Документация обычно содержится в тестпланах
 Скачать 270.2 Kb. Скачать 270.2 Kb.
|

Как работает gitВзаимодействие с удаленным репозиторием происходит при наличии интернета и, по сути, представляет собой синхронизацию двух репозиториев. Команда push копирует новые данные, содержащиеся в локальном репозитории, в удалённый репозиторий, а команда pull передает данные из удаленного репозитория в локальный. Каждая версия документа, внесенные обновления и т.д записываются в локальный репозиторий. Дерево проекта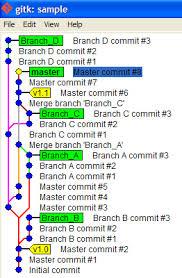 Дерево файлов в системе контроля версий Дерево файлов в системе контроля версий В репозитории содержится «дерево» проекта, то есть все сохраненные версии файлов. Дерево может быть прямым (в этом случае каждое последующее сохранение файлов производилось после предыдущего без возвращения к более ранним версиям) и разветвленным. К появлению «веток» приводит работа с более ранними версиями и сохранение внесённых изменений. На различных ветках дерева содержатся сохранения, основой которых был один исходный файл. В ходе работы в файлы на разных ветках были внесены разные изменения. В системе управления версиями можно работать со всеми ветками дерева проекта, пошагово, изменяя и дополняя содержащиеся в них данные. После проведения ряда изменений 2 ветки могут «срастись», в новой версии файла будут учтены все внесенные изменения. Git-хостингДля комфортной работы с git нужно зарегистрироваться на любом git-хостинге. Их довольно много: Github, Sourceforge, Google Code, GitLab, Codebase и т.д. Самый популярный на данный момент git-хостинг – это Github. Популярность его обоснована простым интуитивно понятным интерфейсом, поддержкой проектов с открытым кодом (возможностью бесплатно размещать такие проекты на хостинге) и обширным функционалом. Git-клиентДля удобства работы с системой контроля версий git разработан целый ряд графических git-клиентов. Это программы, позволяющие эффективно работать с системой контроля версий, используя графический интерфейс. Многие IDE предполагают возможность работы с git.  Работа с Git через IDE Работа с Git через IDE Работа с системами контроля версий — важный навык, нужный каждому программисту. Измеримость и определение качества кода это вечная тема в мире программирования. Думаю все специалисты которые уже имеют опыт с большими проектами с многолетней историей не сомневаются в необходимости поддерживать код в качественном состоянии. Но не всегда достаточно времени для того чтобы выяснить какие характеристики важны именно в этом проекте. В этой статье не будет описано как нужно писать и оформлять код и нужны ли пробелы вокруг скобок. Сегодня я постараюсь выделить самые важные аспекты которым стоит уделять внимание и на что они могут повлиять, а какие допустимые пределы и как за ними следить решать Вам. В первую очередь надо выяснить по каким метрикам надо определять качество кода и для чего это нам вообще нужно. В программировании нам повезло и, в большинстве случаев, для определении метрики нам достаточно определить важную для нас характеристику: соответствие правилам; сложность кода; дубликаты; комментирование; покрытие тестами. Сейчас рассмотрим каждую из них. Соответствие правиламПод этот пункт подпадают ситуации когда код компилируется и, в большинстве случаев, делает свое дело, при чем делает это правильно. Это интересная характеристика в большей степени от того, что в компании сначала должны существовать правила написания кода. Можно поступить проще и взять труд других (Java Code Conventions, GCC Coding Conventions, Zends Coding Standard), а можно поработать и дополнить их своими, наиболее подходящими для специфики вашей компании. Но зачем нам правила написания кода, если код делает свое дело? Чтобы ответить на вопрос выделим несколько типов правил: синтаксические правила — одни из наиболее бесполезных правил (но только первый взгляд), поскольку совсем никоим образом не виляют на исполнение программы. К ним можно отнести стиль именования переменных (camelCase, через подчеркивание), констант (uppercase), методов, стиль написания фигурных скобок и нужны ли они если в блоке только одна строка кода. Этот список можно продолжить. Когда программист пишет код, он его легко читает, потому что он знает свой собственный стиль. Но стоит ему дать код где используется венгерская нотация и скобки с новой строки, ему придется тратить дополнительное внимание на восприятие нового стиля. Особенно веселит ситуация когда несколько совсем разных стилей используются в одном проекте или даже модуле. правила поддержки кода — правила, которые должны сигнализировать что код слишком сложный и его будет трудно сопровождать. К примеру, индекс сложности (подробнее о нем ниже) метода или класса слишком большой или слишком много строк кода в методе, наличие дубликатов в коде или “magic numders”. Думаю суть ясна, все они указывают нам на узкие места которые сложно будет сопровождать. Но нельзя забывать что именно мы можем решить какой индекс сложности для нас большой, а какой приемлемый. очистка и оптимизация кода — самые простые правила в том смысле, что редко кто-то будет утверждать что выражения очень нужны, даже когда они нигде не используются. Сюда можно отнести лишние импорты, переменные и методы которые уже не используются, но по какой-то причине их оставили в наследство. Метрика здесь очевидная: соответствие правилам должно стремится к 100%, то есть чем меньше нарушений правил тем лучше. Цикломатическая сложность кодаХарактеристика, от которой напрямую зависит сложность поддержки кода. Здесь выделить метрику посложнее чем в предыдущей характеристике. Если по простому, оно зависит от количества вложенных операторов ветвления и циклов. Кому интересно более подробное описания, можно почитать на вики. Чем индекс ниже тем лучше, и тем легче в будущем будет менять структуру кода. Стоит мерить сложность метода, класса, файла. Значение этой метрики надо ограничить некоим предельным числом. К примеру цикломатическая сложность метода не должна превышать 10, иначе нужно упростить или разбить его. ДубликатыВажная характеристика, которая отображает насколько легко в будущем (или настоящим) можно будет вносить изменения в код. Метрику можно означить в процентах как соотношение строк дубликатов к всем строкам кода. Чем меньше дубликатов тем легче будет жить с этим кодом. КомментированиеОдна из самых холиварных и больных тем среди программистов: “Комментировать или не комментировать?”. Всем знаком диалог из книги Стива Макконнелла, он уже публиковался на хабре. Из этого можно сделать вывод что к характеристике нужно подходить очень индивидуально, исходя от специфики компании и продуктов с которыми компания работает: для маленьких проектов комментирование не столь необходимо, для больших же хорошо проработанные правила очень облегчат сопровождение. Для комментирования можно выделить две важные метрики: отношение комментариев ко всему коду — из этой метрики можно сделать вывод насколько детальные комментарии и насколько они могут быть полезными. Конечно, из этой метрики нельзя сказать есть ли комментарии “цикл” перед циклом, но это нужно исправлять когда проводится ревю. комментирование публичных методов — отношение комментированных публичных методов к общему их количеству. Так как публичные методы используются вне пределов класса или пакета, то лучше прокомментировать что этот метод должен делать и на что может повлиять. Количество публичных методов без комментария должно стремится к нулю. Как я уже написал, вопрос комментирования кода лучше решать исходя от потребностей компании, но лучше все же жить с комментированным кодом. Покрытие тестамиНе надо описывать необходимость и роль автоматических тестов для проекта, потому что это тема отдельной статьи. Но это очень важная характеристика качества кода. Уровень покрытия считывается как отношение количества покрытых тестами элементов кода к количеству всех существующих. В зависимости от того что означить как элемент кода, часто выделяют следующие типы покрытия: покрытие файлов — здесь нужно определить как понять что файл покрыт тестами: зачастую файл покрыт если тест попал в файл и исполнил хотя бы одну строку кода из файла. Поэтому такая метрика используется крайне редко, но она все же имеет право на существование. покрытие классов — аналогично с покрытием файлов, только покрытие классов :). Также редко используется. покрытие методов — тот же способ исчисления метрики. Правда покрытие методов может найти более широкое распространение: если у вас на проекте существует правило покрывать каждый метод хотя бы одним тестом, тогда с помощью этой метрики можно быстро найти код не соответствующий правилам. покрытие строк — одна из наиболее используемых метрик по покрытию. Тот же способ исчисления, только за об’эк берется строка. покрытие ветвлений — то же, соответственно за элемент берется ветвление. Добиться хорошего показателя по этой метрики стоит наибольших усилий. По этой метрике можно судить насколько совестно программист подошел к покрытию тестами. суммарное покрытие — метрика покрытия при которой в расчетах принимается во внимание не один элемент а несколько. Наиболее часто используют суммарное покрытие строк и ветвлений. Чем выше покрытие кода тестами тем меньше риск поломать часть системы и оставить это незамеченным. Вместо заключенияСписок представленный здесь не полный, но его может быть вполне достаточно для поддержки кода в качественном состоянии. Все эти характеристики входят в статический анализ кода и хорошей практикой есть автоматизировать этот процесс. Надеюсь для кого-то статья будет полезной. |