Эволюция систем баз данных
 Скачать 236.08 Kb. Скачать 236.08 Kb.
|

|
XML как модель данных На исторические причины возникновения XML можно посмотреть с двух различных, но связанных между собой точек зрения. Первая состоит в том, что семантическая ограниченность языка разметки гипертекста HTML не позволяла разработчику Web-приложений описывать специфическую информацию, например, химические или математические формулы. Возникла практическая потребность в других языках разметки, структурно аналогичных HTML, но с другой семантикой. В результате был создан метаязык XML. Вторая точка зрения состоит в следующем. Информация, заключенная в любом документе, в том числе и в Web-странице, является в большей или меньшей степени регулярной. Ранние варианты HTML слабо учитывали эту регулярность, что приводило к громоздкости сообщений на этом языке и не вполне удовлетворяло разработчиков Web-приложений. В общем виде XML-документ имеет структуру произвольного дерева, которая описывается набором вложенных друг в друга тегов. XML-ориентированные базы данных в качестве модели данных использует модель данных, принятую в самом XML. Следует отличать XML-ориентированные базы данных (например, Tamino) от реляционных, поддерживающих обмен данными на языке XML (Oracle, Microsoft SQL Server и др.). В основе последних лежит реляционная модель. Использовать XML в качестве базы данных в средах, где нет больших объемов данных, большого количества пользователей, нет высоких требований к производительности, вполне допустимо. Однако такой подход вряд ли годится для многих реальных задач, предполагающих поддержку большого числа пользователей, жесткие требования к целостности данных и производительности. Многомерная модель данных (OLAP) В развитии концепции информационных систем выделяют два направления: 1) системы оперативной обработки транзакций (OLTP – On-Line Transaction Processing); 2) системы оперативной аналитической обработки (OLAP – On-Line Analytic Processing). OLTP-системы рассчитаны на быстрое обслуживание относительно простых запросов большого числа пользователей. Время выполнения типичных запросов в таких системах не должно превышать нескольких секунд. Например, запрос к OLTP-системе продажи железнодорожных билетов мог бы выглядеть так (в вербальной формулировке): есть ли свободные купейные места на поезд № 9 на такое-то число? Логической единицей функционирования OLTP-систем является транзакция. Применение для реализации систем такого класса баз данных, основанных на реляционной модели данных, является эффективным. OLAP-системы ориентированы на анализ данных и поддержку принятия решений. Включают сложные запросы, требующие статистическую обработку данных за некоторый прошедший промежуток времени, моделирование процессов предметной области, прогнозирование тех или иных явлений. Например, запрос к OLAP-системе продажи железнодорожных билетов мог бы выглядеть так (в вербальной формулировке): каким будет объем продаж железнодорожных билетов в денежном выражении в следующем квартале с учетом сезонных колебаний? OLAP-системы часто включают средства обработки информации на основе методов искусственного интеллекта. Имеют развитые средства графического представления данных. Оперируют большими объемами исторических данных. Реализуют сложные методы анализа, позволяющие выделить из исторических данных содержательную информацию. Реализуют специальные хранилища данных для накопления информации из различных источников за большой период времени. Обеспечивают быстрый доступ к информации. Таким образом, концепция хранилищ данных – это концепция подготовки многомерных данных для последующего анализа. Можно выделить два основных подхода к построению хранилищ данных: 1) подход, использующий многомерную модель БД (MOLAP – Multidimensional OLAP); 2) подход, использующий реляционную модель БД (ROLAP – Relational OLAP). Достоинством многомерной модели данных является более быстрый поиск и чтение данных, и отсутствие необходимости множественного соединения таблиц. Недостаток многомерной модели заключается в потребности в большом объеме памяти для хранения данных и сложность модификации структуры данных. Например, добавление еще одного измерения приводит к необходимости полной перестройки гиперкуба. 3. Данные мультимедиа. 3. Данные мультимедиа. Люди взаимодействуют с мультимедиа каждый день: чтение книг, просмотр телевидения, прослушивание музыки. За последние несколько десятилетий цифровые СМИ значительно распространились. С момента введения мультимедиа в персональные компьютеры, мультимедиа стала общедоступной. Теперь можно легко и быстро оцифровать часть мультимедийных данных вокруг нас. Основным преимуществом оцифрованных данных от хранения данных в обувной коробке в том, что оцифрованными данными можно легко поделиться с другими людьми. Мультимедийная база данных представляет собой совокупность взаимосвязанных мультимедийных данных, которые включают в себя один или более первичных средств массовой информации, таких как: текст, графика: эскизы, изображения: цветные и черно-белые картинки, фотографии, карты, анимированные объекты, видео, аудио, комплексные мультимедиа: сочетание двух или более из указанных выше типов данных. Мультимедийная база данных содержит один или несколько типов мультимедийных данных. Эти типы данных подразделяются на три класса: статические - не зависимы от времени, постоянны, не интерактивны, например, изображения или графический объект; динамические - зависят от времени, движущихся, интерактивные, например, аудио-, видео и анимация; многомерные(трѐхмерные (3D), четырѐхмерные (4D)) –рассматривают данные либо как факты с соответствующими численными параметрами, либо как текстовые измерения, которые характеризуют эти факты, примером многомерной базы данных служит технология OLAP (система оперативной аналитической обработки). Мультимедийные базы данных могут обеспечить более эффективное распространение информации при минимальных затратах средств и энергии в таких областях, как: мультимедийные образовательные сервисы, видео по требованию, экспертные системы, электронная коммерция, медицинские информационные системы. Особенности мультимедийных БД: 1.Отсутствие структуры: мультимедийные данные часто являются неструктурированными, поэтому их трудно найти в документе или извлекать с помощью приложения, управляющего клиентскими базами. 2.Временные и пространственные данные: пространственныеданные сами по себе являются трудными для анализа, и для создания эффективных пространственно-временных систем необходимы специальные алгоритмы. 3.Большой объем данных: мультимедийные данные часто требуют большего по объему запоминающего устройства, что не всегда удобно. 4.Логистика: нестандартные носители могут осложнить обработку. Например, мультимедийное приложение баз данных требует использования алгоритмов сжатия. 5.Перегрузка информацией: обилие различных данных могут запутать и загрузить пользователя и базу данных лишней, возможно, ненужной информацией. В мультимедийном представлении информации возникает проблема разработки новых средств для просмотра, поиска, визуализации содержимого мультимедийных баз данных, но существует два самых часто используемых подхода для представления и поиска контента мультимедийных данных: 1.Ключевое слово: мультимедийный контент описывается пользователю через аннотации. 2.Подход на основе функций: для представления и извлечения мультимедийных данных может быть использован набор функций. Требования, предъявляемые к мультимедийным СУБД 1.Интеграция - возможность избежать дублирования данных для обращения к ним из различных программ. 2.Управление одновременным доступом - обеспечение непротиворечивости данных в БД мультимедиа с помощью правил, регулирующих порядок выполнения параллельных транзакций. 3.Сохранение текущего состояния между сеансами - способность объектов данных продолжать существовать (сохранять текущее состояние) на протяжении ряда различных транзакций и сеансов работы программы. 4.Защищенность - ограничение от несанкционированного доступа к хранимым данным и их модификации. 5.Контроль целостности - обеспечение непротиворечивости состояния БД в процессе обработки транзакций путем наложения на них определенных ограничений. 6.Восстановление - методы, служащие гарантией того, что неудачно завершившиеся транзакции не повлияют на постоянно хранимые данные. 7.Поддержка обработки запросов - распространение механизмов обработки запросов на мультимедиа - данные. 8.Управление версиями - организация хранения различных версий объектов и управление ими. Данная возможность может потребоваться для некоторых приложений. 4. Интеграция информации. В различных подразделениях крупных компаний могут использоваться различные базы данных. Каждое независимое подразделение вправе использовать те БД, которые посчитают нужными. В результате, в пределах одной компании, для описания одних и тех же предметов реального мира могут использоваться разные структуры данных, разные наименования для одной и той же вещи, либо один термин для обозначения нескольких вещей. Строгую централизацию БД проводить не всегда приемлемо. Специализированные разработки слишком дорого переделывать; при укрупнении компаний в распоряжение компании поступают сторонние базы данных. Исходя из этих и других причин унаследованные базы данных не могут (и не должны) непосредственно заменяться единой центральной базой данных компании. Более разумно поверх существующих решений построить новую информационную структуру, способную представить информацию всех подразделений в удобном виде. Одно из популярных решений такой задачи связано с использованием технологии хранилищ данных (data warehouses), которые предполагают копирование информации из унаследованных БД с соответствующей трансляцией и последующим сохранением в центральной БД. После внесения изменений в унаследованной базе данных необходимые исправления вносятся и в содержимое хранилища, хотя не обязательно автоматически и немедленно. Репликация данных обычно производится ночью, когда нагрузка на базы данных наиболее низка. Унаследованные базы данных продолжают выполнять свои обычные функции, а новые, такие как публикация данных на Web, или построение сводных отчетов возлагаются на хранилище данных. Хранилища данных открывают перспективы применения технологии «разработки» данных (data mining) – поиска аномалий, необычных образцов информации и использования их для оптимизации бизнес процессов. 5. Обзор структуры и технологий СУБД. Непрерывные линии – команды, пунктирные – потоки данных. Прямоугольники – компоненты системы. Прямоугольники с двойной рамкой – структуры данных образованные в памяти. Два источника команд: Рядовые пользователи и прикладные программы, запрашивающие или изменяющие данные Администратор базы данных (database administrator, DBA) – лицо или группа лиц, ответственных за поддержку и развитие структуры, или схемы базы данных. Команды определения данных Язык DDL (Data Definition Language – язык определения метаданных) -> Компилятор DDL -> Исполняющая машина изменяет метаданные. Обработка запросов Язык управления данными (Data Manipulation language - DML), язык запросов (query language). SQL – самый распространенный. Получение ответа на запрос Компиляция -> план запроса (query plan) -> запросы на выборку данных менеджеру ресурсов, который осведомлен о размещении файлов данных, таблиц, индексов. Запросы на получение данных преобразуются в адреса страниц -> менеджер буферов. Единица обмена с диском – «дисковый блок» или страница. –> Менеджер хранения. Инструкции ОС или непосредственно контролера. Обработка транзакций Запросы группируются в транзакции – процессы, которые должны выполняться атомарно (atomically) и изолированно (in isolation) друг от друга. Часто – один запрос – отдельная транзакция. Устойчивость (durability). Процессор транзакций = планировщик заданий (scheduler) + менеджер протоколирования и восстановления (logging and recovery manager). Менеджер буферов и хранения данных Кластеры 4К или 16К –> страничные блоки в оперативной памяти. Данные: 1. Данные 2. Метаданные 3. Статистика 4. индексы Обработка транзакций команды транзакций определяются логикой работы приложения протоколирование управление параллельными заданиями. Признаки блокировок ресурсов, которые запрещают обращаться к заблокированным ресурсам. разрешение взаимоблокировок (deadlock resolution) ACID: свойства транзакций A – atomicity (Атомарность) I – isolation (изолированность) D – durability (устойчивость) С – consistency (согласованность) процессор запросов (query processor) Компилятор запросов Синтаксический анализ (query parser) Препроцессор (query preprocessor) – проверка на существование объектов Оптимизатор (query optimizer). Статистика и метаданные. Исполняющая машина 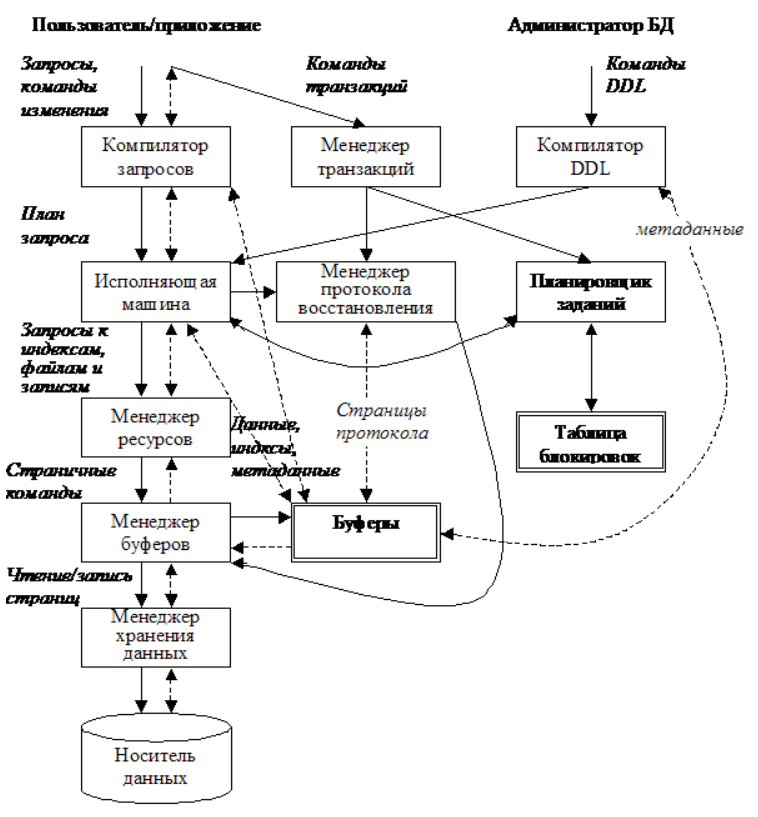 6. Формализация понятий. Проблема отсутствующих данных довольно часто встречается в реальной жизни. Например, в исторических записях встречаются такие записи, как «Дата рождения неизвестна»; в повестке дня собрания часто докладчик «указан» в виде «Будет объявлен»; милицейские доклады могут включать такие записи, как «номер автомобиля неизвестен». Для решения проблемы представления отсутствующих данных был предложен подход, основанный на использовании специального маркера, соответствующего понятию неопределенных значений и называемого null-значением (будем произносить «нул-значение»). В различных источниках на неопределенное значение, то есть на null-значение, часто ссылаются как на «пустое значение» или «нулевое значение». Однако нулевое значение, то есть число 0 – это пустое значение для числовых типов данных, а понятия пустого и неопределенного значений принципиально различаются. Поэтому необходимо обращать внимание на контекст употребления этих терминов. Вначале рассмотрим понятие пустого значения. Пустое значение – это просто одно из возможных значений определенного типа данных, названное пустым. Естественными пустыми значениями, например, являются • 0 – нулевое значение для числовых типов данных, • false для логического типа данных, • ′′ – пустая строка символов для строк символов переменной длины, • строка из пробелов, знаков табуляции и других неотображаемых символов для строк символов постоянной длины. Не всем типам данных можно естественным образом сопоставить пустое значение. Например, какое значение можно назвать пустым для данных типа даты, если в СУБД поддерживается диапазон представления дат от 01.01.0100 до 31.12.9999? В некоторых СУБД в подобных случаях вводится специальное обозначение для константы пустого значения. Так, например, для пустого значения даты может вводиться специальное обозначение {..}, а непустые константы представляться в формате {ДД.ММ.ГГГГ}. Если понятие пустого значения введено для всех типов данных, поддерживаемых СУБД, то тогда появляется возможность использования оператора вставки в таблицу строки пустых значений: insert into имя_таблицы blank Однако в SQL-ориентированных СУБД для подобных целей используется оператор вставки в таблицу строки значений по умолчанию: insert into имя_таблицы default values Значения по умолчанию задаются для каждого столбца при создании таблицы. В частности, в качестве значения по умолчанию можно задать и пустое значение. Поэтому единственная цель, с которой выше вводилось понятие пустого значения – это показать отличие понятия пустого значения от понятия неопределенного значения. 7. Неопределенные значения, интерпретации и свойства. Для маркировки неопределенных значений используется специальное зарезервированное ключевое слово null. Null-значение может быть присвоено переменной любого типа (числового, логического, строкового, даты, даты и времени и т.д.). 2.1. Интерпретации Null-значения допускают следующие интерпретации: 1) значение неизвестно (пока), 2) значение неприменимо. Рассмотрим пример (табл. 2.1). Таблица 2.1.: Интерпретации null-значения  Null-значение номера паспорта в 1-ом случае интерпретируется как неизвестное, поскольку речь идет о гражданине, которому уже есть 14 лет. Во 2-ом случае значение номера паспорта интерпретируется как неприменимое (до тех пор, пока текущая дата рассмотрения этих данных не будет соответствовать 14-летнему возрасту). В 3-ем случае неясно, какую можно дать интерпретацию null-значению номера паспорта, поскольку год рождения имеет null-значение (интерпретируемое как неизвестное). Кроме того, с течением времени интерпретация null-значения номера паспорта во 2-ом случае изменится. Таким образом, интерпретация null-значений существенно зависит от семантики данных. Правила вычисления выражений с null-значениями, реализованные в СУБД, следует рассматривать лишь как правила, действующие в системе по умолчанию. 8. Основные унарные и бинарные операции. Свойства операций(свойств вроде бы нет) Реляционная алгебра – это частная разновидность алгебр, в которой операндами являются отношения (в смысле реляционной модели данных). В реляционной алгебре выделяются унарные и бинарные операции. |