Коллоквиум сұрақтары жауаптары (2) (копия). Коллоквиум сратары
 Скачать 2 Mb. Скачать 2 Mb.
|

|
buffer- жіберілетін немесе қабылданатын деректерді сақтау орны; count-жіберілетін немесе қабылданатын нақты түрдегі деректер элементтерінің саны; type-ендірілген MPI арқылы берілетін элементар деректер түрі-мысалы (с тілі үшін): MPI_CHAR, MPI_SHORT, MPI_INT, MPI_LONG, MPI_FLOAT, MPI_DOUBLE, MPI_BYTE, MPI_PACKED және т. б. dest-хабарлама жеткізілетін процесті көрсетеді - қабылдау процесінің дәрежесі арқылы орнатылады; source-жіберу процесінің нөмірін көрсететін хабарлама қабылдау функциясының дәлелі; mpi_any_source мәнін көрсету кез-келген процестен хабарлама қабылдауды білдіреді; tag-хабарламаны бір мәнді анықтау үшін бағдарламашы тағайындаған ерікті теріс емес бүтін сан; Send және Reseive жұптасқан операцияларында бұл сандар сәйкес келуі керек; Receive операциясында Mpi_any_tag мәнін көрсету tag мәніне қарамастан кез келген хабарламаны қабылдау үшін пайдаланылуы мүмкін ; comm-dest және source аргументтерінің мәндері түсіндірілетін коммуникаторды көрсетеді ; көбінесе кіріктірілген mpi_comm_world коммуникаторы қолданылады ; status-Receive операциясы үшін хабарламаның қайнар көзін (көзін) және оның тегін ( tag) көрсетеді; с тілінде бұл дәлел mpi_status кірістірілген құрылымына сілтеме болып табылады ; сол құрылымнан MPI_Get_count функциясы арқылы қабылданған байттардың санын алуға болады ; request-send және Receive блокталмайтын операцияларында қолданылады және бірегей "сұрау нөмірін" орнатады; с тілінде бұл дәлел mpi_request ендірілген құрылымына сілтеме болып табылады. Ең жиі қолданылатын хабарлама блоктау функцияларына келесі функциялар кіреді: MPI_Send Хабарламаны жіберудің негізгі блоктау операциясы. Ол өз жұмысын сәлемдеме деректері алынған бағдарламалық буфер қайта пайдалануға дайын болған кезде ғана аяқтайды. Функцияны шақыру форматы: MPI_Send ( &buf, count, datatype, dest, tag, comm. ) MPI_Recv Қабылданған деректер бағдарламалық буферде қол жетімді болғанға дейін хабарламаларды қабылдайды және осы функцияны шақыратын процесті блоктайды. Функцияны шақыру форматы: MPI_Recv ( &buf, count, datatype, source, tag, comm, &status ) MPI_Ssend Хабарлама жіберудің синхронды блоктау әрекеті: хабарлама жібереді және бағдарламалық буфер қайта пайдалануға дайын болғанға дейін және алушы процесс жіберілген хабарламаларды қабылдай бастағанға дейін осы функцияны тудырған процесті блоктайды. Функцияны шақыру форматы: MPI_Ssend ( &buf, count, datatype, dest, tag, comm ) MPI_Bsend, MPI_Buffer_attach Mpi_bsend шақырылмас бұрын, бағдарламашы MPI_Bsend-де қолданылатын буферді орналастыру үшін MPI_Buffer_attach функциясын шақыруы керек. MPI_Buffer_attach функциясы Mpi_bsend жұмысы үшін жадтан орын бөлу үшін қолданылатын функция болып табылады. Функцияны шақыру форматы: MPI_Buffer_attach ( &buffer, size ) MPI_Bsend ( &buf, count, datatype, dest, tag, comm ) Ұжымдық деректер алмасуларының "нүкте-нүкте" үлгісіндегі алмасулардан негізгі ерекшеліктері мен айырмашылықтары мынадай: көрсетілген Коммуникатор үшін топтың барлық процестерін бір уақытта қабылдайды және/немесе жібереді; хабар тарату (ұжымдық) функциясы деректерді қабылдауды да, беруді де бір уақытта орындайды, сондықтан оның параметрлерінің бір бөлігі қабылдауға, ал бір бөлігі деректерді беруге қатысты; әдетте, барлық параметрлердің мәндері (буфер мекенжайларын қоспағанда) барлық процестерде бірдей болуы керек; ұжымдық операциялар бұғаттаушы болып табылады; ұжымдық операцияларды тек ендірілген (алдын-ала анықталған) MPI деректер түрлері үшін пайдалануға болады, бірақ туынды MPI деректер түрлері үшін қолдануға болмайды. 7 Ұжымдық байланыс операциялары. Ұжымдық байланыс операциясы берілген Коммуникатор ішіндегі барлық процестерді қолдана отырып деректерді беруді қамтиды, барлық қол жетімді процестерді қамтитын әдепкі коммуникатор MPI_COMM_WORLD деп аталады. Ұжымдық қоңырау орындалған кезде оны Байланыс ішіндегі барлық процестер шақыруы керек. Ұжымдық операциялар мен нүкте-нүкте сияқты операциялардың басты айырмашылығы-кейбір коммуникатормен байланысты барлық процестер әрқашан қатысады. Бұл ережені сақтамау тапсырманың төтенше жағдайда аяқталуына немесе тапсырманың одан да жағымсыз қатып қалуына әкеледі. Ұжымдық операциялар жиынтығы мыналарды қамтиды: Барлық процестерді кедергілермен синхрондау (MPI_Barrier) Ұжымдық коммуникациялық операциялар Ғаламдық есептеу операциялары 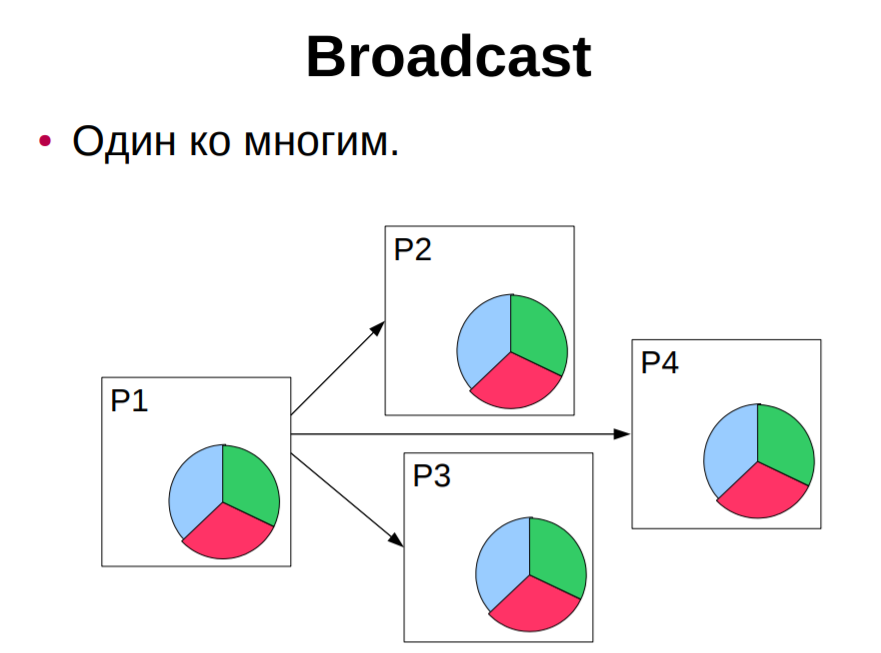 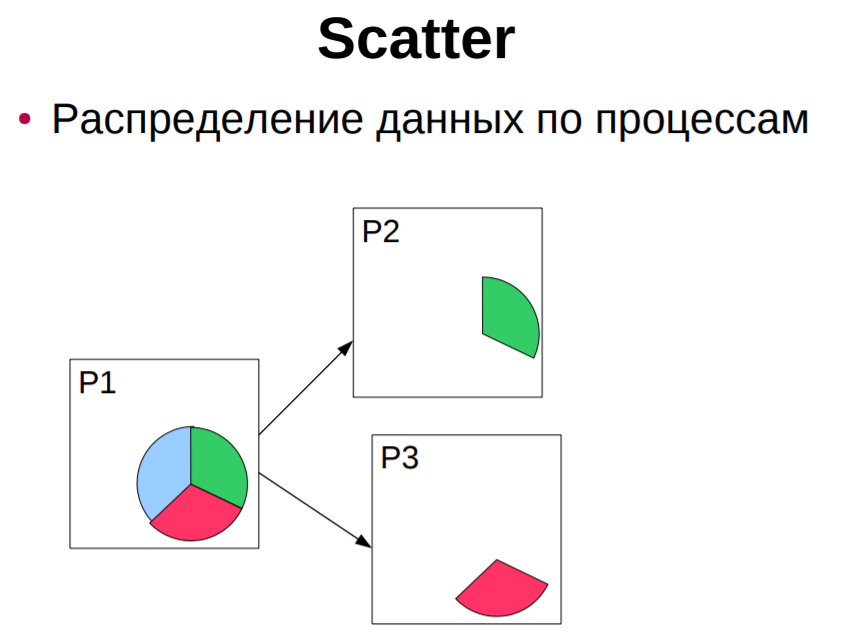 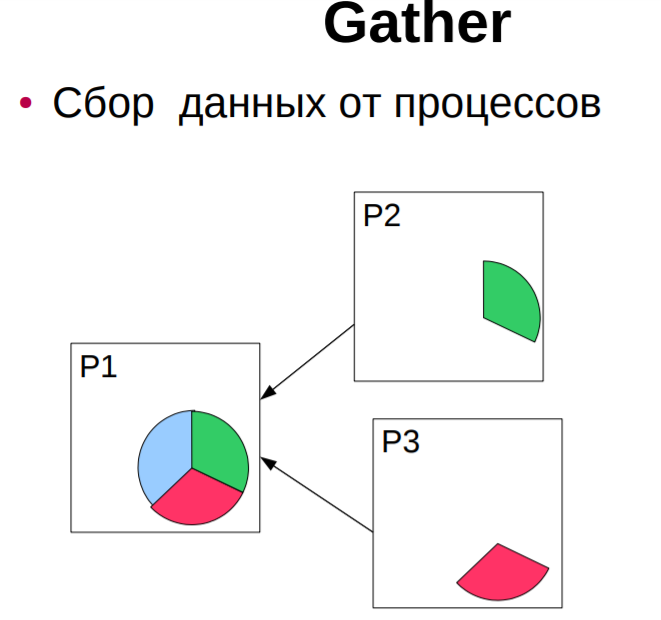 Құрамына мыналар кіретін ұжымдық коммуникациялық операциялар: o бір процестен ақпаратты кейбір байланыс саласының барлық басқа мүшелеріне жіберу (MPI_Bcast); int MPI_Bcast(void *buf,int count,MPI_Datatype type,int root,MPI_Comm comm), INOUT buffer-жіберілген деректердің жадында орналасудың басталу мекенжайы; In count - жіберілген элементтер саны; IN datatype - жіберілетін элементтер түрі; IN root-жіберушінің процесс нөмірі; IN comm - коммуникатор. процестер бойынша бөлінген массивті таңдалған (түбір) процестің адрестік кеңістігінде сақтай отырып, бір массивке құрастыру (gather) (MPI_Gather, MPI_Gatherv); o таратылған массивті бір массивке құрастыру, оны кейбір байланыс аймағының барлық процестеріне жіберу (MPI_Allgather, MPI_Allgatherv); o массивті бөлу және оның фрагменттерін (scatter) байланыс аймағының барлық процестеріне жіберу (MPI_Scatter, MPI_Scatterv); o біріктірілген Scatter/Gather операциясы (all-to-All), әр процесс өзінің тарату буферінен деректерді бөледі және басқа процестер жіберген фрагменттерді жинау кезінде барлық басқа процестерге фрагменттерді шашыратады (MPI_Alltoall, MPI_Alltoallv). Ұжымдық операциялардың ерекшеліктері: - ұжымдық байланыс нүкте-нүкте типті коммуникациялармен өзара әрекеттеспейді; - ұжымдық коммуникациялар құлыптау режимінде орындалады. Әр процестегі ішкі бағдарламадан қайтару оның ұжымдық операцияға қатысуы аяқталған кезде пайда болады, бірақ бұл басқа процестер операцияны аяқтады дегенді білдірмейді; -алынған мәліметтер саны жіберілген мәліметтер санына тең болуы керек. Жіберілетін және қабылданатын хабарламалар элементтерінің түрлері сәйкес келуі тиіс. Хабарламаларда идентификаторлар жоқ. . 8 MPI_Send(), MPI_Ssend(), MPI_Bsend(), MPI_Rsend(), MPI_Recv() Функциялары. Жұмыс принципі, айырмашылықтары. Параметрлері, MPI_STATUS параметрі. Mpi_send хабарлама жіберу функциясы C: int MPI_Send(void* buf, int count, MPI_Datatype datatype, int dest, int tag, MPI_Comm comm) FORTRAN: MPI_SEND(BUF, COUNT, DATATYPE, DEST, TAG, COMM, IERROR) INTEGER COUNT, DATATYPE, DEST, TAG, COMM, IERROR IN buf-жіберілетін деректердің орналасуын бастау мекенжайы; In count - жіберілетін элементтер саны; IN datatype - жіберілетін элементтер түрі; IN dest-comm коммуникаторымен байланысты топтағы алушы процестің нөмірі; IN tag-хабарлама идентификаторы (nread және NWRITE PSE ncube2 хабарлама түрінің аналогы); IN comm-байланыс саласындағы коммуникатор. Функция comm коммуникаторының байланыс саласындағы TAG процессіне Dest идентификаторы бар datatype хабарлама түріндегі элементтерді санау пәрменін орындайды. Буф айнымалы-бұл әдетте массив немесе скаляр айнымалы. Соңғы жағдайда count = 1 мәні. Буфер (MPI_Bsend) - жіберілген хабарлама буферге салынып, функция жұмысын аяқтайды. Хабарлама кітапхана арқылы жіберіледі. Буферлік беріліс дереу аяқталуға кепілдік береді, өйткені хабарлама алдымен жүйелік буферге көшіріліп, содан кейін жеткізіледі. Оның кемшілігі-жүйенің ресурстарын тұтынатын арнайы буферлерді бөлу қажеттілігі. Synchronous (MPI_Ssend) – функция процесті аяқтаған кезде аяқталады-алушы MPI_Recv шақырып, хабарламаны көшіре бастады. Функцияны шақырғаннан кейін буферді қауіпсіз пайдалануға болады. Синхронды беріліс стандарттыға қарағанда әлдеқайда баяу болуы мүмкін. Алайда, бұл байланыс желісінің шамадан тыс жүктелуіне әкелмейді. Бұл беріліс режимін қолдану параллельді қосымшаны жөндеуді жеңілдетеді. Ready (MPI_Rsend) – алушы процесс MPI_Recv функциясын шақырған жағдайда ғана функция сәтті орындалады. Бұл режим байланыс желісінде кезбе хабарламалардың болмауына кепілдік береді. Mpi_recv хабарламасын қабылдау функциясы C: int MPI_Recv(void* buf, int count, MPI_Datatype datatype, int source, int tag, MPI_Comm comm, MPI_Status *status) FORTRAN: MPI_RECV(BUF, COUNT, DATATYPE, SOURCE, TAG, COMM, STATUS, IERROR) INTEGER COUNT, DATATYPE, SOURCE, TAG, COMM, STATUS(MPI_STATUS_SIZE), IERROR Out buff-қабылданған хабардың басталу мекен-жайы; In count - қабылданатын элементтердің ең көп саны; IN datatype - қабылданатын хабарлама элементтерінің түрі; IN source-жіберушінің процесс нөмірі; IN tag-хабарлама идентификаторы; IN comm-байланыс саласындағы коммуникатор; MPI_Send және MPI_Recv үшін бірдей болуы керек. OUT status - қабылданған хабарлама туралы ақпаратты қамтиды: оның идентификаторы, таратқыш тапсырманың нөмірі, аяқталу коды және нақты келген мәліметтер саны. Функция comm коммуникаторының байланыс саласындағы source процесінен tag идентификаторы бар datatype хабарлама түріндегі элементтерді count қабылдауды орындайды. mpi_recv қабылдау функциясы (MPI_Send үшін жұпталған) Жергілікті болып табылады: ол басқа тармақтарға ештеңе хабарлауға тырыспай, деректердің түсуін пассивті түрде күтеді. MPI_Status status; Status қабылданған хабарлама туралы ақпаратты қамтиды: оның идентификаторы, таратқыш тапсырманың нөмірі, аяқталу коды және нақты келген мәліметтер саны. Mpi_status құрылымында MPI SOURCE, MPI TAG, MPI_ERROR атаулары бар үш міндетті өріс бар, олар хабарлама жіберген процестің нөмірін, қабылданған хабарламаның тегін және хабарлама қате жіберілген жағдайда қате кодын қамтиды. Қате коды функцияның қайтару кодымен сәйкес келген кезде MPI қате өрісі қалыпты хабарлама қабылдау функциясын шақырған кезде артық болады. Ол негізінен бірнеше қабылдау операцияларын аяқтайтын функцияларда қолдануға арналған, олардың әрқайсысы қате тудыруы мүмкін. MPI SOURCE және MPI TAG өрістері шаблондарды қолданған жағдайда процестің нөмірін-жіберушіні және келген хабарламаның тегін анықтау үшін қажет. Егер жіберуші процестің нөмірі мен тегі хабарламаны қабылдау функциясын шақырған кезде дәл дәлелдерде көрсетілсе, онда mpi_source және MPI_TAG өрістері бұл ақпаратты қайталайды. 9 Нүктелік алмасулардың семантикасы (нүкте-нүкте байланыс операцияларын орындау кезеңдері). Осы типтегі операцияларға екі байланыс процедурасы кіреді (MPI_Send, MPI_Recv). Нүкте-нүкте сияқты байланыс операцияларына әрқашан 2 процесс қатысады: беру және қабылдау. Түрлері: - Синхронды беру-хабарламаның расталуы алынды. - Буферленген = асинхронды. Хабарлама жіберілгені туралы ақпарат. Бұл тапсырмалар арасындағы байланыстың ең қарапайым түрі: бір тармақ деректерді беру функциясын, ал екіншісі қабылдау функциясын шақырады. MPI-де, мысалы, келесідей көрінеді: 1-тапсырма береді: int buf[10]; MPI_Send( buf, 5, MPI_INT, 1, 0, MPI_COMM_WORLD ); 2-міндет қабылдайды: int buf[10]; MPI_Status status; MPI_Recv( buf, 10, MPI_INT, 0, 0, MPI_COMM_WORLD, &status ); Функция аргументтері: 1-тапсырмада алынған буфердің мекен-жайы, ал 2-тапсырмада деректер орналастырылған. Есіңізде болсын, әр тапсырманың мәліметтер жиынтығы әр түрлі, сондықтан, мысалы, бірнеше тапсырмада бірдей массив атауын қолдана отырып, сіз бірдей жад аймағын көрсетпейсіз, бірақ әр түрлі, бір-бірімен байланысты емес. Буфер мөлшері. Ол байтта емес, ұяшықтар санында орнатылады. Mpi_send үшін қанша ұяшықты беру керектігін көрсетеді (мысалда 5 Сан беріледі). Mpi_recv қабылдау буферінің максималды сыйымдылығын білдіреді. Егер келген хабарламаның нақты ұзындығы аз болса - буфердің соңғы ұяшықтары өзгеріссіз қалады, егер көп болса-жұмыс уақыты қатесі орын алады. Буфер ұяшығының түрі. MPI_Send және MPI_Recv бірдей типтегі мәліметтер массивтерімен жұмыс істейді. MPI-де si негізгі түрлерін сипаттау үшін mpi_datatype типі бар mpi_int, MPI_CHAR, MPI_DOUBLE және т.б. тұрақтылар анықталады. Олардың атаулары "MPI_" префиксімен және тиісті типтегі (Int, char, double,...), бас әріптермен жазылады. Пайдаланушы MPI-ге өзінің деректер түрлерін, мысалы, құрылымдарды "тіркей" алады, содан кейін MPI оларды негізгі мәліметтермен қатар өңдей алады. Тіркеу процесі "деректер түрлері"тарауында сипатталған. Деректер алмасатын тапсырманың нөмірі. Құрылған MPI тобындағы барлық тапсырмалар автоматты түрде 0-ден (топ өлшемі-1) нөмірленеді. Мысалда 0-тапсырма 1-тапсырмаға беріледі, 1-тапсырма 0-тапсырмадан алынады. Хабарлама идентификаторы. Бұл Пайдаланушы өзі таңдаған 0-ден 32767-ге дейінгі бүтін сан. Ол, мысалы, файл кеңейтімі-тапсырма қабылдағышымен бірдей мақсатқа қызмет етеді: идентификатор қабылданған ақпараттың мағынасын анықтайды ; белгісіз ретпен келген хабарламалар жалпы кіріс ағынынан қажетті алгоритм бойынша алынуы мүмкін. "#Define" немесе "const int"операторлары арқылы таңбалық атаулармен идентификаторларды белгілеу жақсы тон болып табылады. Байланыс саласын сипаттаушы (коммуникатор). MPI_Send және MPI_Recv үшін бірдей болуы керек. Қабылдаудың аяқталу мәртебесі. Онда қабылданған хабарлама туралы ақпарат бар: оның идентификаторы, таратқыш тапсырманың нөмірі, аяқталу коды және нақты келген мәліметтер саны. Блоктау функциялары олардан операцияны толық аяқтағаннан кейін ғана шығуды білдіреді, яғни.қоңырау шалу процесі операция аяқталғанша бұғатталады. Хабарлама жіберу функциясы үшін бұл барлық жіберілген деректердің буферге салынғанын білдіреді (әр түрлі MPI енгізу үшін бұл аралық жүйелік буфер немесе тікелей алушының буфері болуы мүмкін). Хабарламаны қабылдау функциясы үшін буфердегі барлық деректер қабылдаушы процестің мекен-жай кеңістігіне орналастырылғанша басқа операциялардың орындалуы бұғатталады. Блоктан тыс функциялар айырбастау операцияларын басқа операциялармен біріктіруді білдіреді, сондықтан блоктан тыс беру және қабылдау функциялары іс жүзінде тиісті операцияларды іске қосу функциялары болып табылады. Операцияның аяқталуын (және аяқталуын) сұрау үшін қосымша функциялар енгізіледі. Блоктау және блоктау операциялары үшін MPI төрт орындау режимін қолдайды. Бұл режимдер тек деректерді беру функцияларына қатысты, сондықтан блоктау және бұғаттамау операциялары үшін хабарлама жіберудің төрт функциясы бар. 3.1-кестеде MPI кітапханасында бар нүкте-нүкте сияқты негізгі байланыс функцияларының атаулары көрсетілген. 10 Нүктелік хабар алмасу кезіндегі тығырыққа тірелу жағдайлары. Программаның тығырыққа тірелуі – блоктауды қолданатын процедураларда пайда болады  Барлық тапсырмалар әлі басталмаған оқиғаларды күткен кезде аяқталады. Тұйықталудың(тығырыққа тірелу) қарапайым мысалы: екеуінің әрқайсысы тиісті қабылдауды аяқтайды деп күтеді, бірақ бұл қабылдаулар жіберілгеннен кейін орындалады, сондықтан егер жіберулер аяқталмаса және қайтарылмаса, қабылдаулар ешқашан орындалмайды және екі байланыс жиынтығы да белгісіз уақытқа тоқтатылады. Күрделірек мысал тұйығының болуы мүмкін, егер мөлшерін хабарлар көп шегін; тұйық жүреді сонымен қатар, бірде-бір міндет емес согласоваться уақыт (үйлесуге) тиісті оған алуға. Егер жүйелік буферде жеткілікті орын болмаса, хабардың мөлшері шекті мәннен аспаған жағдайда да тұйықталу орын алуы мүмкін. Екі тапсырма да жүйелік буферден хабарлама деректерін қайта жазуды күтеді, бірақ бұл қабылдаулар орындалмайды, өйткені екі тапсырма да жіберуде бұғатталған. Тығырықтан құтылудың төрт жолы бар: 1) тапсырмалардағы қоңыраулардың әртүрлі тәртібі Бір тапсырма бірінші болып оны қабылдағанын, ал екінші тапсырма бірінші болып жіберілгенін жариялайтын тәртіпті ұйымдастырыңыз. Бұл нақтылау бір бағыттағы хабарлама екіншісіне қарағанда ертерек өтетін тәртіпті береді. 2) бұғаттамайтын шақырулар олар әр тапсырманы басқа байланыс жасамас бұрын блокталмайтын қабылдауды жариялауға мәжбүр етеді. Бұл кез-келген хабарламаны, хабарлама келген кезде қандай тапсырма жұмыс істейтініне қарамастан және жіберілімдер жарияланған тәртіпке қарамастан алуға мүмкіндік береді. 3)MPI_Sendrecv MPI_Sendrecv_reMpi_sendrecv пайдалану-бұл MPI кітапханасының мүмкіндіктерін пайдаланып, тығырықты жою үшін талғампаз шешім. Бұл нұсқада екі буфер қолданылады: біреуі жіберілген хабарлама үшін, екіншісі алынған хабарлама үшін. _replace нұсқасында жүйе хабар алмасуды өңдеу үшін белгілі бір буферлік кеңістікті (шекті емес) бөледі. Осы буферде жіберілген хабарлама алынған хабарламамен ауыстырылады. Бос mpi_proc_null мәні бар процесспен алмасу нәтиже бермейтінін және бос mpi_proc_null процесіне жіберу әрқашан сәтті болатындығын ескеріңіз. 4) буферлік әдіс Жіберілген хабарламаны жеке буферге көшіргеннен кейін есептеуді жүзеге асыру үшін буферлік жіберуді қолданыңыз. Бұл нәтижелерді орындауға мүмкіндік береді. 11 Буферленген хабарлама жберуді ұйымдастыру(MPI_Bsend() пайдалану). Mpi_bsend функциясы әрқашан деректерді буферге орналастырады. Буферді таңдау қосымшаның міндеті болып табылады: жібермес бұрын, қажетті көлемдегі жад аймағын таңдау керек. Мұны істеу үшін, ең алдымен, осы мөлшерді есептеу керек. Өлшемді есептеу формула бойынша жүзеге асырылады: буфердің_ өлшемі = х хабарламалар саны *(көбейту) бір хабарлама үшін _жады_ мөлшері. Әлбетте, буфердің мұндай көлемі жіберуші жіберген барлық хабарламаларды сақтау үшін қажет. Нақты іске қосылған жад мөлшері MPI_Pack size () функциясы арқылы есептелетін бір хабарламаны сақтау үшін талап етілетін жад көлемінен едәуір аз болуы мүмкін: int MPI_Pack_size (int count, MPI_Datatype, MI'I_Comm comm, int* size) count - деректер элементтерінің саны; datatype - бір деректер элементінің түрі; conm - хабар алмасу жүзеге асырылатын коммуникатор; size- қорытынды өлшем. Соңғы параметр арқылы қайтарылған хабарлама көлемін алу үшін функция жіберілетін деректер элементтерінің саны мен түрін, сондай-ақ жіберу жоспарланған коммуникаторды жібереді. Сонымен қатар, әр хабарламада кейбір қызметтік ақпарат сақталады, оны сақтау үшін mpi_bsend_overhead тұрақтысымен анықталған жад мөлшері қажет.Осылайша, бір хабарламаны Буферлеу үшін бөлектелетін жад көлемін алу үшін алдымен mpirack_size () функциясы арқылы хабарлама мөлшері есептеледі, содан кейін оған MPI_BSEND OVERHEAD қосылады.Өлшемі есептелгеннен кейін, жадты басқарудың стандартты функциялары арқылы бөлуге болады: malloс, calloc және т. б. Mpi_buffer_attach функциясын шақыру арқылы бөлінген жад туралы MPI кітапханасына хабарлау қажет: int MPI_Buffer_attach(void* buffer, int size) buffer- буфер адресі; size- буфер өлшемі.; int MPI_Buffer_detach(void* buffer_address, int* size) buffer_address- буфер адресі; size-буфер өлшемі. Бұл функцияның бірінші дәлелі ретінде таңдалған буфердің мекен-жайы беріледі,ал екіншісі-оның байт мөлшері. Буфер енді қажет болмаған кезде, бөлінген жадты босатпас бұрын процесс mii _BUFFER_DETACH қоңырауын орындауы керек. Бұл функцияның бірінші және екінші параметрлері шығыс болып табылады. Бірінші дәлел ретінде берілген мекен — жайға буфердің мекен-жайы жазылады, ал екінші дәлел ретінде берілген мекен-жайға оның мөлшері жазылады. Буферленген хабарламаларды жіберуді ұйымдастыруға арналған стандартты әрекеттер тізбегі келесідей: Буфердің қажетті көлемін есептеңіз (Mpi_pack_size). 2. Буферге арналған жадты таңдаңыз (malloc). 3. Жүйеде буферді тіркеңіз (MPI_Buffer_attach). 4.Қайта жіберуді орындау. 5.Буферді тіркеуді болдырмау (Mpi_buffer_dettach) 6.Буферге бөлінген жадты босатыңыз (тегін). Атап өту маңызды ерекшеліктері работты с буферінің арқылы: буфер әрқашан бір және жіберуші процесте ұйымдастырылады; буфердің өлшемін өзгерту үшін алдымен MPI Buffer_detach деп қоңырау шалыңыз, содан кейін қажетті мөлшердегі жаңа жад блогын таңдап, оны mpi_buffer_attach қоңырауымен тіркеңіз; . Mi_buffer_detach функциясы барлық буферленген хабарламалар жіберілгенге дейін процесті блоктайды, сондықтан буферге бөлінген жадты босатпас бұрын оны әрдайым шақыру керек - бұл жіберілмеген хабарламалар орналасқан жадтың босатылуына жол бермейді. 5-тізімдегі код үзіндісі буферленген хабар алмасуды қолдануды көрсетеді. 1, 2-жолдарда MPI Int түріндегі m хабарламаларын жіберу үшін қажетті буфер мөлшері есептеледі. B 4, 5-жолдарда буферге жад бөлінеді және жүйеде буфер тіркеледі. 5-8-жолдарда орналасқан циклде М хабарлама жіберіледі, олардың әрқайсысында нақты түрдегі бір элемент болады. 9-11-жолдарда буферді тіркеу алынып, тиісті жад босатылады.MPI_Pack_size (1, MPI_INT, MPI_COMM_WORLD, &msize) blen = M * (msize + MPI_BSEND_OVERHEAD); buf = (int*) malloc (blen); MPI Buffer_attach (buf, blen); for(i = 0; i < M; i ++) { n = i; MPI_Bsend (&n, 1, MPI_INT, 1, i, MPI COMM_WORLD) ; MPI_Buffer_detach (&abuf, &ablen); free (abuf); 12 Жіберілетін хабарлама үшін жад аймағының көлемін есептеу. Каждый процесс должен отправлять/получать данные в/из других процессов. Например, рассмотрим проблему сортировки массива целых чисел. Два процессора делят задачу на две подзадачи, в конце обмениваются данными и упорядочивают весь массив. 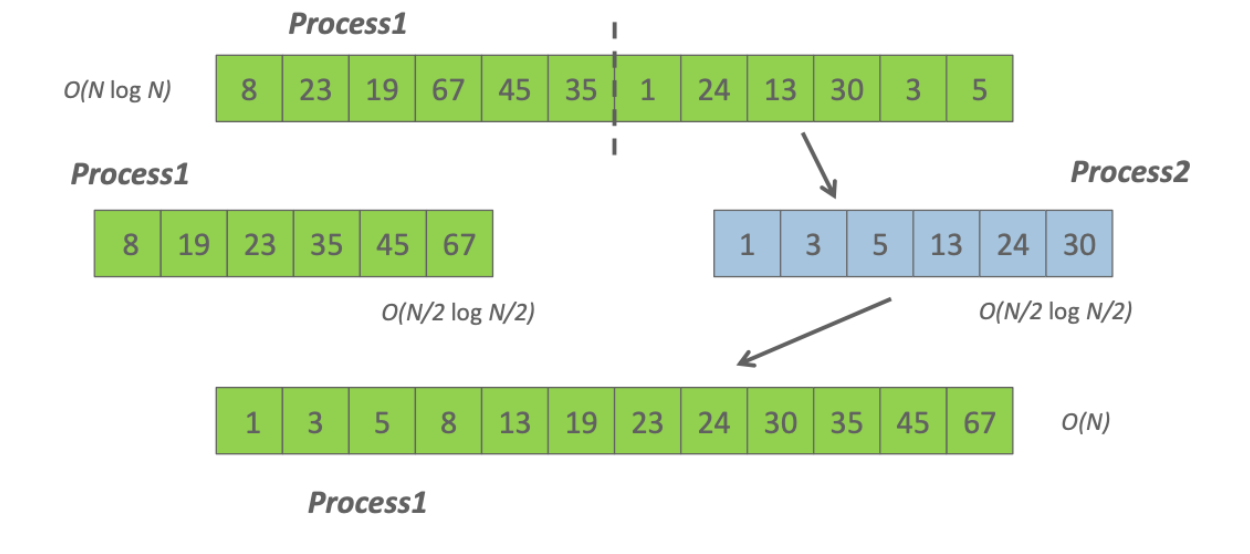 MPI Простая коммуникационная модель 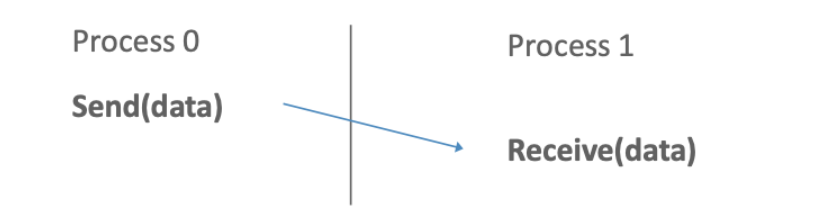 Обмен данными в MPI похож на обмен электронной почтой. Один процесс посылает копию данных другому процессу (или группе процессов), а другой процесс получает ее. Для коммуникации требуется следующая информация: Отправитель должен знать: Кому отправить данные (ранг процесса получателя). Какой тип данных отправить (100 целых чисел или 200 символов и т.д.). Определяемый пользователем тег для сообщения (считайте, что это тема электронного письма; позволяет получателю понять, какой тип данных принимается). Получатель "может" знать: Кто отправляет данные, ранг процесса (если получатель не знает; в этом случае ранг отправителя будет MPI_ANY_SOURCE, то есть любой может отправлять). Какого рода данные принимаются (частичная информация не помешает, например, можно принять до 1000 целых чисел). Каков тег сообщения, определяемый пользователем (хорошо, если получатель не знает; в этом случае тег будет MPI_ANY_TAG). Следующий код описывает вышеупомянутые концепции. Два процесса обмениваются значением char, используя примитив send/receive MPI. Типы и константы MPI В двух взаимодействующих MPI-процессах: одна задача выполняет операцию отправки, а другая - соответствующую операцию получения. Обратите внимание, что операция согласования - это обычный и требуемый способ объяснить этот случай. Более того, когда запускается операция отправки или приема, мы должны сказать, что она размещена. MPI_Send(buffer,count,type,dest,tag,comm) MPI_Recv(buffer,count,type,source,tag,comm,status) 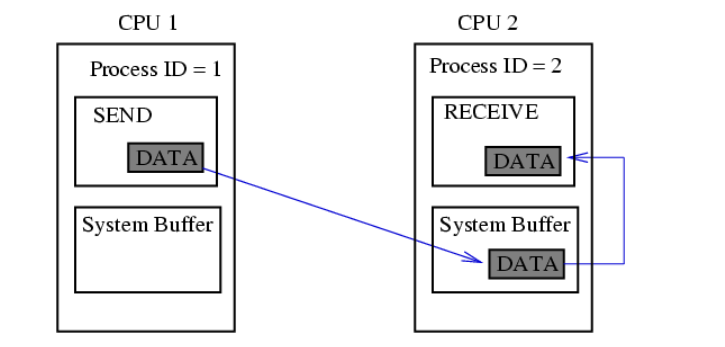 Как вы можете видеть на рисунке, MPI вводит скрытый (или частично скрытый) уровень памяти, этот уровень соответствует системному буферу. MPI использует этот системный буфер для реализации нескольких режимов обмена данными, которые будут описаны позже в этой главе. MPI предоставляет специальные процедуры для управления этим буфером и предварительного выделения его для специальных целей. MPI управляет системной памятью, которая используется для буферизации сообщений и для хранения внутренних представлений различных объектов MPI, таких как группы, коммуникаторы, типы данных и т.д.. Эта память недоступна пользователю напрямую, а хранящиеся в ней объекты непрозрачны: их размер и форма не видны пользователю. Доступ к непрозрачным объектам осуществляется через дескрипторы, которые существуют в пространстве пользователя. Процедурам MPI, которые работают с непрозрачными объектами, передаются аргументы handle для доступа к этим объектам. Помимо использования в вызовах MPI для доступа к объектам, дескрипторы могут участвовать в присваиваниях и сравнениях. В общем случае, когда вы пишете MPI-программу, вы используете два вида буферов: Буферы приложения, эти буферы выделяются и управляются вашим приложением. Эти буферы используются для разработки вашей программы. Внутренние буферы, эти буферы являются внутренними для MPI и могут существовать или даже не существовать. В стандарте MPI нет ничего об этих буферах или о том, как они должны действовать, какого размера они должны быть и т.д. Специальные буферы, существуют и другие виды буферов, которые могут предоставлять специальные услуги, например, буферы на сетевой карте, которые могут ускорить передачу данных. То, как они ведут себя, обычно зависит от типа используемой сети. Буферы MPI MPI_Buffer_attach устанавливает заданный буфер в качестве буферного пространства MPI. Этот буфер затем будет использоваться при отправке сообщений в асинхронном режиме (MPI_Bsend и MPI_Ibsend). Присоединенный буфер должен содержать достаточно места для отправки сообщений плюс накладные расходы памяти, возникающие при выдаче каждого MPI_Bsend или MPI_Ibsend, которые представлены константой MPI_BSEND_OVERHEAD. Буфер, подключенный к MPI, должен быть отсоединен после использования вызовом MPI_Buffer_detach. Кроме того, в каждый момент времени может быть подключен только один буфер. int MPI_Buffer_attach(void* buffer, int size); MPI_Buffer_detach удаляет буфер, прикрепленный в настоящее время к буферному пространству MPI, который был прикреплен с помощью MPI_Buffer_attach. MPI_Buffer_detach будет блокироваться до тех пор, пока не будут отправлены все сообщения, содержащиеся в присоединенном буфере. Обратите внимание, что отсоединение буфера не освобождает соответствующую память; за это отвечает пользователь. int MPI_Buffer_detach(void* buffer, int size); Конвенция именования MPI и термины В MPI-1 использовались неформальные соглашения об именовании. Во многих случаях имена MPI-1 для функций C имеют вид Класс_действия_подмножество, но это правило применяется неравномерно. В MPI-2 была предпринята попытка стандартизировать имена новых функций в соответствии со следующими правилами. Кроме того, привязки C++ для функций MPI-1 также следуют этим правилам. Имена функций языка Си для MPI-1 не были изменены. В Си все функции, связанные с определенным типом объекта MPI, должны иметь форму Class_action_subset или, если подмножество не существует, форму Class_action. В Fortran все процедуры, связанные с определенным типом объекта MPI, должны иметь форму CLASS_ACTION_SUBSET или, если подмножество не существует, форму CLASS_ACTION. Если процедура не связана с классом, имя должно иметь форму Action_subset в C. Имена некоторых действий были стандартизированы. В частности, Create создает новый объект, Get извлекает информацию об объекте, Set устанавливает эту информацию, Delete удаляет информацию, Is спрашивает, обладает ли объект определенным свойством или нет. Имена функций MPI-1 на языке Си нарушают эти правила в нескольких случаях. Наиболее распространенными исключениями являются пропуск имени класса в процедуре и пропуск действия там, где его можно предположить. Идентификаторы MPI ограничены 30 символами (31 при использовании интерфейса профилирования). Это сделано для того, чтобы избежать превышения лимита в некоторых системах компиляции. При обсуждении процедур MPI используются следующие семантические термины. блокирующая Процедура является блокирующей, если возврат из процедуры указывает на то, что пользователю разрешено повторное использование ресурсов, указанных в вызове. неблокирующая Процедура является неблокирующей, если процедура может вернуться до завершения операции и до того, как пользователю будет разрешено повторное использование ресурсов (таких как буферы), указанных в вызове. локальная Процедура является локальной, если завершение процедуры зависит только от локального исполняющего процесса. нелокальная Процедура является нелокальной, если завершение операции может потребовать выполнения какой-либо процедуры MPI на другом процессе. Такая операция может потребовать коммуникации с другим пользовательским процессом. коллективная Процедура является коллективной, если все процессы в группе процессов должны вызвать процедуру. Коллективный вызов может быть синхронизирующим или нет. Коллективные вызовы через один и тот же коммуникатор должны выполняться в одинаковом порядке всеми членами группы процессов. предопределенный Предопределенный тип данных - это тип данных с предопределенным (постоянным) именем (например, MPI_INT, MPI_FLOAT_INT). Производный производный тип данных - это любой тип данных, который не является предопределенным. переносимый Тип данных является переносимым, если он является предопределенным типом данных или получен из переносимого типа данных с использованием только конструкторов типов MPI_TYPE_CONTIGUOUS, MPI_TYPE_VECTOR, MPI_TYPE_INDEXED, MPI_TYPE_INDEXED_BLOCK, MPI_TYPE_CREATE_SUBARRAY, MPI_TYPE_DUP и MPI_TYPE_CREATE_DARRAY. Такой тип данных является переносимым, потому что все перемещения в этом типе данных находятся в терминах экстентов одного предопределенного типа данных. Эквивалент Два типа данных эквивалентны, если кажется, что они были созданы с помощью одной и той же последовательности вызовов (и аргументов) и, таким образом, имеют одну и ту же типовую схему. Типы данных MPI Уровень MPI управляет системной памятью, которая используется для буферизации сообщений и хранения внутренних представлений различных объектов MPI (групп, коммуникаторов, типов данных и т.д.). Эта память недоступна пользователю напрямую, и объекты, хранящиеся в ней, непрозрачны: их размер и форма не видны пользователю. Доступ к непрозрачным объектам осуществляется через дескрипторы, которые существуют в пространстве пользователя. Процедурам MPI, которые работают с непрозрачными объектами, передаются аргументы handle для доступа к этим объектам. Помимо использования в вызовах MPI для доступа к объектам, дескрипторы могут участвовать в присваиваниях и сравнениях. Непрозрачные объекты выделяются и деаллоцируются с помощью вызовов, специфичных для каждого типа объектов. Они перечислены в разделах, где описываются объекты. Вызовы принимают аргумент handle соответствующего типа. Уровень MPI предоставляет несколько типов данных, которые будут использоваться вызовами MPI:  Типы данных MPI_BYTE и MPI_PACKED не соответствуют типам данных языка C. Значение типа MPI_BYTE состоит из байта (8 двоичных цифр). Байт не интерпретируется и отличается от символа. Различные машины могут иметь различные представления для символов или использовать более одного байта для представления символов. С другой стороны, байт имеет одно и то же двоичное значение на всех машинах. Что такое программа MPI? Программа MPI состоит из автономных процессов, выполняющих свой собственный код в стиле MIMD. Коды, выполняемые каждым процессом, не обязательно должны быть идентичными. Процессы обмениваются данными посредством вызовов коммуникационных примитивов MPI. Как правило, каждый процесс выполняется в своем собственном адресном пространстве, хотя возможны реализации MPI с общей памятью. Взаимодействие MPI и потоков гораздо сложнее и требует других спецификаций, но это означает, что процесс MPI может взаимодействовать, используя как общую память (одно и то же адресное пространство), так и распределенную память. 13 MPI_Pack_size(), MPI_Buffer_attach(),MPI_Buffer_detach() функциялары, MPI_BSEND_OVERHEAD тұрақтысы. Функция MPI_Pack_size Возвращает верхнюю границу объема пространства, необходимого для упаковки сообщения. |