Интеллектуальные системы. РЕФЕРАТ. Графические процессоры (gpu)
 Скачать 183.01 Kb. Скачать 183.01 Kb.
|

|
РЕФЕРАТ Тема: «Графические процессоры (GPU)» Выполнил студент: Воля Алексей Александрович 2022 Введение Что такое графический процессор? GPU (аббревиатура с английского термина graphics processing unit) — компонент компьютера, игровой консоли, планшета или смартфона, который предназначен для рендеринга графики, то есть преобразует код в изображение, преимущественно 3D. Массовое применение таких девайсов началось с 2000 года. До этого и разработчики, и пользователи обходились возможностями центрального процессора: игры и программы были слишком примитивны, чтобы задействовать дополнительный компонент. Отрисовка нескольких пикселей, какими и были первые игры и графические редакторы, не требует большой вычислительной мощности. Графический процессор (GPU) — разновидность микропроцессора. В отличие от центрального процессора (CPU), в нем не десятки, а тысячи ядер. Из-за такой архитектуры у графических процессоров есть несколько особенностей: Они могут параллельно выполнять одни и те же операции над целым массивом данных, например, одновременно вычитать или складывать сразу много чисел. В отличие от центральных процессоров, у GPU меньше точность вычислений, но ее достаточно для таких задач, как машинное обучение, где важнее высокая скорость. Графические процессоры энергоэффективны. Например, один сервер, оснащенный GPU Nvidia Tesla V100, потребляет 13 кВт и обеспечивает такую же производительность, что и 30 серверов с центральными процессорами. То есть, используя графические процессоры, можно меньше платить за электроэнергию. Графические процессоры оснащены не только компьютерами, но и консолями, смартфонами и планшетами. По сути, любое устройство, способное отображать трехмерную графику на экране, скорее всего, будет иметь какой-то графический процессор. Что делает графический процессор? Что такое iGPU? Есть два типа графических процессоров. Первый — это iGPU (интегрированный графический процессор), который представляет собой графический процессор, встроенный в процессор. Как правило, они не очень мощные и предназначены для основных задач рендеринга, а не для игр и 3D-анимации. Тем не менее, AMD и Intel в последние годы улучшают свои iGPU, чтобы повысить производительность для требовательных рабочих нагрузок. Если вы покупаете настольный процессор без видеокарты, то стоит убедиться, что он действительно оснащен встроенным графическим процессором, так как это не всегда так. Что такое dGPU? Второй тип графического процессора — это dGPU (блок обработки дискретной графики). Это компонент, который находится внутри видеокарты для настольных систем или в качестве специального чипа в ноутбуках высокого класса. Дискретный графический процессор обычно значительно мощнее, чем iGPU, и специализируется на рендеринге расширенной графики для игр и создания контента. Если вам нужен игровой ПК, вам необходим мощный dGPU. Они также могут поддерживать такую технологию, как трассировка лучей, которая обеспечивает расширенные эффекты освещения и теней для большей реалистичности. AMD и Nvidia в настоящее время являются основными поставщиками dGPU, но Intel также выпустила собственный графический процессор Xe Max (находится внутри Acer Swift 3X ) и планирует выпустить больше в будущем. Однако у дискретных графических процессоров есть загвоздка, поскольку им требуется специальная система охлаждения, чтобы максимизировать производительность и предотвратить ее перегрев. К сожалению, это означает, что игровые ноутбуки обычно намного тяжелее стандартных ноутбуков только с iGPU. Дискретные графические процессоры также имеют высокое энергопотребление, что значительно сокращает время автономной работы. Дискретные графические процессоры также повышают стоимость ноутбука, в то время как высокопроизводительные настольные графические процессоры обычно являются самым дорогим компонентом при сборке ПК — самая дешевая видеокарта в последней серии 30 от Nvidia стоит 299 фунтов стерлингов / 329 долларов. Из-за этого дискретный графический процессор рекомендуется только в том случае, если он вам нужен, например, для игр, создания контента или других интенсивных рабочих нагрузок. Современная видеокарта состоит из следующих частей: Графический процессор (Graphics processing unit (GPU) — графическое процессорное устройство) занимается расчётами выводимого изображения, освобождая от этой обязанности центральный процессор, производит расчёты для обработки команд трёхмерной графики. Является основой графической платы, именно от него зависят быстродействие и возможности всего устройства. Современные графические процессоры по сложности мало чем уступают центральному процессору компьютера, и зачастую превосходят его как по числу транзисторов, так и по вычислительной мощности, благодаря большому числу универсальных вычислительных блоков. Однако, архитектура GPU прошлого поколения обычно предполагает наличие нескольких блоков обработки информации, а именно: блок обработки 2D-графики, блок обработки 3D-графики, в свою очередь, обычно разделяющийся на геометрическое ядро (плюс кэш вершин) и блок растеризации (плюс кэш текстур) и др. Акселератор на базе GPU представляет собой набор вычислительных узлов (мультипроцессоров), состоящих из некоторого числа арифметико-логических устройств (АЛУ). Он имеет SIMD-архитектуру. Иначе говоря, в любой момент времени все АЛУ одного мультипроцессора выполняют одинаковую последовательность инструкций над разными наборами данных, расположенных в памяти GPU-устройства. В качестве примера далее рассматривается акселератор nVidia GeForce 8800 GTX, который имеет 16 мультипроцессоров, по 8 АЛУ в каждом. Поскольку в SIMD-устройствах каждый мультипроцессор конфигурируется определенным образом для выполнения заданной последовательности команд на множестве входных данных, то перед разработчиком стоит задача формирования последовательности инструкций, решающей поставленную задачу, конфигурации устройства и передачи в устройство потока входных данных. При использовании nVidia CUDA SDK, эта процедура выглядит следующим образом (рис. 1): разработчик описывает ядро (kernel), то есть процедуру, которая будет исполняться на GPU над потоком данных и при запуске ядра на GPU задает ему конфигурацию на основе описанной ниже иерархии. Каждый поток, физически выполняющийся на АЛУ мультипроцессора, исполняет инструкции, описанные в ядре. При этом, благодаря SIMD-архитектуре, на каждом мультипроцессоре несколько потоков параллельно выполняют одну и ту же последовательность инструкций. Логически потоки объединяются в блоки, ограничивающие возможность обмена данными между потоками. Потоки могут обмениваться данными через общую память только внутри одного блока. Кроме того, потоки из одного блока выполняются на одном и том же мультипроцессоре. Таким образом, перед запуском ядра разработчик задает его конфигурацию (grid): размер блока и общее число блоков. Для более удобного структурирования конкретных задач в CUDA предусмотрена возможность конфигурирования блоков и потоков в двумерные сетки. Данная возможность обеспечивает удобство при обработке данных, имеющих двумерную структуру: изображений, матриц и пр. Отметим так же еще один важный структурный элемент конфигурации ядра – основу (warp). Под основой (в терминологии nVidia) подразумевается набор потоков, инструкции которых выполняются на мультипроцессоре одновременно. Размер основы определяется архитектурой конкретного GPU-устройства и размер блока, определяемый при конфигурировании ядра должен быть пропорционален размеру основы. Ключевым моментом отображения вычислительного алгоритма на GPU-архитектуру является определение ядра, соответствующего решению поставленной задачи. При этом следует учитывать, что каждый из потоков, исполняющих код ядра, для получения входных данных должен обращаться к своей области памяти устройства. На рис. 2 представлена общая схема преобразования последовательного циклического алгоритма в его GPU-реализацию. При исполнении на CPU-системе алгоритм многократно последовательно вычисляет некоторую функцию на различных наборах данных . При исполнении на GPU указанная функция преобразуется к виду , удобному для исполнения в рамках одного потока и затем вычисляется на GPU параллельно, на разных наборах данных. Разумеется, данный подход является эффективным лишь в том случае, когда итерации цикла, вычисляющего независимы. Заметим также, что при описании вычислительного ядра необходимо учитывать ряд важных особенностей работы GPU-устройств. Во-первых, SIMD-архитектура накладывает ограничения на использование ветвящихся конструкций (if/else). Это связано с тем, что потоки, исполняющиеся на одном и том же мультипроцессоре, должны оперировать одной и той же последовательностью инструкций, что может нарушаться при несовпадении условий ветвления у разных потоков. При нарушении этого ограничения может происходить сильное ухудшение производительности. Во-вторых, следует учитывать особенности работы GPU-устройств с памятью: определение ядра таким образом, чтобы одновременно выполняющиеся потоки читали данные из соседних участков памяти, существенно увеличивает производительность. Кроме того, необходимо учитывать трудоемкость обращения к памяти GPU-устройства: например, чтение из памяти для акселераторов nVidia занимает 400-600 тактов, тогда как операция сложения занимает всего 4 такта. В-третьих, следует учитывать архитектуру конкретного GPU-устройства, на котором выполняется вычислительная задача. Например, неэффективно задавать конфигурацию ядра с числом блоков меньшим числа мультипроцессоров, имеющимся на устройстве. Принцип работы · Порт соединения с материнской платой (AGP, PCI-E) для передачи данных и управления. · Процессор (GPU), чтобы решить, что сделать с каждым пикселем на экране. · Память (VRAM), чтобы держать информацию о каждом пикселе и временно хранить сформированные изображения. · Вывод на монитор (VGA, DVI), чтобы видеть окончательный результат обработки. Внутренняя модель nVidia GPU – ключевой момент в понимании GPGPU2 с использованием CUDA3. Вычислительная модель GPU: Рассмотрим вычислительную модель GPU более подробно. 1. Верхний уровень ядра GPU состоит из блоков, которые группируются в сетку или грид (grid) размерностью N1 * N2 * N3. Это можно изобразить следующим образом: Вычислительное устройство GPU. Размерность сетки блоков можно узнать с помощь функции cudaGetDeviceProperties, в полученной структуре за это отвечает поле maxGridSize. К примеру, на моей GeForce 9600M GS размерность сетки блоков: 65535*65535*1, то есть сетка блоков у меня двумерная (полученные данные удовлетворяют Compute Capability v.1.1). 2. Любой блок в свою очередь состоит из нитей (threads), которые являются непосредственными исполнителями вычислений. Нити в блоке сформированы в виде трехмерного массива (рис. 2), размерность которого так же можно узнать с помощью функции cudaGetDeviceProperties, за это отвечает поле maxThreadsDim. Параметры и характеристики Высокая вычислительная мощность GPU объясняется особенностями архитектуры. Если современные CPU содержат несколько ядер (на большинстве современных систем от 2 до 6, по состоянию на 2012 г.), графический процессор изначально создавался как многоядерная структура, в которой количество ядер может достигать сотен. Разница в архитектуре обусловливает и разницу в принципах работы. Если архитектура CPU предполагает последовательную обработку информации, то GPU исторически предназначался для обработки компьютерной графики, поэтому рассчитан на массивно параллельные вычисления. Каждая из этих двух архитектур имеет свои достоинства. CPU лучше работает с последовательными задачами. При большом объеме обрабатываемой информации очевидное преимущество имеет GPU. Условие только одно — в задаче должен наблюдаться параллелизм. Процитируем Джека Донгарра, директора Инновационной вычислительной лаборатории Университета штата Теннеси: "GPU уже достигли той точки развития, когда многие приложения реального мира могут с легкостью выполняться на них, причем быстрее, чем на многоядерных системах.Будущие вычислительные архитектуры станут гибридными системами с графическими процессорами, состоящими из параллельных ядер и работающими в связке с многоядерными CPU". Но как GPU достигли этой самой точки? Для ответа на данный вопрос рассмотрим историю развития устройств в области обработки графики. В конце 1980-х возникновение графических операционных систем семейства Windows дает толчок для появления процессоров нового типа. В начале 1990-х годов обрели популярность ускорители двумерной графики. Эти ускорители были спроектированы для операций с растровыми изображениями, тем самым, делая работу с графической операционной системой более комфортной. В те былые времена, когда видеоадаптеры, специализировались в основном на ускорении вывода 2D-графики. В то время считалось, что обработка трехмерных данных просто не целесообразна. Отметим, что данной тенденции не придерживалась компания Silicon Graphics, которая старалась вывести трехмерную графику на различные рынки, в том числе приложения для военных, правительства, эффекты в кино, визуализация научных данных. Результатом её трудов стало открытие данной компанией программного интерфейса к своему оборудованию. В 1992 году компания выпустила библиотеку OpenGL. Большой скачок в развитии графических ускорителей произошел в середине 90-х годов в ответ на возрастающее потребление вычислительных ресурсов компьютерными играми. Данные видеокарты являлись специализированными процессорами для ускорения операций с трехмерной графикой и предназначались для построения двумерных изображений трехмерных сцен в режиме реального времени. Для ускорения операций использовались аппаратная реализация алгоритмов, в том числе отсечения невидимых поверхностей при помощи буфера глубины, и аппаратное распараллеливание. Ускорители принимали на вход описание трехмерной сцены в виде массивов вершин и треугольников, а также параметры наблюдателя, и строили по ним на экране двумерное изображение сцены для этого наблюдателя. Поддерживалось отсечение невидимых граней, задание цвета вершин и интерполяционная закраска, а также текстуры объектов и вычисление освещенности без учета теней. Тени можно было добавить при помощи алгоритмов расчета теней на ускоритель, таких как теневые карты или теневые объемы. Из-за увеличения спроса на трехмерную графику и взаимной конкуренции такие компании NVIDIA, ATI Technologies, 3dfx Interactive, начали выпускать доступные по цене графические ускорители. Данный факт закрепил за трехмерной графикой ведущее место на рынке перспективных технологий. Сам термин GPU впервые был использован в августе 1999 года в отношении главного чипа видеокарты модели nVidia GeForce 256, основная функция которого заключалась в ускорении вывода трехмерной графики. Впервые вычисление геометрических преобразований и освещения сцены стало возможно проводить на самом графическом процессоре. Дальнейший прорыв принадлежит также компании NVIDIA, которая выпустила серия GeForce 3 в 2001 году. В данной серии появилась микросхема, в которой был реализован всем известный ныне, а тогда еще новый стандарт Microsoft DirectX 8.0. Данный стандарт добавил возможности программирования к GPU. Изначально фиксированный алгоритм вычисления освещенности и преобразования координат вершин был заменен на алгоритм, задаваемый пользователем. Затем появилась возможность писать программы для вычисления цвета пиксела на экране. По этой причине программы для GPU стали называть шейдерами12, от английского shade — закрашивать. Первые шейдеры писались на ассемблере GPU, их длина не превосходила20 команд, не было поддержки команд переходов, а вычисления производились в формате с фиксированной точкой. По мере роста популярности использования шейдеров появлялись высокоуровневые шейдерные языки, например, Cg от NVidia и HLSL от Microsoft, увеличивалась максимальная длина шейдера. В 2003 году на GPU впервые появилась поддержка вычислений с 32-разрядной точностью. В качестве основного интерфейса программирования выделился Direct3D,первым обеспечивший поддержку шейдеров. Обозначились основные производители дискретных графических процессоров: компании ATI и NVidia. Появились первые приложения, использующие GPUдля высокопроизводительных вычислений, начало складываться направление GPGPU. GPGPU (General-Purpose computing on Graphic Processing Units) — использование графических процессоров для решения произвольных вычислительных задач. Для программирования GPU предложен подход потокового программирования13. Дальнейшее развитие GPU характеризуются расширенными возможностями программирования. Появляются операции ветвления и циклов, что позволяет создавать более сложные шейдеры. Поддержка32-битных вычислений с плавающей точкой становится повсеместной, что способствует активному росту направления GPGPU. OpenGL в версии 2.0добавляет поддержку высокоуровневого шейдерного языка GLSL.Производительность GPU на реальных задачах достигает сотен гигафлопс. В более поздних представителях третьего поколения появляется поддержка целочисленных операций, а также операций с двойной точностью. Появляются специализированные средства,позволяющее взаимодействовать с GPU напрямую, минуя уровень интерфейса программирования трехмерной графики (CUDA NVIDIA, CTM ATI). Свободные таблицы сравнений Сравнение пиковой производительности систем на CPU и GPU Потоки GPU обладают крайне небольшой стоимостью создания, управления и уничтожения (контекст нити минимален, все регистры распределены заранее), для эффективной загрузки GPUСвободные таблицы сравнений 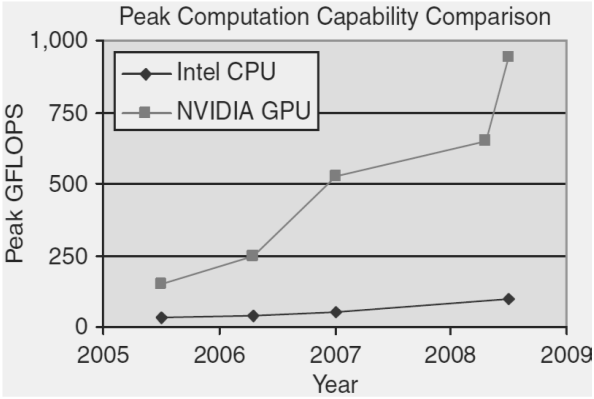 Потоки GPU обладают крайне небольшой стоимостью создания, управления и уничтожения (контекст нити минимален, все регистры распределены заранее), для эффективной загрузки GPU необходимо использовать много тысяч потоков, в то время как для CPU обычно использует 10-20 потоков. За счѐт того, что программы в CUDA пишутся фактически на обычном языке C (на самом деле для частей, выполняющихся на CPU, можно использовать C++), в который добавлены новые конструкции (спецификаторы типа, встроенные переменные и типы, директива запуска ядра), написание программ с использованием технологии CUDA оказывается заметно проще, чем при использовании графического API. 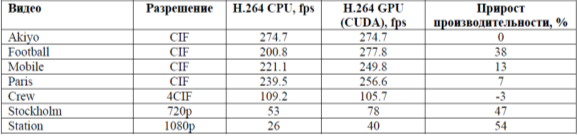 Разработчики софта для сжатия видео с GPU отмечают, что для того, чтобы получить ощутимую прибавку в производительности, надо производить сжатие видео формата не ниже 720p на машине с мощными как CPU, так и GPU. Отсюда следует, что применение GPU целесообразно для видео высокого разрешения. Действительно, для сжатия видео небольшого разрешения вполне можно использовать кодеры без применения GPU. Наличие B-кадров в настройках кодера CPU приводит к снижению производительности, нетипично большая область поиска макроблоков для межкадровой компенсации движения, также приводит к снижению производительности, обычно это значение гораздо меньше, в популярной реализации кодера стандарта H.264 x264 значение по умолчанию для этого параметра 16. Наибольшее значение этого параметра для кодера с CUDA не так критично. Для GPU задачи такого плана являются типичными, так как легко распараллеливаются. При использовании мощных ПК можно сжимать в реальном времени видео с разрешением до 720p. Стоит отметить, что кодер с использованием GPU с включенными B-кадрами на мощных РС всегда работает быстрее, чем с выключенными B-кадрами. Из табл. 2 видно, что качество декодированного видео при использовании B-кадров зачастую падает. Таблица 2. Сравнение качества декодированного видео сжатого разными кодерами. 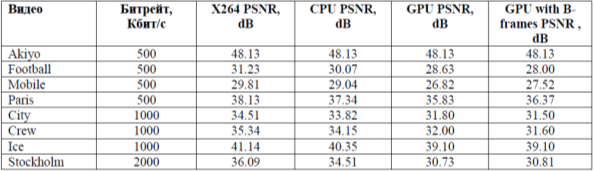 На основании проведѐнных тестов можно утверждать, что видеокодер с использованием GPU пока не показал своих преимуществ перед кодером без GPU. Имеющиеся реализации кодеров с GPU проигрывают кодерам без GPU в качестве декодированного видео. При этом прирост производительности при использовании GPU не столь ощутим и составляет единицы или десятки процентов (в зависимости от контекста видео и его разрешения). Когда графические процессоры (GPU) только появились, никто и не думал, что со временем их станут так широко применять. Изначально графические процессоры использовали для отрисовки пикселей в графике, а их основным преимуществом была энергоэффективность. Никто не пытался использовать GPU для вычислений: они не способны обеспечить такую же точность, как центральные процессоры (CPU). Но затем оказалось, что точность вычислений на графических процессорах вполне приемлема для машинного обучения. При этом GPU способны быстро обрабатывать большие объемы данных. Так что сегодня их применяют в разных сферах, о самых интересных рассказываем в статье. В подготовке статьи нам помогли эксперты Академии больших данных MADE от VK. Кстати, у них открыт набор на бесплатное обучение, где в том числе учат работать с GPU. Что такое графические процессоры (GPU) GPU и машинное обучение Графические процессоры применяют на всех этапах машинного обучения — при подготовке данных, тренировке моделей машинного обучения и их промышленной эксплуатации. Последние поколения графических процессоров от NVIDIA содержат тензорные ядра — новый тип вычислительных ядер. По сравнению с классическими GPU они выполняют меньше операций за единицу времени, но еще более энергоэффективны. Это важно для крупных компаний с собственными дата-центрами. Сегодня машинное обучение используют в различных отраслях, например в медицине. Решения на базе ИИ проверяют КТ- и МРТ-снимки и находят на них патологические изменения. В итоге врачи тратят меньше времени на работу со снимками, а риск человеческой ошибки снижается. «Цельс» — ИИ-платформа для анализа медицинских изображений, она обрабатывает поступающие из больниц снимки. Например, на КТ-снимках легких система способна распознать злокачественные новообразования и COVID-19. Обработка одного исследования занимает 60 секунд, точность выявления патологии — 95%. «Цельс» обнаружил новообразования в молочной железе. Источник Машинное обучение лежит в основе и компьютерного зрения — нейросети, которая умеет распознавать людей и объекты на фотографиях и видео. Например, компьютерное зрение внедрили в «Инвитро» для решения проблемы очередей. Сотруднику регистратуры требуется время на поиск карточки пациента в базе данных — пока он ищет, очередь увеличивается. Чтобы сократить время ожидания, на входе в клинику пациента снимает камера видеонаблюдения. Она передает изображение в систему, где компьютерное зрение распознает его личность и заранее открывает для регистратора нужную карточку. В итоге пациенты меньше ждут в очередях, а их лояльность возрастает. Подобные технологии лежат и в основе Valossa AI. Компания предоставляет различные ИИ-решения для работы с изображениями и видео. В частности, нейросети способны обнаруживать в видео нежелательный контент, чтобы его удалить, или распознавать эмоции людей. Функцию распознавания эмоций, например, использовали в шоу финской телекомпании Yle. По правилам, его участники слушали шутки, стараясь сохранить нейтральное выражение лица. ИИ оценивал, насколько им это удалось. ИИ определил, что на стоянке 35 грузовиков. Источник GPU и обработка изображений GPU изначально разрабатывали для работы с графикой. Так что сегодня их используют в системах, которые обрабатывают большие массивы изображений, например снимки из космоса. Такие снимки в том числе используют, чтобы следить за состоянием лесов или развитием половодья. Но в исходном виде в снимках невозможно разобраться, поэтому их предварительно обрабатывают: убирают все лишнее и наносят определенную разметку — GPU помогают ускорить этот процесс. «Банк базовых продуктов» Роскосмоса предоставляет другим ведомствам и ученым снимки с космических аппаратов. Используя их, оценивают качество поверхностных вод, состояние лесов, следят за пожарной обстановкой и паводками. Чтобы на снимках можно было легко найти нужную информацию, система предварительно их обрабатывает. На обработанном снимке черным цветом отмечено русло реки, синим — зоны подтоплений. Источник GPU и рендеринг графики С каждым годом фильмы и мультфильмы, созданные с помощью компьютерной графики, выглядят все реалистичнее. Это достигается с помощью рендеринга — процесса визуализации. Чтобы компьютерная графика выглядела на экране естественно, современные программы для рендеринга учитывают множество деталей — например, как падает свет и выглядят тени. Это требует больших вычислительных мощностей, так что крупные студии, как правило, используют графические процессоры. Для мультфильма «Город героев» в Walt Disney использовали Hyperion — симулятор глобального освещения, который создавали около двух лет. Он производит сложные вычисления, чтобы рассчитать, как будет выглядеть непрямой свет, многократно отраженный от всех поверхностей. Для отрисовки «Города героев» расчеты проводились с помощью кластера, состоящего из 55 000 вычислительных ядер. В мультфильме «Город героев» 83 000 зданий, 260 000 деревьев, 215 000 уличных фонарей и 100 000 автомобилей. Источник Еще графические процессоры применяют в KVM — специальных программах для геймеров, например, к ним относится Playkey. Они позволяют запускать игры с хорошей графикой на маломощных компьютерах за счет переноса нагрузки в облако. Так что мощный компьютер не требуется. GPU и тяжелые вычисления Тяжелыми называют вычисления, в которых задействованы сложные алгоритмы, из-за чего они потребляют большое количество ресурсов. Пример таких вычислений — докинг. Это метод молекулярного моделирования, он позволяет подобрать молекулу, которая лучше всего взаимодействует с нужным белком. Это трудоемкая и дорогая работа, например, в США на разработку одного нового лекарства уходит в среднем 985 млн долларов. Используя графические процессоры, фармкомпании экономят на вычислительных мощностях, ускоряют разработку и за счет этого тратят меньше денег. В начале пандемии ученые из Московского государственного университета стали искать вещества, которые могут оказаться полезными для лечения коронавируса. Чтобы найти лекарство, они подобрали перспективный белок, проанализировали его структуру и создали модели для докинга. Молекулярное моделирование запустили на суперкомпьютере «Ломоносов». Другой пример тяжелых вычислений — анализ большого количества разнородных данных. Например, он требуется при обработке сейсмографических данных. В регионах, где давно добывают нефть, стандартные методы сейсморазведки уже не справляются с поиском залежей в нужных объемах. Так, например, случилось в Башкортостане, где первая скважина появилась еще в 1930-х годах. Поэтому для разведки нефтяных запасов в ООО НПЦ «Геостра» использовали облачные решения. Расчеты велись на платформе VK Cloud Solutions (бывш. MCS). Для сложных расчетов использовали графические процессоры NVIDIA Tesla V100. Пилотный проект оказался успешным: удалось спрогнозировать эффективность будущих скважин и определить места для бурения. GPU и промышленный интернет вещей На промышленных предприятиях умные датчики собирают данные о работе оборудования и передают их в аналитическую систему. Используя эту информацию, компании могут следить за работой оборудования, предсказывать поломки, планировать профилактические работы и думать над оптимизацией производства. Для того чтобы данные обрабатывались быстрее, используют графические процессоры. Например, WaveAccess на базе VK IoT Platform разработала решения для Единой платформы сбора и анализа данных, с помощью которой государство контролирует природопользование. Всего решений четыре: система мониторинга воздуха, дистанционного надзора за объектами культурного наследия, незаконной вырубкой лесов и зарастания сельхозземель. Платформа собирает данные с помощью датчиков IoT и выявляет инциденты в режиме реального времени. На основании этих данных государственные органы проводят проверки. Еще решения в области интернета вещей используют для создания цифровых двойников — виртуальных копий станков или целых заводов. В таком случае система не просто анализирует данные с умных датчиков, а строит на их основе трехмерную модель оборудования. Фактически инженеры на компьютере видят, как работает тот или иной станок. На передачу и обработку данных требуется время. Поэтому на предприятиях, которым важно узнавать о неполадках в режиме реального времени, для ускорения работы используют графические процессоры. Например, благодаря цифровому двойнику Московской ТЭЦ-20 удалось повысить эффективность работы предприятия на 4%. Другой пример — виртуальный прототип завода КАМАЗ, где оцифровали почти 50 станков, а также манипуляторы, производственные роботы и другое оборудования. Благодаря этому на предприятии могут контролировать все этапы сборки автомобилей. На заводе Siemens в Амберге выпускают 12 млн программируемых логических контроллеров в год, то есть одно изделие в секунду. На предприятии объединили виртуальное и реальное производство: на изделия нанесены коды, которые передают оборудованию его маршрут и требования к каждой операции — за процессом следят специальные программы. В итоге новые заказы на заводе выполняются за сутки, 99,99885% выпускаемой продукции полностью соответствует стандартам качества, а себестоимость снизилась на 25%. Сверхмощные вычисления в облаке Чтобы повысить скорость вычислений, необязательно закупать графические процессоры — мощности можно арендовать у облачного провайдера. У GPU в облаке есть несколько особенностей: Быстрое подключение мощностей. Не нужно ждать поставок оборудования, провайдер подключает графические процессоры по запросу. Возможность аренды на короткий срок. Если вам требуется разово произвести сложные вычисления, то вы можете подключить GPU только на это время, а затем сразу отключить. На платформе VK Cloud Solutions (бывш. MCS) к виртуальным машинам можно подключить графические процессоры NVIDIA Tesla V100. Это одно из последних поколений GPU, в каждом процессоре 640 тензорных ядер. К нужной виртуальной машине графические процессоры подключают по запросу, для этого нужно обратиться в техподдержку. На платформе есть и другие решения для машинного обучения и работы с большими данными. Используя их, можно построить в облаке собственную аналитическую систему или решение для тренировки нейросетей. Что нужно знать о графических процессорах Графические процессоры — разновидность микропроцессоров, которые содержат тысячи вычислительных ядер. Они быстро производят сложные расчеты, но потребляют меньше энергии, чем центральные процессоры. Сегодня GPU применяют в машинном обучении, обработке изображений, молекулярном моделировании и других сферах. Необязательно покупать графические процессоры, мощности с GPU можно арендовать у облачного провайдера. Графический процессор (англ. graphics processing unit, GPU) - отдельное устройство персонального компьютера или игровой приставки, выполняющее графический рендеринг Графические процессоры (GPU) по сложности абсолютно не уступают центральным процессорам, но из-за своей узкой специализации, в состоянии более эффективно справляться с задачей обработки графики, построением изображения, с последующим выводом его на монитор. Если говорить о параметрах, то они у графических процессоров весьма схожи с центральными процессорами. Это уже известные всем параметры, такие как микроархитектура процессора, тактовая частота работы ядра, техпроцесс производства. Но у них имеются и довольно специфические характеристики. Например, немаловажная характеристика графического процессора – это количество пиксельных конвейеров (Pixel Pipelines). Эта характеристика определяет количество обрабатываемых пикселей за один такт роботы GPU. Пиксельный конвейер занимается тем, что просчитывает каждый последующий пиксель очередного изображения, с учётом его особенностей. Для ускорения процесса просчёта используется несколько параллельно работающих конвейеров, которые просчитывают разные пиксели одного и того же изображения. Также, количество пиксельных конвейеров влияет на немаловажный параметр – скорость заполнение видеокарты. Скорость заполнения видеокарты можно рассчитать умножив частоту ядра на количество конвейеров. Помимо пиксельных конвейеров, различают ещё так называемых текстурные блоки в каждом конвейере. Чем больше текстурных блоков, тем больше текстур может быть наложено за один проход конвейера, что также влияет на общую производительность всей видеосистемы. Графический процессор от центрального отличает так же разница в архитектуре. Современные CPU содержат несколько ядер, тогда как графический процессор изначально создавался как многопоточная структура с множеством ядер. Разница в архитектуре обусловливает и разницу в принципах работы. Если архитектура CPU предполагает последовательную обработку информации, то GPU исторически предназначался для обработки компьютерной графики, поэтому рассчитан на массивно параллельные вычисления. Каждая из этих двух архитектур имеет свои достоинства. CPU лучше работает с последовательными задачами. При большом объёме обрабатываемой информации очевидное преимущество имеет GPU. Условие только одно - в задаче должен наблюдаться параллелизм. eGPU - Это понятие расшифровывается, как External Graphics Processing Untit. По-другому – внешняя видеокарта. Обычно, это может быть не конкретно графический адаптер, а внешний интерфейс, который совместим со множеством видеокарт Внешние графические процессоры иногда используются совместно с портативными компьютерами. Ноутбуки могут иметь большой объём оперативной памяти (RAM) и достаточно мощный центральный процессор (CPU), но часто им не хватает мощного графического процессора, вместо которого используется менее мощный, но более энергоэффективный встроенный графический чип. Встроенные графические чипы обычно недостаточно мощны для воспроизведения новейших игр или для других графически интенсивных задач, таких как редактирование видео. Поэтому желательно иметь возможность подключать графический процессор к некоторой внешней шине ноутбука. PCI Express - единственная шина, обычно используемая для этой цели. Порт может представлять собой, к примеру, порт ExpressCard или mPCIe (PCIe×1, до 5 или 2,5 Гбит / с соответственно) или порт Thunderbolt 1, 2 или 3 (PCIe×4, до 10, 20 или 40 Гбит / с соответственно). Эти порты доступны только для некоторых ноутбуков. Разработка eGPU не получила широкой поддержки от производителей, но пользовалась популярностью у пользователей ноутбуков. Особенности развития графических процессоров История современных 3D-акселераторов, предназначенных для домашнего, а не профессионального использования, всерьез началась с компании 3Dfx. Видеокарты на основе процессора Voodoo Graphics (он же Voodoo 1) производства 3Dfx появились в продаже в 1997 году и надолго сделали название производящей их компании синонимом слова 3D-акселератор. Платы на этом процессоре были видеоакселераторами в чистом виде, то есть для работы требовали уже установленной в системе видеокарты. Типичное рабочее разрешение для Voodoo I составляло 512х384 пикселов, максимальное – 640х480 при 16-битной глубине цвета, поддерживалось до 4 МБ видеопамяти. Поддержало репутацию 3Dfx и следующее поколение — Voodoo 2. Отличия были кардинальными: вдвое большее количество текстурных блоков, что позволяло использовать мультитекстурирование (наложение более одной текстуры за такт). Тактовые частоты чипов (на плате их было два) и памяти повысились. Размер видеопамяти увеличился до 8-12 Мбайт, что позволяло использовать большие разрешения. Впервые в истории появилась видеокарта, реализующая трилинейную фильтрацию. Конкуренцию 3Dfx составляла с самого начала присутствовавшая на этом рынке компания ATI, хотя ее первый процессор — Rage 3D — проигрывал Voodoo I. Но в 1999 году в продаже появились карты на базе чипа Rage 128 и Rage 128 PRO (они же Rage Fury и Rage Fury PRO). PRO представлял собой разогнанный вариант обычного Rage 128 (частоты 140/160 и 103/103 МГц соответственно). В них впервые появилась аппаратная поддержка MPEG-2. Еще один игрок на этом рынке — компания nVidia, начинавшая с весьма приличного процессора Riva128 и Riva128ZX, в 1999 году выпустила серьезный чипсет Riva TNT, в котором появилась поддержка шины AGP, 32-битного цвета, разрешения до 1920х1440 пикселов. А на процессорах TNT2 выпускался знаменитый видеоакселератор Creative 3DBlaster TNT2 Ultra. Заметными в истории графических процессоров были G400 производства Matrox, которые, хоть и несколько проигрывали в скорости 3D-графики, но сочетание с великолепным качеством обработки двухмерного изображения сделало карты на этом чипе очень популярными среди тех, кому нужны от компьютера не только игры. Оценена была и «двуголовость» некоторых карт на этом процессоре — он мог поддерживать 2 монитора. Видеокарты на следующей версии этого процессора, G400MAX, уже позиционировались как профессиональные, и потому стоили (и стоят до сих пор) очень недешево, а покупали их в основном профессионалы-полиграфисты и верстальщики, не признающие мониторов дешевле 1000 долларов и разрешений ниже 1600х1200. Термин GPU был впервые использован компанией nVidia в августе 1999 в отношении главного чипа видеокарты нового поколения GeForce 256. От предшествующих графических чипов его отличала поддержка технологии Transform&Lighting. Эта технология заключалась в преобразовании координат виртуальных трехмерных объектов в плоские координаты, отображаемые на мониторе, и вычислении освещенности этих объектов. Это очень ресурсоемкие и сложные вычисления, особенно при большом количестве объектов. Ранее они выполнялись на центральном процессоре, отнимая значительную часть процессорного времени, либо на отдельных процессорах освещения и трансформации. Поэтому, благодаря появлению графических процессоров, с одной стороны, с CPU снималась часть нагрузки, что позволяло использовать его для решения других задач. С другой стороны, появилась возможность увеличения количества объектов и степени их прорисовки, что позволило добиться нового уровня реалистичности в 3D-приложениях, особенно в компьютерных играх. Плата GeForce 256 была дорогой и непроизводительной на приложениях, которые не использовали возможностей аппаратного T&L, и по-прежнему пользовались услугами ЦП для ручных вычислений. Поэтому другие производители видеокарт, например, ATI, 3dfx Interactive, Matrox, не поддержали новой технологии и пророчили ей скорое забвение. Ситуация изменилась с выходом игр, поддерживающих аппаратно реализованную технологию T&L — Quake III Arena, Unreal Tournament и др. Ввиду неоспоримых преимуществ аппаратного T&L перед программным вскоре он стал де-факто стандартом при программировании трехмерных игр. Компания ATI выпустила платы Radeon с его поддержкой, а два других конкурента вынуждены были уйти с рынка игровых видеоадаптеров. Новым этапом в развитии графических процессоров стало появление пиксельных и вершинных шейдеров. Шейдеры представляют собой программы, написанные на языке, похожем на язык ассемблера, и позволяющие непосредственно управлять GPU, которые ранее не были программируемыми. Вершинные шейдеры позволяют определять параметры пикселя (освещенность, прозрачность, отражающую способность, координаты, текстуру и т.д.), исходя из параметров вершин треугольника, содержащего его. Пиксельные шейдеры позволяют работать с каждым пикселем индивидуально, уже после проведения геометрических преобразований. Поддержка программируемых шейдеров на аппаратном уровне впервые была реализована в 2000 году, в GPU nVidia GeForce 2 и ATI Radeon R100 (позднее переименован в Radeon 7200). Однако программная часть поддержки была плохо реализована. В результате, после согласования спецификаций, программируемые шейдеры стали поддерживаться DirectX 8.0, и первыми видеокартами, в которых можно было в полной мере пользоваться их преимуществами, стали видеокарты с чипами GeForce 3 и Radeon 8500. Дальнейшее развитие графических процессоров обоих производителей происходило эволюционным путем: увеличивались тактовые частоты, добавлялась поддержка новых шейдерных моделей, улучшались технологии фильтрования и сглаживания. Все это позволяло добиваться новых уровней реалистичности при прорисовке объемных сцен. На 2006 основными производителями графических процессоров для домашних ПК являются ATI Technologies и nVidia. Процессоры 2006 изготавливаются, как правило, по 130 или 90 нм технологии и работают на частоте 400-600 МГц. Список литературы · Дж. Ли, Б. Уэр. Трёхмерная графика и анимация. — 2-е изд. — М.: Вильямс, 2002. — 640 с. · Д. Херн, М. П. Бейкер. Компьютерная графика и стандарт OpenGL. — 3-е изд. — М., 2005. — 1168 с. · Э. Энджел. Интерактивная компьютерная графика. Вводный курс на базе OpenGL. — 2-е изд. — М.: Вильямс, 2001. — 592 с. · Г. Снук. 3D-ландшафты в реальном времени на C++ и DirectX 9. — 2-е изд. — М.: Кудиц-пресс, 2007. — 368 с. — ISBN 5-9579-0090-7 · В. П. Иванов, А. С. Батраков. Трёхмерная компьютерная графика / Под ред. Г. М. Полищука. — М.: Радио и связь, 1995. — 224 с. — ISBN 5-256-01204-5 · Скотт Мюллер. Модернизация и ремонт ПК = Upgrading and Repairing PCs. — 17 изд. — М.: «Вильямс», 2007. — С. 889—970. — ISBN 0-7897-3404-4 · Чобану М. Многомерные многоскоростные системы обработки сигналов. М.: ТЕХНОСФЕРА, 2009, 480 с. |