Это способ ограничения определенного рода информации конкретным списком возможных
 Скачать 6.7 Mb. Скачать 6.7 Mb.
|

1 2 containsValue(DataType dt) – Boolean содержит ли? containsKey(Key) – Boolean содержит ли ключ? keySet() выдает множество всех ключей. Values() выдает множество значений. entrySet() HashMap в деталях HashMap работает по принципу хеширования, которые определен в классе Object. С помощью метода HashCode любой объект преобразовывается в число Int. В основе HashMap лежит массив. Элементами данного массива являются структуры LinkedList. Данные структуры LinkedList и заполняются элементами, которые мы добавляем в HashMap. То есть каждый элемент массива будет содеражть LinkedList, так же часто называют элементами массива Бакетами, корзинами, нодами, потому что внутри каждого бакета содержится: HashCode Key Value Reference (ссылка на другой элемент HashMap, если есть, а если нет, то null) Сначала происходит сравнение с помощью HashCode, если одинаковый, то происходит сравнение по equals, если equals разные, то значит разные объекты, а если одинаковые, то объекты одинаковы 100%. При создания HashMap мы можем задать 2 параметра, которые очень влияют на производительность: Initial capacity – начальный размер массива; Load factor – коэффициент того, насколько массив должен быть заполнен, после чего его размер будет увеличен вдовое. Map Map Если мы устанавливаем большой размер HashMap тем больше памяти он будет занимать, но тем меньше будет образовываться LinkedList, поэтому и скорость поиска будет быстрее. Чем больше loadFactor, тем больше мы будем экономить памяти, но будет медленнее осуществляться поиск. 0,75 – золотая середина. При неправильной реализации метода HashCode(когда много коллизии), в один бакет помещаются наши элементы и образуют LinkedList, поэтому скорость начинает падать, но после определенного порога вместо LinkedList образуется сбалансированное дерево. Сбалансированное дерево:  Справа всегда больший элемент находится, а слева меньший. Тут уже происходит бинарный поиск, поэтому скорость O(log(n)). Ключи нужно делать неизменяемыми, то есть final, чтобы нельзя было изменить поле и мы не потеряли ключ. Так же HashMap not synchronized, поэтому нужно использовать QunqurentHashMap потому что она synchronized. Equals и hashcode Если переопределили Equals, то нужно переопределить и HashCode HashMap и HashSet используют хеширования при сравнении. В HashMap сравнение сначала идет по хешкоду, а потом уже по equals, поэтому два этих метода должны быть определенны правильно, иначе могут искажаться данные. Когда HashCode разных объектов совпадают – это называют коллизией и это соответственно плохо, значит что наш HashCode метод неправильно или плохо переопределен. Если, согласно методу equals, два объекта равны, то и HashCode данных объектов обязательно должен быть одинаковым. Если, согласно методу equals, два объекта НЕ равны, то hashcode данных объектов НЕ обязательно должен быть разными. Контракт equals(); Рефлексивность: для любого заданного значения x, выражение x.equals(x) должно возвращать true.Заданного — имеется в виду такого, что x != null Симметричность: для любых заданных значений x и y, x.equals(y) должно возвращать true только в том случае, когда y.equals(x) возвращает true. Транзитивность: для любых заданных значений x, y и z, если x.equals(y) возвращает true и y.equals(z) возвращает true, x.equals(z) должно вернуть значение true. Согласованность: для любых заданных значений x и y повторный вызов x.equals(y) будет возвращать значение предыдущего вызова этого метода при условии, что поля, используемые для сравнения этих двух объектов, не изменялись между вызовами. Сравнение null для любого заданного значения x вызов x.equals(null) должен возвращать false. TreeMap Элементами TreeMap являются пары ключ/значение. В TreeMap элементы хранятся в отсортированном по возрастанию порядке. Сортировка происходит по ключу. Ключи должны быть уникальны, если ключ повторяется, то происходит перезапись. Основная цель использования TreeMap – нахождения каких-нибудь range(отрезков). При работе с ключами, нет смысла переопределять методы equals и hashCode, потому что сравнение ключей происходит при помощи Compare, но стоит переопределять метод при поиске по значению, потому что как раз благодаря equals и hashCode происходит сранение значение. Not Synchronized. Map В основе TreeMap лежит красно-черное дерево. Это позволяет методам работать быстро, но не быстрее, чем методы HashMap. Значения могут быть неуникальными. Методы put, get, remove. descendingMap() – разворачивает наш TreeMap в обраную сторону(по ключам). tailMap(Key k) – больше определенного ключа будет выводиться. headMap(Key k) – меньше этого ключа будет выводиться. lastEntry() – выводит последний элемент. firstEntry() – выводит первый элемент. containsValue(DataType dt) – содержит ли значение? Красно-черное дерево является двоичным и самобалансирующимся. Поэтому скорость поиска будет O(log(n)) можно сказать, что бинарный поиск. LinkedHashMap LinkedHashMap – является наследником HashMap, Хранит информацию о порядке добавления элементов или порядке их использования. Производительность методотов немного меньше, чем у методов HashMap, то есть в каком порядке добавили, в таком порядке и будут находится. LinkedHashMap accessOrder – true/false: false – ничего не меняет, он оставляет порядок в котором были добавлены элементы, true – меняет в зависимости от использования, то есть если вызвали метод get, то данный элемент помещается в самый конец, то есть меняется порядок. HashTable HashTable – устаревший класс, который работает по тем же принципам, что и HashMap. В отличии от HashMap является synchronized. По этой причине его метода далеко не такие быстрые. В HashTable ни ключ ни значение не могут быть Null. Даже если нужно поддержка многопоточности HashTable лучше не использовать. Следует использовать ConcurrentHashMap. Set  Set – это коллекция уникальных элементов. Методы данной коллекции очень быстры. В основе любого Set, лежит урезанная версия Map. HashSet не запоминает порядок добавления элементов. HashSet в своей основе имеет HashMap, но вместо ключа, он имеет «заглушку» в виде константы. Так же может содержать null и not synchronized. Не может содержать дубликаты, и просто не добавляет. При вызове метода add у HashSet, он внутренне вызывает метод put, который принадлежит HashMap. Remove(DataType); Size(); IsEmty(); Contains(Object t); Если будем хранить кастомный класс, то необходимо переоределить HashCode и equals, потому что в основе он содержит HashMap. Метод addAll(HashSet hs); можно объединить без дубликатов два HashSet.(union) retainAll(HashSet hs); оставляет пересечение множеств двух HashSet.(intersect) removeAll(HashSet hs); - позволяет удалить из 1 HashSet, все элементы другого HashSet. TreeSet TreeSet хранит элементы в отсортированном по возрастанию порядке. В основе TreeSet лежит TreeMap. У элементов данного TreeMap: ключ – элементы TreeSet, значения – это константа-заглушка. Null не хранит. Add(DataType), remove(), contains(), first(), last(), headset(DataType) – берем все, что ниже, а tailSet(DataType) – берем, все что выше, включая, subset(DataType1, DataType2) – то есть множество больше или равно DataType1 и меньше DataType2. LinkedHashSet LinkedHashSet является наследником HashSet. Хранит информацию о порядке добавления элементов. Производительность методов немного ниже, чем у методо HashSet. В основе LinkedHashSet лежит HashMap. У элементов данного HashMap: ключи – это элементы LinkedHashSet, а значения – это константа-заглушка. Queue 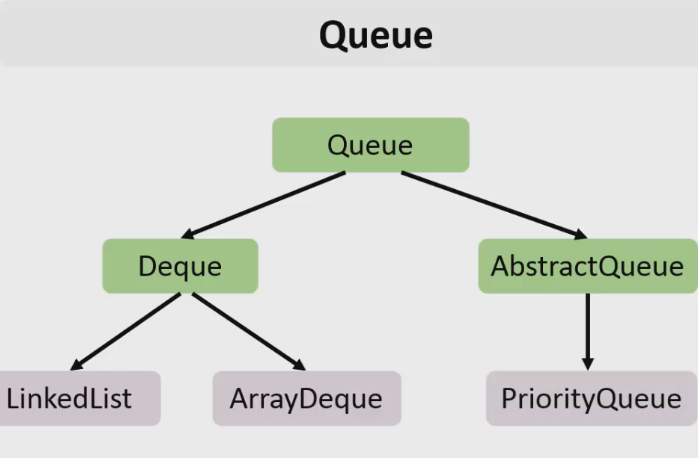 Все эти классы и интерфейсы not synchronized. Queue – это коллекция, хранящая последовательность элементов. Добавляется элементы в конец очереди, используется для начала очереди – правило ФИФО. Самый распространенная коллекция, когда нам нужна очередь. LinkedList, когда используется как очередь(то есть наследуется от Queue). Queue Add(“String”); - добавляет в конец очереди. Offer(“String”); - добавляет так же в конец очереди. Отличие add от offer: если наш LinkedList ограничен, например 4 элемента можем добавить только. При добавлении 5 элемента при помощи add – выбросится исключение, а если использовать метод offer, то исключение не будет и элемент не добавится в LinkedList. Remove(“String”); - удаляет элемент LinkedList, remove() – без параметров удаляет по методу ФИФО, то есть первый элемент. Выбрасывает исключение, если пытаемся удалять элемент, которого нет. Poll(); без параметров используется, не выбрасывает исключение, если элементы закончились и мы пытаемся их удалить. Удаляет по методу фифо. Element(); - показывает первый элемент в очереди, потому что используется метод фифо. Если пытаемся показать элемент которого нет, то выбрасывается NoSuchElementException. Peek(); - работает точно так же как и element() но не выбрасывает исключение, а возвращает null, если элемента нет. Данный класс LinkedList, который наследуется от Queue не предназначен для удаления элементов в середине, потому что тогда смысл от данной коллекции теряется, нужно использовать его, когда у нас есть очередь, и он работает по методу фифо. PriorityQueue PriorityQueue – это специальный вид очереди, в котором используется натуральная сортировка или та, которую мы описываем с помощью интерфейса Comparable или Comparator. Таким образом используется тот элемент из очереди, приоритет которого выше. Когда мы выводим с помощью sout PriorityQueue то сортировки нет, но, когда мы используем элементы с помощью remove или poll, то уже сортировка по natural order присутствует. Методы такие же как и в LinkedList(см выше). У PriorityQueue есть конструктор, который на входе принимает кастомный компаратор, где должна быть указана логика сортировки элементов, если она нужна. Deque and ArrayDeque Интрефейс Deque(Дек) расширяет интерфейс Queue и реализует двунаправленную очередь. Deque – double ended queue(двунаправленная очередь). В такой очереди элементы могут использоваться с обоих концов. Здесь работают оба правила – ФИФО и ЛИФО. Интерфейс Deque реализуется классами LinkedList и ArrayDeque. В классе ArrayDeque можно добавлять как в начало так и в конец, поэтому и называется двунаправленная очередь. Методы: ArrayDeque<”String”> a = new ArrayDeque<>(); addFirst(…) addLast(…) offerFirst(…); offerLast(…); Добавляет в начало или конец, add -выбрасывает исключение, а offer не выбрасывает. removeFirst(…) removeLast(…) poolFirst(…); poolLast(…); Удаляет элементы в начале или конце, remove – выбрасывает исключение, а pool не выбрасывает исключение. GetFirst(); getLast(); peekFirst(); peekLast(); берет первые или последний элементы, в данном классе нет метода element, тут они заменяются методом get. Метод add выбрасывает исключение, а метод peek не выбрасывает исключение и просто не добавляет. Lambda Это стиль функционального программирования, добавленный в java 8. С помощью Лямбы выражения можно заменять анонимные классы. Info.testSTudent(Students, (Student p) -> {return p.age<30;}); Выведет всех студентов, у которых возраст меньше 30 лет. Функциональные интерфейс – это интерфейс, который содержит всего один абстрактный метод. Короткий способ записи lambda p -> p.age<30; Stream Stream – это последовательность элементов, поддерживающих последовательные и параллельные операции над ними. Грубо говоря поток данных. Методы Stream List List.add(“….”); List.add(“….”); List.add(“….”); List.add(“….”); Добавили какие-то строки и мы хотим изменить строки в длину строк. Нам поможет stream. list.stream().map(element->element.length()).collect(Collectors.toList()); list.stream() – создаем поток map(element->element.length()) – с помощью map и Lambda делаем из элементов их длинну. collect(Collectors.toList()); с помощью коллекта переводим тип данных stream в List. Stream не меняет саму коллекцию или массив который мы изменяем, нужно создавать новый коллекцию или массив, чтобы задать нужные параметры 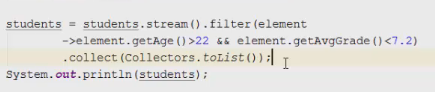 Filer – фильтрует просто значения.  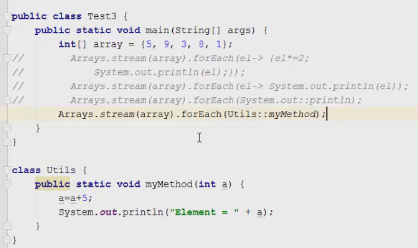 Reduce – с помощью данного метода уменьшаем n количество элементов до одного, например сложить все элементы или узнать длину массива или же коллекции. List List.add(5); List.add(8); List.add(2); List.add(4); List.add(3); 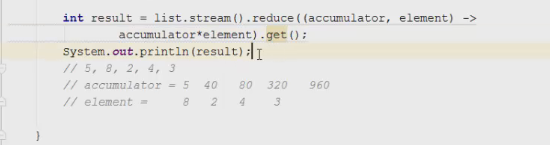 Нужно два параметра иметь, accumulator изначально становится первым элементом из коллекции, а element становится 2 элементом из коллекции, далее происходит их умножение, и получаем 40. Accumulator берет значение 40, а element берет значение 2, и происходит умножение и так по кругу. Reduce возвращает Optional, с помощью метода get(), мы переводим с тип данных int. Объект типа Optional обворачивает различные типы данных. 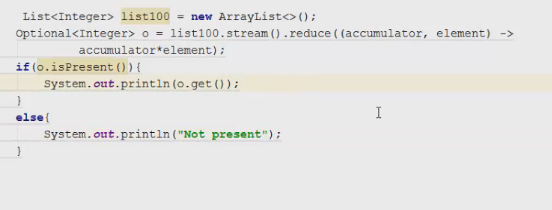 Правильно использовать так, чтобы обезопасить себя от ексепшена. Если наша Коллекция пустая, и мы попытаемся взять результат с помощью get(), то вылетит NoSuchElementException, поэтму нам необходимо присвоить значение Optional И с помощью isPresent() – обработать несколько ситуаций. Второй способ использования метода reduce:  Itentity = 1 Это означает, что первоначальное значение это 1, то есть accumulator = 1, а element = 5; происходит их умножение, и accumulator принимает значение 5, а element 8, и так до конца. Данный способ обеспечивает нам, что исключения не будет, потому что, если элементов нет, то ответ будет 1, так как accumulator = 1 изначально. Поэтому использовать метод get() нет необходимости, его нужно убрать. Sorted Сортирует по natural order, но если Student, то нужно наследовать интерфейс Comparable, либо созать кастомный компаратор и передать его в параметр sorted(...), либо прописать логику сортировки внутри метода sorted(… -> …) с помощью лямбы выражения. Chaining Использовать когда необходимо нам, что методы стрима шли друг за другом. Multithreading Cuncurenncy – выполнение сразу несколько задач одновременно. Методы Thread setName(“String s”); - назвать поток getName(); - получить название потока setPriority(Int i); - назначить приоритет getPriority(); - взять приоритет. Дефолт – 5. Максимальный – 10, а мин – 1; Thread.currentThread() – берет текущий поток. Thread.currentThread().getName(); – берет у текущего потока его название. Thread.sleep(“Long l”); - заставить спать наши потоки; Thread.join(); поток в котором вызывается данный метод, тогда данный поток будет ждать, пока выполнит всю свою работу другие потоки и только после этого закончит уже свою! В параметр можно передать Long l миллисекунды, чтобы либо подождать пока поток закончит свое действие, либо пока пройдет количество времени, указанное в параметре. Thread states (состояние потоков): New – когда поток был только создан, до метода .start(); Runnable – поток находится в состоянии выполнения, после вызова метода .start(); 2.1) Ready – поток готов к выполнению, то есть ждет ОС, пока его запустят, после вызова метода .start(); 2.2) Running – поток уже работает. Terminated – Работа потока завершена Thread.getState(); Различие между Cuncurrency/Parallelism and Asynchronous/ Synchronous; Cuncurrency(Согласованность) – Означает выполнение сразу несккольких задач. В зависимости от процессора компьютера concurrency может достигаться разными способами .Пример: Петь и кушать – в данном случае мы не можем выполнять два действия параллельно, поэтому сначала делаем немного одно, потом немного другое, то есть переключаемся между задачами(потоками). Готовить и говорить по телефону – в данном случае мы можем выполнять два действия одновременно, то есть параллельно, поэтому это и называется параллелизм. Parallelism – означает выполнение 2-ух и более задач в одно и то же время, т.е. параллельно. В компьютерах с многоядерными процессором concurrency может достигаться за счет parallelism. Asynchronous(Асинхронно) – выполняется одновременно, то есть пока одна работа выполняется, можем переключиться на другую работу. Например стирать и есть, пока вещи стираются в стиральной машинке, мы садимся за стол и кушаем. Synchronous(Синхронно) – выполняется последовательно друг за другом. Сначала написали одно письмо, потом второе письмо или же сначала выполнили один метод, потом другой метод. Когда наша программа является асинхронной и работает на многоядерной машине, то мы можем достичь Parallelism то есть выполнения двух задач параллельно друг другу. Ключевое слово volatile Когда мы используем данное ключевое слово, мы показываем, что наша переменная будет храниться только в main memory, а не в кеше CPU, ведь тогда может случится ситуация, когда мы изменили нашу переменную, а она осталась в кеше и не попала в main memory, откуда она должна попасть в кеш другого потока.  Для синхронизации значения переменной между потоками ключевое слово volatile используется тогда, когда только один поток может изменять значение этой переменной, а остальные потоки могут его только читать. Data race и synchronized методы Data race – это проблема, которая может возникнуть, когда два и более потоков обращаются к одной и той же переменной и как минимум 1 поток ее изменяет. Чтобы это исправить, мы можем поставить lock, чтобы два потока не могли одновременно обращаться к переменной. То есть пока полностью не выполнится работа, доступ других потоков не будет предоставляться к данной переменной. Чтобы поставить lock, нам нужно поставить ключевое слово synchronized, либо внутри метода создать блок synchronized(Объект){Логика}. Понятие «Монитор» и synchronized блоки Монитор имеется у каждого объекта и класса и имеет статус: Свободен Занят Именно так работает synchronized если у монитора статус Свободен, то он заходит и происходит работа нашего метода, а если статус занят, то ожидает, пока поток освободит данный монитор. Синхронизация происходит на объекте или классе. При ситуации, когда у нас есть два метода, и 3 потока, если один метод занят уже, то в другой метод поток не имеет право войти, пока первый не закончит, нужно использовать synchronized блок, где в параметре указать объект lock. Static final Object lock = new Object(); Pubic void phone(){ Synchronized(lock){….} } Pubic void phone2(){ Synchronized(lock){….} } Два метода синхронизированы на одном объекте(мониторе) Object, теперь каждый поток сможет войти в метод, когда оба будут свободны. Нельзя синхронизировать конструкторы, jvm обеспечивает нам, что конструктор может обеспечиваться только одним потоком. Методы wait и notify Для извещения потоком других потоков о своих действиях часто используются следующие методы: Wait – освобождает монитор и переводит взывающий поток в состояние ожидания до тех пор, пока другой поток не вызовет метод notify(); Notify – НЕ освобождает монитор и будит поток, у которого ранее был вызван метод wait(); notifyAll – НЕ освобождает монитор и будит все потоки, у которых ранее был вызван метод wait(); Возможные ситуации в многопоточном программировании Deadlock – ситуация, когда 2 или более потоков залочены навсегда, ожидают друг друга и ничего не делают. Чтобы избежать данную ситуацию, необходимо при использовании synchronized блоков использовать одинаковый порядок lockов. Livelock – ситуация, когда 2 или более потоков залочены навсегда, ожидают друг друга, проделывают какую-то работу, но без какого-либо прогресса. Например, есть два потока, первый поток делает какие-то записи, а второй поток их стирает, первый поток видит, что записей нет и опять начинает делать записи, а второй опять стер и так до бесконечности. Lock starvation – ситуация, когда менее приоритетные потоки ждут долгое время или все время для того, чтобы могли запуститься. Интерфейс Lock и ReentrantLock Lock – интерфейс, которой имплементируется классом ReentrantLock. Lock lock = new ReentrantLock(); Также как ключевое слово synchronized, Lock нужен для достижения синхронизации между потоками. Методы в интерфейсе Lock: Lock() – активируем наш лок и соответственно в одно и то же время воспользоваться участком кода может воспользоваться только один поток. Unlock() – снимает лок. tryLock() - можно использовать в связке с if else, то есть, если лок свободен, то нужно его занять, а если лок занят, то реализовать другую логику, например, использует другой метод или же просто ждет открытие лока. 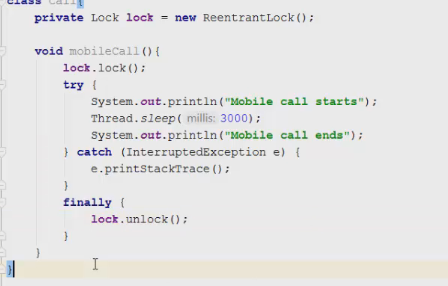 Между lock() и unlock() должна быть прописана логика нашего приложения. Unlock() обязательно должен быть помещен в блок finally, потому что если будет исключение, то мы в любом случае смогли разблокировать наш поток, то есть снять замок. Daemon поток Daemon потоки предназначены для выполнения фоновых задач и оказания различных сервисов User потокам. То есть, если все User потоки закончили свое действие, то программа завершится и не будет ждать выполнение Daemon потоков. Чтобы назначить поток демоном, необходимо setDaemon(true); данный метод необходимо вызывать после создания потока, но до его запуска. isDaemon() – является ли поток демоном; Прерывание потоков Thread.stop() – это старый метод и он прерывал поток грубо, классы и переменные могли находится не определенном состоянии, поэтому придумали другой метод. thread.interrupt(); - новый метод, который посылает поток сигнал о том, что его хотят прервать.  Нужно использовать так. isInterrupted() – есть ли сигнал о том, что хотят прервать данный поток или нет, если нет, то все продолжает работать, а если есть сигнал, то нужно return, что прерывает наш поток полностью.  Thread pool и ExecutorService Thread pool – это множество потоков, каждый из которых предназначен для выполнения той или иной задачи. Данный пул более эффективен для использования для множества потоков. Концепция Thread pool заключается в том что, когда у нас есть кучу потоков и задач, когда поток освобождается, то он берет выполнять другую задачу, после ее выполнения видит еще задачу и берется выполнять ее и тд. В java с thread pool удобнее всего работать при помощи ExecutorService. ExecutorService es = Executors.newFixedThreadPool(Количество потоков);  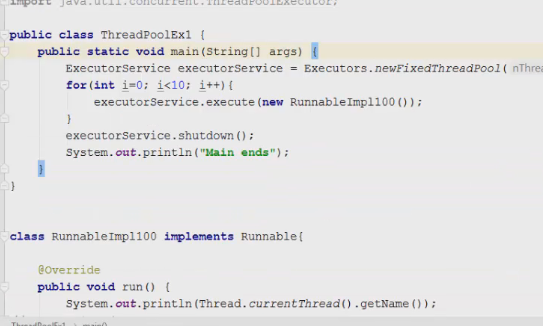 executorService.execute(new RunnableImpl100()); в параметр данного метода необходимо поместить объект, который impl runnable. Данный метод работает всегда, пока мы не выключим его с помощью метода executorService.shutdown(); Метод execute передает наше задание(task) в thread pool, где оно выполняется одним из потоков.  executorService.awaitTermination(Время какое-либо, TimeUnit.SECONDS); второй параметр нужно передать именно в чем будет время, дни, секунды, миллисекунды и тд. Данный метод работает как join то есть, где вызван был данный метод, тот поток будет ждать пока закончится выполнение нашего сервиса.  ExecutorService exec = Executors.newSingleThreadExecutor(); - создает один поток, а далее с помощью метода execute один поток начинает выполнять таски по логике как в Executors.newFixedThreadPool. ScheduledExecutorService мы используем тогда, когда хотим установить расписание на запуск потоков из узла. ScheduledExecutorService ses = Executors.newScheduledThreadPool(int count); Далее, чтобы начать выполнять наши таски необходимо вызвать метод execute. ses.execute(… Класс, который имплементирует Runnable). ses.schedule(Класс, который имплементирует Runnable, int delay(задержка), TimeUnit.SECONDS); - данный метод выполнит наши таски выполнит через определенный период времени delay(например, 3 секунды). ses.scheduleAtFixedRate(Класс, который имплементирует Runnable, int InitDelay, Int period, TimeUnit….); - initDelay – впервые данный таск обработается через int времени, period – будет выполнятся каждый n количество времени. ses.scheduleAtFixedRate(new RunnableImpl(), 3, 1, TimeUnit.SECONDS); то есть, в методе run нашего класса RunnableImpl таск начнет выполняться впервые через 3 секунды с периодичностью каждые 1 секунду. Например, у нас периодичность выполнения таска 1 секунда, а если в методе run таск выполняется 2 секунды, то наш метод ses.scheduleAtFixedRate не будет ждать еще 1 секунду, он сразу же будет выполнять следующий таск. ses.scheduleWithFixedDelay(Класс, который имплементирует Runnable, int InitDelay, Int period, TimeUnit….) данный метод работает точно так же как и ses.scheduleAtFixedRate, но между окончанием первого таска и началом второго таска обязательно должен пройти period, даже если наш таск выполняется 10 секунд, а период 1 секунду, то в любом случае между концом первого таска и началом второго пройдет ровно 1 секунда.  Еще можно создать следующий ThreadPool: ExecutorService es = Executors.newCashedThreadPool(); - кешированный ThreadPool и он будет создавать новые потоки по надобности. Например, пришел 1 таск и данный метод создал 1 поток и выполняет его, потом пришел 2 таск, нужно еще один поток создать и он его создает и тд. Если потоков не хватает для выполнения всех тасков, происходит просто создание новых потоков. Если уже новые таски не приходят и через 60 секунд к потоку не пришел новый таск, то кешированный поток удалит его. Интерфейсы callable и future Callable мы можем использовать только с ExecuteService.  Использовать данный интерфейс можно следующим образом:  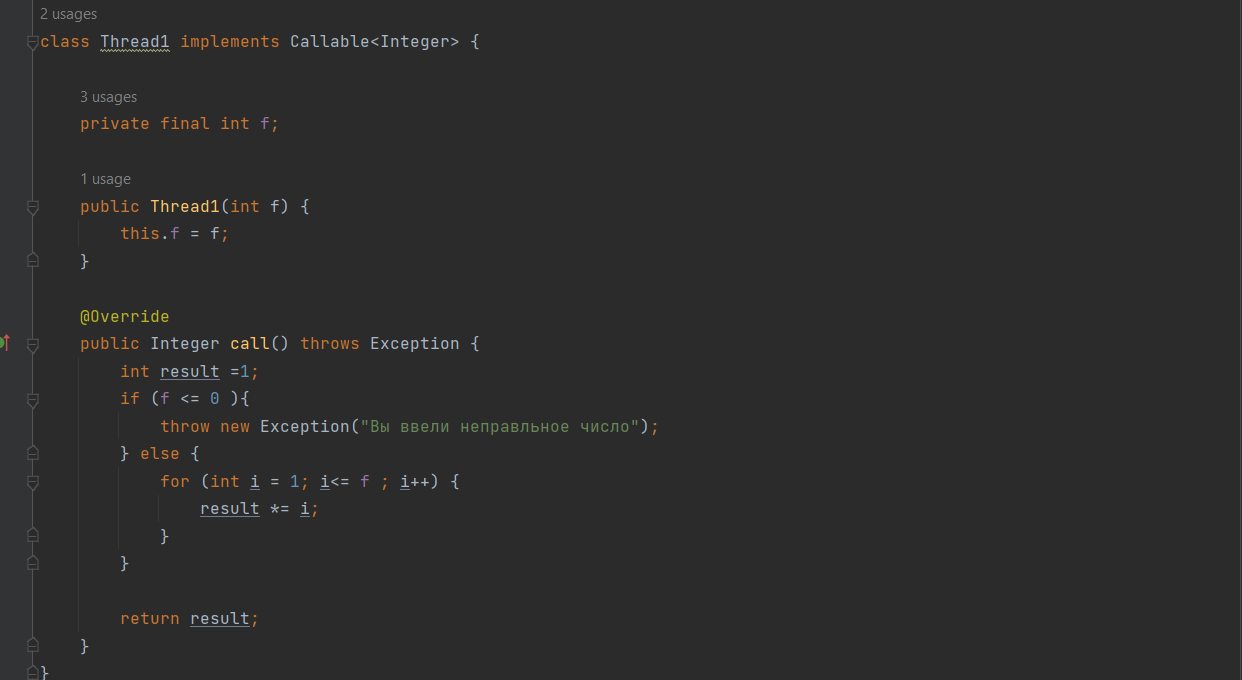 Когда мы используем кастомное исключение с помощью throw new Exception(“Ввели неправильное число”), необходимо в try catch блоке использовать e.getCause(), чтобы в консоль вывелось кастомное исключение. При имплементации интерфейса Callable Вместо метода execute у ExecuteService нужно использовать метод submit(return type Future 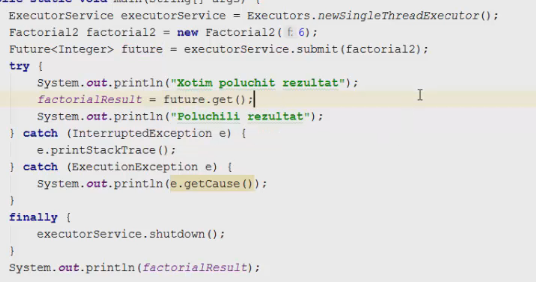 Когда мы пытаемся получить return type с помощью метода get(), может быть такая ситуация, когда поток еще выполняет данный таск, но мы уже хотим получить число, поэтому метод get() временно блокирует наш main поток, чтобы подождать пока наш поток довыполнит таск. Когда таск выполнится, метод get() разблокирует наш main поток и мы уже присвоим нашей переменной значение. С помощью метода future.isDone() – можно проверить выполнился ли наш таск или еще нет. Выводит true или false. Метод submit у ExecuteService можно использовать и у класса, который implements Runnable: Future future = new ExecuteService.submit(new Thread()) – сюда указать дженерики не нужно, потому что return type у класса, который implements Runnable является void, и если мы будем использовать метод get() у future, он всегда будет выдавать null. Синхронизатор Semaphore В предыдущем мы проходили concurrency на низком уровне, потому что мы сами писали локи, синхронизаторы, потоки и тд. А теперь мы будем рассматривать высокий уровень. Semaphore – это синхронизатор, позволяющий ограничить доступ к какому-то ресурсу. В конструктор Semaphore нужно передавать количество потоков Semaphore будет разрешать одновременно использовать этот ресурс. Иными словами, Semaphore разрешить изменять наш ресурс только 3 потоками(например 3 потоками), если все потоки уже работают над таском, то жругие ждут. Если в конструктор Semaphore мы передаем значение 1, то это будет однотипно использования lock.  Методы Semaphore().ecquire(); - предназначен для попытки получения разрешения для semaphore, то есть данный метод заблокирует наш ресурс, пока он будет доступен для нас. В начале мы указали, что телефоном могут пользоваться только 2 человека, поэтому пока 2 человека пользуются телефоном, semaphore не дает доступ, как только доступ появится, то будет сигнал и доступ предоставится уже другим. У semaphore есть counter, который уменьшается, если какой-либо поток уже использует наш ресурс. Semaphore().release(); - данный метод освобождает разрешение semaphore и counter увеличивается на единицу. Иными словами освобождает поток для semaphore. Данный метод необходимо использовать в блоке finally, чтобы гарантировать, что semaphore закончит свою работу в любом случае, даже если у нас будет выброшено исключение. Синхронизатор CountDownLatch CountDownLatch – это синхронизатор, которые предоставляет возможность любому количеству потоков ожидать до тех пор, пока не завершится определённое количество операция, после окончания, потоки будут отпущены. В конструктор данного класса передается количество операций, которое должно быть выполнено, чтобы наш класс отпусти потоки. CountDownLatch cdl = new CountDownLatch(Значение счетчика int); Допустим, нам нужно чтобы магазин заработал, для этого нужно чтобы сотрудники пришли, потом сотрудники разложили товары, и открыли магазиин. После каждого отдельного метода, который описывает приход сотрудников, разложение товаров и открытие магазина нужно вызвать метода cdl.countDown, чтобы счетчик у CountDownLatch уменьшился. Далее в классе, который имплементирует Runnable или наследует Thread, в метод run нужно вызвать cdl.await(), который, если у CountDownLatch номер счетчика больше 0, будет ждать пока счетчик не станет 0. Пример кода: 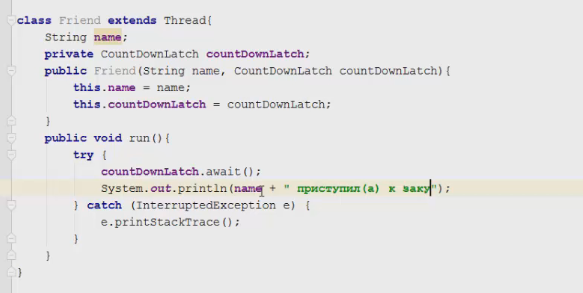 Синхронизатор Exchanger  То есть обмен информацией между потоками происходит только тогда, когда у двух потоков вызван метод exchange. Класс AtomicInteger AtomicInteger – это класс, который предоставляет возможность работать с целочисленными значениями int, используя атомарные операции. AtomicInteger ai = new AtomicInteger(); изначально внутри конструктора значение 0, но можно его изменить, например, на 104 13 220 и другие. Методы AtomicInteger: ai.counterAndGet(); - добавляет единицу и присваивает в значение, теперь data race нас не беспокоит. ai.getAndIncrement(); сначала получаем старое значение, а потом добавляем его, то есть в итоге получается в любом случае старое значение. ai.addAndGet(Int i); - добавляем то число, которое указано в параметре данного метода, например 1 2 5 6 и другие. ai.getAndAdd(int i) – сначала присваиваем значение, а потом уже добавляем какое-либо число. ai.decrementAndGet(int i); - сначала добавляем, а потом присваиваем. ai.getAndDecrement(int i); сначала присваиваем, а потом добавляем уже. Есть еще кучу других классов, например AtomicString, AtomicLong, AtomicChar и другие, работает по схожему выполняет неатомарные операции атомарным способом. Работа с IO и NIO Stream(поток) для работы с файлами – это упорядоченная последовательность данных. Файлы разделяют на: Читабельные для человека – text files; Нечитабельные для человека – binary files; Для работы с текстовыми и бинарными файлами нам необходимо использовать разные типы стримов(Одни для бинарных, другие для текстовых). FileReadder & FileWriter FileReadder and FileWriter используются для работы с текстовыми файлами. 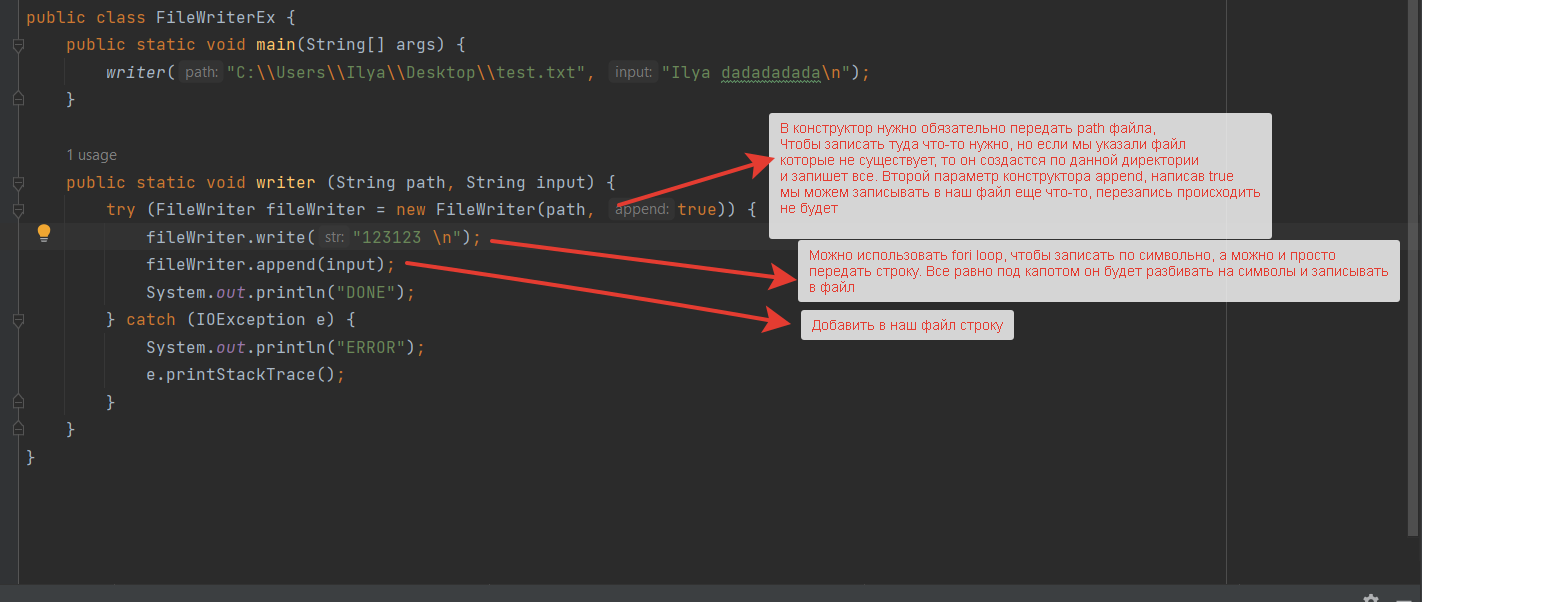 Обязательно помещать в try-catch-finally блок(или же try-with-resources – который является синтаксическим сахаром для try-catch блока). Если try-catch-finally – то обязательно нужно закрыть поток символов использовав метод close(). Данный метод появляется, если мы наследуемся от интерфейса AutoCloseable, где данный метод и находится. 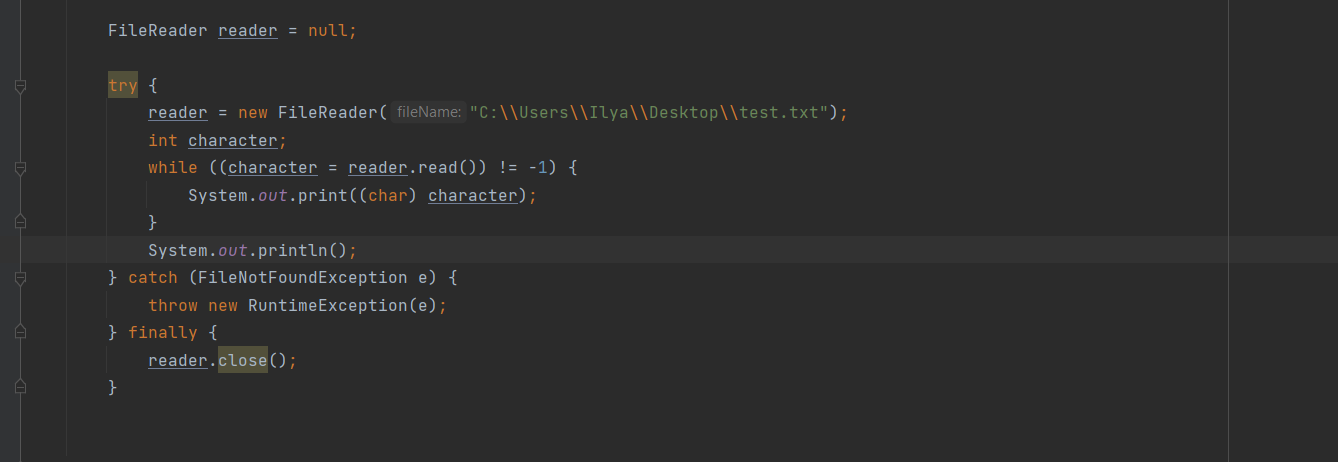 Все то же самое, но мы должны читать символы с файла. Метод reader.read() – имеет тип возвращаемого значение int, поэтому мы должны присвоить к int переменной значение и читать до тех пор, пока данное значение не станет -1, если значение равно -1, то значит reader.read() закончил чтение с файла поток данных. BufferedReader & BufferedWriter Использование буферизации в стримах позволяет достичь большей эффективности при чтении файла или записи в него! BufferedWriter writer = new BufferedWriter(new FileWriter(“file1.txt”)); BufferedWriter более эффективный, чем FileWriter. FileWriter обращается то количество раз, сколько всего символов нам нужно записать в файл, а BufferedWriter сначала заполняет свой буффер символами, а потом уже заполняет файл. Таким образом получается, что при использовании BufferedWriter мы обращаемся гораздо реже к file.txt, чем при FileWriter. Обращение к файлу, весьма ресурсоемкая задача. BufferedReader reader= new BufferedReader (new FileReader(“file1.txt”)); BufferedReader является более эффективной оберткой от FileReader, просто под капотом он содержит буффер. FileReader обращается каждый раз, когда хочет считать символ, столько раз он обратится к файлу, сколько символов содержит файл, а это весьма ресурсозатратная операция, поэтому и придумали BufferedReader. BufferedReader содержит под капотом буффер, который заполняется при обращении к файлу, то есть, чтобы прочитать символы в файле, нам необходимо гораздо меньше количество раз обратиться к файлу, чем при FileReader Первый способ копирования данных из одного файла в другой с использовании метода reader.read(), который возвращает int 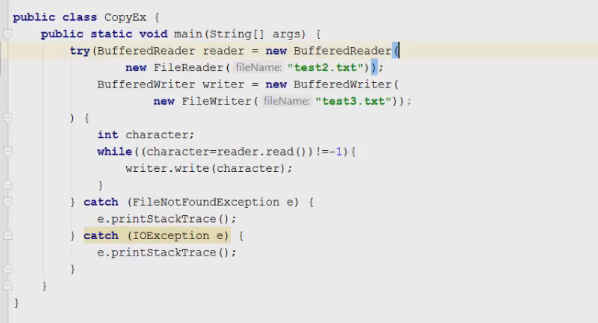 Просто скопировали данные из файла test2.txt в файл test3.txt; Второй способ копирования данных из одного файла в другой! 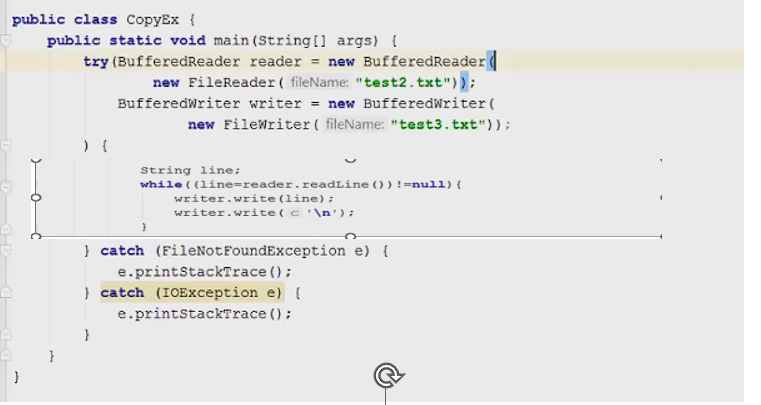 Запись и чтение из файла происходит через метод reader.readLine(). FileInputStream & FileOutputStream Данные два класса предназначены для работы с файлами при помощи потоков данных! Если мы попытаемся скопировать картинку при помощи FileReader и FileWriter или при помощи оберток над ними в виде буферизации, то потом мы не сможешь открыть данную картинку, ведь мы используем символьный формат, а нам нужен бинарный, следовательно нужно использовать FileInputStream & FileOutputStream! FileInputStream & FileOutputStream используются для работы с бинарными файлами.  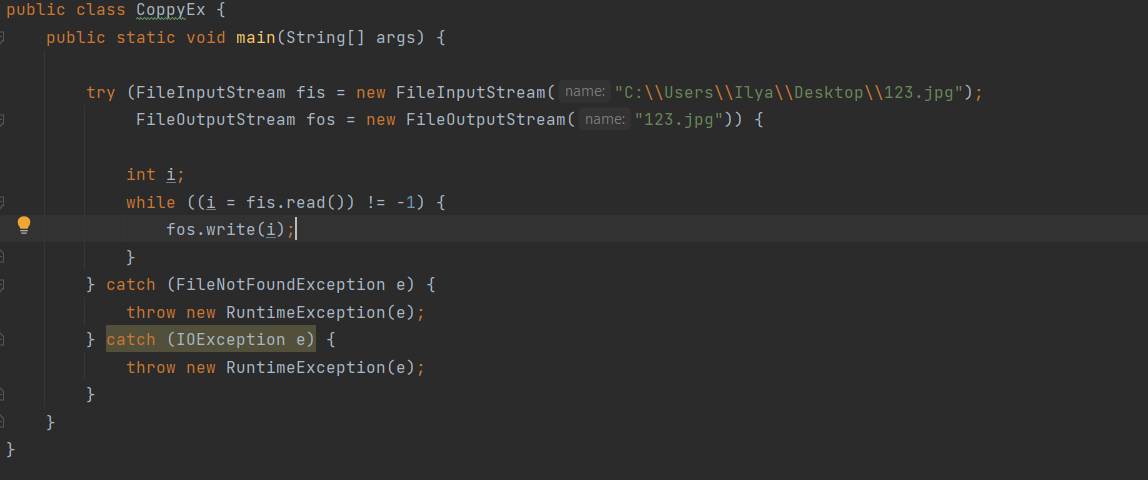 Все то же самое как и со символами, но под капотом бинарное считывание и записывание! Так же есть классы BufferedInputStream и BufferedOutputStream они являются просто оберткой над FileInputStream & FileOutputStream, которые под капотом используют буферизацию, поэтому и более эффективнее! DataInputStream & DataOutputStream DataInputStream & DataOutputStream данные классы позволяют записывать в файл и читать из них примитивные типы данных!  DataInputStream & DataOutputStream являются обертками над FileInputStream и FileOutputStream, предназначенные для работы с примитивными типами данных!  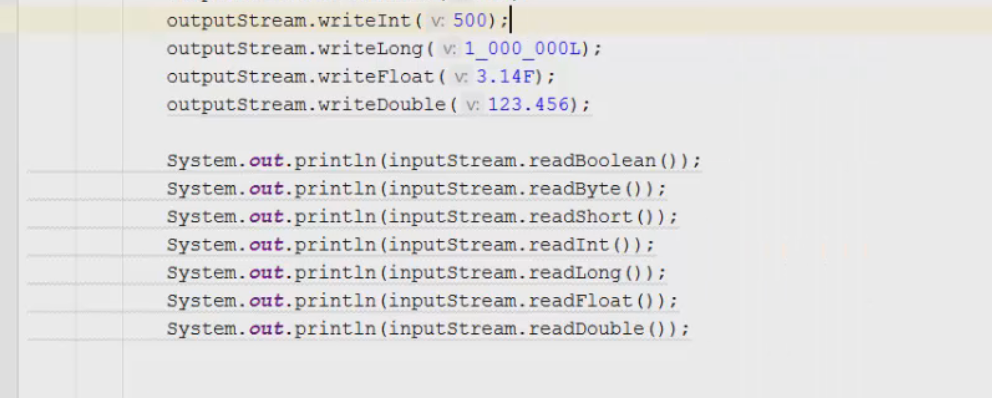 Serialization(Сериализация) Сериализация – это процесс преобразования объекта в последовательность байт. Десериализация – это процесс восстановления объекта, из последовательности байтов.  Для сериализации и десериализации мы будем использовать два данных класса, которые являются оберткой над FileInputStream и FileOutputStream соответственно! Для того, чтобы сериализировать объекты нужно, чтобы объект наследовал интерфейс Serializable, тогда мы можем его записать в bin файл и впоследствии считать!  Процесс сериализации: 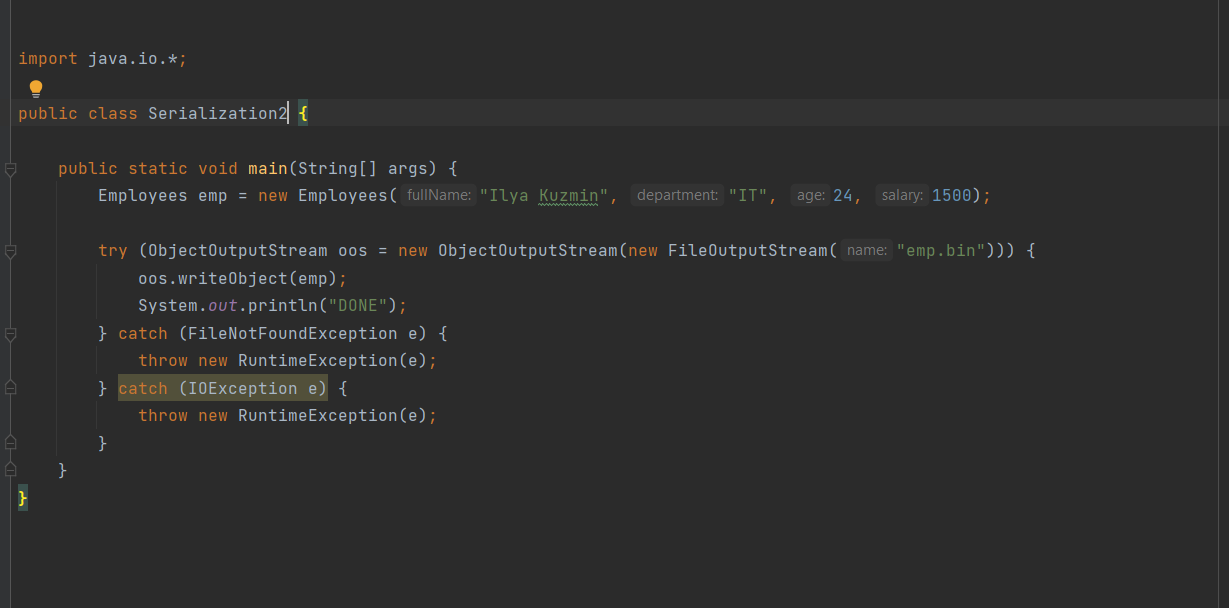 Процесс десериализации: 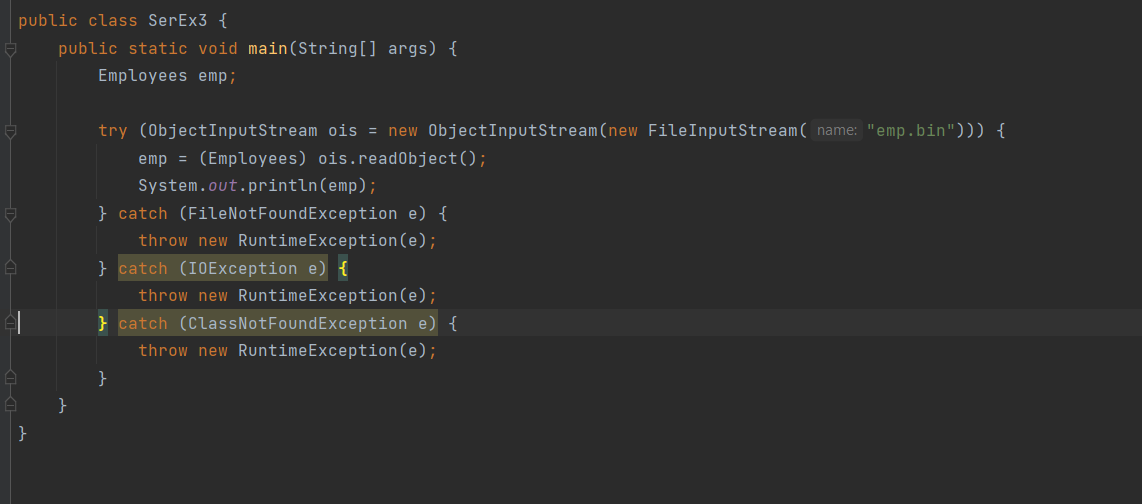 Если нам нужно, чтобы значение определенного поля не записывалось в файл и не читалось, нам необходимо пометить данное поле ключевым словом transient; Вместо, допустим: Private double salary; Transient private double salary; И он при выводе будет писать значения by default(для ссылочных null, Boolean false, примитивы 0); При сериализации, необходимо в явном виде укзаывать поле private static final long serialVersionUID = 1; - изначальное значение. Это необходимо, если у нашего класса Employee вдруг изменятся поля, то мы должен изменить версию нашего класса, чтобы дать понять другому программисту, которые пытается десериализовать. RandomAccessFile Данный класс RandomAccessFile позволяет читать информацию из любого места файла и записывать информацию в любое место файла! RandomAccessFile raf = new RandomAccessFile("test.txt", "rw") – второй параметр конструктора заключается в указании, что мы можем делать с нашем RandomAccessFile: R – read W – write Rw – read and write Seek(long l) – перемещает наш курсор на определенное значение. getFilePointer() – узнать на какой мы позиции находимся! Класс File  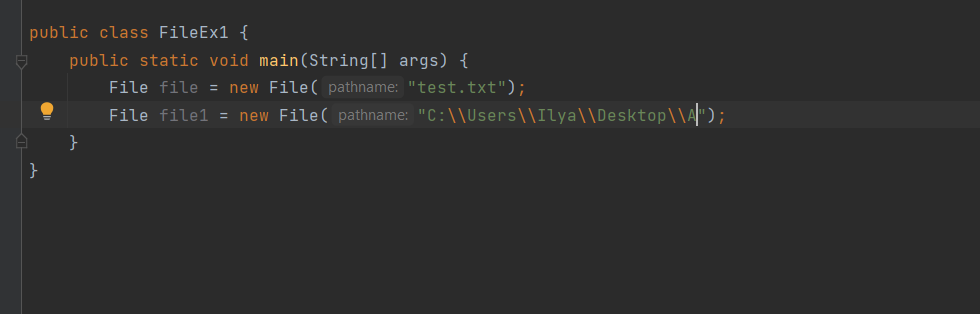 1) Первый путь является относительным, потому что он показывает файл относительно того места, где находится наш проект! 1) Первый путь является относительным, потому что он показывает файл относительно того места, где находится наш проект!2) Для папки путь является абсолютным, ведь он показывает точное местоположение! file.getAbsolutePath(); с помощью данного метода мы можем получить абсолютный путь из относительного, а если мы хотим получить абсолютный путь из абсолютного, то просто выведет абсолютный путь) file.isAbsolute() – наш файл или папка является абсолютной или нет? В первом случае нет, а во втором да(false; true); file.isDirectory() – проверяет является ли это папкой или же нет. В первом случае нет, во втором да! file.exists(); - проверит, существует ли наш файл или директория или же нет! file.createNewFile(); данный метод создает новый файл(именно только файл)! выдает true or false, если успешно создано, то true, а если нет, то false!; file.mkdir(); - данный метод создает директорию(mkdir – makeDirectory); выдает true or false, если успешно создано, то true, а если нет, то false! file.length(); - Узнать размер нашего файла или директории. Количество байтов для файла и всегда 0 для директорий, даже если внутри директории есть другие файлы в которых есть данные, разработчику необходимо самостоятельно реализовать данный функционал, чтобы узнать размерность нашей директории! file.delete()- удаляет папки и файлы! True or false, мы сможем удалить папку, только в том случае если она пустая, если там находится файл какой-то то будет false и удаление будет невозможно! File[] files = file.listFiles(); - узнать все содержимое нашей папки! Sout(Arrays.toString(files)); file.isHiden() – возращает true or false – скрыта наша папка или же нет! file.canRead() – есть ли доступ для чтения файла? True or false; file.canWrite() – есть ли доступ для записи в файл? True or false; file.canExecute() – есть ли доступ для выполнения данного файла? True or false; Константа File.separator – выводит \ для разделения между папками и фалайми, которая предназначенная для каждой платформы Unix/Windows   С помощью данного метода можно узнать, указывают ли два файла на один и тот же путь или же нет. Метод getAbsolutePath() – не всегда подойдет, потому что могут быть . или .. которые указывают на данную директорию, а если сравнивать с помощью equals() то это окажется разное, поэтому нужно использовать getCanonicalPath() – который под капотом берет асболютный путь и убирает все нужное. NIO New input and output – новый пакет, где собраны более эффективные и удобные классы для работы с вводом и выводом! Buffers and Channels Buffer – Это блок памяти, в который мы можем записывать информацию, а также читать ее. В отличии от стримов Channal может как читать файл, так и записывать в него! Чтение файла: Channel читает информацию из файла и записывает в Buffer. Запись в файл: Channel читает информацию из Buffer и записывает ее в файл.  Когда мы хотим прочитать нашу информацию из файла, то Channel читает информацию из file, передает эту информацию в буфер, а потом наша программа берет эту информацию из буфера. Когда мы хотим записать нашу информацию в файл, то программ записывает информацию в буфер, потом Channal читает эту информацию из буфера и далее записывает в file. Есть различные Buffer и Channel для различных видов работ. Channel всегда работает с Buffer! Buffer – это блок памяти в который мы можем записать какую-либо информацию для чтения из него или записи в файл!  Создать наш буфер и указать его размер. При помощи статического метода. Мы хотим взять данные из file, далее записать их в буфер и прочитать в нашей программе. Это делается с помощью int length = channel.read(buffer); Проверяем записалось что-нибудь в наш буффер или нет ? Если что-то записалось, то необходимо вызвать метод flip() чтобы перевести буфер из режима записи в него, в режим чтения из него. Далее мы присоединяем каждый байт(каждый байт мы закастили в чар). Далее мы с помощью метода clear() переводим наш buffer в режим записи в него. И цикл повторяется, если в наш буфер что-то записалось из файла! Далее рассмотрим как писать в файл Используя канал и буфер Можно писать в файл использую Channel and Buffer 2 способами: Способ(менее красивый и много использовать строчек кода) Создаем строку, которую хотим записать в файл! Далее создаем буфер, в котором указываем размер байтов длину. Далее, с помощью методa put, кладем нашу строку с помощью байтов. Далее переводим из режима записи наш Buffer в режим чтения для файла! И с помощью метода write записываем в файл!  Способ более элегантный Вместо метода allocate, мы можем использовать метод wrap, который самостоятельно выполняет под капотом весь функционал из 1 способа. И нам нужно будет только записать нашу строку в файл используя метод write.  Важные методы для Channel and Buffer  Большая часть методов описана выше, тут мы поговорим про последние 4 метода! buffer.rewind(); Возвращает наш курсор на первоначальную позицию. buffer.compact(); копирует непрочитанные байты в начало буфера 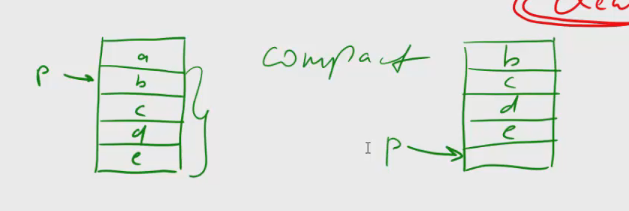 То есть, мы прочли один байт(1 байт) и находимся на второй позиции(значение b). Вместо метода clear() который бы затер по итогу наши данные, можем вызвать метод compact(); который скопирует непрочитанный байты b c d e в начало нашего буфера, а потом переместит наш курсор на позицию после скопированных непрочитанных байтов! buffer.mark(); ставим метку на определенной позиции. buffer.reset(); Производим возвращение к метке. 1 2 |