Методы анализа данных 2 практика. 2 практика. Исследование данных с помощью Sqoop для рсубд (MariaDB)
 Скачать 3.51 Mb. Скачать 3.51 Mb.
|

Исследование данных с помощью Sqoop для РСУБД (MariaDB)В этой практической работе вам предстоит импортировать и экспортировать таблицы из РСУБД в HDFS (Hadoop Distributed Filesystem), используя Sqoop. Импортирование таблицы в HDFS с использованием Sqoop. Начну с получения информации о базах данных и таблицах в них перед импортированием таблиц в HDFS. В терминале авторизуюсь в MariaDB и выберите базу данных labs.  Замечание: Если вы не введете ничего в качестве пароля (password), то он будет запрошен: $ mysql -u student -p labs Введите "student". Если авторизация прошла успешно, то приглашение для ввода сменится на "MariaDB [labs]>". Введите команду для проверки того, какие базы данных доступны. 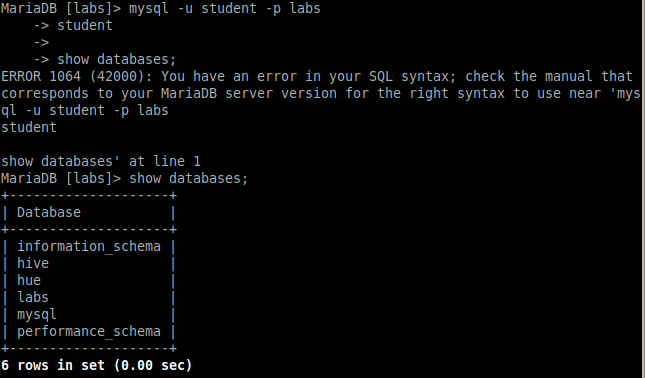 Рисунок 1. Список баз данных в MariaDB Затем введите команду для просмотра таблиц в базе labs: 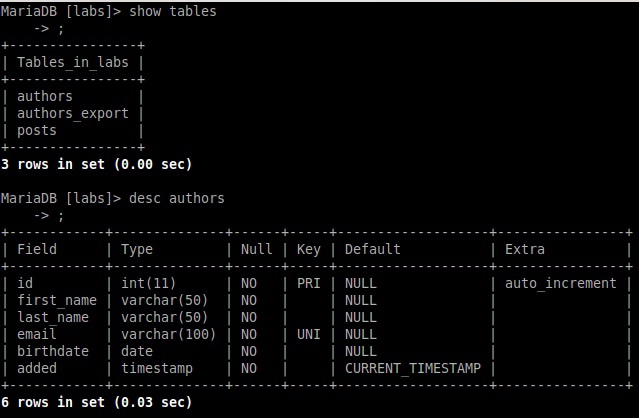 Рисунок 2. Список названий таблиц в БД labs На экране отображены таблицы authors и posts. Эти таблицы мы будем импортировать и экспортировать через команды Sqoop. Замечание: Команды desc и describe выполняют одно и то же. 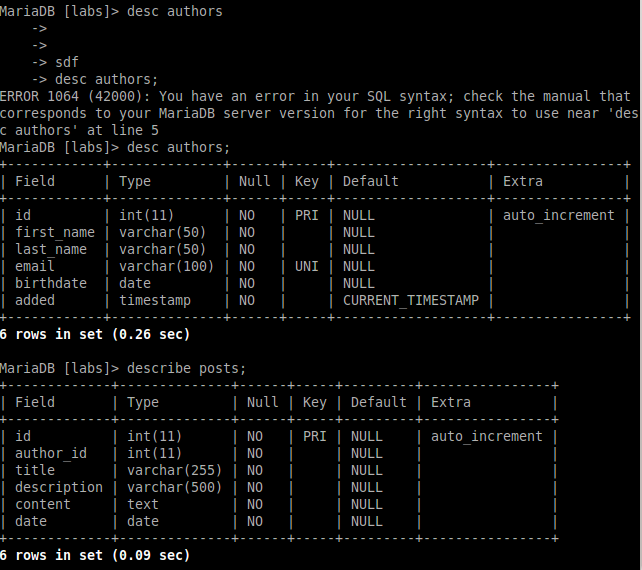 Рисунок 3. Структура таблиц authors и posts Посмотрим на структуру таблиц authors и post, а также на несколько записей оттуда. 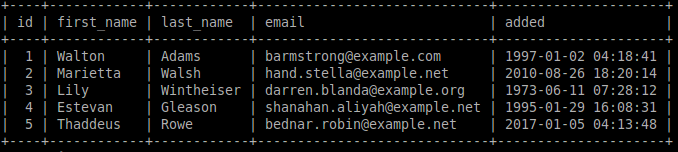 Для выхода из MariaDB напишите quit и нажмите Enter. Для получения помощи по базовым командам sqoop запустите следующую команду:  Для получения детализированной информации по каждой подкоманде, введите ее название после help. Например, для получения справки по команде import, выполните следующую команду:  Просмотр списка баз данных в MariaDB и таблиц в базе данных labs осуществляется следующей командой: Результат выполнения этой команды совпадает с тем, что мы видели на рисунке 1. Замечание: альтернативой использованию аргумента --password является использование ключа -P (заглавная буква) и ввод пароля при запросе. При этом вводимые символы будут невидимы. 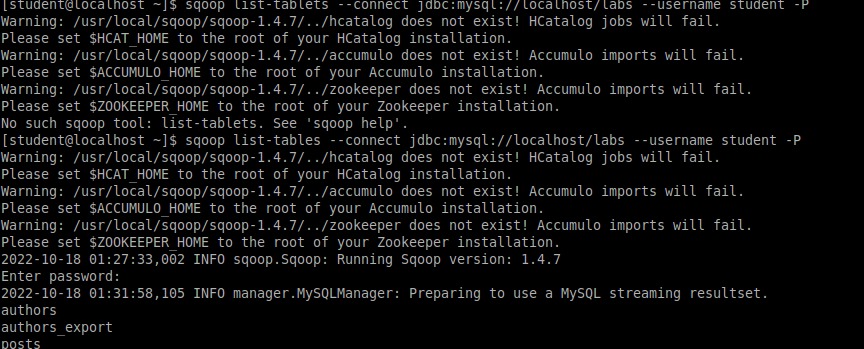 В результате выполнения этой команды будут выведены таблицы authors, aythors_export и posts. Импортируем все таблицы в базе labs используя команду import-all-tables.  Замечание: в Sqoop хоть и есть команда import-all-table, на практике она редко используется. Причина в том, что эта команда за раз выполняет много задач. Постарайтесь по возможности ее больше не использовать. В реальных средах обычно сотни баз данных с тысячами таблиц в каждой, поэтому используйте эту команду только для тестов. Обычно импортирование даже одной таблицы занимает много времени. В большинстве случаев используйте команду import. Выполните эту команду для получения таблицы posts из базы labs и сохранения последней в HDFS:   После выполнения этой команды создастся директория posts в домашней директории HDFS /user/student, а данные сохранятся как показано ниже:  Рисунок 4. Список постов в HDFS Создаем целевую директорию в HDFS для импортирования данных в нее. $hdfs dfs -mkdir /mywarehouse Импортируем таблицу authors и сохраняем ее в директорию HDFS, которую мы создали выше, используя ‘,’ для разделения полей. Замечание: аргумент --field-terminated-by ‘,’ используется для задания запятой в качестве разделителя полей в HDFS файле. Если вы хотите работать с Hive или Spark, то лучше использовать ‘\t’ вместо ‘,’. $ sqoop import --connect jdbc:mysql://localhost/labs \ --username student --password student \ --table authors --fields-terminated-by ',' \ --target-dir /mywarehouse/authors  Для проверки воспользуемся командой hdfs по целевой директории. $ hdfs dfs -ls /mywarehouse/authors $ hdfs dfs -cat /mywarehouse/authors/part-m-00000  Рисунок 5. Список файлов в /mywarehouse/authors Если запустить команду cat, вы сможете увидеть, что каждая строка данных отделена от соседней знаком ‘,’, что отличается от того, что было в файле posts (там были табуляции) в HDFS. Импортирование определенных столбцов осуществляется указанием аргумента --columns для папки authors в домашней директории HDFS. Импортируемые столбцы: first_name, last_name, email $ sqoop import --connect jdbc:mysql://localhost/labs --username student --password student --table authors --fields-terminated-by '\t' --columns "first_name, last_name, email" 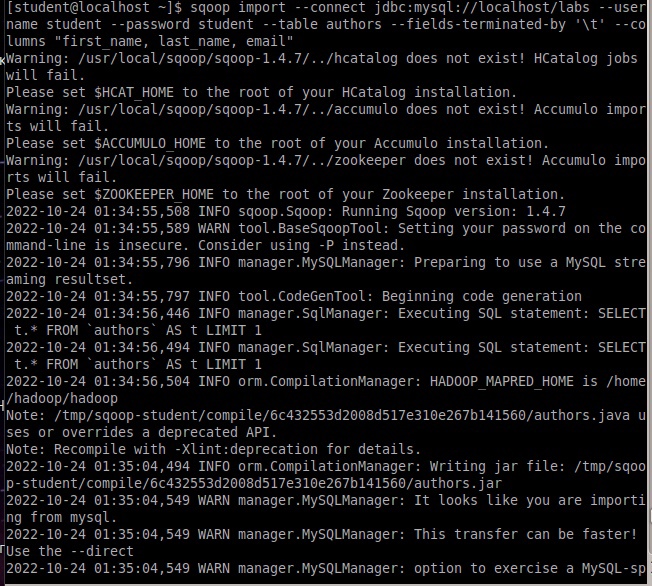 Рисунок 6. Результаты команды Sqoop Импортируем только подходящие строки с помощью --where. Для примера импортируем строки из таблицы authors, где first_name указано, как ‘Dorthy’. $ sqoop import --connect jdbc:mysql://localhost/test --username student --password student --table authors --fields-terminated-by '\t' --where "first_name='Dorthy'" --target-dir authors_Dorthy Замечание: вывод работ (job) Hadoop сохраняется в один или более файлов разделов (partition). Обычно создаются 4 файла, а результаты запроса помещаются в произвольный файл. 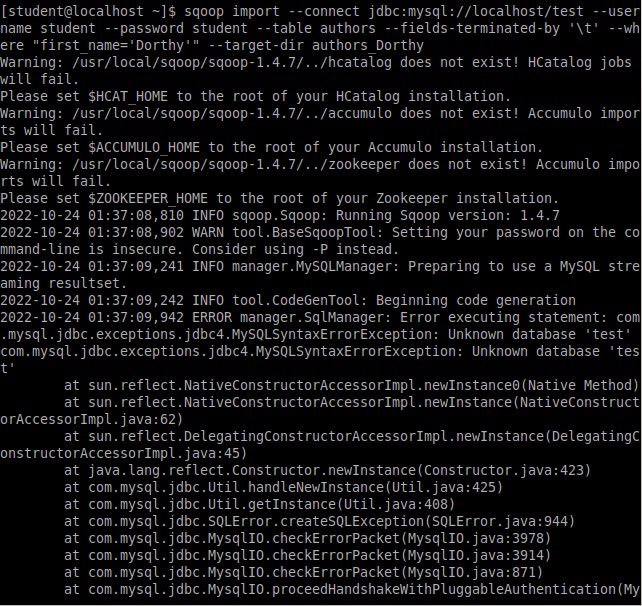 Импортируем таблицу, используя другой формат файла, вместо простого текстового. Импортируем таблицу authors в файл формата Parquet: $sqoop import --connect jdbc:mysql://localhost/labs --username student --password student --table authors --target-dir /mywarehouse/authors_parquet --as-parquetfile 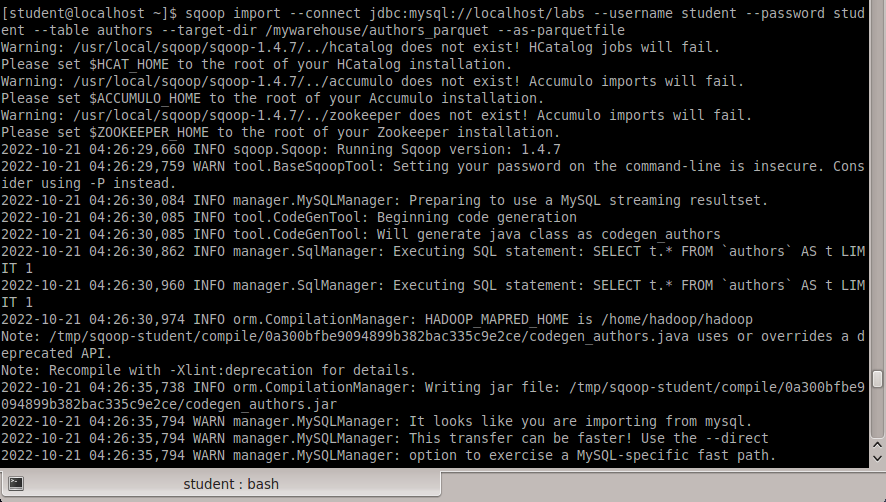 Смотрим результат при помощи отображения содержимого целевой директории HDFS: 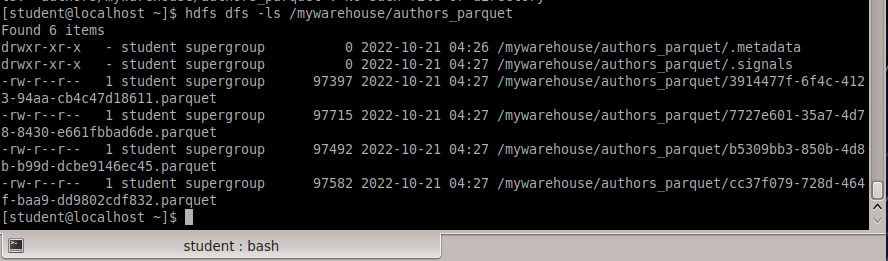 Figure 7. Список файлов Parquet Каждому файлу Parquet дано уникальное имя, например, 5e44cda6-728c-4912-864a-94d0659930f3.parquet. Данные в этом формате нельзя просмотреть напрямую, так как формат двоичный. Для просмотра записей в таких файлах используйте команду parquet-tools show. Сначала нужно получить файл parquet на локальный узел, а затем запустить команду parqet-tools: $ hdfs dfs -get /mywarehouse/authors_parquet/5e44cda6-728c-4912-864a-94d0659930f3.parquet $ parquet-tools show 5e44cda6-728c-4912-864a-94d0659930f3.parquet  Импортируем таблицу authors, используя сжатие (аргумент --compress или -z): $ sqoop import --connect jdbc:mysql://localhost/labs --username student --password student --table authors --target-dir /mywarehouse/authors_compressed --compress  Рисунок 8. Список сжатых файлов Импортируем строки, где first_name указано, как «Dorthy» (мы уже делали это в шаге 15) и сохраняем результат в папку dorthy в домашней директории HDFS: $ sqoop import --connect jdbc:mysql://localhost/labs --username student --password student --table authors --fields-terminated-by '\t' --where "first_name='Dorthy'" --target-dir dorthy Экспортируем сохраненную папку dorthy в качестве таблицы в базу данных labs: $sqoop export --connect jdbc:mysql://localhost/labs --username student --password student --table authors_export --fields-terminated-by '\t' --export-dir dorthy 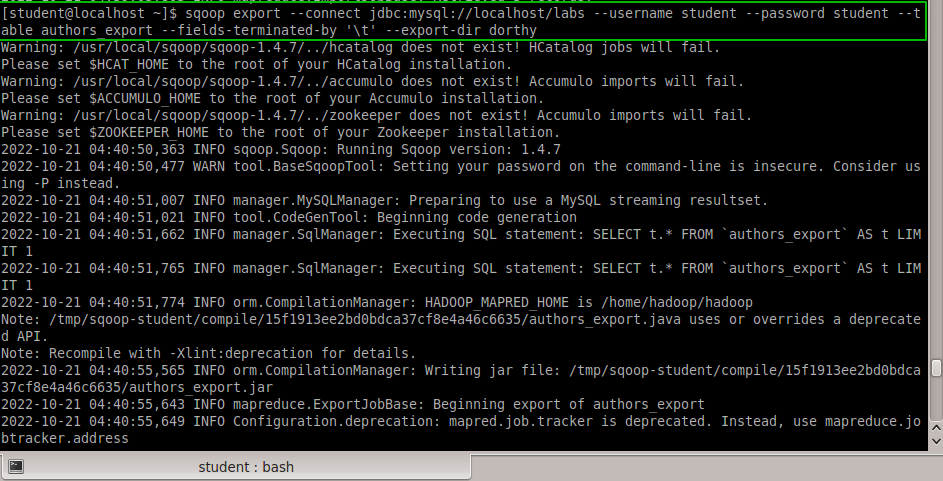 Посмотрим содержимое экспортированных записей в MariaDB: 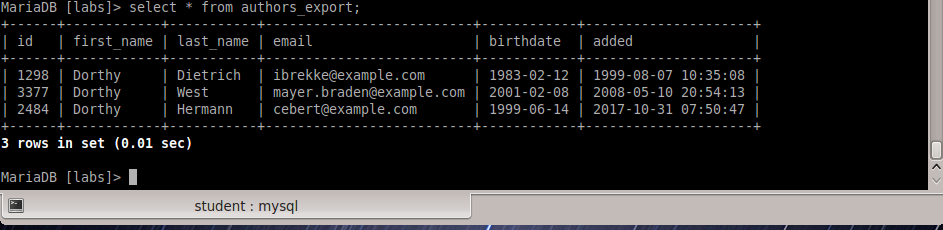 Рисунок 9. Экспортированные записи в MariaDB Создайте целевую директорию в HDFS для импортирования данных таблицы из базы labs (/tmp/mylabs). Из таблицы posts импортируйте первичный ключ, заголовки постов, дату публикации в директорию HDFS /tmp/mylabs/posts_info. Сохраните файл в текстовом формате с табуляциями в качестве разделителей. Подсказка: вам необходимо выяснить названия нужных столбцов, используя команды sqoop, а не напрямую в MariaDB. 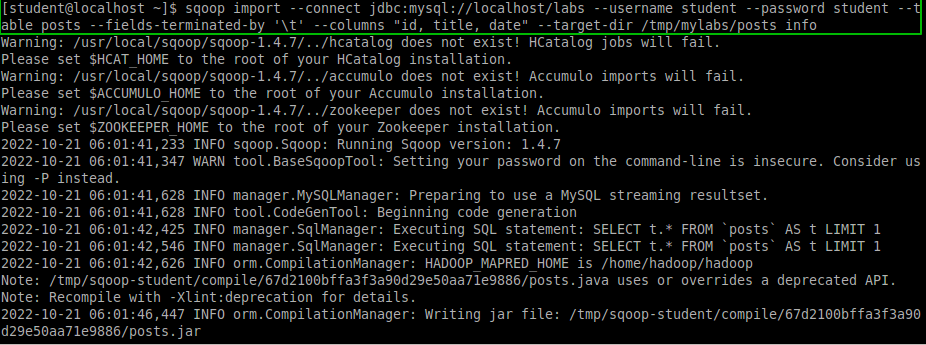 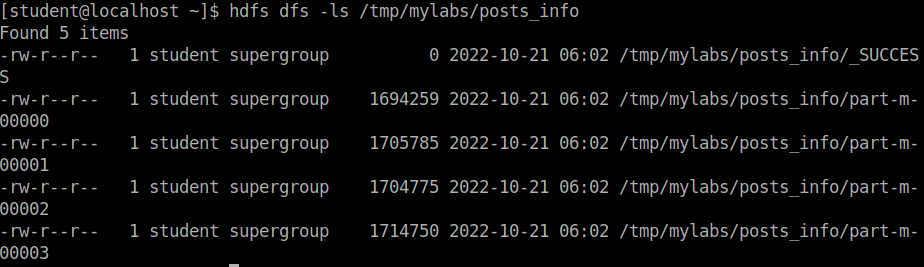 Теперь сохраните то же самое, только в формате parquet со сжатием snappy в папке /tmp/mylabs/posts_compressed. 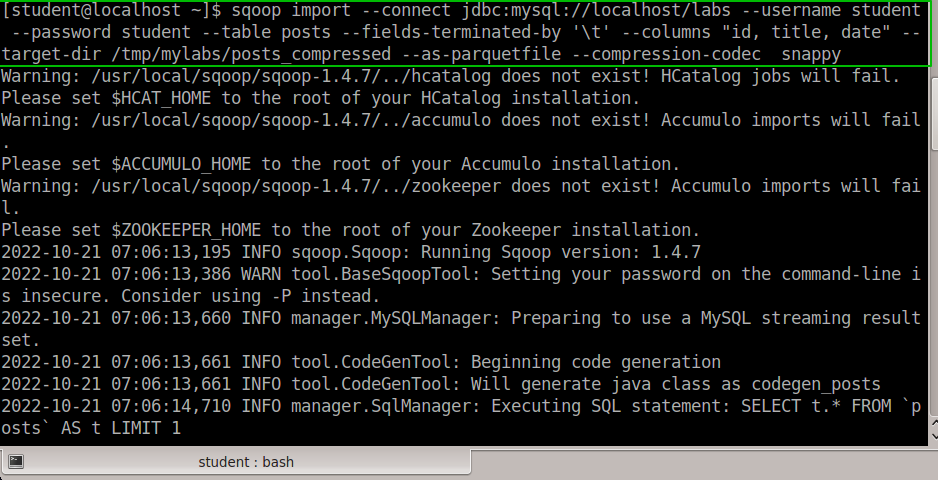 Из окна терминала отобразите несколько записей из тех, что вы только что проимпортировали. Импортируйте столбцы id, first_name, last_name, birthdate из таблицы authors в домашнюю директорию HDFS. Файл сохраните в текстовом формате с табуляциями в качестве разделителей. Подсказка: если директория authors уже существует в домашней директории HDFS, удалите ее и только потом выполните команду import. 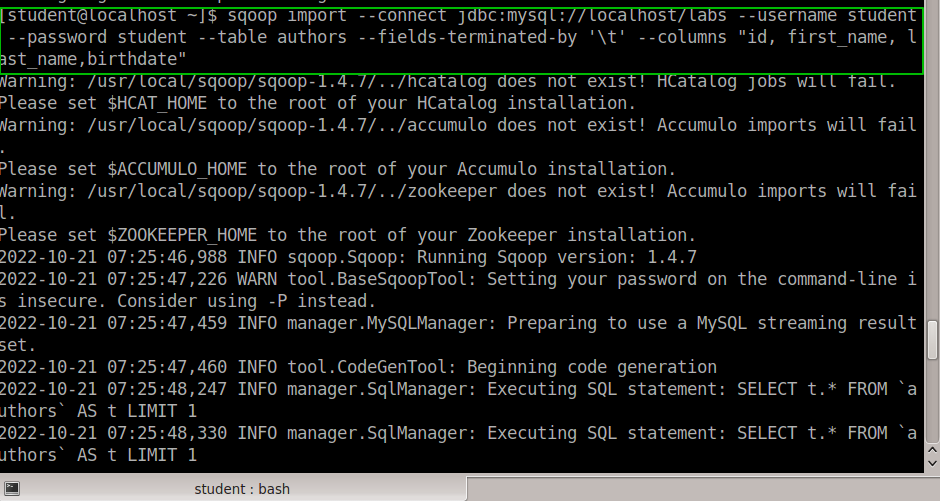  Импортируйте и сохраните в директории /tmp/mylabs/posts_NotN те посты, название которых не NULL. Импортируйте только следующие столбцы: id, title, content. Сохраните файл в формате parquet, а для сжатия используйте кодек snappy. 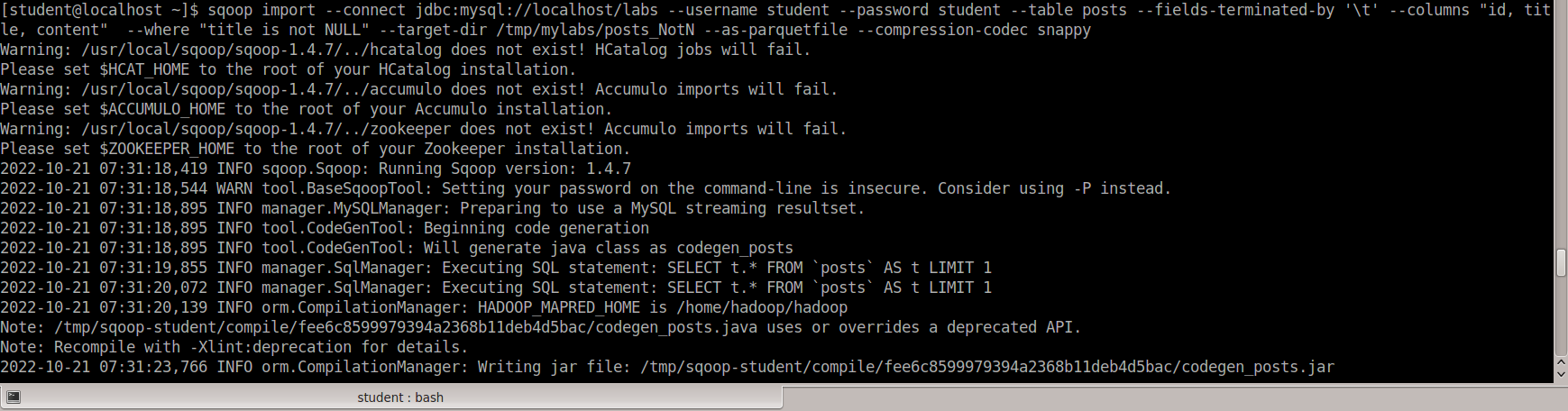  Подсказка: выражение SQL для проверки того, что значение в столбце не NULL: "название_столбца is not NULL" SQL будет объяснен на лекции. |