Лабораторная. Лаб_10. Диаграммы потоков данных в методологии dfd
 Скачать 315 Kb. Скачать 315 Kb.
|

|
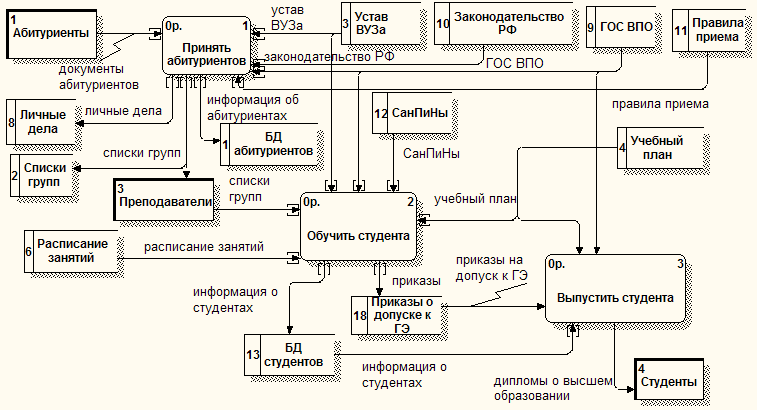
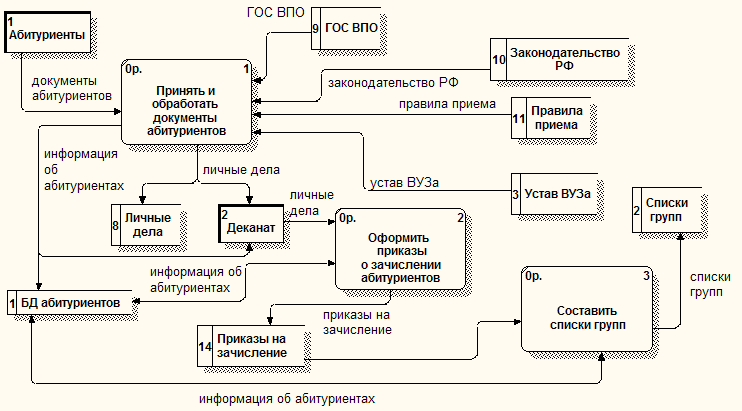
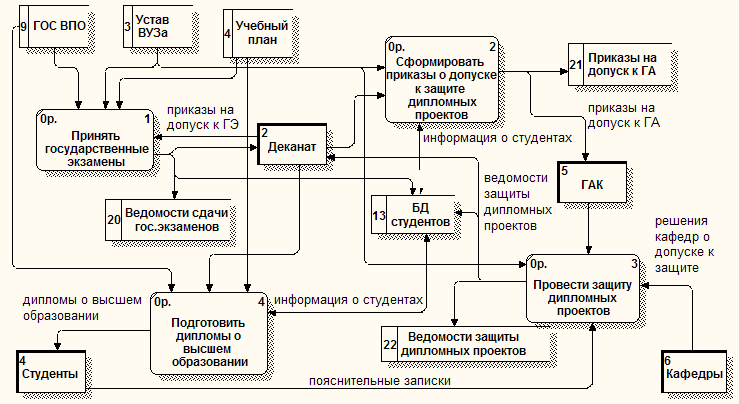
Федеральное государственное бюджетное образовательное учреждение высшего п образования Иркутский ГАУ ПРОЕКТИРОВАНИЕ ИНФОРМАЦИОННЫХ СИСТЕМспециальность 09.03.03 «Прикладная информатика (в экономике)» Лабораторная работа № 10 Тема: ДИАГРАММЫ ПОТОКОВ ДАННЫХ В МЕТОДОЛОГИИ DFD Учебные вопросы: Теоретические основы методологии DFD. Построение диаграмм потоков данных. Литература, техническое и программное обеспечение: Методическая разработка по теме занятия. Класс ПЭВМ. AllFusion Process Modeler 4.1 (BPwin). Вопрос 1. Теоретические основы методологии DFD Диаграммы потоков данных DFD показывают, как каждый процесс преобразует свои входные данные в выходные, и выявляют отношения между этими процессами. DFD-диаграммы успешно используются как дополнение к модели IDEF0 для описания документооборота и обработки информации. Подобно IDEF0, DFD представляет моделируемую систему как сеть связанных работ. А также эта методология может дополнять диаграммы IDEF0 путем декомпозиции их функциональных блоков. Для построения диаграмм DFD в BPwin используется нотация Гейна-Сарсона. Основные компоненты DFD Процесс (работа) – это преобразование входных потоков данных в выходные в соответствии с определенным алгоритмом (рис. 1.1). Каждый процесс имеет номер для его идентификации и имя. Имя начинается с глагола в неопределенной форме (вычислить, рассчитать, проверить, определить, создать, получить), за которым следуют существительные в винительном падеже. Работа имеет входы и выходы, но не поддерживает управление и механизмы, как IDEF0.  Рисунок 1.1 – Процесс (работа) Внешняя сущность – это материальный предмет или физическое лицо, являющееся источником или приемником информации, например, заказчики, клиенты, бухгалтерия (рис. 1.2). Определение некоторого объекта или системы в качестве внешней сущности указывает на то, что она находится за пределами границ анализируемой ИС. Внешняя сущность имеет номер для ее идентификации и имя. Одна внешняя сущность может быть использована многократно на одной или нескольких диаграммах. В процессе анализа некоторые внешние сущности могут быть перенесены внутрь диаграммы анализируемой ИС, если это необходимо, или, наоборот, часть процессов ИС может быть вынесена за пределы диаграммы и представлена как внешняя сущность.  Рисунок 1.2 – Внешняя сущность Поток данных (стрелка) – это информация, передаваемая через некоторое соединение от источника к приемнику. Реальный поток данных может быть информацией, передаваемой по кабелю между двумя устройствами, пересылаемыми по почте письмами, магнитными лентами или дискетами, переносимыми с одного компьютера на другой и т.д. Поток данных на диаграмме изображается линией, оканчивающейся стрелкой, которая показывает направление потока (рис. 1.3). Каждый поток данных имеет имя, отражающее его содержание. Поскольку в DFD каждая сторона работы не имеет четкого назначения, как в IDEF0, стрелки могут подходить и выходить из любой грани прямоугольника работы. 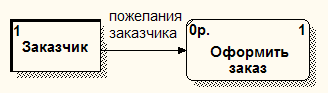 Рисунок 1.3 – Поток данных Хранилище данных – это абстрактное устройство для хранения информации, которую можно в любой момент поместить в него и через некоторое время извлечь, причем способы помещения и извлечения могут быть любыми (рис. 1.4). Хранилище данных может быть реализовано физически в виде микрофиши, ящика в картотеке, таблицы в оперативной памяти, файла на магнитном носителе и т.д. Каждое хранилище данных имеет номер для его идентификации и имя. В случае, когда поток данных входит в хранилище или выходит из него и его структура соответствует структуре хранилища, он должен иметь то же самое имя, которое нет необходимости отражать на диаграмме.  Рисунок 1.4 – Хранилище данных Построение диаграмм DFD Диаграммы DFD могут быть построены с использованием традиционного структурного анализа, подобно тому, как строятся диаграммы IDEF0. Диаграммы верхних уровней иерархии (контекстные диаграммы) определяют основные процессы с внешними входами и выходами. Они детализируются при помощи диаграмм нижнего уровня. Такая декомпозиция продолжается, создавая многоуровневую иерархию диаграмм, до тех пор, пока не будет достигнут такой уровень декомпозиции, на котором процессы становятся элементарными и детализировать их далее невозможно. Изображение компонентов системы с помощью контекстной диаграммы помогает аналитику, пользователю и менеджеру представлять альтернативные логические проекты системы высокого уровня. Элементы диаграммы DFD ведут непосредственно к физическому проекту, к процессам, предполагающим программы и процедуры, потокам данных, предполагающим связи и хранилищам данных, предполагающим сущности данных, файлы и базы данных. В DFD стрелки могут сливаться и разветвляться, что позволяет описать декомпозицию стрелок. Каждый новый сегмент сливающейся или разветвляющейся стрелки может иметь собственное имя. Правила построения диаграмм Все потоки данных должны начинаться или заканчиваться процессом. Данные не могут протекать непосредственно от источника до потребителя или между источником / потребителем и хранилищем данных, если они не проходят через промежуточный процесс. Потоки данных должны входить в процесс из хранилища данных или внешней сущности. Потоки данных, выходящие из процесса, должны входить в хранилище данных или внешнюю сущность. Поскольку механизмы процессов не указываются явно стрелками, для понятности в их можно указать в процессе в конце его имени, например, оформить заказ менеджером. Многочисленные потоки данных между двумя компонентами можно показывать двумя линиями потока данных или двунаправленной стрелкой. Название процесса состоит из глагола, следующего за существительным. В соответствии с соглашением, названия источников, получателей и хранилищ данных использует заглавные буквы, в то время как названиям процесса и потоки данных показываются произвольно. Процессы первого уровня перечисляется 1, 2, 3, и так далее. Подпроцессам в декомпозированной диаграмме потока данных назначают номера, начинающиеся с номера родительского процесса. Вопрос 2. Построение диаграмм потоков данных Запустите BPwin. В появившемся диалоговом окне ModelMart Connection Manager нажмите Cancel. В диалоговом окне BPwin выберите позицию Create model, введите имя модели Подготовка специалистов и тип DFD. Нажмите ОК. Появится окно Properties for New Models. Во вкладке General введите фамилию и инициалы автора. Остальные вкладки используются для определения настроек проекта. Автоматически создается контекстная диаграмма в рабочей области. Обратите внимание на панель инструментов DFD со следующими кнопками: |