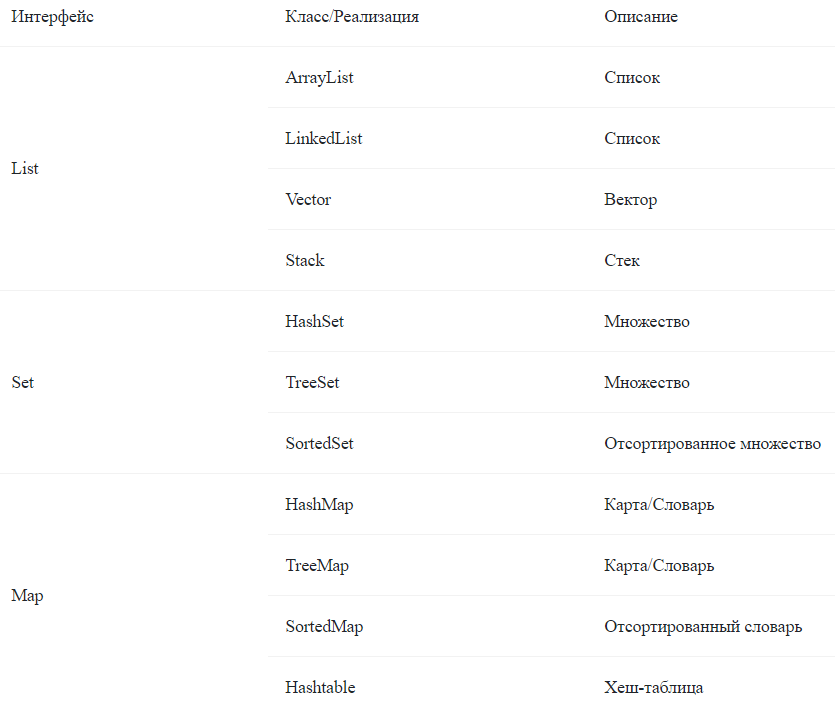 ) Линейные структуры: ) Линейные структуры:(Массивы, Динамические массивы ArrayList, связанные списки LinkedList) 2) Линейные структуры данных с конечными точками: (Стек - структура LIFO, Очередь - структура FIFO, Двухсторонние очереди, Очередь с приоритетом) 3) Деревья и кучи: (Простое дерево, Двоичное дерево, Красно-чёрные деревья, АВЛ-деревья, Куча(не та) - это структура данных) 4) Нелинейные структуры данных: (Словарь данных, упорядоченное и неупорядоченное множества.) Подробнее прочитать можно тут! |
| 2. Что такое коллекция? |
| «Коллекция» — это структура данных, позволяющая хранить набор каких-либо объектов. Объектами в наборе могут быть числа, строки, объекты пользовательских классов и т.п. Коллекция позволяет хранить их в одном массиве и обращаться к ним. Коллекция может автоматически расширяться. |
| 3. Для чего они нужны? |
| Обеспечивают удобство при работе с информацией, удобная запись, сортировка и хранение данных. |
| 4. Иерархия коллекций? |
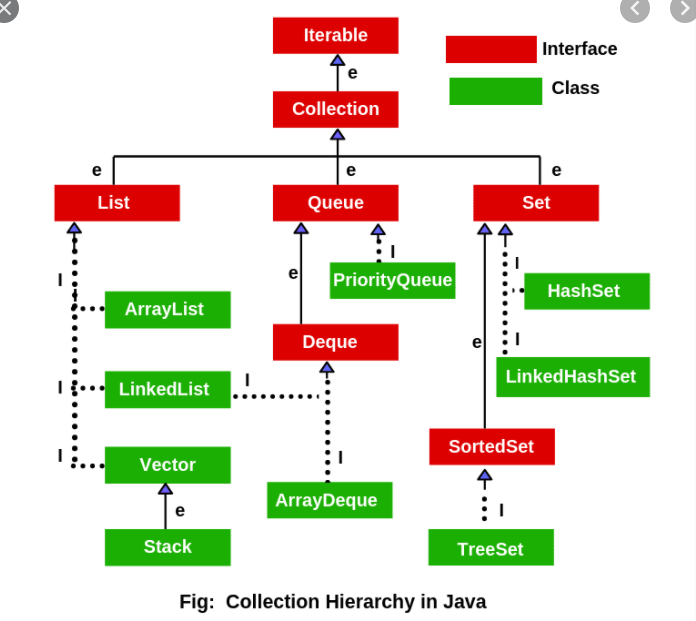 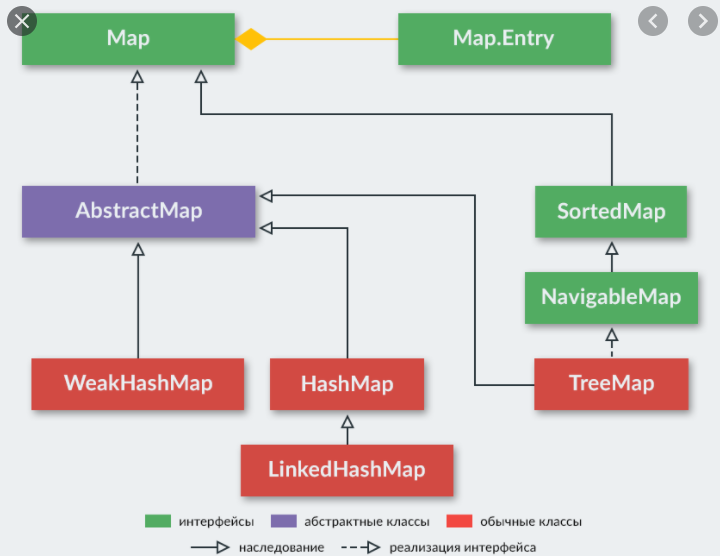 На вершине иерархии в Java Collection Framework располагаются 2 интерфейса: Collection и Map. Эти интерфейсы разделяют все коллекции, входящие во фреймворк на две части по типу хранения данных: простые последовательные наборы элементов и наборы пар «ключ — значение» соответственно. ПОДРОБНЕЕ ОБЯЗАТЕЛЬНО ПРОЧИТАТЬ ТУТ! 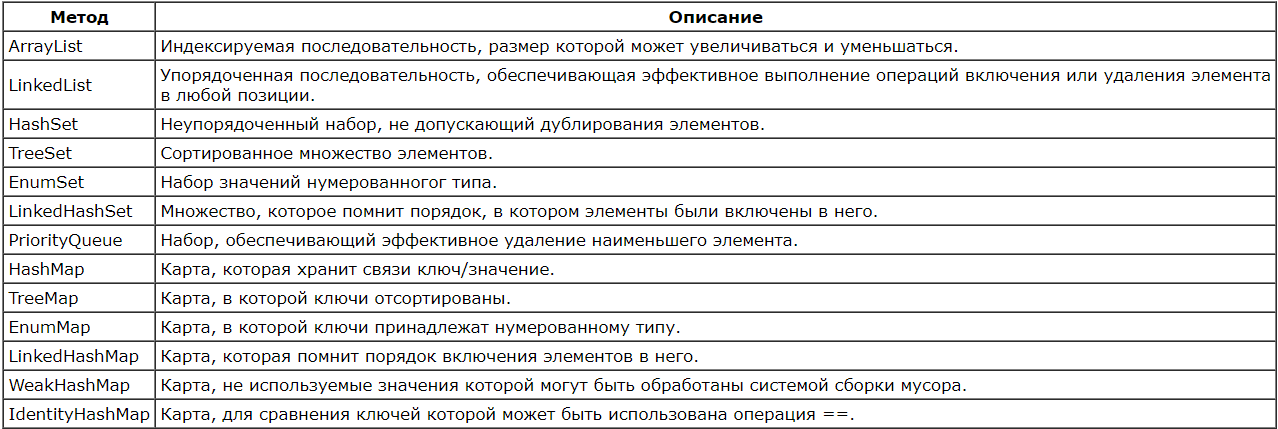 |
| 5. Iterable интерфейс расширяет интерфейс Collection. |
| Интерфейс Iterable является корневым интерфейсом для всех классов коллекции, поскольку интерфейс Collection расширяет интерфейс Iterable, поэтому все подклассы интерфейса Collection также реализуют интерфейс Iterable. Интерфейс Iterable содержит только один абстрактный метод. Iterator iterator(): возвращает итератор по элементам типа T. |
| 6. Что из себя представляет интерфейс Collection? |
| Этот интерфейс определяет основные методы работы с простыми наборами элементов, которые будут общими для всех его реализаций (например size(), isEmpty(), add(E e) и др.). Интерфейс был слегка доработан с приходом дженериков в Java 1.5. Также, в версии Java 8, было добавлено несколько новых методов для работы с лямбдами (такие как stream(), parallelStream(), removeIf(Predicate filter) и др.). Все эти методы были реализованы непосредственно в интерфейсе как default-методы. |
| 7. Какие методы у Collection? (15 штук) |
| - add(E e) - Гарантирует, что этот набор содержит указанный элемент (дополнительная работа). - addAll(Collection c) - Добавляют все элементы в указанном наборе к этому набору (дополнительная работа). - clear() - Удаляет все элементы от этого набора (дополнительная работа). - contains(Object o) - true возвратов, если этот набор содержит указанный элемент. - containsAll(Collection c) - true возвратов, если этот набор содержит все элементы в указанном наборе. - equals(Object o) - Сравнивает указанный объект с этим набором для равенства. - hashCode() - Возвращает значение хэш-кода для этого набора. - isEmpty() - true возвратов, если этот набор не содержит элементов. - iterator() - Возвращает iterator по элементам в этом наборе. - remove(Object o) - Удаляет единственный экземпляр указанного элемента от этого набора, если это присутствует (дополнительная работа). - removeAll(Collection c) - Удаляет все элементы этого набора, которые также содержатся в указанном наборе (дополнительная работа). - retainAll(Collection c) - Сохраняет только элементы в этом наборе, которые содержатся в указанном наборе (дополнительная работа). - size() - Возвращает число элементов в этом наборе. - toArray() - Возвращает массив, содержащий все элементы в этом наборе. - toArray(T[] a) - Возвращает массив, содержащий все элементы в этом наборе; тип времени выполнения возвращенного массива является типом указанного массива. Подробнее можно посмотреть тут! |
| 8. Какие интерфейсы расширяют интерфейс Collection? (3 интерфейса) |
| - List (список) представляет собой коллекцию, в которой допустимы дублирующие значения. Элементы такой коллекции пронумерованы, начиная от нуля, к ним можно обратиться по индексу. - Set (сет) описывает неупорядоченную коллекцию, не содержащую повторяющихся элементов. - Queue (очередь) предназначена для хранения элементов в порядке, нужном для их обработки, имеет предопределённым способ вставки и извлечения. Эта коллекция построена по принципу FIFO, First-In-First-Out («первым пришел-первым ушел»). |
| 9. Реализации интерфейса List? (4 класса) |
| - ArrayList - инкапсулирует в себе обычный массив, длина которого автоматически увеличивается при добавлении новых элементов. - LinkedList (двунаправленный связный список) - состоит из узлов, каждый из которых содержит как собственно данные, так и две ссылки на следующий и предыдущий узел. - Vector — реализация динамического массива объектов, методы которой синхронизированы. Позволяет хранить любые данные, включая null в качестве элемента. - Stack — коллекция является расширением коллекции Vector. Эта коллекция построена по принципу FILO, First-In-Last-Out («первым пришел, последним ушел») Является частично синхронизированной коллекцией (кроме метода добавления push(). После добавления в Java 1.6 интерфейса Deque, рекомендуется использовать именно реализации этого интерфейса, например ArrayDeque. |
| 10. Реализации интерфейса Set? (3 класса) |
| - HashSet - использует HashMap для хранения данных. В качестве ключа и значения используется добавляемый элемент. Из-за особенностей реализации порядок элементов не гарантируется при добавлении. - LinkedHashSet — гарантирует, что порядок элементов при обходе коллекции будет идентичен порядку добавления элементов. - TreeSet — предоставляет возможность управлять порядком элементов в коллекции при помощи объекта Comparator, либо сохраняет элементы с использованием «natural ordering». |
| 11. Реализации интерфейса Queue? (2 класса) |
| - PriorityQueue — предоставляет возможность управлять порядком элементов в коллекции при помощи объекта Comparator, либо сохраняет элементы с использованием «natural ordering». - ArrayDeque — реализация интерфейса Deque, который расширяет интерфейс Queue методами, позволяющими реализовать конструкцию вида LIFO (last-in-first-out). |
| 12. Какие методы у Queue? (15 штук) |
| - E element(): возвращает, но не удаляет, элемент из начала очереди. Если очередь пуста, генерирует исключение NoSuchElementException. - boolean offer(E obj): добавляет элемент obj в конец очереди. Если элемент удачно добавлен, возвращает true, иначе – false. - E peek(): возвращает без удаления элемент из начала очереди. Если очередь пуста, возвращает значение null. - E poll(): возвращает с удалением элемент из начала очереди. Если очередь пуста, возвращает значение null. - E remove(): возвращает с удалением элемент из начала очереди. Если очередь пуста, генерирует исключение NoSuchElementException. |
| 13. Интерфейс Deque? |
| Интерфейс Deque расширяет вышеописанный интерфейс Queue и определяет поведение двунаправленной очереди, которая работает как обычная однонаправленная очередь, либо как стек, действующий по принципу LIFO (последний вошел - первый вышел). |
| 14. Какие методы у Deque? (15 штук) |
| - void addFirst(E obj): добавляет элемент в начало очереди - void addLast(E obj): добавляет элемент obj в конец очереди - E getFirst(): возвращает без удаления элемент из головы очереди. Если очередь пуста, генерирует исключение NoSuchElementException - E getLast(): возвращает без удаления последний элемент очереди. Если очередь пуста, генерирует исключение NoSuchElementException - boolean offerFirst(E obj): добавляет элемент obj в самое начало очереди. Если элемент удачно добавлен, возвращает true, иначе - false - boolean offerLast(E obj): добавляет элемент obj в конец очереди. Если элемент удачно добавлен, возвращает true, иначе - false - E peekFirst(): возвращает без удаления элемент из начала очереди. Если очередь пуста, возвращает значение null - E peekLast(): возвращает без удаления последний элемент очереди. Если очередь пуста, возвращает значение null - E pollFirst(): возвращает с удалением элемент из начала очереди. Если очередь пуста, возвращает значение null - E pollLast(): возвращает с удалением последний элемент очереди. Если очередь пуста, возвращает значение null - E pop(): возвращает с удалением элемент из начала очереди. Если очередь пуста, генерирует исключение NoSuchElementException - void push(E element): добавляет элемент в самое начало очереди - E removeFirst(): возвращает с удалением элемент из начала очереди. Если очередь пуста, генерирует исключение NoSuchElementException - E removeLast(): возвращает с удалением элемент из конца очереди. Если очередь пуста, генерирует исключение NoSuchElementException - boolean removeFirstOccurrence(Object obj): удаляет первый встреченный элемент obj из очереди. Если удаление произшло, то возвращает true, иначе возвращает false. - boolean removeLastOccurrence(Object obj): удаляет последний встреченный элемент obj из очереди. Если удаление произшло, то возвращает true, иначе возвращает false. |
| 15. В чем разница между классами java.util.Collection и java.util.Collections? |
| java.util.Collections - набор статических методов для работы с коллекциями. java.util.Collection - один из основных интерфейсов Java Collections Framework. |
| Внутреннее устройство коллекций (подробности) |
| 1. Как устроена очередь, стек и двунаправленная очередь? |
| - Очередь — это как конвейер. С одной стороны кладешь, с другой забираешь. - Стек - как обойма пистолета, что последним кладешь, то первым забираешь. - Двунаправленная очередь - совмещает в себе очередь и стек. Это такой ящик с двумя отверстиями, в который вы что-то можете класть и с одной и с другой стороны, так же и забирать. Например, кладем слева и забираем слева (как стек) или кладем слева, а забираем справа (как очередь) или, с другой стороны, подходим и делаем то же самое. |
| 2. В чём разница между Queue и Deque и Stack? (очередь, дв.очередь, стек) |
| - Queue расширяет базовый интерфейс Collection и определяет поведение класса в качестве однонаправленной очереди, можно получить элементы в том порядке что и добавляли. - Deque расширяет интерфейс Queue и определяет поведение двунаправленной очереди, которая работает как обычная однонаправленная очередь, либо как стек. - Класс Stack определяет стандартный конструктор, который создает пустой стек. Stack включает все методы, определённые Vector, и самостоятельно добавляет 5 своих собственных. - boolean empty() - Проверяет, является ли стек пустым. Возвращает true, если стек пустой. Возвращает false, если стек содержит элементы. - Object peek() - Возвращает элемент, находящийся в верхней части стэка, но не удаляет его. - Object pop() - Возвращает элемент, находящийся в верхней части стэка, удаляя его в процессе. - Object push(Object element) - Вталкивает элемент в стек. Элемент также возвращается. - int search(Object element) - Ищет элемент в стеке. Если найден, возвращается его смещение от вершины стека. В противном случае возвращается 1. |
| 3. Как устроен класс ArrayList? (динамический массив) |
| - Внутри ArrayList’a находится обыкновенный массив, который выступает хранилищем данных. Если размер не указать при создании, то по умолчанию его размер — [10]. - При добавлении элемента в массив, в первую очередь производится проверка — достаточно ли во внутреннем массиве места и влезет ли еще один элемент. - Если место есть, новый элемент добавляется в ячейку, следующую за последним текущим элементом. - Если добавлять элемент в середину списка(массива), то происходит сдвиг элементов вправо (начиная с ячейки, в которую мы добавили элемент, это занимает значительное время.) - Если в массиве при проверке не оказалось места, то создаётся новый массив * на 1.5 + 1 элемент (то есть [16]) - Старый массив будет удален сборщиком мусора, и останется только новый, расширенный. Теперь поговорим об удалении элементов. При работе с обычными массивами возникает проблема: при удалении элементов в нём оставались “дыры”. Единственным выходом было сдвигать элементы влево каждый раз при удалении, причём писать код для сдвига приходилось самостоятельно. - ArrayList работает по тому же принципу, но в нём этот механизм уже реализован автоматически в методе remove(). - При удалении объектов из ArrayList размер внутреннего массива не уменьшается автоматически. - Для проведения оптимизации в данном случае можно использовать специальный метод класса ArrayList — trimToSize(). Подробнее можно посмотреть тут! |
| 4. Чем отличается класс ArrayList от класса Vector? Зачем добавили ArrayList, если уже был Vector? |
| Методы класса Vector синхронизированы, а ArrayList - нет; По умолчанию, Vector удваивает свой размер, когда заканчивается выделенная под элементы память. ArrayList же увеличивает свой размер только на половину. Vector это устаревший класс и его использование не рекомендовано. |
| 5. Как устроен класс LinkedList? |
| В LinkedList элементы фактически представляют собой звенья одной цепи. У каждого элемента помимо тех данных, которые он хранит, имеется ссылка на предыдущий и следующий элемент. По этим ссылкам можно переходить от одного элемента к другому. 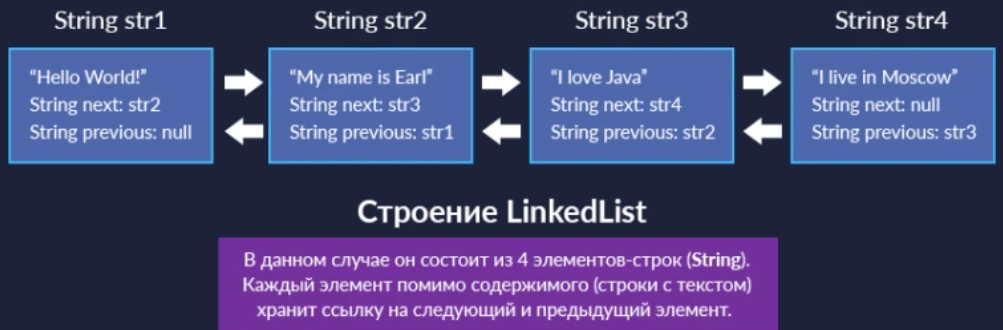 Добавление нового элемента делается с помощью метода add(). В результате элементы str2 и str1 становятся связанными через хранящиеся в них ссылки next и previous: LinkedList двусвязный список. Элементы LinkedList являются единым списком, именно благодаря вот этой цепочке ссылок. Внутри LinkedList нет массива, как в ArrayList. В отличие от удаления в ArrayList здесь нет никаких сдвигов элементов массива. Мы просто методом remove(), переопределяем ссылки у элементов str1 и str3. Теперь они указывают друг на друга, а объект str2 “выпал” из этой цепочки ссылок, и больше не является частью списка. |
| 6. Отличие классов ArrayList от LinkedList? |
| - ArrayList это список, реализованный на основе массива, а LinkedList — это классический двусвязный список, основанный на объектах с ссылками между ними и изменении этих ссылок. - В целом, LinkedList в абсолютных величинах проигрывает ArrayList и по потребляемой памяти, и по скорости выполнения операций. П 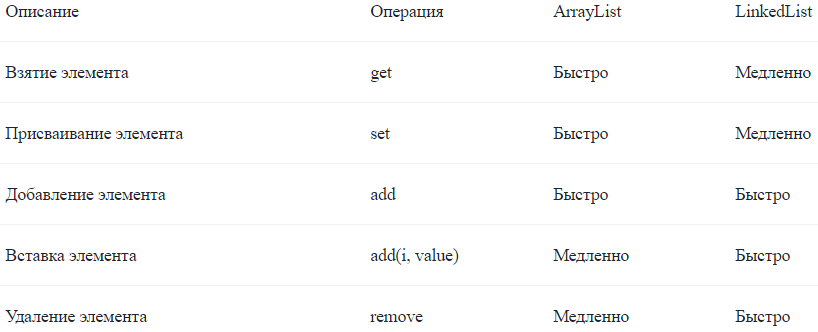 ри каждой вставке (удалении) в середине списка ArrayList уже знает точный адрес в памяти, к которому он должен обратиться, а вот LinkedList’у ещё нужно до места “дотопать”. ри каждой вставке (удалении) в середине списка ArrayList уже знает точный адрес в памяти, к которому он должен обратиться, а вот LinkedList’у ещё нужно до места “дотопать”. |
| 7. Когда лучше использовать класс ArrayList, а когда класс LinkedList? |
| - LinkedList предпочтительно применять, когда нужны частые операции вставки/удаления или в случаях, когда необходимо гарантированное время добавления элемента в список. - ArrayList это минимум накладных расходов при хранении элементов. - LinkedList требует больше памяти для хранения такого же количества элементов, потому что кроме самого элемента хранятся еще указатели на следующий и предыдущий элементы списка. Подробнее можно почитать тут! |
| 8. Методы классов LinkedList и ArrayList? |
| У LinkedList есть много общих с ArrayList методов. Например, такие методы как add(), remove(), indexOf(), clear(), contains() (содержится ли элемент в списке), set() (вставка элемента с заменой) и size() есть в обоих классах. Хотя (как мы выяснили на примере add() и remove()) внутри многие из них работают по-другому, но в конечном итоге они делают то же самое. У LinkedList есть 5 методов для работы с началом и концом списка, которых нет в ArrayList: addFirst(), addLast(): методы для добавления элемента в начало/конец списка. peekFirst(), peekLast(): возвращают первый/последний элемент списка. Возвращают null, если список пуст. toArray(): возвращает массив из элементов списка. |
| 9. Как устроен интерфейс Set? |
| Все классы, реализующие интерфейс Set, внутренне поддерживаются реализациями Map. HashSet хранит элементы с помощью HashMap. Хоть и для добавления элемента в HashMap он должен быть представлен в виде пары «ключ-значение», в HashSet добавляется только значение. |
| 10. Как устроен класс HashSet? |
| HashSet – это коллекция, которая для хранения элементов внутри использует их хэш-значения, которые возвращает метод hashCode(). (вспоминаем переопределение hashCode и equals) - Поиск в HashSet (и в HashMap) гарантированно работает правильно, только если объекты – immutable. - Класс реализует интерфейс Set, он может хранить только уникальные значения, основан на хэш-таблице; - В HashSet элементы не упорядочены, нет никаких гарантий, что элементы будут в том же порядке спустя какое-то время. - Порядок добавления элементов вычисляется с помощью хэш-кода; - HashSet также реализует интерфейсы Serializable и Cloneable; - Может хранить NULL – значения. - Поддерживается с помощью экземпляра HashMap. Начальная ёмкость – изначальное количество ячеек в хэш-таблице. Если все ячейки будут заполнены, их количество увеличится автоматически. Коэффициент загрузки – показатель того, насколько заполненным может быть HashSet до того момента, когда его ёмкость автоматически увеличится. Когда количество элементов в HashSet становится больше, чем произведение начальной ёмкости и коэффициента загрузки, хэш-таблица ре-хэшируется (заново вычисляются хэшкоды элементов, и таблица перестраивается согласно полученным значениям) и количество ячеек в ней увеличивается в 2 раза. Коэффициент загрузки = Количество хранимых элементов в таблице / размер хэш-таблицы Например, если изначальное количество ячеек в таблице равно 16, и коэффициент загрузки равен 0,75, то из этого следует, что, когда количество заполненных ячеек достигнет 12, их количество автоматически увеличится. Конструкторы HashSet: HashSet h = new HashSet(); — конструктор по умолчанию. Начальная ёмкость по умолчанию – 16, коэффициент загрузки – 0,75. HashSet h = new HashSet(int initialCapacity) – начальная ёмкость задана пользователем. Коэффициент загрузки – 0,75. HashSet h = new HashSet(int initialCapacity, float loadFactor); — начальная ёмкость коэффициентом загрузки задана пользователем. HashSet h = new HashSet(Collection C) – конструктор, добавляющий элементы из другой коллекции. Важно: HashSet не является структурой данных с встроенной синхронизацией, поэтому если с ним работают одновременно несколько потоков, и как минимум один из них пытается внести изменения, необходимо обеспечить синхронизированный доступ извне. Часто это делается за счёт другого синхронизируемого объекта, инкапсулирующего HashSet. Если такого объекта нет, то лучше всего подойдет метод Collections.synchronizedSet(). На данный момент это лучшее средство для предотвращения несинхронизированных операций с HashSet. Значения, которые мы передаём в HashSet, являются ключом к объекту HashMap, а в качестве значения в HashMap используется константа. Таким образом, в каждой паре «ключ-значение» все ключи будут иметь одинаковые значения. Можно заметить, что метод add() у HashSet вызывает метод put() у внутреннего объекта HashMap, передавая ему в качестве ключа добавляемый элемент, а в качестве значения – константу PRESENT. Сходным образом работает и метод remove(). В нем вызывается метод remove() внутреннего объекта HashMap |
| 11. Методы HashSet? |
| boolean add(E e): добавляет элемент в HashSet, если таковой отсутствует, если же такой элемент уже присутствует, метод возвращает false. void clear(): удаляет все элементы из множества. boolean contains(Object o): возвращает true, если данный элемент присутствует в множестве. boolean remove(Object o): удаляет данный элемент из множества, если таковой присутствует. Iterator iterator(): возвращает итератор для элементов множества. boolean isEmpty(): возвращает true, если в множестве нет элементов. Object clone(): выполняет поверхностное клонирование HashSet. |
| 12. Отличие класса HashSet от класса LinkedHashSet? |
| LinkedHashSet – это HashSet, в котором элементы хранятся еще и в связном списке. Обычный HashSet не поддерживает порядок элементов. Во-первых, официально порядка просто нет, во-вторых, даже внутренний порядок может сильно поменяться при добавлении всего одного элемента. А у LinkedHashSet можно получить итератор и с его помощью обойти все элементы именно в том порядке, в котором они добавлялись в LinkedHashSet. Не часто, но иногда это может понадобится. |
| 13. Почему в HashSet вместо value не null а new Object? |
| Потому что HashSet хеширует объекты при добавлении (хеш int-овый). Если добавить null, то приложение скомпилируется, но при запуске, когда встречается значение null, JVM пытается распаковать его в примитив int, что приводит к исключению NPE. Вы должны изменить свой код, чтобы избежать этого, добавив в качестве значения new Object. В случае с HashSet при возврате null будет непонятно -объект там был или не был. |
| 14. Как устроен класс TreeSet? |
| HashSet не может гарантировать, что данные будут отсортированы, так как работает по другому алгоритму. Если сортировка для вас важна, то используйте TreeSet. Класс TreeSet является реализацией интерфейса Set и реализует красно-чёрное дерево. Элементы в этой структуре данных хранятся в упорядоченном по возрастанию порядке. Эта структура данных является крайне эффективной, когда нам необходимо получить доступ к элементу при большом количестве элементов. |
| 15. Null в TreeSet? Можно ли? |
| В пустой TreeMap можно положить единственный ключ-null, все остальные операции (кроме size() и clear(), кстати) после этого не работают. В непустой TreeMap положить null-ключ нельзя из-за обязательного вызова compareTo(). |
| 16. Как работает метод contains в ArrayList, LinkedList, HashSet? |
| Возвращает, true если этот список или набор элементов содержит указанный элемент. Применяется строго после переопределения equals и HashCode!s |
| 17. Как происходит удаление элементов из ArrayList? Как меняется в этом случае размер ArrayList? |
| При удалении произвольного элемента из списка, все элементы, находящиеся «правее» смещаются на одну ячейку влево и реальный размер массива (его ёмкость, capacity) не изменяется никак. Механизм автоматического «расширения» массива существует, а вот автоматического «сжатия» нет, можно только явно выполнить «сжатие» командой trimToSize(). |
| 18. Расскажи отличие List от Set? |
| 1) Фундаментальное различие. List позволяет дублировать элементы. Set не позволяет дублировать. Если вы вставляете дубликат в Set, он заменит старое значение. Любая реализация Set в Java будет содержать только уникальные элементы. 2) List - упорядоченная последовательность элементов (LinkedList, ArrayList, Vector), тогда как Set — это отдельный список неупорядоченных элементов (HashSet, LinkedHashSet, TreeSet). Хотя Set предоставляет другую альтернативу SortedSet, которая может хранить элементы Set в определенном порядке сортировки, определенные методами Comparable и Comparator для объектов, хранящихся в Set. |
| 19. Что такое Iterator? (это интерфейс со способностью перебрать все элементы в коллекции) |
| Итератор идёт от начала коллекции к её концу: смотрит есть ли в наличии следующий элемент и возвращает его, если таковой находится. На основе этого несложного алгоритма построен цикл forEach. |
| 20. В каких случаях нужно использовать Iterator? И почему? |
| Когда нам нужно перебрать элементы класса Set или его подклассов. Вызывать итератор в явном виде зачастую нецелесообразно и делается это, как правило в одном случае — когда во время итерации вам нужно удалять элементы. У итератора есть методы hasNext, next и remove, которые проверяют наличие следующего элемента, получают следующий элемент и удаляют элемент. Попытка удаления элемента при итерации с помощью цикла приведет к исключению. |
| 21. В чём разница между Iterable и Iterator? |
| Интерфейс Iterable имеет только один метод - iterator(), который возвращает объект Iterator. - Iterable — это простое представление ряда элементов, которые могут быть повторены. Он не имеет никакого состояния итерации. Вместо этого у него есть один метод, который производит Iterator. - Iterator — это объект с состоянием итерации. Он позволяет проверить, есть ли в нём больше элементов, используя hasNext(), и перейти к следующему элементу (если таковой имеется), используя next(). |
| 22. Как между собой связаны Iterable, Iterator и «forEach»? |
| - Классы, реализующие интерфейс Iterable, могут применяться в конструкции forEach, которая использует Iterator. - При работе с forEach нельзя одновременно «идти по коллекции циклом» и удалять из неё элементы. Это всё из-за устройства итератора. - В цикле forEach использование итератора скрыто полностью. (позволяет сделать код лаконичнее) - Цикл forEach можно использовать для любых объектов, которые поддерживают итератор. Т.е. ты можешь написать свой класс, добавить ему метод iterator() и сможешь использовать его объекты в правой части конструкции forEach. |
| 23. Чем различаются Enumeration и Iterator? |
| Хотя оба интерфейса и предназначены для обхода коллекций между ними имеются существенные различия: - С помощью Enumeration нельзя добавлять/удалять элементы; - В Iterator исправлены имена методов для повышения читаемости кода (Enumeration.hasMoreElements() соответствует Iterator.hasNext(), Enumeration.nextElement() соответствует Iterator.next() и т.д); - Enumeration присутствуют в устаревших классах, таких как Vector/Stack, тогда как Iterator есть во всех современных классах-коллекциях. |
| 24. ListIterator - что это, в чём отличие от обычного Iterator? |
| - ListIterator расширяет интерфейс Iterator - ListIterator может быть использован только для перебора элементов коллекции List; - Iterator позволяет перебирать элементы только в одном направлении, при помощи метода next(). Тогда как ListIterator позволяет перебирать список в обоих направлениях, при помощи методов next() и previous(); - ListIterator не указывает на конкретный элемент: его текущая позиция располагается между элементами, которые возвращают методы previous() и next(). - При помощи ListIterator вы можете модифицировать список, добавляя/удаляя элементы с помощью методов add() и remove(). Iterator не поддерживает данного функционала. |
| 25. Что произойдет при вызове Iterator.next() без предварительного вызова Iterator.hasNext()? |
| Если итератор указывает на последний элемент коллекции, то возникнет исключение NoSuchElementException, иначе будет возвращен следующий элемент. |
| 26. Сколько элементов будет пропущено, если Iterator.next() будет вызван после 10-ти вызовов Iterator.hasNext()? |
| Нисколько - hasNext() осуществляет только проверку наличия следующего элемента. |
| 27. Зачем в итераторе метод remove? (iterator.remove()) |
| Если вызову iterator.remove() предшествовал вызов iterator.next(), то iterator.remove() удалит элемент коллекции, на который указывает итератор, в противном случае будет выброшено IllegalStateException(). |