Исследование ошибок в операционных системах
 Скачать 260.52 Kb. Скачать 260.52 Kb.
|

|
ПЕРВОЕ ВЫСШЕЕ ТЕХНИЧЕСКОЕ УЧЕБНОЕ ЗАВЕДЕНИЕ РОССИИ  МИНИСТЕРСТВО науки и высшего ОБРАЗОВАНИЯ РОССИЙСКОЙ ФЕДЕРАЦИИ федеральное государственное бюджетное образовательное учреждение высшего образования «САНКТ-ПЕТЕРБУРГСКИЙ ГОРНЫЙ УНИВЕРСИТЕТ» Кафедра системного анализа и управления КУРСОВАЯ РАБОТА По дисциплине Информационная безопасность и защита информации (наименование учебной дисциплины согласно учебному плану) ПОЯСНИТЕЛЬНАЯ ЗАПИСКА Тема работы: «Исследование ошибок в операционных системах» Выполнил: студент гр. САМ-21-1 Громыко Д.В. (шифр группы) (подпись) (Ф.И.О.) Оценка: Дата получения задания: 11.02.22 Дата сдачи работы: 20.05.22 Проверил руководитель работы: ассистент Мартиросян А.В. (должность) (подпись) (Ф.И.О.) Санкт-Петербург 2022 ОглавлениеВведение 3 1.Анализ предметной области 4 2.Аппаратное обеспечение 8 3.Программное обеспечение 13 4.Современное состояние предметной области 18 Заключение 21 Библиографический список 22 ВведениеАктуальность темы курсовой работы обусловлена интересом людей к поддержанию устойчивости информационных систем, для обеспечения стабильной работы которых создаются различные инструменты для своевременного выявления ошибок. Объект исследования: операционные системы. Предмет исследования: инструменты исследования ошибок. Цель работы заключается в изучении современных средств поиска и анализа ошибок в операционных системах. В связи с поставленной темой в данной работе решаются следующие задачи: Дать определение операционной системе. Составить требования по контролю ошибок. Рассмотреть технологии выявления ошибок. Изучить тенденции развития. Анализ предметной областиОсновным предметом данной области является операционная система. Операционная система – комплекс программ, обеспечивающий управление аппаратными средствами компьютера, организующий работу с файлами и выполнение прикладных программ, осуществляющий ввод и вывод данных. Операционные системы осуществляют две значительно отличающиеся друг от друга функции: предоставляют прикладным программистам (и прикладным программам, естественно) вполне понятный абстрактный набор ресурсов взамен неупорядоченного набора аппаратного обеспечения и управляют этими ресурсами [5]. Одной из ожидаемых характеристик ОС является корректная реализация своей функциональности. Но не всегда ОС выполняет заложенные требования. По этой причине в системе возникают ошибки. Программная ошибка – ошибка в программе или в системе, из-за которой программа выдает неожиданное поведение и, как следствие, результат. На современном уровне развития вычислительной техники ошибки могут наносить непоправимый ущерб системам. В каждой программе происходят разного рода вычисления. По этой причине необходимо осуществляется контроль вычислительного процесса. Контроль вычислительного процесса опирается на общие принципы построения программного обеспечения. Он заключается в проверке своевременности выполнения программ, правильности выполнения ее участков, разветвлений и обращений к подпрограммам. Осуществляется контроль следующих состояний программы: Контроль зацикливаний. Производится с помощью программного счетчика времени. Данный метод позволяет обнаруживать зацикливание с некоторой задержкой, зависящей от периода прерываний. Период прерываний выбирается с учетом двух противоречивых требований – необходимости обнаружения зацикливаний с минимальной (допустимой) задержкой и минимального (допустимого) увеличения времени реализации программы. Организация контроля зацикливания должна учитывать возможность взаимного прерывания программ в мультипрограммных режимах работы вычислительных машин. Контроль прекращения выполнения программы. Производится аналогично обнаружению зацикливания. Контроль прерываний. Предполагает проверку правильности выполнения операции прерывания, перехода к прерывающей программе и последующее возвращение к прерванной программе. Вследствие относительной простоты логики прерываний возникновение ошибок возможно только при большом числе программ, допускающих прерывания со значительной глубиной вложенности. Защита от таких программных ошибок и от аппаратных сбоев основана на периодическом контроле выполнения всех программ: периодически включаемая программа производит подготовку контрольных заданий каждой контролируемой программе и проверку правильности их выполнения. Контроль последовательности выполнения программ. Производится путем проверки предшествования или проверки изменения ключевых слов. Проверка предшествования основана на том, что каждая из программ перед обращением к другой записывает в фиксированную область памяти определенный код. Последующая программа по данному коду проверяет правильность своего включения. Использование ключевых слов предусматривает, что в начале выполнения программы, содержащей несколько подпрограмм, формируется специальная таблица. Эта таблица содержит имена подпрограмм, подлежащих обязательному выполнению, последовательность и количество включений каждой из них. После каждой реализации подпрограммы осуществляется корректировка таблицы. По завершении программы проводится анализ таблицы, в результате чего выясняется правильность реализации совокупности подпрограмм. Обнаружение ошибки происходит с большой задержкой во времени. Повышение оперативности обнаружения ошибки достигается путем проверки правильности обращения при каждой передаче управления подпрограмме. Контроль самоблокировки вычислительного процесса. Может осуществляться аналогично контролю зацикливания [4]. Предотвращение самоблокировки основано на предупреждении возникновения следующих условий: Различные программы претендуют на исключительное право использования ресурсов, которые они затребовали (время процессора, области памяти, массивы данных и т.д.). Программы удерживают выделенные ресурсы, ожидая назначения других ресурсов. До завершения исполнения программ нельзя принудительно изымать занятые ими ресурсы. Существует замкнутая цепь программ, в которой каждая из них удерживает хотя бы один ресурс, необходимый другой программе. Меры по обнаружению ошибок могут быть приняты на нескольких структурных уровнях комплекса программ, начиная от элементов отдельных компонент и кончая уровнем комплекса. Восстановление вычислительного процесса требует выполнения определенной последовательности действий. Если обнаружена ошибка, то необходимо определить вид, характер, причину и место возникновения ошибки. Вид ошибки характеризует особенности ее проявления (например, ошибка организации обмена с внешним запоминающим устройством или ошибка в результате вычислений). Анализ вида ошибки основывается на изучении информации, содержащейся в регистрах вычислительной машины (аппаратный способ обнаружения ошибок), или на результатах выполнения программных процедур контроля. Характер ошибки определяется их повторяемостью. Каждая впервые появившаяся ошибка считается случайной. Если ошибка появляется многократно, то она считается систематической. Определение характера ошибки производится с помощью счетчиков кратности появления ошибок данного вида, повторения ошибок любого вида на заданном интервале времени и общего числа ошибок, возникающих в процессе выполнения комплекса программ. Счетчик кратности повторения ошибок данного вида позволяет определить, является ли ошибка случайной или систематической. Каждому виду ошибок ставится в соответствие допустимое число повторений, в пределах которого ошибка считается случайной, например, в ходе контроля повторным счетом допускается не более трех-четырех повторений. Для некоторых видов ошибок не предусматривают повторные действия (при ошибке в оформлении поступившей информации). Счетчик частоты повторения ошибок любого вида используется в целях обнаружения отказов устройств вычислительной машины, появление которых вызывает большое количество сигналов от схем аппаратного контроля. Переполнение счетчика вызывает формирование сигнала о неисправности машины. Счетчик общего числа ошибок предназначен для удобства анализа информации об ошибках. Отыскание причины и места ошибки, обнаруженной аппаратными средствами, производится с помощью диагностических тестов. Диагностические тесты являются одним из методов выявления неисправностей на аппаратном уровне. Такие тесты осуществляются сторожевыми механизмами, речь о которых пойдет в следующей главе. Страница заполнена минимум наполовину Аппаратное обеспечениеСторожевой механизм – механизм, направленный на повышение надежности работы вычислительной системы. На рисунке 2.1 представлена схема работы сторожевого механизма. 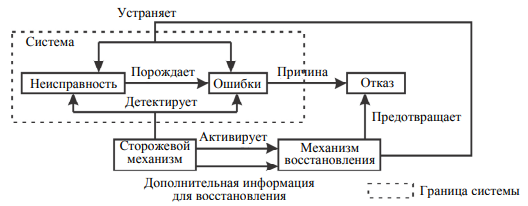 Рисунок 2.1. Функции сторожевого механизма в задаче обеспечения надежного функционирования встраиваемой системы В основе работы сторожевых механизмов лежат методы обнаружения ошибок. Существует большое разнообразие таких методов, но все они объединяются общей идеей. Суть ее состоит в сопоставлении текущих показателей системы с теми их значениями, которые предсказывает некоторая модель этой системы. При расхождении значений делается вывод о присутствии в системе ошибки. Данная концепция отражена на рисунке 2.2. 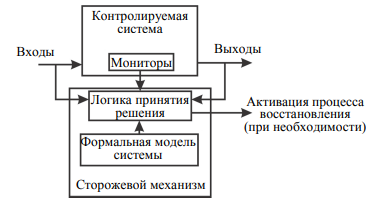 Рисунок 2.2. Принцип работы сторожевого механизма Под мониторами понимаются аппаратные и (или) программные компоненты, позволяющие получать информацию о внутреннем состоянии контролируемой системы. На основании этой информации, предсказаний формализованной модели системы, а также данных с входов и выходов системы сторожевой механизм делает вывод о наличии или отсутствии в ней ошибок и неисправностей. На основе тестирования и резервирования ресурсов созданы следующие методы обнаружения ошибок: Тестирование/диагностика компонентов системы. Данный метод основан на проведении специализированных диагностических тестов системы. Использование резервирования. Данный метод основан на использовании аппаратной, программной, информационной, временной избыточности системы для сравнения данных c их копиями или результатов нескольких вычислений с целью выявления в них расхождений [3]. При решении задач детектирования ошибок важно учитывать время их существования, так как это напрямую сказывается на эффективности методов их обнаружения. В соответствии с этим свойством можно выделить кратковременные (transient) ошибки, если время их существования весьма незначительно по отношению ко времени функционирования системы. Если же время их существования сопоставимо со временем функционирования системы, то говорят о постоянных (permanent) ошибках. Список методов выше направлены на контроль внутренних компонентов системы без учета задачи, которую решает система. Методы группы, приведенной ниже, основаны на проверке корректности выполнения целевого алгоритма (фрагментарно или в целом). Стоит отметить, что некоторые из методов позволяют не только обнаруживать ошибки, но и диагностировать их причины, а иногда и идентифицировать источники неисправности. Методы проверки корректности выполнения целевого алгоритма: Реверсивная проверка. Данный метод на основе значения, полученного на выходе, производит предположение о значении на входе, после чего эти значения сравниваются. Выявляется несоответствие рассчитанного значения входа и его текущего значения. Кодирование. Данный метод проверяет соответствие текущих значений кодов для данных и команд с их заранее вычисленными эталонными значениями. Выявляет их несоответствие. Проверка функционально корректности. Данный метод использует знания о системе с целью проверки корректности значений некоторых величин. Выявляет несоответствие ожидаемым значениям или невыполнение логических выражений – ассертов. Обработка исключений. Данный метод выявляет особые (например, деление на 0) ситуации, свидетельствующие о наличии ошибок в системе или тех, что потенциально могут стать их причиной. Проверка доступа к памяти. Данный метод проверяет корректность доступа к памяти со стороны различных системных объектов. Проверка целостности структуры. Данный метод проверяет целостность структур данных, таких как списки, деревья, очереди и т.д. Проверка потока управления. Проверка количества инструкций. Данный метод проверяет соответствие количества выполненных инструкций и их заранее подсчитанного количества для каждого программного блока. Сигнатурный анализ. Назначенные сигнатуры. Данный метод проверяет поток управления путем сопоставления информации о разрешенных переходах между блоками и сигнатурами (уникальными метками) текущего и предыдущего блоков. Сигнатуры назначаются. Вычисленные сигнатуры. Данный метод помимо проверки правильности следования блоков инструкций позволяет проверить правильность инструкций и порядок их следования в блоке вычислением сигнатуры блока из кодов инструкций и ее сравнением с заранее вычисленной сигнатурой блока. Сигнатуры вычисляются на основе кодов инструкций блока. Проверка временных ограничений. Данный метод проверяет выполнение временных ограничений, накладываемых на различные операции и процессы [1]. Одним лишь выявлением ошибок сторожевые механизмы не ограничены. Функционал таких устройств дополнен различными действиями над системой при обнаружении ошибок, однако такие действия выходит за рамки инструментов исследования ошибок. Перейдем к программным технологиям обнаружения ошибок. Страница заполнена минимум наполовину Программное обеспечениеВ данной главе будет рассмотрена технология фаззинг-тестирования на примере операционной системы Linux. Фаззинг – техника тестирования программного обеспечения, часто автоматическая или полуавтоматическая, заключающаяся в передаче приложению на вход неправильных, неожиданных или случайных данных. Те данные, на которых программа вошла в бесконечный цикл или аварийно завершилась, сохраняются для дальнейшего исследования и выявления дефекта. Такой дефект в дальнейшем может привести к обнаружению определенной уязвимости. Область применения фаззинга неуклонно растёт. Данный метод применяют для поиска недостатков в браузерах, парсерах, компиляторах, интерпретаторах, криптографических компонентах, сетевых протоколах, базах данных и т. д. Не менее важным аспектом является фаззинг операционных систем, виртуальных машин и гипервизоров. Несмотря на широкую популярность ОС на базе ядра Linux, систематических исследований по его фаззингу проводилось немного. Несмотря на то, что многие фаззеры ядра имеют открытый исходный код, отсутствие в большинстве случаев хотя бы краткой документации алгоритма работы затрудняет их изучение. В данной главе рассмотрены различные типы фаззеров ядра и проанализированы подходы фаззинга с применением наиболее актуального в настоящего времени инструмента Syzkaller. Для успешного фаззинга необходимо генерировать новые входные данные, которые будут максимально охватывать исследуемый объект. По способам генерации входных данных можно выделить следующие типы фаззеров: Грамматический фаззер. В основе работы лежит набор правил для генерации входных данных. После того как фаззер создаст новые правила, он сгенерирует новые комбинации на их основе. Однако можно отклоняться от правил, полученных ранее, чтобы добавить долю случайности в входные данные. Разработка фаззера данного типа довольно трудоемка, так как на первом этапе необходимо самостоятельно определять грамматику, от которой в будущем зависит вся эффективность фаззинга. Мутационный фаззер. На каждом этапе данные генерируются случайным образом в отличии от предыдущей итерации. Для старта требуется набор репрезентативных входов, которые используются в дальнейших мутациях. Во время работы достигается максимальное разнообразие комбинаций данных подаваемых на вход программе. Трудоемкость разработки не является высокой, т. к. в основе лежит разработка алгоритмов мутаций и комбинаций исходных данных. Универсальный фаззер. Сочетает в себе оба способа описанных ранее. Трудоемкость заключается в построении грамматики с помощью машинного обучения на основе имеющихся данных. Высока сложность оценки эффективности работы. Фаззер с покрытием кода. В основе – генетический алгоритм, стремящийся к максимальному покрытию тестируемого кода. Один из самых эффективно работающих фаззеров на сегодняшний день. По мере развития фаззинга ядра сформировались 4 основные категории данного ПО: основанные на рандомизации, типизированные, основанные на перехватах и фаззеры с обратной связью. Основанные на рандомизации. Появление фаззеров ядра относится к 1991 году, когда был выпущен фаззер tsys. Идея его работы проста: он вызывает серию случайно выбранных системных вызовов UNIX System V со случайно сгенерированными аргументами. Типизированные фаззеры. В 1997 г. Купман и другие исследователи определили набор всевозможных тестовых комбинаций данных для системных вызовов, которые были сгенерированы на основе типов их аргументов. В 2010 г. в фаззере Trinity данная идея была развита – была добавлена некоторая случайность для генерации тестовых кейсов. Основанные на перехватах. Фаззеры данной категории пытаются перехватить вызовы функции API во время выполнения ядра. Фаззеры с обратной связью. Некоторые фаззеры, такие как syzkaller, kernel-fuzzing, TriforceLinuxSyscallFuzzer используют покрытие кода при генерации системных вызовов. В частности, они выбирают один из случайно генерируемых системных вызовов, который максимизирует покрытие кода ядра. В качестве обратной связи может использоваться код возврата из функции [2]. Наиболее актуальным фаззером для ядра Linux на сегодня является Syzkaller, разработанный компанией Google. Схема компонентов и их взаимодействия инструмента Syzkaller приведена на рисунке 3.1. 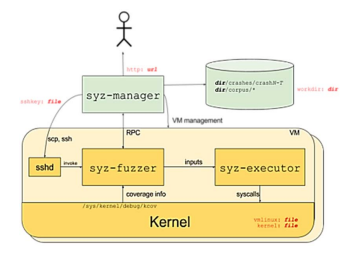 Рисунок 3.1. Архитектура Syzkaller Остановимся на схеме взаимодействия компонентов более подробно. Процесс sys-manager запускает, отслеживает и перезапускает несколько экземпляров виртуальных машин. В каждом экземпляре порождается процесс sys-fuzzer. Sys-manager хранит различные корпуса. входных данных и информацию об аварийных завершениях, обнаруженных в ходе анализа ядер внутри виртуальных машин. Этот процесс работает на стабильном ядре, которое изолировано от процессов sys-fuzzer. Процесс sys-fuzzer запускается внутри нестабильной виртуальной машины и осуществляет фаззинг, при этом отправляя входы, вызывающие прирост покрытия по базовым блокам, в процесс sys-manager с использованием RPC (механизм удаленного вызова процедур). Sys-fuzzer запускает временный процесс sys-executor, каждый экземпляр которого исполняет единственный вход в виде последовательности системных вызовов, после чего возвращает результат в sys-fuzzer с использованием разделяемой памяти. Фаззинг ядра необходимо осуществлять в режиме debug с включенными детекторами возникновения внештатных ситуаций таких как: санитайзеры и специализированные опции, включенные в ядро. Санитайзеры помогают фаззеру распознать критические ситуации и получить подробную информацию при возникновении kernel crash, т. е. аварийного завершения ядра. Без дополнительных средств отладки, таких как KASAN, UBSAN, KMSAN, KTSAN, процесс фаззинга становится неэффективным. UBSAN – санитайзер, выявляющий неопределенное поведение во время исполнения. В основе использует инструмент времени компиляции, чтобы обнаружить неопределенное поведение (UB). Компилятор вставляет код, который выполняет определенные виды проверок перед операциями, которые могут вызвать UB. Если проверка не удалась, вызывается функция __ubsan_handle_ * для вывода сообщения об ошибке. KASAN на этапе компиляции вставляет проверки легитимности перед каждым обращением к памяти, поэтому для успешного функционирования требуется версия компилятора, которая это поддерживает. KMSAN – детектирует использование неинициализированной памяти для ядра Linux. KTSAN – детектирует гонки данных. В основе лежит TSAN средство выявления состояний гонки потоков в пользовательском пространстве (TSAN). Включается на этапе сборки ядра. CONFIG_HARDENED_USERCOPY – опция в ядре, которая включает набор дополнительных проверок при копировании памяти из пользовательского пространства в пространство ядра (и наоборот). Изначально была основана на функции PAX_USERCOPY GrSecurity, но переработана в совершенно новую форму. Применяются следующие критерии проверок, если: адрес является объектом кучи, размер не должен превышать выделенный размер объекта; диапазон адресов находится в текущем стеке процесса, он должен находиться в допустимом кадре стека (если такая проверка возможна) или, по крайней мере, целиком в стеке текущего процесса. (Это может перехватить большие длины, которые вышли бы за пределы текущего стека процессов, или переполнились, если их длина вернулась в исходный стек.); диапазон адресов является частью данных ядра, rodata или bss, разрешить копирование; диапазон адресов распределен по страницам, он не охватывает несколько распределений (за исключением страниц с резервированием и страниц CMA); адрес находится в текстовой области памяти ядра, отклонить его; все остальные манипуляции при копировании разрешены. На данном этапе получены все необходимые знания о технологии фаззинга. Страница заполнена минимум наполовину Современное состояние предметной областиВ предыдущей главе была рассмотрена актуальный и эффективный фаззер. Осталось рассмотреть способы повышения эффективности сторожевых механизмов. Повышение эффективности сторожевых механизмов возможно посредством использования различных методов. Однако выделяют два основных подхода. Первый заключается в снижении их избыточности. Он реализуется посредством решения задачи обеспечения достаточно уровня контроля при условии минимизации расходов. Для этого целесообразно сначала составить градацию неисправностей и выявленных ошибок по степени серьёзности последствий, к которым они ведут. В последующем это позволит выделить в системе важные процессы и объекты, которые нуждаются в повышенном контроле со стороны сторожевых механизмов. Ряд исследователей предлагают выделять в программе критические пути и важные блоки на базе частоты исполнения, выбора пользователя и размера самого блока. Другие источники сообщают о возможности выделения наиболее значимых переменных на базе вычисления определенных метрик. Второй подход повышения эффективности обусловлен комплексным и глубоким знанием особенностей программного и аппаратного обеспечения целевой системы, что является необходимым условием для выполнения ряда проверок. К примеру, ряд источников сообщает, что для подсчета числа реализованный инструкций применяется встроенный монитор. Другие источники говорят о возможности дублирования главного процессов за счет встроенной опции «основной/проверяющий». Для получения сведений об инструкциях, которые исполняет процессор, предложено применять средства, которые встроены в него и используются в ходе отладки. Для получения контроля ожидающих задач применяется их опрос, механизм которого выполняется при наличии необходимых возможностей в рамках операционной системы. Также для повышения эффективности сторожевых механизмов может использоваться информация, динамически получаемая, обновляемая и затем используемая. К примеру, в их памяти хранится информация о часто эксплуатируемых блоках, которая регулярно динамически обновляется. За счет этого появляется возможность контроля за программами, которые занимают большой объем, при этом нет необходимости увеличения памяти самого процессора. С целью увеличения эффективности также широко распространено применение комбинаций из разнообразных методов для выявления и устранению имеющихся ошибок. К примеру, сигнатурный анализ может сочетаться с проверкой корректности посредством применения логических утверждений. Либо к сигнатурного анализу, может быть, добавлено дублирование наиболее ценных переменных. Помимо этого, популярен метод, в котором подсчет числа инструкций сочетается проверкой временных переменных и сигнатурным анализом. Ошибки и неисправности могут наблюдаться на всех системных уровнях, что диктует необходимость использования многоуровневых сторожевых механизмов для достижения эффективной эксплуатации. Это также позволяет расширить возможности системы в области выявления ошибок, а также минимизировать время их выявления и увеличить точность их идентификации, последующей локализации. Проектирование, установка и реализация сторожевых механизмов во встраиваемых вычислительных системах с высокой эффективностью требует большого количества времени, специфичных знаний и навыков разработчика. Анализ литературных источников, а также реальных изделий и проектов позволил выявить, что отсутствие компактной и четкой методики в реализации сторожевых механизмов в системах ведет к тому, что сторожевые механизмы работают некорректно, на выходе наблюдается нерабочее или ненадежное решение. Характеристики преимущественной части разрабатываемых встраиваемых вычислительных систем, в частности гетерогенность виртуальных и физических процессов, и многоуровневая организация, дают возможность сформулировать наиболее приоритетные задачи в области совершенствования качества и сокращения трудоемкости использования: Создание модели сторожевых механизмов в соответствии с типовым организационным системным уровнем и технологиями, которые характерны для этого уровня. Унификация имеющихся моделей механизмов в области поддержки наиболее перспективных методик проектирования категории аппаратно-программного сопряженного проектирования HW/SW Codesign. Выделение кросс-уровневых механизмов, предложение для них языка специфицирования и интеграции в средства создания основных организационных уровней систем [1]. Таким образом, есть широкий спектр задач, которые необходимо решить в рамках разработки технологий применения сторожевых механизмов, входящих во встраиваемые вычислительные системы, обладающие реконфигурируемой архитектурой. ЗаключениеИсследование ошибок в операционных системах является важной задачей, по причине того, что огромное количество информационных систем используются в управлении жизненно важными процессами. В ходе данной курсовой работы были выполнены следующие задачи: Дано определение операционной системы. Были составлены требования по контролю ошибок в вычислительных системах. Рассмотрены различные технологии выявления ошибок, а именно, сторожевые механизмы и технология фаззинг-тестирования. Изучены тенденции развития. В первой главе были рассмотрены основные понятия предметной области. Также были описаны методы и подходы контроля вычислительного процесса. Во второй главе было представлено аппаратное обеспечение. Описан принцип его работы. В третьей главе был описан принцип работы фаззеров. Была представлена эффективная и актуальная программа syzkaller. В четвертой главе были представлены перспективы разработки. Также были предложены способы повышения эффективности сторожевых механизмов. 2-3 ПРЕДЛОЖЕНИЯ ПРО КАЖДУЮ ГЛАВУ Библиографический списокПономарьков, С. М. Исследование недостатков ядра Linux методом фаззинга с применением пользовательского по / С. М. Пономарьков, П. А. Теплюк, Е. В. Шарлаев // Прикладная математика и информатика: современные исследования в области естественных и технических наук : Материалы VI Международной научно-практической конференции (школы-семинара) молодых ученых, Тольятти, 23–25 апреля 2020 года. – Тольятти: Тольяттинский государственный университет, 2020. – С. 931-936. Платунов А.Е., Стерхов А.С. Сторожевые механизмы во встраиваемых вычислительных системах // Научно-технический вестник информационных технологий, механики и оптики. 2017. Т. 17. № 2. С. 301–311. doi: 10.17586/2226- 1494-2017-17-2-301-311. Сяо, Ц. Применение сторожевых механизмов во встраиваемых вычислительных системах / Ц. Сяо // Наукосфера. – 2021. – № 2-2. – С. 82-86. Колентеев, Н. Я. Контроль и восстановление вычислительного процесса / Н. Я. Колентеев, А. С. Кобелева, С. А. Старостина // Информационные технологии в современном инженерном образовании : Материалы II межвузовской научно-практической конференции, Петергоф, 25 марта 2021 года. – Петергоф: Военный институт (железнодорожных войск и военных сообщений) Федерального государственного казенного военного образовательного учреждения высшего образования "Военная академия материально-технического обеспечения им. генерала армии А.В. Хрулева" Министерства обороны Российской Федерации, 2021. – С. 181-188. Таненбаум, Э. Современные операционные системы. 2-е изд. / Э. Танненбаум. – СПб. : Питер, 2002. – 1040 с. |