Лекция Управление данными. Управление данными Тема 1. Информационные системы и их виды
 Скачать 53.55 Kb. Скачать 53.55 Kb.
|

|
Управление данными Информационные системы и их видыИнформационная система (ИС) - это система, состоящая из персонала и комплекса средств автоматизации его деятельности, реализующих информационную технологию выполнения установленных функций (ГОСТ 34.003-90 Автоматизированные системы); система, которая организует хранение и манипулирование информацией о предметной области (ГОСТ 34.321-96 Информационные технологии); совокупность содержащейся в базах данных информации и обеспечивающих ее обработку информационных технологий и технических средств (ГОСТ Р 50922-2006 Защита информации); организационно упорядоченная совокупность документов и информационных технологий, в том числе с использованием средств вычислительной техники и связи, реализующих информационные процессы (ГОСТ Р 54089-2010 Интегрированная логистическая поддержка). Будем понимать под ИС систему для сбора, передачи, обработки, хранения и выдачи информации пользователям и состоящую из следующих основных компонентов: программное и информационное обеспечения, технические средства, обслуживающий персонал. ИС по характеру представления и логической организации информации делятся на: фактографические, документальные, геоинформационные. По функциям и решаемым задачам ИС делятся на справочные, поисковые, расчетные, технологические. База данных (БД) и система управления базой данных (СУБД)Сегодня ни одна ИС не обходится без базы данных и системы управления базой данных. База данных (БД) - именованная совокупность данных, отражающая состояние объектов и их отношений в рассматриваемой предметной области. Система управления базами данных (СУБД) - совокупность языковых и программных средств, предназначенных для создания, ведения и совместного использования БД многими пользователями. Первый этап развития СУБД связан с организацией баз данных на больших машинах типа IBM 360/370, ЕС-ЭВМ и др. В этот период базы данных хранились во внешней памяти центральной ЭВМ, задачи запускались в пакетном режиме, интерактивный режим доступа обеспечивался с помощью терминалов, программы доступа к БД писались на различных языках и запускались как обычные числовые программы, управление распределением ресурсов в основном осуществляются операционной системой (ОС).. Второй этап связан с эпохой персональных компьютеров, когда появились программы, которые назывались СУБД и позволяли хранить значительные объемы информации; все СУБД были рассчитаны на создание БД в основном с монопольным доступом. Третий этап связан с распространением компьютерных сетей. В этот период обеспечение поддержки полной реляционной модели большинство СУБД рассчитаны на много платформенную архитектуру, практически все СУБД имеют средства подключения клиентских приложений, разработанных с использованием настольных СУБД, и средства экспорта данных из форматов настольных СУБД второго этапа развития Четвертый этап характеризуется появлением новой технологии доступа к данным — интранет (технологии клиент-сервер), когда отпадает необходимость использования специализированного клиентского программного обеспечения и для работы с удаленной базой данных используется стандартный браузер Виды СУБДАмериканским комитетом по стандартизации ANSI (American National Standards Institute) предложена трехуровневая система организации СУБД: уровень внешних моделей (определяет отдельные приложения); концептуальный уровень (объединяет данные, используемые всеми приложениями и отражает обобщенную модель предметной области, для которой создавалась база данных); физический уровень (собственно данные, расположенные в файлах на внешних носителях информации). Такая организация обеспечивает логическую (возможность изменения одного приложения без корректировки других) и физическую (возможность переноса хранимой информации с одних носителей на другие при сохранении работоспособности всех приложений) независимость уровней СУБД По степени распределённости различают локальные СУБД (все части локальной СУБД размещаются на одном компьютере) серверные СУБД (файлы данных располагаются централизовано на сервере). В свою очередь серверные СУБД подразделяются на файл-серверные и клиент-серверные. Для файл-серверных характерно размещение данных на файл-сервере, а СУБД - на каждом клиентском компьютере, а доступ СУБД к данным осуществляется через локальную сеть. К преимуществам таких СУБД следует отнести низкую нагрузку на процессор файлового сервера, а к недостаткам: потенциально высокую загрузка локальной сети; затруднённость или невозможность централизованного управления данными; затруднённость или невозможность обеспечения таких характеристик как высокая надёжность, высокая доступность и высокая безопасность. Недостатки файл серверных систем становятся преимуществами клиент-серверных СУБД. В клиент-серверных на сервере вместе с БД располагается СУБД и доступ к данным осуществляется непосредственно в монопольном режиме. Все клиентские запросы обрабатываются СУБД централизованно. В этом случае предъявляются повышенные требования к серверу, но обеспечивается потенциально более низкая загрузка локальной сети; удобство централизованного управления данными; такие характеристики как высокая надёжность, высокая доступность и высокая безопасность. Примеры серверных СУБД - Oracle, IBM DB2, MS SQL Server, Sybase, My SQL Предметная область и ее описаниеПроектирование информационной системы, составным компонентом которой является база данных, начинается с анализа предметной области. Предметная область (ПО) – это область применения конкретной БД. Предметной областью может быть сфера управления предприятиями, транспорт, медицина, научные исследования и т.п. Прежде всего, должны быть определены границы предметной области и сформулирована главная цель проектирования базы данных. При определении границ ПО используют : подход «от реального мира», когда с помощью экспертов определяются границы ПО (состав объектов, их свойства и отношения с учетом существующего положения дел и развития системы); подход «от запросов пользователей», который широко используется для уточнения границ ПО и наибольшее применение получает в период использования ИС, когда накапливается достаточно информации о содержании запросов и необходимо выполнить коррекцию границ ПО и модели системы. Будем говорить, что предметная область БД определена, если известны существующие в ней объекты, их свойства и отношения (связи). Объект – это то, о чем должна накапливаться информация. Выбор объектов осуществляется в соответствии с целевым назначением. Объекты могут быть атомарными или составными, причем один и тот же объект может быть в одном приложении выступать как атомарный, в другом – как составной. Атомарный объект — объект определенного типа, дальнейшее разложение которого на более мелкие объекты в рамках данной предметной области невозможно. Составные объекты включают в себя множества объектов Каждый объект в конкретный момент времени характеризуется состоянием, которое описывается набором свойств и связей его с другими объектами. Свойства объекта могут не зависеть от его связей с другими объектами, то есть являются локальными, а могут и зависеть. В последнем случае они являются реляционными. Между объектами ПО могут существовать отношения подчиненности. Каждая связь (отношение) между объектами по числу входящих в нее объектов характеризуется степенью n=2.3, …, k (бинарная, териарная, …, k-арная). Чтобы отобразить объекты в информационную сферу, необходимо определить: какие объекты важны для данного применения; какие свойства могут иметь эти объекты; какие связи существуют между объектами; какие имена можно присвоить отдельным составляющим объектной системы. Таким образом, анализ предметной области позволяет определить ее границы и лежит в основе проектирования состава элементов информационной модели БД. Инфологическое моделированиеЦель инфологического проектирования -создание структурированной информационной модели предметной области, для которой разрабатывается БД. Определим требования к такой модели: обеспечение естественных для человека способов сбора и представления информации, которую предполагается хранить в создаваемой БД; адекватное отображение моделируемой предметной области (корректность схемы БД); простота и удобство использования на следующих этапах проектирования, то есть поддерживается известными СУБД (сетевые, иерархические, реляционные и др.); использование языка описания, понятного проектировщикам БД, программистам, администратору и будущим пользователям. Инфологическая модель выражает информацию о предметной области в виде, независимом от используемой СУБД. Ее называют также семантической, смысловой или концептуальной. На этапе инфологического моделирования базы данных широко используется модель «сущность-связь». Модель «сущность-связь» предложена в 1976 г Питером Пин-Шен Ченом американским профессором компьютерных наук. Составные элементы инфологической модели сущности, их атрибуты и связи между ними Сущность – некоторая абстракция реально существующего предмета, объекта, явления. Тип сущности – набор однородных личностей, предметов, событий или идей, выступающих как целое. Экземпляр сущности относится к конкретному объекту Атрибут – это поименованная характеристика сущности. Атрибуты используются для определения того, какая информация должна быть собрана о сущности, то есть для описания свойства сущности. Это следует из определения. Но атрибут также используется: для однозначной идентификации конкретного экземпляра сущности (ключ – минимальный набор атрибутов, по значениям которых можно однозначно найти требуемый экземпляр сущности); для представления связей между сущностями, характеризует те объекты между которыми существует связь (отношение). Связь – средство представления отношений между сущностями. Графическое представление модели «сущность-связь» носит название ER(Entity Relatioship) -диаграммы. Множества сущностей изображаются в виде прямоугольников, а множества отношений (связей) - в виде ромбов. Если сущность участвует в отношении, они связаны линией. Атрибуты изображаются в виде овалов и связываются линией с одним отношением или с одной сущностью (см.рисунок 1). 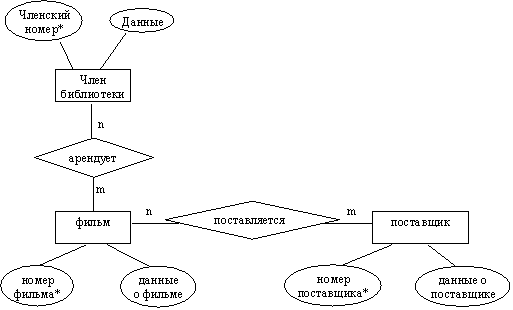 Рисунок 1 Даталогическое моделирование (иерархическая, сетевая, реляционная модели данных)Даталогическая модель разрабатывается на основе инфологической модели предметной области с учётом конкретной реализации СУБД. Существуют различные виды даталогических моделей - иерархическая, сетевая, реляционная. Иерархическая модель представляет данные в виде иерархии и ориентирована на описание объектов, находящихся между собой в отношении подчинения (см.рисунок 2). Иерархические модели представляются в форме графов – форме деревьев. Дерево – это связный граф, который не содержит циклов (корень дерева – вершина, в которую не заходит ни одно ребро). На верхнем уровне дерева в имеется один узел – “корень”, на следующем уровне располагаются узлы, связанные с этим корнем. Вершины графа – типы сущностей, а дуги – типы связей между сущностями. Поиск данных в иерархической системе всегда начинается с корня. Основные достоинства этой модели - простота описания иерархических структур реального мира и быстрое выполнение запросов, 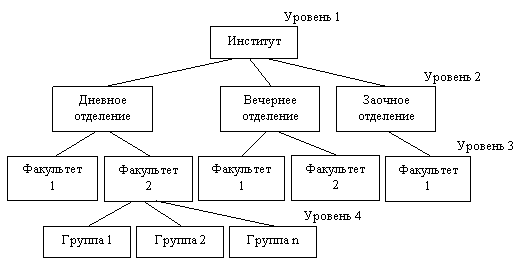 Рисунок 2 – Иерархическая модель Сетевая модель позволяет описывать более сложные виды взаимоотношений между данными, чем иерархическая, но расширение возможностей достигается за счет большей сложности реализации самой модели и трудности манипулирования данными. Эти модели данных широко применялась в 70-е годы в первых СУБД. Сетевая модель также использует графовую форму представления данных, но сетевой модели соответствует произвольный граф (возможно имеющий циклы и петли), см.рисунок 3. а)  б) 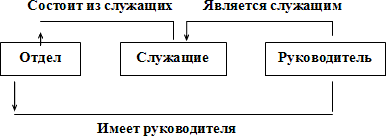 Рисунок 3 – Примеры сетевых моделей данных В узлах графа помещаются типы записей, а ребра интерпретируются как связи между типами записей, причем объект-потомок может иметь не одного, а любое количество объектов-предков. Кроме того, допускаются любые связи-отношения, в том числе и одноуровневые Сетевые модели не распространены из-за отсутствия языков, которые бы позволили в разных прикладных ИС одинаковым образом описывать данные сетевой организации. Реляционная база данных представляет собой хранилище данных, организованных в виде двумерных таблиц . Любая таблица реляционной базы данных состоит из строк (называемых записями) и столбцов (называемых полями). Строки таблицы содержат сведения о представленных в ней фактах (или документах, или людях, одним словом, об однотипных объектах). На пересечении столбца и строки находятся конкретные значения содержащихся в таблице данных. Данные в таблицах удовлетворяют следующим принципам: каждое значение на пересечении строки и столбца должно быть атомарным; значения данных в одном и том же столбце должны принадлежать к одному и тому же типу; каждая запись в таблице уникальна (не существует двух записей полностью совпадающих, что определяется ключом); каждое поле имеет уникальное имя ; последовательность полей в таблице несущественна; последовательность записей в таблице несущественна. Поле, указывающее на запись в другой таблице, связанную с данной записью, называется внешним ключом. Связь между двумя таблицами устанавливается путем присвоения значений внешнего ключа одной таблицы значениям первичного ключа другой. Достоинство реляционной модели данных заключается в простоте, понятности и удобстве физической реализации на ЭВМ. |