ОС СРС. Кэш жадысы. Кэш жадысында деректерді келісімділігі кері жне ткел жазба дістері
 Скачать 304.48 Kb. Скачать 304.48 Kb.
|

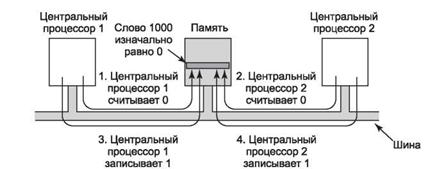
Использование базы данных механизмом Business Process EngineМеханизм Business Process Engine продукта Business Process Choreographer (BPC) хранит в базе данных BPC информацию обо всех процессах и обо всех экземплярах задач долго исполняющихся процессов. Это позволяет для пользовательского приложения, исполняющегося на механизме Business Process Engine, определить транзакции, одновременное выполнение которых может привести к взаимным блокировкам или к тайм-аутам блокировки. Это может произойти в том случае, если приложение пользователя задает очень продолжительные транзакции, которые обновляют много ресурсных объектов. Не забывайте, что взаимная блокировка – это результат выполнения последовательности операций с базой данных, которые были инициированы программным кодом приложения, исполняющегося «поверх» продукта Process Server. Process Server изменяет базу данных от имени этого приложения. Помимо этих обновлений, инициированных приложением, имеют место определенные обновления внутреннего состояния самого механизма BPC, призванные поддержать состояние исполняющихся экземпляров. Приложение пользователя может войти в состояние взаимной блокировки с обновлением этого типа. Чтобы избежать таких взаимных блокировок, можно в пользовательском приложении изменить или добавить границы транзакций, а также сделать транзакции короче. Благодаря механизму обнаружения и устранения взаимных блокировок каждая взаимная блокировка в конечном итоге устраняется без негативного воздействия на функциональные возможности приложения. Пострадать может лишь производительность – если взаимные блокировки происходят слишком часто. Если дело обстоит подобным образом, может помочь настройка базы данных и системы, хотя в некоторых случаях требуется оптимизация приложения. Обычно взаимные блокировки выявляются на этапе тестирования приложения – при выполнении параллельных тестов и при увеличении тестовой нагрузки. Чем выше уровень параллелизма и чем больше продолжительность транзакции, тем выше вероятность возникновения взаимных блокировок и тайм-аутов блокировки. Выявление тайм-аутов и взаимных блокировокНастройка нагрузочных тестов и тестов производительности на анализ взаимных блокировокЧтобы проанализировать первопричину взаимных блокировок или тайм-аутов, вам потребуется набор трассировочных файлов и системных журналов от различных систем. Эти файлы должны соответствовать одному и тому же периоду, что позволит обеспечить корреляцию всей информации. Перед запуском тестов необходимо настроить следующие свойства и инструменты с целью получения полного набора журнальных файлов и другой информации. Различные типы взаимных блокировокСамый быстрый способ собрать сведения обо всех типах взаимных блокировок состоит в том, чтобы проанализировать выходную информацию монитора db2evmon, которая уже была разъяснена выше. Ищите имена таблиц, SQL-запросы и типы блокировок. Существует еще одна ситуация, характерная для процессов с обработчиком событий. Поскольку обработчик событий – это параллельный поток, он должен обновить область экземпляра процесса после его завершения. Иногда сам процесс должен обновить свою область после своего завершения. В некоторых случаях, когда границы транзакции не установлены должным образом, это может привести к взаимным блокировкам. Следует убедиться в том, что все текущие транзакции завершены до выхода из обработчика событий и из области процесса. ЗаключениеИз этой статьи вы узнали, как обнаруживать и устранять взаимные блокировки и тайм-ауты в приложениях продукта WebSphere Process Server. Одновременно с этим вы узнали, как делать моментальные снимки DB2, как анализировать их и выходную информацию монитора DB2 Event Monitor, а также как осуществлять трассировку BPC. Вы научились исследовать результаты трассировки, находить потоки Process Server, вовлеченные во взаимную блокировку, связывать их с кодом BPEL-приложения и вносить изменения в этот код для устранения проблем. 6 Все, что делает таймер, аппаратно - он инициирует прерывание через определенные интервалы времени. Все остальное делается программно. Для работы часов, необходим драйвер часов. В обязанности драйвера входит: · Следить за текущим временем · Не позволять процессам работать больше, чем им положено (при запуске процесса планировщик записывает в счетчик выделенное процессу время) · Вести учет использования процессора · Поддерживать следящие таймеры для ОС (создаются виртуальные таймеры) · Ведут наблюдение, анализ и сбор статистики При 60 Грц 32-разрядный счетчик переполнится через два года. Три способа реализации текущего времени: 1. Можно использовать 64-разрядный счетчик 2. Можно хранить время не в тиках, а в секундах, но нужен дополнительный счетчик, переводящий секунды в тики. 3. Можно учитывать время только с момента загрузки системы, а не с 1 января 1970 года 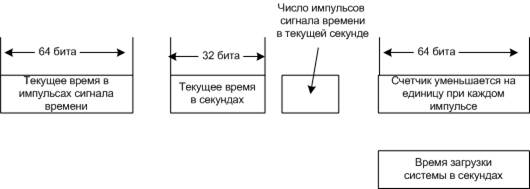 Три способа реализации текущего времени Таймеры(также называемые часами)очень важны для работы любой многозадач ной системы по ряду причин. Среди многих других задач, они следят за временем суток и не позволяют одному процессу надолго занять центральный процессор. В компьютерах широко применяются два типа таймеров. Обе схемы сильно отли чаются от наручных и настольных часов. Наиболее простые компьютерные часы привязываются по частоте к линии питания переменного напряжения 110 или 220 В и вызывают прерывания при каждом цикле напряжения с частотой 50 или 60 Гц. Такие часы очень широко применялись ранее, но сейчас являются редкостью. Другой тип часов состоит из трех компонентов: кварцевого генератора, счетчи ка и регистра хранения, как показано на рисунке: Если взять кусок кристалла квар ца правильного размера и установить его в оправу под давлением, то можно заста вить его колебаться и выдавать электрический сигнал с частотой в несколько сот мегагерц. Частота зависит от конкретного кристалла, но каждый кристалл выдер живает эту частоту с достаточно высокой точностью. С помощью электроники эту частоту можно поднять до 1 ГГц или даже до еще более высокой частоты. По край ней мере, одна такая схема обязательно присутствует в каждом компьютере, обес печивая сигнал синхронизации для различных цепей компьютера. Этот сигнал подается на вход декрементного счетчика. Когда содержимое счетчика достигает нуля, он вызывает прерывание центрального процессора. У программируемого таймера обычно есть несколько режимов работы. В режи ме одновибратора при запуске таймера содержимое регистра хранения копирует ся в счетчик. Затем содержимое счетчика уменьшается на единицу при каждом импульсе от кристалла. Когда счетчик достигает нуля, он вызывает прерывание и останавливается до тех пор, пока он не будет снова явно запущен программным обеспечением. В режиме генератора прямоугольных импульсов при достижении счетчиком нуля инициируется прерывание, а содержимое регистра хранения авто матически копируется в счетчик, и весь процесс повторяется снова бесконечно. Преимущество программируемого таймера состоит в том, что частота преры ваний от него может управляться программно. Если используется кристалл с ча стотой колебаний 500 МГц, то счетчик получает импульс каждые 2 нс. При ис пользовании 32-разрядного регистра можно запрограммировать возникновение прерываний через равные интервалы времени от 2 не до 8,6 с, называемые тиками. Микросхемы программируемых таймеров обычно содержат два или три незави симо программируемых счетчика и помимо этого обладают целым рядом других функций (например, могут увеличивать, а не уменьшать значение счетчика, не инициировать прерываний и т. д.). Чтобы показания таймера не терялись, пока питание компьютера выключено, часы большинства компьютеров питаются от аккумулятора. Показания часов считываются при загрузке операционной системы. Если таких часов у компьютера нет, операционная система может запросить дату и время при запуске. Кроме того, си стема может узнать эти сведения по сети от удаленного хоста. В любом случае эти время и дата транслируются в количество интервалов таймера с какого-либо мо мента, например полуночи 1 января 1970 года по всеобщему скоординированно му времени (UTC, Universal Coordinated Time), как это делает, например, система UNIX. До 1928 года время UTC называлось средним временем по Гринвичу (GMT, Greenwich Mean Time). В системе Windows время отсчитывается от 1 января 1980 года. При каждом прерывании от таймера счетчик времени увеличивается на единицу. В операционной системе обычно присутствуют программы, позволяю щие скорректировать показания системных часов. 7 Мультипроцессор (от англ. multiprocessor, multiprocessing[1]) — это подкласс многопроцессорных компьютерных систем, где есть несколько процессоров и одно адресное пространство, видимое для всех процессоров. В таксономии Флиннамультипроцессоры относятся к классу SM-MIMD-машин. Мультипроцессор запускает одну копию ОС с одним набором таблиц, в том числе тех, которые следят какие страницы памяти свободны. По ролям, которые играют процессоры в мультипроцессорной системе, различают: симметричные мультипроцессоры(SMP) - все процессоры играют одинаковую роль и имеют одинаковый доступ к памяти и периферии, и асимметричные мультипроцессоры (AMP) - процессоры играют разные роли или по-разному обращаются к периферийным устройствам. Технология AMP была лишь переходной в 60-х годах до того момента, когда была отработана технология SMP. По способу адресации памяти различают несколько типов мультипроцессоров, среди которых: UMA (Uniform Memory Access), NUMA (Non Uniform Memory Access) и COMA (Cache Only Memory Access). Помимо этого мультипроцессоры могут быть гомогенного типа, когда все процессоры в системе одинаковы, или гетерогенного типа - когда процессоры в системе разного типа. В программировании мультипроцессоров можно использовать две модели программирования: многопоточность, где на каждом процессоре запускается поток исполнения, и они обмениваются друг с другом данными через общие переменные в общей памяти, либо (более сложный) message passing, когда на каждом процессоре запускается отдельный процесс, и они обмениваются данными друг с другом путём обмена сообщениями. Многопоточное программирование используется либо явно (в компилируемых языках программирования с помощью системного API (например в C/C++ с помощью POSIX Threads, а также с помощью boost::thread или std::thread в C++, начиная со стандарта C++11), в интерпретируемых языках (Java и C#) с помощью конструкций языка), либо неявно (декларативно с помощью директив компилятора (OpenMP) или автоматически самим компилятором (High Performance Fortran)). Мультипроцессорные операционные системы предоставляют пользователям все возможности многозадачных систем, и, кроме того, обеспечивают одновременное решение двух наиболее важных задач, размещенных в одном или разных разделах оперативной памяти. Кроме псевдопараллельной работы осуществляется параллельное решение двух задач разными процессорами. При выходе из строя одного из процессоров комплекс переходит в однопроцессорный режим функционирования, обеспечивающий такие же возможности, как и однопроцессорная многозадачная операционная система. Многозадачная мультипроцессорная операционная система ( работает только на УВК СМ-2) отличается от многозадачной однопроцессорной системы тем, что обеспечивает одновременное выполнение на двух процессорах двух старших по приоритету задач. Задачи, как и операционная система, хранятся в общей оперативной памяти УВК в единственном экземпляре и никак априори не привязаны к процессорам. Если задача, решаемая одним из процессоров, переходит в состояние ожидания какого-либо внешнего по отношению к ней события, то этот процессор переключается на решение менее важной задачи, которая не выполняется другим процессором. Если для процессора не оказывается задачи, готовой к выполнению, процессор переводится в состояние динамического останов Простейший способ организации мультипроцессорных операционных систем состоит в том, чтобы статически разделить оперативную память по числу центральных процессоров и дать каждому центральному процессору свою собственную память с собственной копией операционной системы. [6] Наконец, к этой книге было добавлено множество разделов, а многие разделы были серьезно пересмотрены. Это разделы по темам: графические интерфейсы пользователя, мультипроцессорные операционные системы, управление энергопотреблением для переносных компьютеров, надежные системы, вирусы, сетевые терминалы, файловые системы для компакт-дисков, RAID, мягкие таймеры, стабильные хранилища, справедливое планирование и новые алгоритмы замещения страниц. Добавлено множество новых задач и многие старые задачи были пересмотрены. Сборник задач с решениями может быть предоставлен профессорам, использующим эту книгу на своем курсе. Они могут получить копию книги у своего локального представителя издательства Prentice Hall. Кроме того, было добавлено более 250 новых ссылок на новейшую литературу, чтобы привести книгу в соответствие с современностью. 8 Центральные процессоры, входящие в состав мультипроцессора, часто нуждаются в синхронизации. Только что была рассмотрена ситуация, при которой критические области ядра и таблицы должны быть защищены мьютексами. А теперь мы присмотримся к тому, как эта синхронизация работает в мультипроцессоре. Вскоре станет ясно, что здесь далеко не все так просто. Для начала надо будет выбрать правильные примитивы синхронизации. Если процесс на однопроцессорной системе осуществляет системный вызов, который требует доступа к некой критической таблице, находящейся в ядре, то программный код ядра может до предоставления доступа к таблице просто запретить прерывания. Но на мультипроцессорной системе запрет прерываний воздействует только на тот центральный процессор, который их и запретил. Остальные центральные процессоры продолжат свою работу и все равно смогут получить доступ к критической таблице. Следовательно, требуется подходящий мьютекс-протокол, соблюдаемый всеми центральными процессорами и гарантирующий работу взаимного исключения. Основой любого практического мьютекс-протокола является специальная команда процессора, позволяющая провести проверку и установку значения за одну неделимую операцию. На рис. 2.16 был показан пример использования команды TSL (Test and Set Lock — проверить и установить блокировку) при реализации критических областей. Было рассмотрено, что эта команда считывает слово памяти в регистр процессора. Одновременно она записывает 1 (или другое ненулевое значение) в слово памяти. Конечно, для выполнения операций чтения из памяти и записи в память требуются два цикла обращения к шине. На однопроцессорной машине команда ТБЬ работает так, как и ожидалось, поскольку команда процессора не может быть прервана на полпути. А теперь подумаем, что может произойти на мультипроцессоре. На рис. 8.10 показано наихудшее из возможных развитие ситуации, где в качестве блокиратора используется слово памяти по адресу 1000, имеющее начальное значение 0. На шаге 1 центральный процессор 1 считывает слово и получает значение 0. На шаге 2, перед тем как у процессора 1 появится возможность переписать значение слова на 1, на сцену выходит центральный процессор 2 и также считывает это слово, получая значение 0. На шаге 3 центральный процессор 1 записывает в это слово значение 1. На шаге 4 центральный процессор 2 также записывает значение 1 в это слово. Оба процессора получили в результате работы команды ТБЬ значение 0, поэтому теперь они оба имеют доступ к критической области и взаимного исключения не происходит.
Для предотвращения проблемы команда TSL должна сначала заблокировать шину, препятствуя доступу к ней со стороны других центральных процессоров, затем осуществить обе операции доступа к памяти, после чего разблокировать шину. Как правило, блокировка шины осуществляется путем запроса шины с использованием обычного протокола ее запроса с последующим выставлением логической единицы на какой- нибудь специальной линии шины, до тех пор пока не будут завершены оба цикла обращения к шине. Пока на этой специальной линии шины выставлена единица, доступа к шине не получит никакой другой центральный процессор. Эта команда может быть реализована только на шине, у которой имеются необходимые линии и аппаратный протокол для их использования. Все современные шины обладают такими возможностями, но на более ранних шинах, не обладающих ими, правильно реализовать команду TSL невозможно. Поэтому был изобретен протокол Петерсона для синхронизации сугубо программным путем (Peterson, 1981). При правильных реализации и использовании команды TSL гарантируется работоспособное взаимное исключение. Но этот метод взаимной блокировки использует спин-блокировку (spin lock), потому что запрашивающий центральный процессор просто находится в коротком цикле, с максимально возможной скоростью тестируя блокировку. При этом совершенно напрасно тратится время запрашивающего центрального процессора (или процессоров), и, кроме того, может быть также слишком нагружена шина или память, существенно замедляя нормальное функционирование других центральных процессоров. На первый взгляд может показаться, что конкуренция в борьбе за шину должна быть устранена за счет кэширования, но это не так. Теоретически, как только запрашивающий центральный процессор считал слово блокировки, он должен получить его копию в своем кэше. Пока ни один из других центральных процессоров не пытается использовать блокировку, запрашивающий центральный процессор должен обладать способностью выходить за пределы своего кэша. Когда центральный процессор, владеющий блокировкой, делает запись в слово, чтобы снять блокировку, протокол кэша автоматически аннулирует все копии этого слова в удаленных кэшах, требуя извлечь заново правильное значение. Проблема в том, что кэши работают с блоками по 32 или 64 байта. Перед тем как перейти к рассмотрению вопросов планирования работы мультипроцессоров, нужно четко определить, что именно подвергается планированию. В былые времена, когда все процессы были однопоточными, ответ был один: следовало планировать процессы, поскольку больше планировать было нечего. Но все современные операционные системы поддерживают многопоточные процессы, что значительно усложняет планирование. Играет роль и то, с какими потоками мы имеем дело: с потоками в пространстве ядра или с потоками в пользовательском пространстве. Если потоки образуются с помощью библиотеки, находящейся в пользовательском пространстве, и ядро о них ничего не знает, то планирование осуществляется, как и всегда, на основе процессов. Если ядро даже ничего не знает о существовании потоков, то вряд ли оно сможет заниматься их планированием. А вот с потоками в пространстве ядра все обстоит по-другому. Здесь ядро знает обо всех потоках и может выбирать из тех потоков, которые принадлежат процессу. В этих системах ядро стремится выбрать для выполнения поток, а процесс, которому он принадлежит, играет в алгоритме выбора потока лишь незначительную роль (или вообще не играет никакой роли). Далее речь пойдет о планировании потоков, но, разумеется, в системах с однопоточными процессами или потоками, реализованными в пользовательском пространстве, объектом планирования являются процессы. Что именно подвергать планированию — процессы или потоки, не является единственным вопросом, касающимся планирования. В однопроцессорной системе планирование ведется в одном измерении. Здесь нужно многократно отвечать лишь на один вопрос: какой поток должен быть запущен следующим? В мультипроцессорных системах планирование ведется в двух измерениях. Планировщик должен решить, какой поток запускать и на каком центральном процессоре следует это сделать. Это дополнительное измерение существенно усложняет планирование на мультипроцессорах. Другим усложняющим фактором является то, что в некоторых системах все потоки не связаны друг с другом в силу принадлежности к разным процессам и не могут ничего сделать друг с другом. В других системах они сведены в группы, где все они принадлежат одному и тому же приложению и работают вместе. Примером первого варианта служит серверная система, в которой независимые друг от друга пользователи запускают независимые процессы. Потоки, относящиеся к разным процессам, не связаны друг с другом, и работа каждого из них может планироваться без оглядки на все остальные. Второй вариант регулярно проявляется в средах разработки программ. Большие системы часто состоят из некоторого количества заголовочных файлов, содержащих макросы, определения типов и объявления переменных, которые используются существующими файлами кода. При изменении заголовочного файла должны быть перекомпилированы все файлы кода, включающие данный заголовочный файл. Для управления процессом разработки часто используется программа make. Будучи вызванной, программа make приступает к компиляции только тех файлов кода, которые должны быть перекомпилированы из-за изменений, происшедших в заголовочных файлах или файлах кода. Объектные файлы, сохраняющие свою актуальность, заново не создаются. Первоначальная версия программы make выполняла свою задачу последовательно, но ее современные версии разработаны так, чтобы мультипроцессорные системы могли запускать все компиляции одновременно. Если требуется провести десять компиляций, то нет никакого смысла в планировании немедленного запуска девяти из них и откладывании в долгий ящик последней компиляции, поскольку пользователь не будет считать работу завершенной до тех пор, пока не будет завершена последняя компиляция. В таком случае имеет смысл рассматривать потоки, осуществляющие компиляцию как группу, и принимать это во внимание при планировании их работы. Кроме того, иногда полезно планировать работу потоков, осуществляющих интенсивный обмен данными, скажем, в режиме «производитель — потребитель», не только в одно и то же время, но и близко друг к другу в пространстве. Например, они могут получить преимущество от совместного использования кэшей. Подобно этому, в NUMA- архитектурах может быть полезно дать им возможность доступа к той памяти, которая будет находиться поблизости. 9 Многомашинная вычислительная система (ММС) содержит несколько ЭВМ, каждая их которых имеет свою оперативную память (ОП) и работает под управлением своей операционной системы, а также средства обмена информацией между машинами. Реализация обмена информацией происходит в конечном итоге путем взаимодействия операционных систем разных машин между собой. Это ухудшает динамические характеристики процессов межмашинного обмена данными. Применение многомашинных систем позволяет повысить надежность вычислительных комплексов. При отказе в одной машине обработку данных может продолжать другая машина комплекса. Однако можно заметить, что при этом оборудование комплекса недостаточно эффективно используется для этой цели. Достаточно в этой системе в каждой из машин выйти из строя хотя бы по одному устройству, как вся система становится неработоспособной. Этих недостатков лишены многопроцессорные системы (МПС). В них процессоры обретают статус рядовых агрегатов вычислительной системы, которые подобно другим агрегатам, таким как модули памяти, каналы, ПУ, включаются в состав системы в нужном количестве. Многопроцессорная система содержит несколько процессоров, работающих с общей ОП, и управляется одной общей операционной системой. В МПС по сравнению с ММС достигается более быстрый обмен информацией между процессорами через общую ОП, и поэтому может быть получена более высокая производительность, более быстрая реакция на ситуации, возникающие внутри системы и в ее внешней среде, и более высокая надежность и живучесть, так как система сохраняет работоспособность пока работоспособны хотя бы по одному модулю каждого типа устройства. Однако построение ММС из стандартно выпускаемых ЭВМ с их стандартными операционными системами значительно проще, чем построение МПС, требующих преодоления определенных трудностей, возникающих при реализации общего поля ОП, и, главное, трудоемкой разработки специальной операционной системы. Примером реализации МПС из стандартно выпускаемых процессоров Pentium является плата, построенная на чипсете фирмы INTEL PR440FX (второе название Providence) и операционной системы Windows NT (New Technology). Важной структурной особенностью ВС является способ организации связи между устройствами (модулями) системы. Он непосредственно влияет на быстроту обмена информацией между модулями системы, а следовательно, и на производительность, быстроту реакции на поступающие запросы, приспособленность к изменению конфигурации, и, наконец, на размеры аппаратурных затрат на осуществление межмодульных связей. В частности, от организации межмодульных связей зависит частота возникновения конфликтов при обращении процессора к одним и тем же ресурсам и потери производительности из-за конфликтов. Используются следующие способы организации межмодульных связей: • многоуровневые связи, соответствующие иерархии интерфейсов ЭВМ; • общая шина; • регулярные связи между модулями; • коммутатор межмодульных связей. Принципы организации МПС и ММС существенно отличаются в зависимости от их предназначения. Поэтому целесообразно различать: 1. ВС, ориентированные на достижение сверхвысокой производительности. 2. ВС, ориентированные на повышение надежности и живучести. Многомашинная ВС (ММС) содержитнесколько ЭВМ, каждая из которых имеет свою ОП и работает под управлением своей операционной системы, а также средства обмена информацией между машинами. Реализация обмена информацией происходит, в конечном счете, путем взаимодействия операционных систем машин между собой. Это ухудшает динамические характеристики процессов межмашинного обмена данными. Применение многомашинных систем позволяет повысить надежность вычислительных комплексов. При отказе в одной машине обработку данных может продолжать другая машина комплекса. Однако можно заметить, что при этом оборудование комплекса недостаточно эффективно используется для этой цели. Достаточно в системе в каждой ЭВМ выйти из строя по одному устройству (даже разных типов), как вся система становится неработоспособной. Однако построение многомашинных систем из серийно выпускаемых ЭВМ с их стандартными операционными системами значительно проще, чем построение МПС, требующих преодоления определенных трудностей, возникающих при реализации общего поля памяти, и, главное, трудоемкой разработки специальной операционной системы.Работа любой многомашинной системы определяется двумя главными компонентами: высокоскоростным механизмом связи процессоров и системным программным обеспечением, которое предоставляет пользователям и приложениям прозрачный доступ к ресурсам всех компьютеров, входящих в комплекс. В состав средств связи входят программные модули, которые занимаются распределением вычислительной нагрузки, синхронизацией вычислений и реконфигурацией системы. Если происходит отказ одного из компьютеров комплекса, его задачи могут быть автоматически переназначены и выполнены на другом компьютере. Если в состав многомашинной системы входят несколько контроллеров внешних устройств, то в случае отказа одного из них, другие контроллеры автоматически подхватывают его работу. Таким образом, достигается высокая отказоустойчивость комплекса в целом. Помимо повышения отказоустойчивости, многомашинные системы позволяют достичь высокой производительности за счет организации параллельных вычислений. По сравнению с мультипроцессорными системами возможности параллельной обработки в многомашинных системах ограничены: эффективность распараллеливания резко снижается, если параллельно выполняемые задачи тесно связаны между собой по данным. Это объясняется тем, что связь между компьютерами многомашинной системы менее тесная, чем между процессорами в мультипроцессорной системе, так как основной обмен данными осуществляется через общие многовходовые периферийные устройства. Говорят, что в отличие от мультипроцессоров, где используются сильные программные и аппаратные связи, в многомашинных системах аппаратные и программные связи между обрабатывающими устройствами являются более слабыми. Территориальная распределенность в многомашинных комплексах не обеспечивается, так как расстояния между компьютерами определяются длиной связи между процессорным блоком и дисковой подсистемой. |