ффф. Изучение основных методов кластеризации с использованием приложения "Orange" по дисциплине Интеллектуальный анализ данных
 Скачать 455.41 Kb. Скачать 455.41 Kb.
|

|
МИНИСТЕРСТВО ОБРАЗОВАНИЯ И НАУКИ РОССИЙСКОЙ ФЕДЕРАЦИИ ФЕДЕРАЛЬНОЕ ГОСУДАРСТВЕННОЕ АВТОНОМНОЕ ОБРАЗОВАТЕЛЬНОЕ УЧРЕЖДЕНИЕ ВЫСШЕГО ОБРАЗОВАНИЯ «ЮЖНЫЙ ФЕДЕРАЛЬНЫЙ УНИВЕРСИТЕТ» ИНЖЕНЕРНО-ТЕХНОЛОГИЧЕСКАЯ АКАДЕМИЯ Институт компьютерных технологий и информационной безопасности Кафедра систем автоматизированного проектирования Лабораторная работа № 1 на тему: «Изучение основных методов кластеризации с использованием приложения “Orange”» по дисциплине «Интеллектуальный анализ данных»
. Таганрог 2022 Цель и задача работы: Ознакомиться и получить навыки работы с GUI интерфейсом приложения OrangeDataMining. Используя разные методы кластеризации, выявить оптимальные точки размещения отделений неотложной медицинской помощи в регионе на основе выданных тестовых данных. Теоретические положения Кластеризация – многомерная процедура, сортирующая собранные данные в однородные группы. Кластеризация классифицируется различными алгоритмами: Иерархические – древо кластеров, где корни – вся выборка, листья – наиболее мелкие кластеры. Плоские – общее разбиение объектов, на кластеры. Масштабируемые – адаптированы для ограниченных ресурсов вычислительной техники (объем памяти, бстродействие), они обеспечивают линейный рост времени работы с увеличением числа исследуемых задач. Немасштабируемые – работа со всеми данными, крайне востребованы к объему вычислительных ресурсов. Четкие – непересекающиеся алгоритмы, соотносящие один объект только с одним кластером. Нечеткие – пересекающиеся алгоритмы, к каждому объекту ставят в соответствие набор значений, определяющие степень принадлежности объекта к кластерам. Выполнение работы: Получив вариант задания, в программу «Orange» с помощью вкладки «File» были загруженные нужные данные. В соответствии с заданием, в виджетах «Select Rows» и «Select Columns» была осуществлена фильтрация и очистка данных, изображено на рисунке 1. 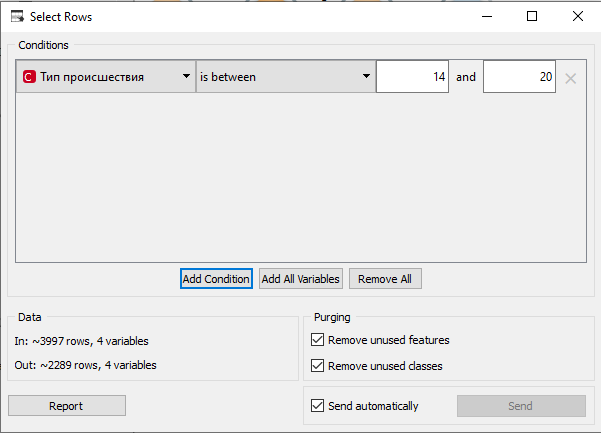 Рисунок 1 – Фильтрация в «Select Rows» С помощью алгоритма k – средних 9 (k-means) была осуществлена кластеризация подготовленных данных с фиксированным и опциональным количеством кластеров. Рисунок 2 демонстрирует оба варианта. 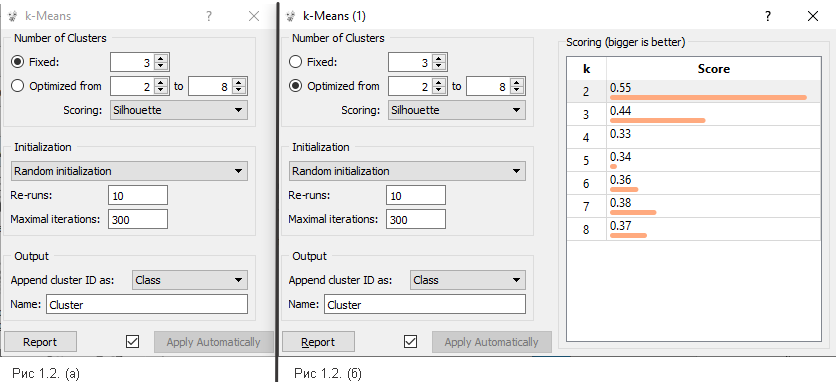 Рисунок 2 (а) – Фиксированное количество кластеров; (б) – Опциональное количество кластеров. Чтобы вывести результат, была использована точечная диаграмма (виджет «Scatter plot»), рисунок 3 показывает визуальный отчет алгоритма k-means. 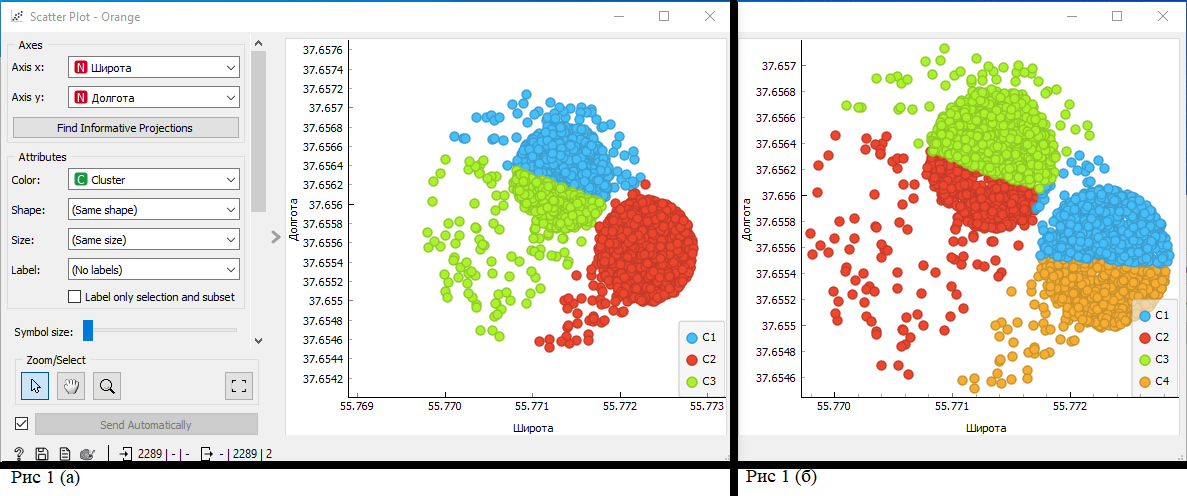 Рисунок 3 (а) – Отчет фиксированного количества кластеров; 3 (б) – Отчет опционального количества кластеров. Используя виджет «Hierarchical Clustering» была осуществлена кластеризация подготовленных данных с помощью иерархической кластеризации. В качестве меры расстояния была выбрана евклидова величина. На рисунке 4 изображено иерархическое дерево с евклидовой величиной. 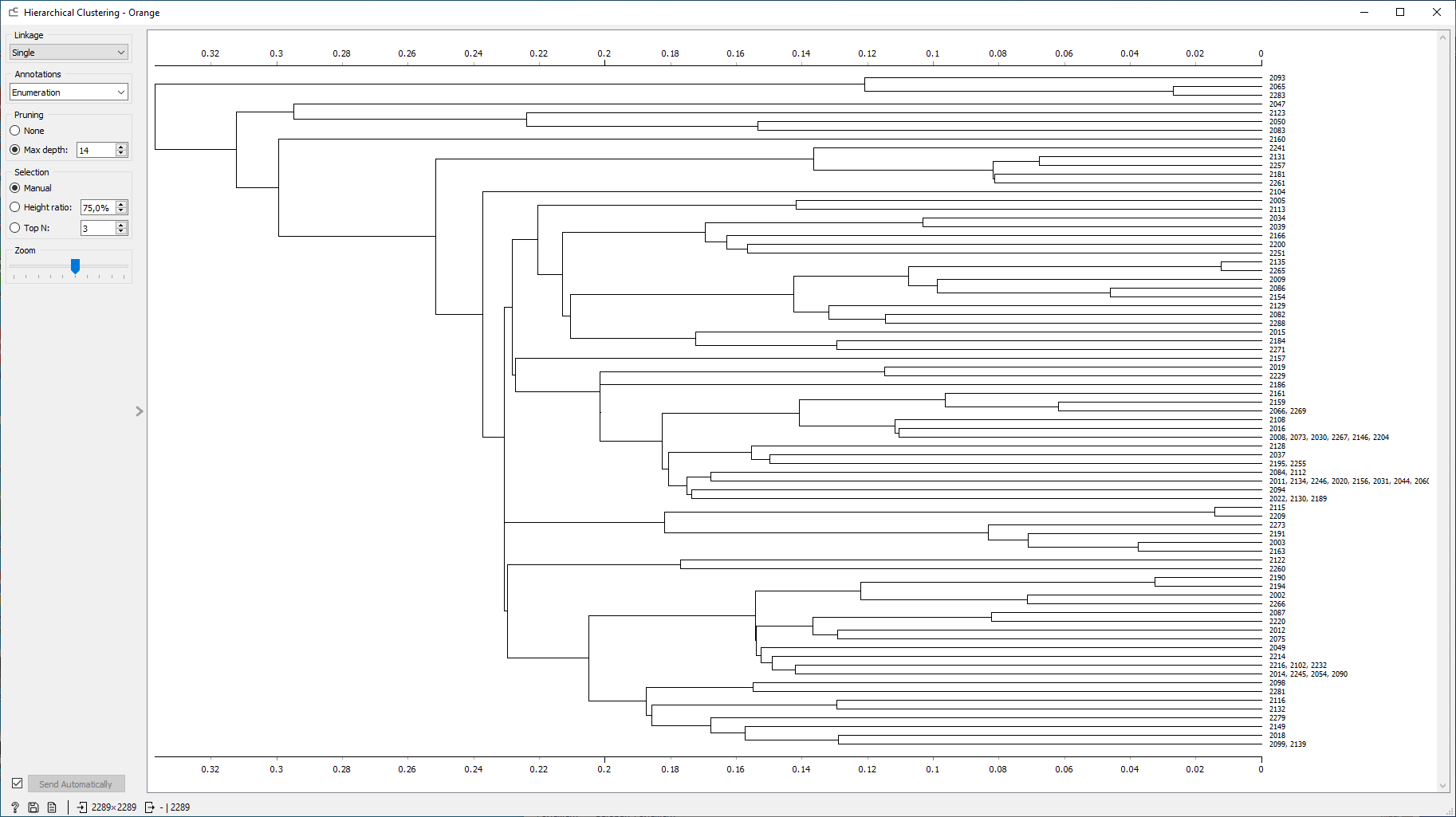 Рисунок 4 – Иерархическое дерево с евклидовой величиной с фильтрацией данных Эксперимент будет проведен повторно, предварительно отключив фильтрацию данных для оптимальных параметров на рисунке 5 продемонстрирован результат. 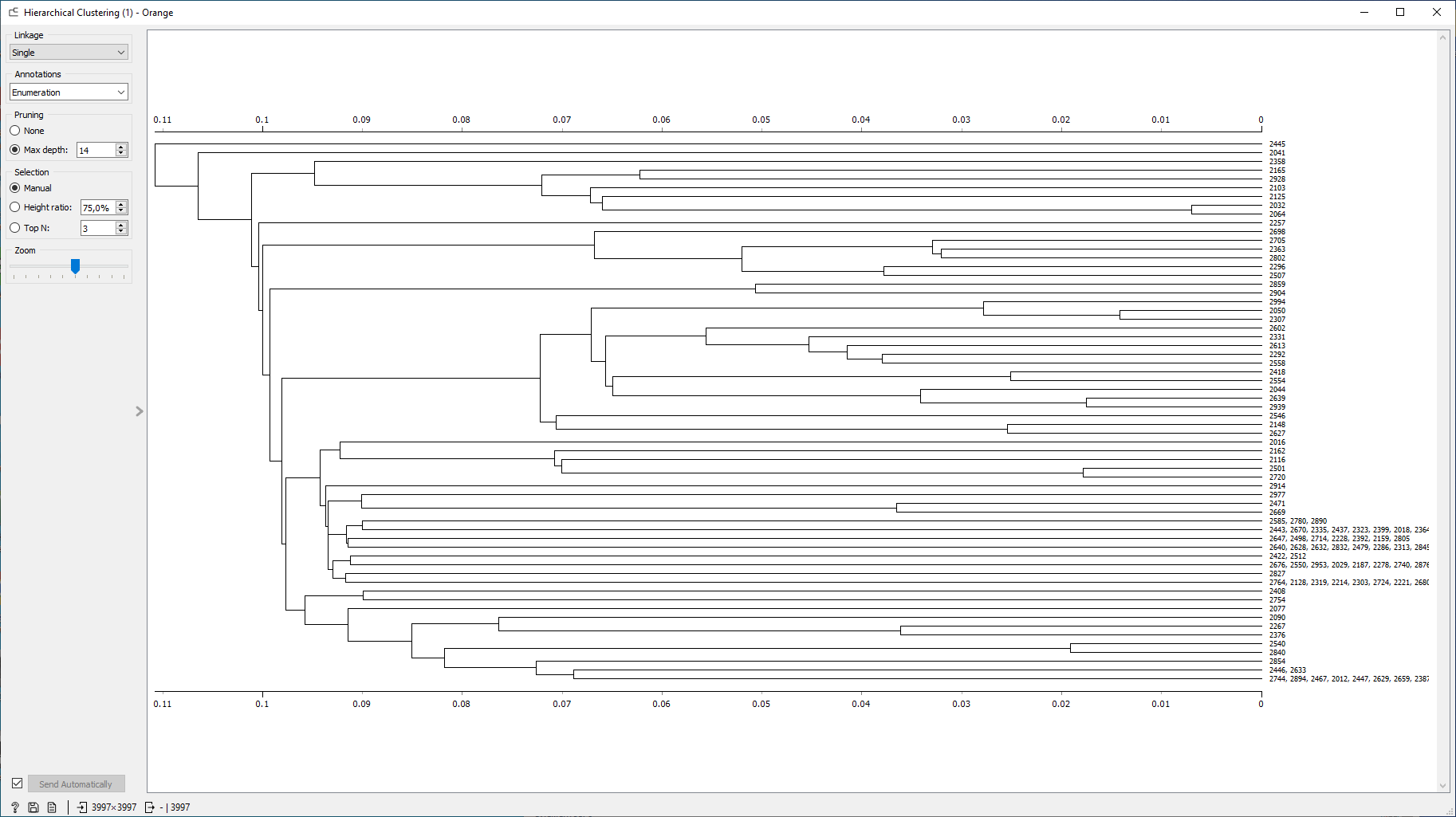 Рисунок 5 - Иерархическое дерево с евклидовой величиной без фильтрации данных Итоговый результат рабочего стола программы «Orange» продемонстрирован на рисунке 6.  Рисунок 6 - Рабочий стол программы «Orange» Вывод: Выполняя данную лабораторную работу, используя различные методы кластеризации были обнаружены оптимальные точки размещения отделений неотложной медицинской помощи в регионе на основе выданных тестовых данных. Так же, при выполнении данной работы, были получены и закреплены навыки работы с GUI интерфейсом приложения Orange Data Mining. Изучен теоретический материал и выписаны для дальнейшего изучения ключевые слова с их разъяснением, в собственном понимании. |