База данных-понятия. Классификация по
 Скачать 0.55 Mb. Скачать 0.55 Mb.
|

6.4.Объектно-реляционные СУБД.Другой способ объединения возможностей реляционного и объектно-ориентированного подхода к управлению данными предложил известный американский ученый Майкл Стоунбрейкер. Согласно его воззрениям реляционную СУБД нужно просто дополнить средствами доступа к сложным данным. При этом ядро СУБД не требует переработки, как в случае с SQL3, и сохраняет все присущие реляционным системам достоинства. Объектные расширения реализуются в виде надстроек, которые динамически подключаются к ядру. На основе этой идеи под руководством М.Стоунбрейкера в университете Беркли (Калифорния, США) была разработана СУБД Postgres, которая имеет следующие ключевые возможности:
SELECT владелец FROM участки WHERE расположение_участка IN заданная_область
Реализация описанных свойств позволила М.Стоунбрейкеру так спозиционировать объектно-реляционные СУБД относительно реляционных и объектно-ориентированных систем:
Кроме того, Postgres обладает свойствами, которые позволяют назвать его темпоральной СУБД. При любом обновлении записи создается ее новая копия, а предыдущий вариант продолжает существовать вечно. Даже после удаления записи все накопленные варианты сохраняются в базе данных. Можно извлечь из базы данных любой вариант записи, если указать момент или интервал времени, когда этот вариант был текущим. Достижение этих свойств позволило также пересмотреть схемы журнализации и отката транзакций. Сейчас все вышеописанные функции развиваются в коммерческой СУБД Informix. Тем не менее, проект Postgres продолжается до сих пор, уже международной группой независимых разработчиков. К возможностям СУБД добавлены поддержка SQL (в перспективе планируется обеспечение совместимости со стандартом ANSI SQL-92), поэтому несколько было изменено название СУБД - теперь это PostgreSQL, оптимизатор запросов на основе генетических алгоритмов и многое другое. При этом PostgreSQL остается свободно распространяемой системой, причем бесплатно можно получить как исходный код, так и бинарные файлы, собранные для той или иной платформы (поддерживаются практически все разновидности ОС Unix). Более подробная информация находится на сервере www.postgresql.org. 6.5.Нечисловая обработка и ассоциативные процессоры.В предыдущих разделах данной главы мы говорили о недостатках реляционных СУБД и способах их преодоления. Теперь настала пора обсудить некоторые более общие вопросы использования баз данных и их поддержки вычислительными архитектурами. Компьютеры, как известно, были созданы для удовлетворения потребностей исследователей, решавших вычислительные задачи. Однако, со временем все чаще и чаще они стали использоваться для решения невычислительных задач, а именно для хранения, поиска и преобразования документов (инофрмации). Когда компьютеры стали широко применяться в таких задачах, обнаружилась неприспособленность их традиционной (фоннеймановской) архитектуры для этих целей. Архитектура компьютера, разработанная Дж. Фон Нейманом показана на следующем рисунке. 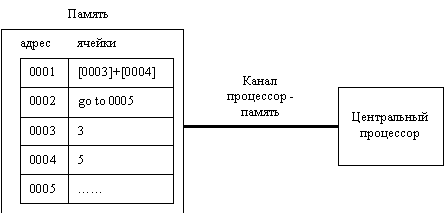 Центральный процессор связан каналом с памятью, представляющей набор ячеек, каждая из которых харакетризуется адресом (последовательным номером). В ячейках хранятся команды (вычислительные, а также условного и безусловного переходов на другую ячейку), которые процессор последовательно извлекает и обрабатывает. Некоторые команды могут требовать каких-либо данных, которые также хранятся в ячейках памяти. Ссылка на данные осуществялется при этом при помощи указания адресов хранящих их ячеек. Таким образом, способы построения запоминающих устройств и способы обращения к ним центрального процессора у современных ЭВМ ориентированы на числовую обработку. В качестве примера рассмотрим фрагмент программы, связанный с обработкой массива: for i=1 to 10 do a[i]=a[i]+b[i]; При обращении к массиву компьютер определяет начальный адрес массива и по значению индекса выбирает его конкретный элемент (адрес элемента = начальный адрес + смещение). Теперь рассмотрим пример, связанный с выборкой из базы данных: SELECT имя FROM служащие WHERE возраст < 35 AND зарплата > 400 Здесь имена служащих выбираются из файла не по адресу, а по содержимому полей "возраст" и "зарплата". Этот способ адресации называется ассоциативным обращением или ассоциативной адресацией. Поскольку в современных компьютерах для нечисловой обработки используется та же архитектура, что и для числовой, используются методы эмуляции ассоциативного доступа - создается специальная таблица для перевода ассоциативного запроса в соответствующий адрес - индекс. В общем виде архитектура нечисловой обработки должна удовлетворять следующим требованиям:
К сожалению, до настоящего времени не достигнуто больших успехов в создании ассоциативных систем. Более подробно с этим вопросом можно ознакомиться в книге Э.Озкарахана (см. список литературы). |