Коллоквиум сұрақтары жауаптары (2) (копия). Коллоквиум сратары
 Скачать 2 Mb. Скачать 2 Mb.
|

|
MPI_Irecv. Возврат из подпрограммы происходит немедленно, без ожидания окончания приема данных. Определить момент окончания приема можно с помощью подпрограмм MPI_Wait или MPI_Test с соответствующим параметром request. Как и в блокирующих операциях часто возникает необходимость опроса параметров полученного сообщения без его фактического чтения. Это делается с помощью функции MPI_Iprobe. Параметры:
Функции MPI_Wait(),MPI_Test(), принцип работы, приведите примеры. MPI_Wait MPI_Wait ожидает завершения неблокирующей операции. То есть, в отличие от MPI_Test, MPI_Wait будет блокировать до завершения основной неблокирующей операции. Поскольку неблокирующая операция немедленно возвращается, она делает это до завершения основной MPI-процедуры. Ожидание завершения этой процедуры и есть то, для чего предназначен MPI_Wait. Существуют разновидности MPI_Wait для одновременного мониторинга нескольких обработчиков запросов: MPI_Waitall, MPI_Waitany и MPI_Waitsome. Синопсис int MPI_Wait(MPI_Request *request, MPI_Status *status) Входные параметры Запрос - request запрос (хэндл) Выходные параметры Статус -status объект состояния (Status). Может быть MPI_STATUS_IGNORE. Поле MPI_ERROR возврата статуса устанавливается только в том случае, если возврат из MPI-подпрограммы - MPI_ERR_IN_STATUS. Этот класс ошибок возвращается только теми процедурами, которые принимают массив аргументов состояния (MPI_Testall, MPI_Testsome, MPI_Waitall и MPI_Waitsome). Во всех остальных случаях значение поля MPI_ERROR в статусе остается неизменным. Для операций отправки единственное использование статуса - это MPI_Test_cancelled или в случае, если произошла ошибка в одной из четырех процедур, которые могут вернуть класс ошибки MPI_ERR_IN_STATUS, в этом случае поле MPI_ERROR в статусе будет установлено. В этом случае значение будет установлено в MPI_SUCCESS для любой операции отправки или приема, которая завершилась успешно, или MPI_ERR_PENDING для любой операции, которая и не провалилась и не завершилась. Пример: int main(int argc, char* argv[]) { MPI_Init(&argc, &argv); // Убедиться что будет использовано всего 2 процесса int size; MPI_Comm_size(MPI_COMM_WORLD, &size); if (size != 2) { printf("Это приложение предназначено для запуска с помощью 2 процессов.\n"); MPI_Abort(MPI_COMM_WORLD, EXIT_FAILURE); } // Задаем ранги процессам int my_rank; MPI_Comm_rank(MPI_COMM_WORLD, &my_rank); if (my_rank == 0) { // Мастер процесс отправляет сообщение int buffer = 12345; printf("MPI-процесс %d отправляет значение %d.\n", my_rank, buffer); MPI_Ssend(&buffer, 1, MPI_INT, 1, 0, MPI_COMM_WORLD); } else { // Служебный процесс принимает сообщение int received; MPI_Request request; MPI_Irecv(&received, 1, MPI_INT, 0, 0, MPI_COMM_WORLD, &request); // Выполните некоторые другие действия, пока выполняется MPI_Recv. printf("MPI-процесс %d выдал MPI_Irecv и перешел к печати этого сообщения.\n", my_rank); // Выполните некоторые другие действия, пока выполняется MPI_Recv. printf("MPI-процесс %d ожидает завершения базового MPI_Recv.\n", my_rank); MPI_Wait(&request, MPI_STATUS_IGNORE); printf("MPI_Wait завершен, что означает, что базовый запрос (т.е. MPI_Recv) также завершен..\n"); } MPI_Finalize(); return EXIT_SUCCESS; } 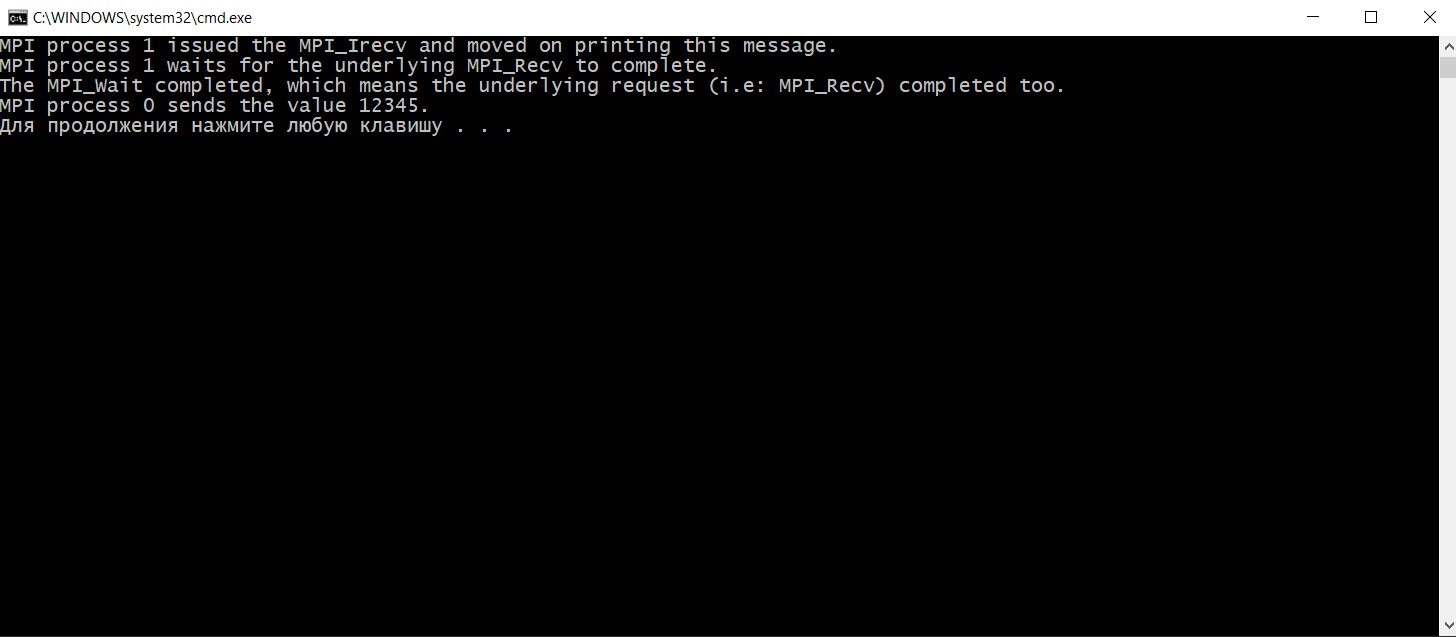 MPI_TEST MPI_Test проверяет, завершена ли неблокирующая операция в заданное время. То есть, в отличие от MPI_Wait, MPI_Test не будет ждать завершения основной неблокирующей операции. Поскольку неблокирующая операция немедленно возвращается, она делает это до завершения основной MPI-процедуры. Проверка завершения этой процедуры - это то, для чего предназначен MPI_Test. Существуют разновидности MPI_Test для проверки нескольких обработчиков запросов одновременно: MPI_Testall, MPI_Testany и MPI_Testsome. Синтаксис int MPI_Test(MPI_Request* request, int* flag, MPI_Status* status); запрос Обработчик запроса на неблокирующую процедуру для ожидания. флаг Переменная, в которой хранится результат проверки; true, если основная неблокирующая процедура завершена, false в противном случае. статус Переменная, в которой хранится статус, возвращенный соответствующей неблокирующей процедурой. Если статус не нужен, может быть передан MPI_STATUS_IGNORE. Значения возврата *Код ошибки, возвращенный в результате тестирования запроса. *MPI_SUCCESS: процедура успешно завершена. ПРИМЕР: #include #include #include int main(int argc, char* argv[]) { MPI_Init(&argc, &argv); // Получить количество процессов и проверить, что используется только 2 процесса int size; MPI_Comm_size(MPI_COMM_WORLD, &size); if(size != 2) { printf("Это приложение предназначено для запуска с помощью 2 процессов.\n"); MPI_Abort(MPI_COMM_WORLD, EXIT_FAILURE); } // Получить звание int my_rank; MPI_Comm_rank(MPI_COMM_WORLD, &my_rank); if(my_rank == 0) { // “Ведущий" процесс MPI отправляет сообщение. int first_message = 12345; int second_message = 67890; MPI_Request request; // Ждать, пока приемник выдаст MPI_Test, предназначенный для отказа MPI_Barrier(MPI_COMM_WORLD); printf("[Process 0] Sends first message (%d).\n", first_message); MPI_Isend(&first_message, 1, MPI_INT, 1, 0, MPI_COMM_WORLD, &request); printf("[Process 0] Sends second message (%d).\n", second_message); MPI_Send(&second_message, 1, MPI_INT, 1, 0, MPI_COMM_WORLD); MPI_Wait(&request, MPI_STATUS_IGNORE); } else { // "Ведомый" процесс MPI получает сообщение. int first_message; int second_message; int ready; MPI_Request request; MPI_Irecv(&first_message, 1, MPI_INT, 0, 0, MPI_COMM_WORLD, &request); // Соответствующий send еще не был выдан, этот MPI_Test будет "провален". MPI_Test(&request, &ready, MPI_STATUS_IGNORE); if(ready) printf("[Process 1] MPI_Test #1: message received (%d).\n", first_message); else printf("[Process 1] MPI_Test #1: message not received yet.\n"); // Сообщите отправителю, что мы выдали MPI_Test, который должен был завершиться неудачей, теперь он может отправить сообщение. MPI_Barrier(MPI_COMM_WORLD); MPI_Recv(&second_message, 1, MPI_INT, 0, 0, MPI_COMM_WORLD, MPI_STATUS_IGNORE); printf("[Process 1] Second message received (%d), which implies that the first message is received too.\n", second_message); MPI_Test(&request, &ready, MPI_STATUS_IGNORE); if(ready) printf("[Process 1] MPI_Test #2: message received (%d).\n", first_message); else printf("[Process 1] MPI_Test #2: message not received yet.\n"); } MPI_Finalize(); return EXIT_SUCCESS; } 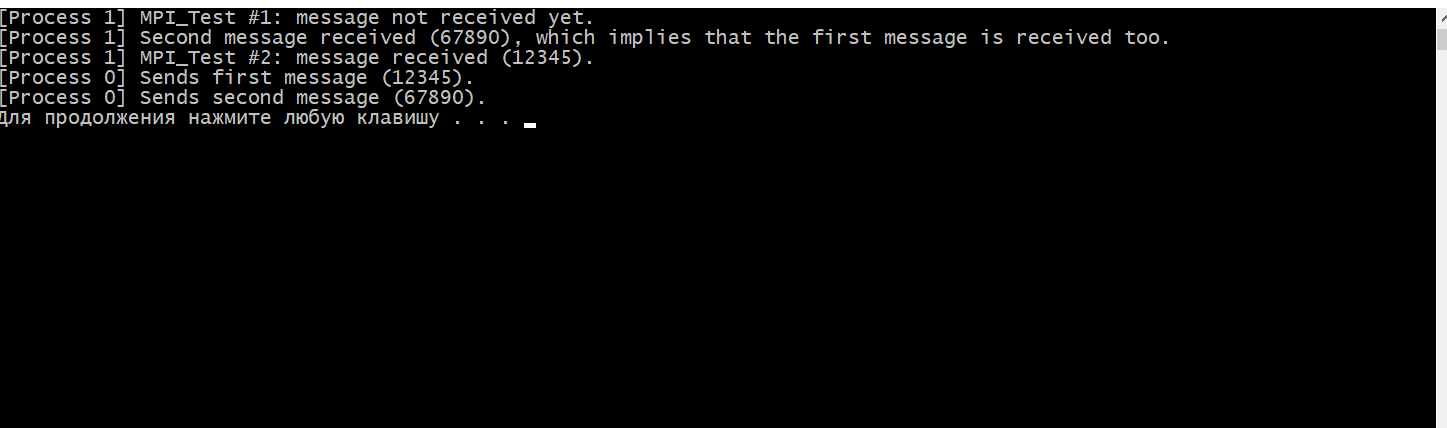 Функции MPI_Barrier(), MPI_Bcast() MPI_BARRIER() MPI_Barrier блокирует все MPI-процессы в данном коммуникаторе, пока все они не вызовут эту процедуру. СИНТАКСИС int MPI_Barrier(MPI_Comm communicator); Параметры: коммуникатор Коммуникатор, в котором находится барьер. Возвращаемое значение: *Код ошибки, возвращенный барьером. *MPI_SUCCESS: Процедура успешно завершена. ПРИМЕР #include #include #include int main(int argc, char* argv[]) { MPI_Init(&argc, &argv); // Get my rank int my_rank; MPI_Comm_rank(MPI_COMM_WORLD, &my_rank); printf("[MPI process %d] Я начинаю ждать у барьера.\n", my_rank); MPI_Barrier(MPI_COMM_WORLD); printf("[MPI process %d] Я знаю, что все процессы MPI ожидали на барьере.\n", my_rank); MPI_Finalize(); return EXIT_SUCCESS; } 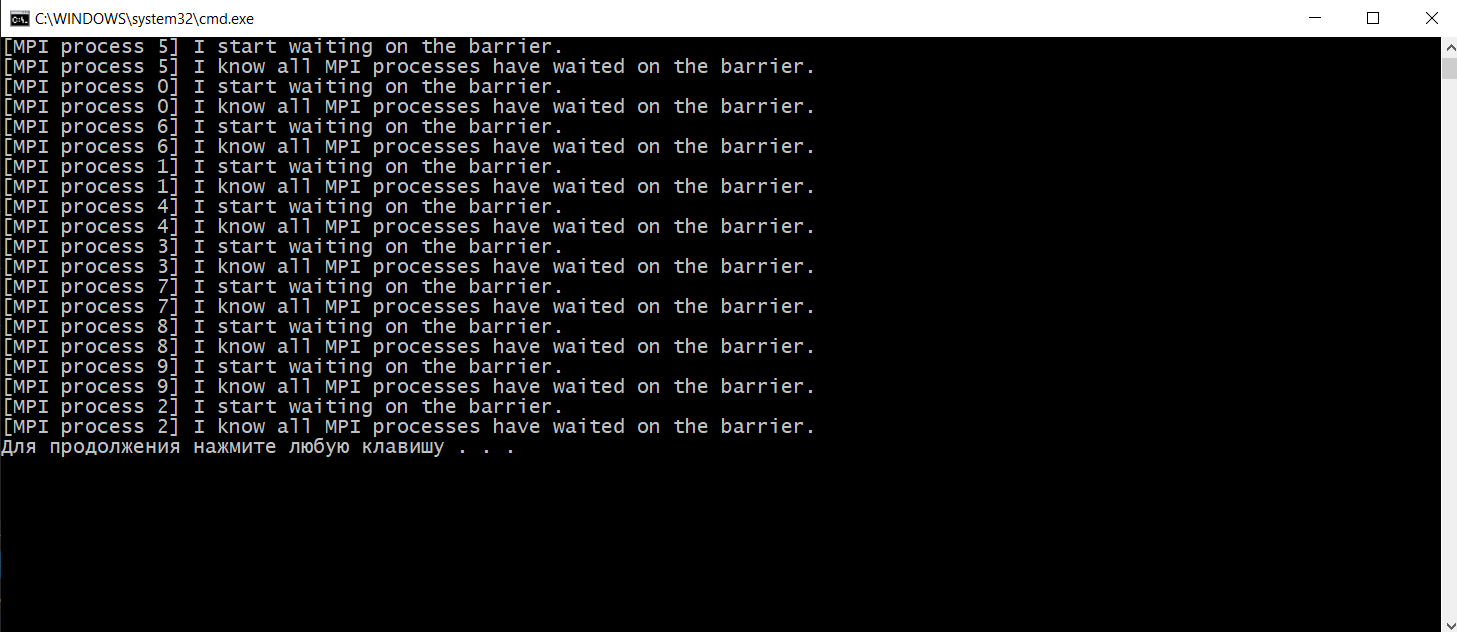 MPI_Bcast () MPI_Bcast передает сообщение от процесса всем другим процессам в том же коммуникаторе. Это коллективная операция; она должна быть вызвана всеми процессами в коммуникаторе. СИНТАКСИС int MPI_Bcast(void* buffer, int count, MPI_Datatype datatype, int emitter_rank, MPI_Comm communicator); Параметры buffer Буфер, из которого загружаются данные для трансляции, если вызывающий MPI-процесс является излучателем, или буфер, в который сохраняются транслируемые данные, если вызывающий MPI-процесс является приемником. count Количество элементов в транслируемом буфере. datatype Тип элемента в транслируемом буфере. emitter_rank Ранг MPI-процесса, который транслирует данные, все остальные процессы получают транслируемые данные. Communicator Коммуникатор, в котором происходит трансляция. Возвращаемое значение *Код ошибки, возвращенный из трансляции. *MPI_SUCCESS: Процедура успешно завершена. ПРИМЕР: #include #include #include int main(int argc, char* argv[]) { MPI_Init(&argc, &argv); // Получить звание в коммуникаторе int my_rank; MPI_Comm_rank(MPI_COMM_WORLD, &my_rank); // Определите ранг процесса излучателя эфира int broadcast_root = 0; int buffer; if(my_rank == broadcast_root) { buffer = 12345; printf("[MPI process %d] Я - корень вещания, и посылаю значение %d.\n", my_rank, buffer); } MPI_Bcast(&buffer, 1, MPI_INT, broadcast_root, MPI_COMM_WORLD); if(my_rank != broadcast_root) { printf("[MPI process %d] Я являюсь приемником вещания и получаю ценность %d.\n", my_rank, buffer); } MPI_Finalize(); return EXIT_SUCCESS; } 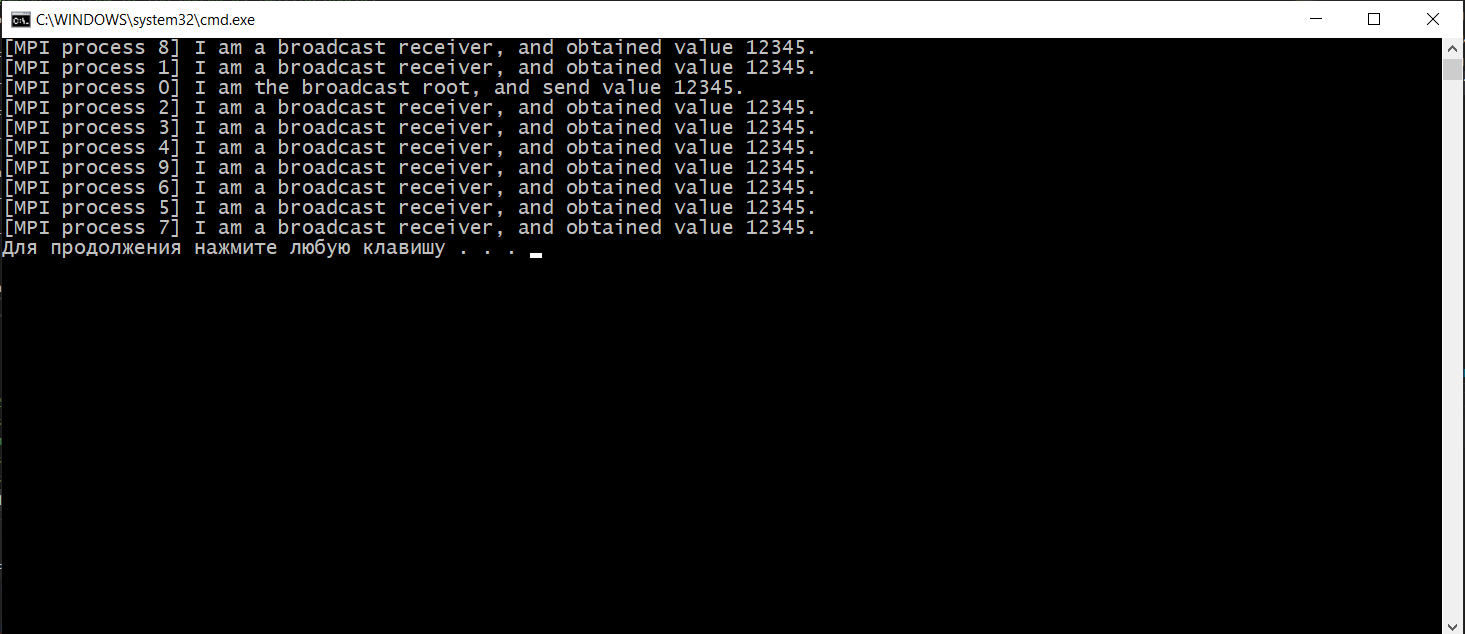 Функции MPI_Gather(), MPI_Gatherv(), MPI_Allgather(), MPI_Allgatherv(). Функции MPI_Scatter(), MPI_Scatterv(), MPI_Alltoall(). Глобальные вычислительные операции над распределенными данными. Функции MPI_Reduce(), MPI_Allreduce(), MPI_Reduce_scatter(). В параллельном программировании математические операции над блоками данных, распределенных по процессорам, называют глобальными операциями редукции. В общем случае операцией редукции называется операция, аргументом которой является вектор, а результатом - скалярная величина, полученная применением некоторой математической операции ко всем компонентам вектора. В частности, если компоненты вектора расположены в адресных пространствах процессов, выполняющихся на различных процессорах, то в этом случае говорят о глобальной (параллельной) редукции. Например, пусть в адресном пространстве всех процессов некоторой группы процессов имеются копии переменной var (необязательно имеющие одно и то же значение), тогда применение к ней операции вычисления глобальной суммы или, другими словами, операции редукции SUM возвратит одно значение, которое будет содержать сумму всех локальных значений этой переменной. Использование этих операций является одним из основных средств организации распределенных вычислений. В MPI глобальные операции редукции представлены в нескольких вариантах: с сохранением результата в адресном пространстве одного процесса (MPI_Reduce). с сохранением результата в адресном пространстве всех процессов (MPI_Allreduce). префиксная операция редукции, которая в качестве результата операции возвращает вектор. i-я компонента этого вектора является результатом редукции первых i компонент распределенного вектора (MPI_Scan). совмещенная операция Reduce/Scatter (MPI_Reduce_scatter). Функция MPI_Reduce выполняется следующим образом. Операция глобальной редукции, указанная параметром op, выполняется над первыми элементами входного буфера, и результат посылается в первый элемент буфера приема процесса root. Затем то же самое делается для вторых элементов буфера и т.д. С: int MPI_Reduce(void* sendbuf, void* recvbuf, int count, MPI_Datatype datatype, MPI_Op op, int root, MPI_Comm comm)
|