Коллоквиум сұрақтары жауаптары (2) (копия). Коллоквиум сратары
 Скачать 2 Mb. Скачать 2 Mb.
|

|
Орысша Технология параллельного программирования MPI. Принцип работы. Отличие от OpenMP. Основные понятия Наиболее распространенной технологией программирования параллельных компьютеров с распределенной памятью является технология MPI [2,10]. Основным способом взаимодействия параллельных процессов в таких системах является передача сообщений друг другу. Это и отражено в названии технологии Message Passing Interface. Под параллельной программой в рамках MPI понимается множество одновременно выполняемых процессов. Процессы могут выполняться на разных процессорах, но на одном процессоре могут располагаться и несколько процессов (в этом случае их исполнение осуществляется в режиме разделения времени). В предельном случае для выполнения параллельной программы может использоваться один процессор как правило, такой способ применяется для начальной проверки правильности параллельной программы. Каждый процесс параллельной программы порождается на основе копии одного и того же программного кода. Данный программный код, представленный в виде исполняемой программы, должен быть доступен в момент запуска параллельной программы на всех используемых процессорах. Исходный программный код для исполняемой программы разрабатывается на алгоритмических языках C или Fortran с применением той или иной реализации библиотеки MPI. Количество процессов и число используемых процессоров определяется в момент запуска параллельной программы средствами среды исполнения MPI программ и в ходе вычислений не может меняться без применения специальных, но редко задействуемых средств динамического порождения процессов и управления ими, появившихся в стандарте MPI версии 2.0. Все процессы программы последовательно перенумерованы от 0 до p1, где p есть общее количество процессов. Номер процесса именуется рангом процесса. Основу MPI составляют операции передачи сообщений. Среди предусмотренных в составе MPI функций различаются парные (pointtopoint) операции между двумя процессами и коллективные (collective) коммуникационные действия для одновременного взаимодействия нескольких процессов. Для выполнения парных операций могут использоваться разные режимы передачи, среди которых синхронный, блокирующий и др. Процессы параллельной программы объединяются в группы. Другим важным понятием MPI, описывающим набор процессов, является понятие коммуникатора. Под коммуникатором в MPI понимается специально создаваемый служебный объект, который объединяет в своем составе группу процессов и ряд дополнительных параметров (контекст), используемых при выполнении операций передачи данных. Парные операции передачи данных выполняются только для процессов, принадлежащих одному и тому же коммуникатору. Коллективные операции применяются одновременно для всех процессов одного коммуникатора. Как результат, указание используемого коммуникатора является обязательным для операций передачи данных в MPI. В ходе вычислений могут создаваться новые и удаляться существующие группы процессов и коммуникаторы. Один и тот же процесс может принадлежать разным группам и коммуникаторам. Все имеющиеся в параллельной программе процессы входят в состав конструируемого по умолчанию коммуникатора с идентификатором MPI_COMM_WORLD. При выполнении операций передачи сообщений для указания передаваемых или получаемых данных в функциях MPI необходимо указывать тип пересылаемых данных. MPI содержит большой набор базовых типов данных, во многом совпадающих с типами данных в алгоритмических языках C и Fortran. Кроме того, в MPI имеются возможности создания новых производных типов данных для более точного и краткого описания содержимого пересылаемых сообщений. Итак, если сформулировать коротко, MPI это библиотека функций, обеспечивающая взаимодействие параллельных процессов с помощью механизма передачи сообщений. Это библиотека, состоящая примерно из 130 функций, в число которых входят: Функции инициализации и закрытия MPI-процессов; Функции, реализующие парные операции; Функции, реализующие коллективные операции; Функции для работы с группами процессов и коммуникаторами; Функции для работы со структурами данных; Функции формирования топологии процессов. Изучение MPI начнем с рассмотрения базового набора функций, образующих минимально полный набор, достаточный для написания простейших программ. MPI означает интерфейс передачи сообщений. Это набор объявлений API о передаче сообщений (таких как отправка, получение, широковещательная передача и т. Д.) И о том, какого поведения следует ожидать от реализаций.Идея "message passing" довольно абстрактна. Это может означать передачу сообщений между локальными процессами или процессами, распределенными по сетевым хостам, и т. Д. Современные реализации очень стараются быть универсальными и абстрагироваться от множества базовых механизмов (доступ к общей памяти, сеть IO и т. Д.). OpenMP -это API, который предназначен для того, чтобы (предположительно) упростить написание многопроцессорных программ с общей памятью. Нет никакого понятия о передаче сообщений. Вместо этого с помощью набора стандартных функций и директив компилятора вы пишете программы, которые параллельно выполняют локальные потоки, и контролируете поведение этих потоков (к какому ресурсу они должны иметь доступ, как они синхронизируются и т. Д.). OpenMP требует поддержки компилятора, поэтому вы также можете рассматривать его как расширение поддерживаемых языков. Базовые функции библиотеки MPI и их параметры. Любая прикладная MPI-программа (приложение) должна начинаться с вызова функции инициализации MPI: функции MPI_Init. В результате выполнения этой функции создается группа процессов, в которую помещаются все процессы приложения, и создается область связи, описываемая предопределенным коммуникатором MPI_COMM_WORLD. Эта область связи объединяет все процессы-приложения. Процессы в группе упорядочены и пронумерованы от 0 до groupsize-1, где groupsize равно числу процессов в группе. Кроме этого, создается предопределенный коммуникатор MPI_COMM_SELF, описывающий свою область связи для каждого отдельного процесса. Синтаксис функции инициализации MPI_Init значительно отличается в языках C и FORTRAN: C: int MPI_Init(int *argc, char ***argv) FORTRAN: MPI_INIT(IERROR) INTEGER IERROR В программах на C каждому процессу при инициализации передаются аргументы функции main, полученные из командной строки. В программах на языке FORTRAN параметр IERROR является выходным и возвращает код ошибки. Функция завершения MPI программ MPI_Finalize C: int MPI_Finalize(void) FORTRAN: MPI_FINALIZE(IERROR) INTEGER IERROR Функция закрывает все MPI-процессы и ликвидирует все области связи. Функция определения числа процессов в области связи MPI_Comm_size C: int MPI_Comm_size(MPI_Comm comm, int *size) FORTRAN: MPI_COMM_SIZE(COMM, SIZE, IERROR) INTEGER COMM, SIZE, IERROR
Функция возвращает количество процессов в области связи коммуникатора comm. До создания явным образом групп и связанных с ними коммуникаторов (раздел 6) единственно возможными значениями параметра COMM являются MPI_COMM_WORLD и MPI_COMM_SELF, которые создаются автоматически при инициализации MPI. Подпрограмма является локальной. Функция определения номера процесса MPI_Comm_rank C: int MPI_Comm_rank(MPI_Comm comm, int *rank) FORTRAN: MPI_COMM_RANK(COMM, RANK, IERROR) INTEGER COMM, RANK, IERROR
Функция возвращает номер процесса, вызвавшего эту функцию. Номера процессов лежат в диапазоне 0..size-1 (значение size может быть определено с помощью предыдущей функции). Подпрограмма является локальной. В минимальный набор следует включить также две функции передачи и приема сообщений. Функция передачи сообщения MPI_Send C: int MPI_Send(void* buf, int count, MPI_Datatype datatype, int dest, int tag, MPI_Comm comm) FORTRAN: MPI_SEND(BUF, COUNT, DATATYPE, DEST, TAG, COMM, IERROR) INTEGER COUNT, DATATYPE, DEST, TAG, COMM, IERROR
Функция выполняет посылку count элементов типа datatype сообщения с идентификатором tag процессу dest в области связи коммуникатора comm. Переменная buf - это, как правило, массив или скалярная переменная. В последнем случае значение count = 1. Функция приема сообщения MPI_Recv C: int MPI_Recv(void* buf, int count, MPI_Datatype datatype, int source, int tag, MPI_Comm comm, MPI_Status *status) FORTRAN: MPI_RECV(BUF, COUNT, DATATYPE, SOURCE, TAG, COMM, STATUS, IERROR) INTEGER COUNT, DATATYPE, SOURCE, TAG, COMM, STATUS(MPI_STATUS_SIZE), IERROR
Функция выполняет прием count элементов типа datatype сообщения с идентификатором tag от процесса source в области связи коммуникатора comm. Более детально об операциях обмена сообщениями мы поговорим в следующем разделе, а в заключение этого раздела рассмотрим функцию, которая не входит в очерченный нами минимум, но которая важна для разработки эффективных программ. Речь идет о функции получения отсчета времени - таймере. С одной стороны, такие функции имеются в составе всех операционных систем, но, с другой стороны, существует полнейший произвол в их реализации. Опыт работы с различными операционными системами показывает, что при переносе приложений с одной платформы на другую первое (а иногда и единственное), что приходится переделывать - это обращения к функциям учета времени. Поэтому разработчики MPI, добиваясь полной независимости приложений от операционной среды, определили и свои функции отсчета времени. Функция отсчета времени (таймер) MPI_Wtime C: double MPI_Wtime(void) FORTRAN: DOUBLE PRECISION MPI_WTIME() Функция возвращает астрономическое время в секундах, прошедшее с некоторого момента в прошлом (точки отсчета). Гарантируется, что эта точка отсчета не будет изменена в течение жизни процесса. Для хронометража участка программы вызов функции делается в начале и конце участка и определяется разница между показаниями таймера. { double starttime, endtime; starttime = MPI_Wtime(); ... хронометрируемый участок ... endtime = MPI_Wtime(); printf("Выполнение заняло %f секунд\n", endtime-starttime); } Функция MPI_Wtick, имеющая точно такой же синтаксис, возвращает разрешение таймера (минимальное значение кванта времени). Основные понятия в MPI. В каждом из процессов, входящих в коммуникатор MPI_COMM_WORLD, прочесть одно целое число A и вывести его удвоенное значение. Кроме того, для главного процесса (процесса ранга 0) вывести количество процессов, входящих в коммуникатор MPI_COMM_WORLD. Для ввода и вывода данных использовать поток ввода-вывода pt. В главном процессе продублировать вывод данных в разделе отладки, отобразив на отдельных строках удвоенное значение A и количество процессов (использовать два вызова функции ShowLine, определенной в задачнике наряду с функцией Show). Прежде всего разъясним термины параллельного MPI-программирования. При параллельном выполнении программы запускается несколько экземпляров этой программы. Каждый запущенный экземпляр представляет собой отдельный процесс (англ. process), который может взаимодействовать с другими процессами, обмениваясь сообщениями (messages). MPI-функции предоставляют разнообразные средства для реализации такого взаимодействия (аббревиатура MPI расшифровывается как «Message Passing Interface» — интерфейс передачи сообщений). Для идентификации каждого процесса в группе процессов используется понятие ранга (rank). Ранг процесса — это порядковый номер процесса в группе процессов, отсчитываемый от нуля (таким образом, первый процесс имеет ранг 0, а последний процесс — ранг K – 1, где K — количество процессов в группе). При этом группа процессов может включать лишь часть всех запущенных процессов параллельного приложения. Заметим, что в формулировках заданий буква K используется обычно для обозначения количества процессов. С группой процессов связывается особая сущность библиотеки MPI, называемая коммуникатором (communicator). Любое взаимодействие процессов возможно только в рамках того или иного коммуникатора. Стандартный коммуникатор, содержащий все процессы, запущенные при параллельном выполнении программы, имеет имя MPI_COMM_WORLD. «Пустой» коммуникатор, не содержащий ни одного процесса, имеет имя MPI_COMM_NULL. Коммуникатор можно представлять себе как канал, соединяющий между собой некоторую группу процессов. В некоторых случаях бывает удобно организовывать дополнительные каналы, которые, например, содержат не все исходные процессы или в которых изменен порядок их следования. В этой ситуации создаются новые коммуникаторы. Более подробно работа с коммуникаторами рассматривается в группах заданий MPI5Comm и MPI8Inter. В заданиях начальных четырех групп всегда используется стандартный коммуникатор MPI_COMM_WORLD. Процесс ранга 0 часто называют главным процессом (master process), а остальные процессы — подчиненными процессами (slave processes). Как правило, главный процесс играет особую роль по отношению к подчиненным процессам, передавая им свои данные или получая данные от всех (или некоторых) подчиненных процессов. В рассматриваемом задании MPI1Proc2 все процессы должны выполнить одно и то же действие — прочесть одно целое число и вывести его удвоенное значение, а главный процесс, кроме этого, должен выполнить дополнительное действие — вывести количество всех запущенных процессов (иными словами, количество всех процессов, входящих в коммуникатор MPI_COMM_WORLD). Обратите внимание на то, что в этом простом задании процессам не требуется обмениваться сообщениями друг с другом (таковы все задания вводной группы MPI1Proc). Поддерживаемые типы данных в MPI. Синхронная и асинхронная (с блокировкой, без блокировки) передача сообщений в MPI. Основы использования, отличие. Коммуникационные операции типа точка-точка. Коллективные коммуникационные операции. РУС Коллективная коммуникационная операция предполагает передачу данных с использованием всех процессов внутри данного коммуникатора, коммуникатор по умолчанию, содержащий все доступные процессы, называется MPI_COMM_WORLD. Когда выполняется коллективный вызов, он должен быть вызван всеми процессами внутри связи. Главное отличие коллективных операций от операций типа точка-точка состоит в том, что в них всегда участвуют все процессы, связанные с некоторым коммуникатором. Несоблюдение этого правила приводит либо к аварийному завершению задачи, либо к еще более неприятному зависанию задачи. Набор коллективных операций включает: Синхронизация всех процессов с помощью барьеров (MPI_Barrier) Коллективные коммуникационные операции Глобальные вычислительные операции 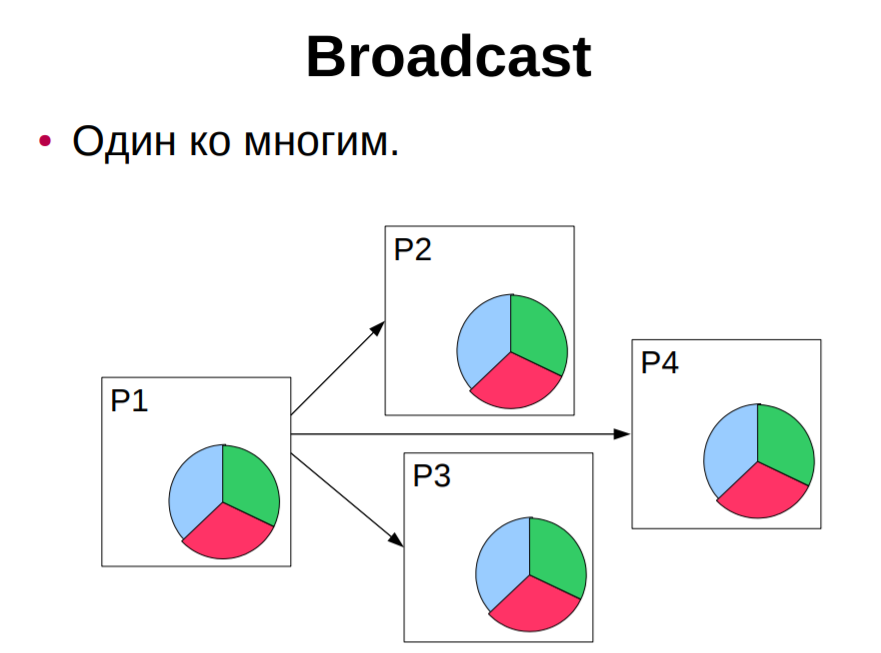 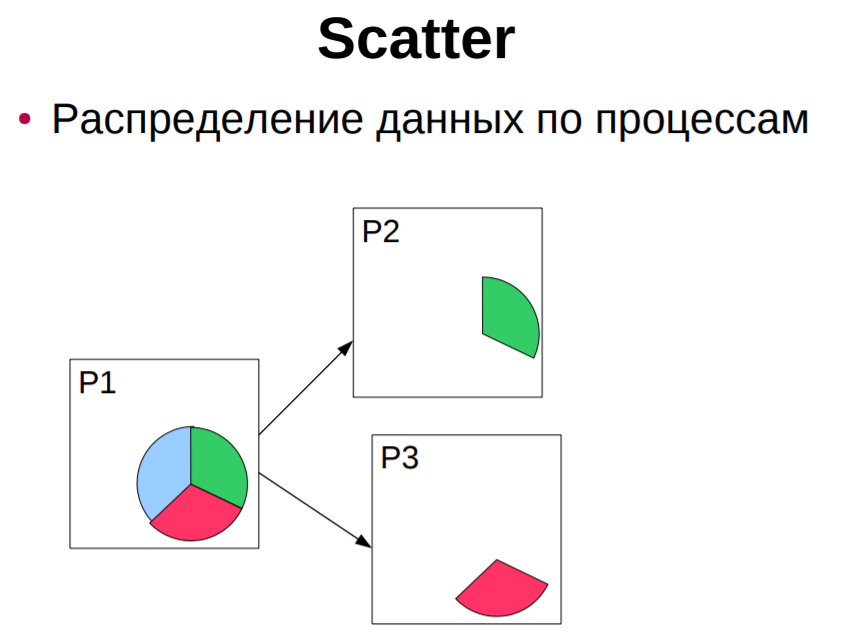 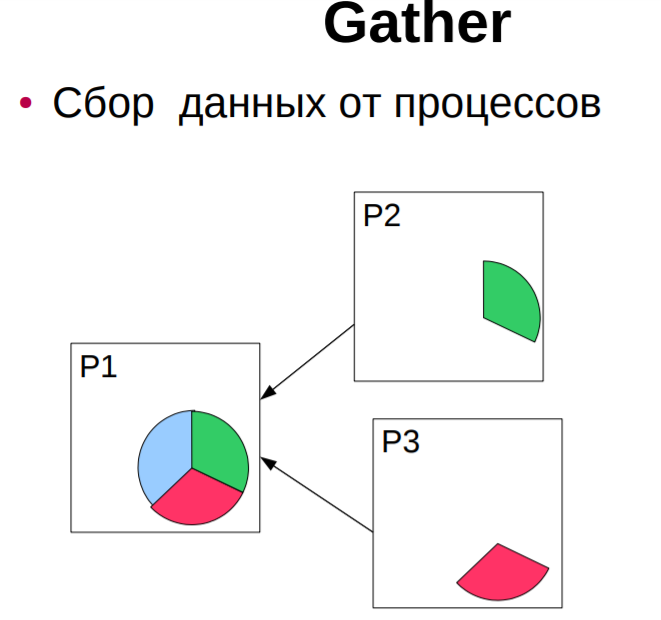 Коллективные коммуникационные операции, в число которых входят: рассылка информации от одного процесса всем остальным членам некоторой области связи (MPI_Bcast); int MPI_Bcast(void *buf,int count,MPI_Datatype type,int root,MPI_Comm comm),
сборка (gather) распределенного по процессам массива в один массив с сохранением его в адресном пространстве выделенного (root) процесса (MPI_Gather, MPI_Gatherv); сборка (gather) распределенного массива в один массив с рассылкой его всем процессам некоторой области связи (MPI_Allgather, MPI_Allgatherv); разбиение массива и рассылка его фрагментов (scatter) всем процессам области связи (MPI_Scatter, MPI_Scatterv); совмещенная операция Scatter/Gather (All-to-All), каждый процесс делит данные из своего буфера передачи и разбрасывает фрагменты всем остальным процессам, одновременно собирая фрагменты, посланные другими процессами в свой буфер приема (MPI_Alltoall, MPI_Alltoallv). Отличительные особенности коллективных операций: - коллективные коммуникации не взаимодействуют с коммуникациями типа точка-точка; - коллективные коммуникации выполняются в режиме с блокировкой. Возврат из подпрограммы в каждом процессе происходит тогда, когда его участие в коллективной операции завершилось, однако это не означает, что другие процессы завершили операцию; -количество получаемых данных должно быть равно количеству посланных данных. Типы элементов посылаемых и получаемых сообщений должны совпадать. Сообщения не имеют идентификаторо Функции MPI_Send(), MPI_Ssend(), MPI_Bsend(), MPI_Rsend(), MPI_Recv(). Принцип работы, отличия. Параметры, параметр MPI_STATUS. РУС Функция передачи сообщения MPI_Send C: int MPI_Send(void* buf, int count, MPI_Datatype datatype, int dest, int tag, MPI_Comm comm) FORTRAN: MPI_SEND(BUF, COUNT, DATATYPE, DEST, TAG, COMM, IERROR) INTEGER COUNT, DATATYPE, DEST, TAG, COMM, IERROR
Функция выполняет посылку count элементов типа datatype сообщения с идентификатором tag процессу dest в области связи коммуникатора comm. Переменная buf - это, как правило, массив или скалярная переменная. В последнем случае значение count = 1. Buffered (MPI_Bsend) – отправляемое сообщение помещается в буфер и функция завершает свою работу. Сообщение будет отправлено библиотекой. Буферизованная передача гарантирует немедленное завершение, поскольку сообщение вначале копируется в системный буфер, а затем доставляется. Недостатком ее является необходимость выделения специальных буферов, потребляющих ресурсы системы. Synchronous (MPI_Ssend) – функция завершает своё выполнение когда процесс-получатель вызвал MPI_Recv и начал копировать сообщение. После вызова функции можно безопасно использовать буфер. Синхронная передача может быть существенно медленнее стандартной. Однако она не приведет к перегрузке коммуникационной сети. Использование этого режима передачи также облегчает отладку параллельного приложения. Ready (MPI_Rsend) – функция успешно выполняется только если процесс-получатель уже вызвал функцию MPI_Recv. Этот режим гарантирует отсутствие в коммуникационной сети блуждающих сообщений. Функция приема сообщения MPI_Recv C: int MPI_Recv(void* buf, int count, MPI_Datatype datatype, int source, int tag, MPI_Comm comm, MPI_Status *status) FORTRAN: MPI_RECV(BUF, COUNT, DATATYPE, SOURCE, TAG, COMM, STATUS, IERROR) INTEGER COUNT, DATATYPE, SOURCE, TAG, COMM, STATUS(MPI_STATUS_SIZE), IERROR
Функция выполняет прием count элементов типа datatype сообщения с идентификатором tag от процесса source в области связи коммуникатора comm. функция приема MPI_Recv (парная для MPI_Send) является локальной: она всего лишь пассивно ждет поступления данных, ничего не пытаясь сообщить другим ветвям. MPI_Status status; Status содержит информацию о принятом сообщении: его идентификатор, номер задачи-передатчика, код завершения и количество фактически пришедших данных. Структура MPI_status имеет три обязательных поля с именами MPI SOURCE, MPI TAG, MPI_ERROR, которые содержат номер процесса, пославшего сообщения, тэг принятого сообщения и код ошибки, если передача сообщения прошла некорректно. Поле MPI ERROR избыточно при обычном вызове функции приема сообщения, когда код ошибки совпадает с кодом возврата функции. Оно предназначено главными образом для применения в функциях, завершающих выполнение нескольких операций приема, каждая из которых может вызвать ошибку. Поля MPI SOURCE и MPI TAG нужны для того, чтобы в случае использования шаблонов определить номер процесса-отправителя и тэг пришедшего сообщения. Если номер процесса-отправителя и тэг указаны точно в аргументах при вызове функции приема сообщения, то поля MPI_SOURCE и MPI_TAG дублируют эту информацию. Семантика точечных обменов (Этапы выполнения коммуникационных операции типа точка-точка). РУС К операциям этого типа относятся две коммуникационные процедуры (MPI_Send, MPI_Recv). В коммуникационных операциях типа точка-точка всегда участвуют 2 процесса: передающий и принимающий. Типы: – Синхронная передача- Подтверждение того, что сообщение получено. – Буферизованая = асинхронная. Информация о том, что сообщение послано. Это самый простой тип связи между задачами: одна ветвь вызывает функцию передачи данных, а другая - функцию приема. В MPI это выглядит, например, так: Задача 1 передает: int buf[10]; MPI_Send( buf, 5, MPI_INT, 1, 0, MPI_COMM_WORLD ); Задача 2 принимает: int buf[10]; MPI_Status status; MPI_Recv( buf, 10, MPI_INT, 0, 0, MPI_COMM_WORLD, &status ); Аргументы функций: Адрес буфера, из которого в задаче 1 берутся, а в задаче 2 помещаются данные. Помните, что наборы данных у каждой задачи свои, поэтому, например, используя одно и то же имя массива в нескольких задачах, Вы указываете не одну и ту же область памяти, а разные, никак друг с другом не связанные. Размер буфера. Задается не в байтах, а в количестве ячеек. Для MPI_Send указывает, сколько ячеек требуется передать (в примере передаются 5 чисел). В MPI_Recv означает максимальную емкость приемного буфера. Если фактическая длина пришедшего сообщения меньше - последние ячейки буфера останутся нетронутыми, если больше - произойдет ошибка времени выполнения. Тип ячейки буфера. MPI_Send и MPI_Recv оперируют массивами однотипных данных. Для описания базовых типов Си в MPI определены константы MPI_INT, MPI_CHAR, MPI_DOUBLE и так далее, имеющие тип MPI_Datatype. Их названия образуются префиксом "MPI_" и именем соответствующего типа (int, char, double, ...), записанным заглавными буквами. Пользователь может "регистрировать" в MPI свои собственные типы данных, например, структуры, после чего MPI сможет обрабатывать их наравне с базовыми. Процесс регистрации описывается в главе "Типы данных". Номер задачи, с которой происходит обмен данными. Все задачи внутри созданной MPI группы автоматически нумеруются от 0 до (размер группы-1). В примере задача 0 передает задаче 1, задача 1 принимает от задачи 0. Идентификатор сообщения. Это целое число от 0 до 32767, которое пользователь выбирает сам. Оно служит той же цели, что и, например, расширение файла - задача-приемник: по идентификатору определяет смысл принятой информации ; сообщения, пришедшие в неизвестном порядке, может извлекать из общего входного потока в нужном алгоритму порядке. Хорошим тоном является обозначение идентификаторов символьными именами посредством операторов "#define" или "const int". Описатель области связи (коммуникатор). Обязан быть одинаковым для MPI_Send и MPI_Recv. Статус завершения приема. Содержит информацию о принятом сообщении: его идентификатор, номер задачи-передатчика, код завершения и количество фактически пришедших данных. Блокирующие функции подразумевают выход из них только после полного окончания операции, т.е. вызывающий процесс блокируется, пока операция не будет завершена. Для функции посылки сообщения это означает, что все пересылаемые данные помещены в буфер (для разных реализаций MPI это может быть либо какой-то промежуточный системный буфер, либо непосредственно буфер получателя). Для функции приема сообщения блокируется выполнение других операций, пока все данные из буфера не будут помещены в адресное пространство принимающего процесса. Неблокирующие функции подразумевают совмещение операций обмена с другими операциями, поэтому неблокирующие функции передачи и приема по сути дела являются функциями инициализации соответствующих операций. Для опроса завершенности операции (и завершения) вводятся дополнительные функции. Как для блокирующих, так и неблокирующих операций MPI поддерживает четыре режима выполнения. Эти режимы касаются только функций передачи данных, поэтому для блокирующих и неблокирующих операций имеется по четыре функции посылки сообщения. В таблице 3.1 перечислены имена базовых коммуникационных функций типа точка-точка, имеющихся в библиотеке MPI. Тупиковые ситуации при точечных обменах сообщениями. Явление тупика наиболее распространено при блокирующих коммуникациях. Тупик случается, когда все задачи ожидают событий, которые еще не были инициализированы. Простейший пример тупика: каждая отправка из двух ждёт соответствующего ей получения, чтобы завершиться, но эти получения исполняются после отправок, так что, если отправки не завершены и не вернулись, то получения никогда не смогут исполниться и оба набора коммуникаций подвиснут на неопределённое время. Более сложный пример тупика может произойти, если размер сообщения больше порога; тупик произойдет из-за того, что ни одна задача не может согласоваться во времени (синхронизироваться) с соответствующим ей получением. Тупик все же может произойти и в случае, когда размер сообщения не превышает порога, если нет достаточного места в системном буфере. Обе задачи будут ожидать получения, чтобы переписать данные сообщения из системного буфера, но эти получения не могут исполниться, так как обе задачи заблокированы в отправке. Решения для исключения тупиков: Есть четыре способа избежать тупика: 1)различный порядок вызовов у задач Организуйте порядок, в котором одна задача объявляет первой свое получение, а вторая объявляет первой свою отправку. Это прояснение даст порядок, в котором сообщение в одном из направлений проходит раньше, чем в другом. 2)неблокирующие вызовы заставляют каждую задачу объявить неблокирующее получение до того, как она произведет какую-нибудь другую коммуникацию. Это дает возможность получить каждое сообщение независимо от того, над чем задача трудится, когда сообщение прибывает, и независимо от порядка, в котором отправки объявлены. 3)MPI_Sendrecv MPI_Sendrecv_replace Использование MPI_Sendrecv -- это элегантное решение, использующее возможности самой библиотеки MPI для исключения тупика. В этой версии используется два буфера: один для отправляемого сообщения, а другой для получаемого. В версии _replace система выделяет некоторое единственное буферное пространство (не зависящее от порогового предела) для обработки обмена сообщениями. Отправленное сообщение в этом буфере замещается полученным. Заметим здесь, что обмен с процессом, который имеет пустое значение MPI_PROC_NULL, не дает результата, а отправка на пустой процесс MPI_PROC_NULL всегда успешна. 4)буферизованный способ Используйте буферизованную отправку, чтобы можно было осуществлять вычисления после копирования отправляемого сообщения в пользовательский буфер. Это дает возможность исполнения получений. Организация буферизованных пересылок (Использование MPI_Bsend()). 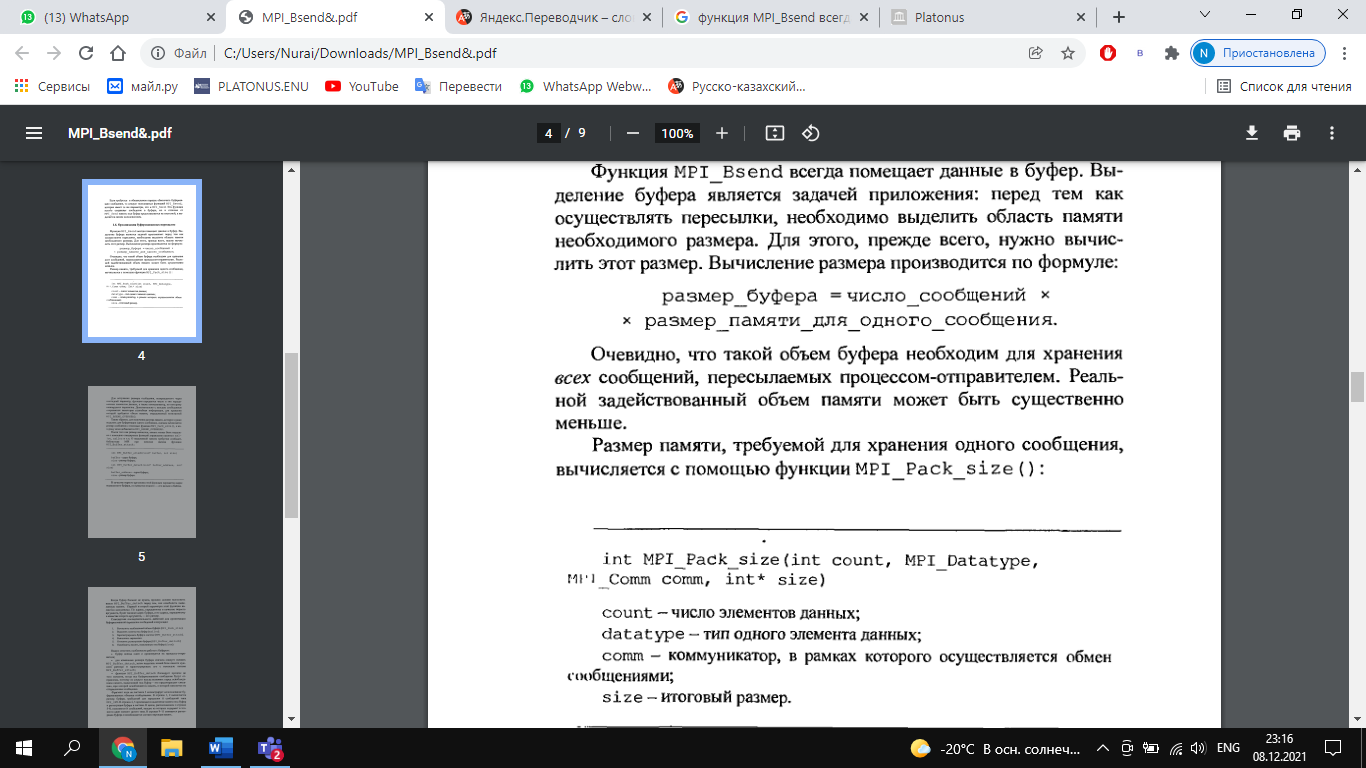 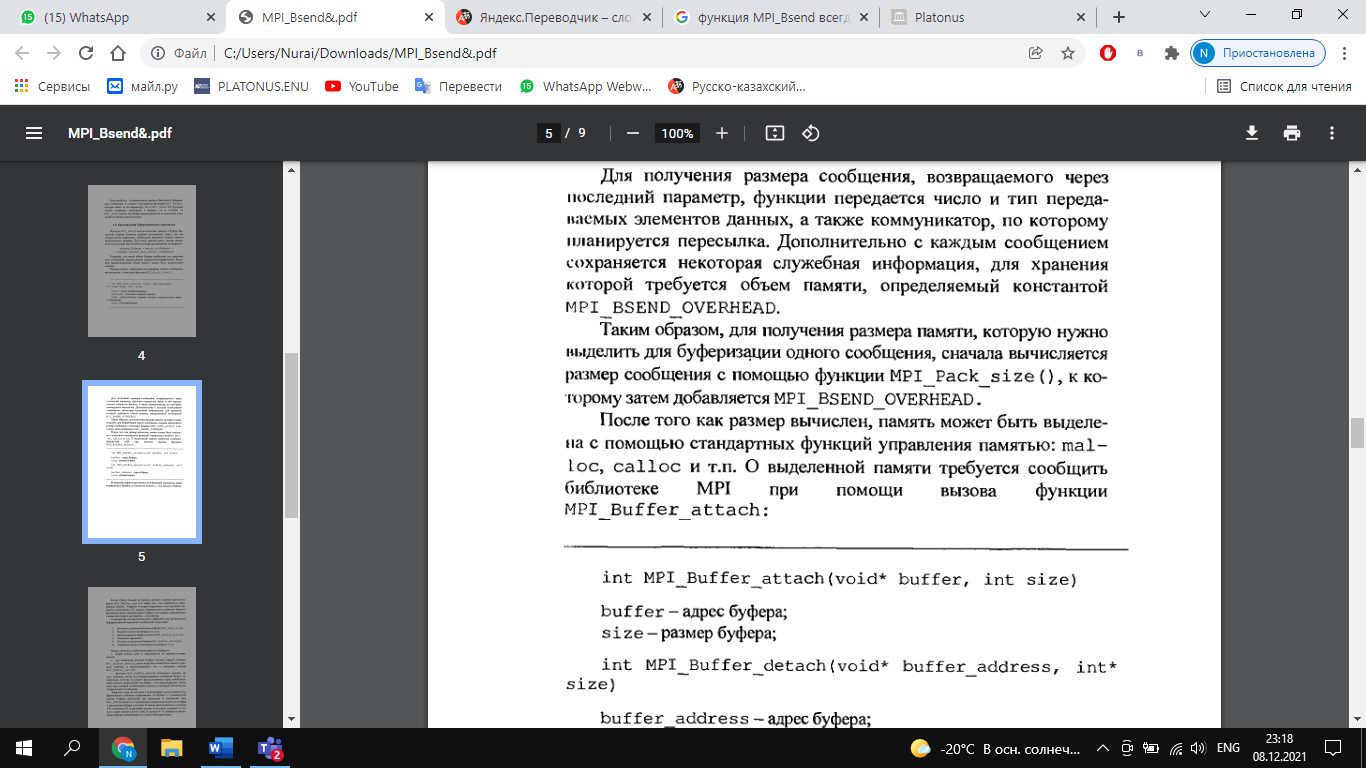 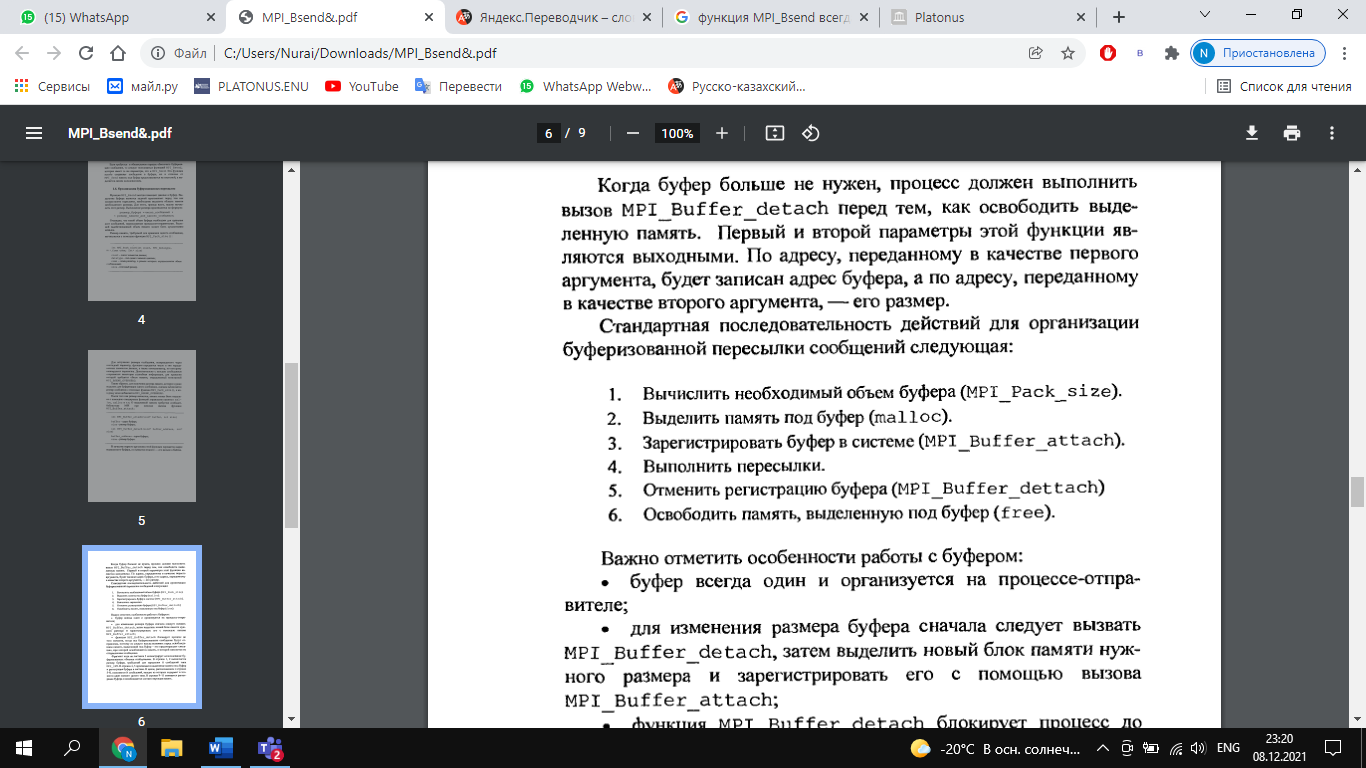 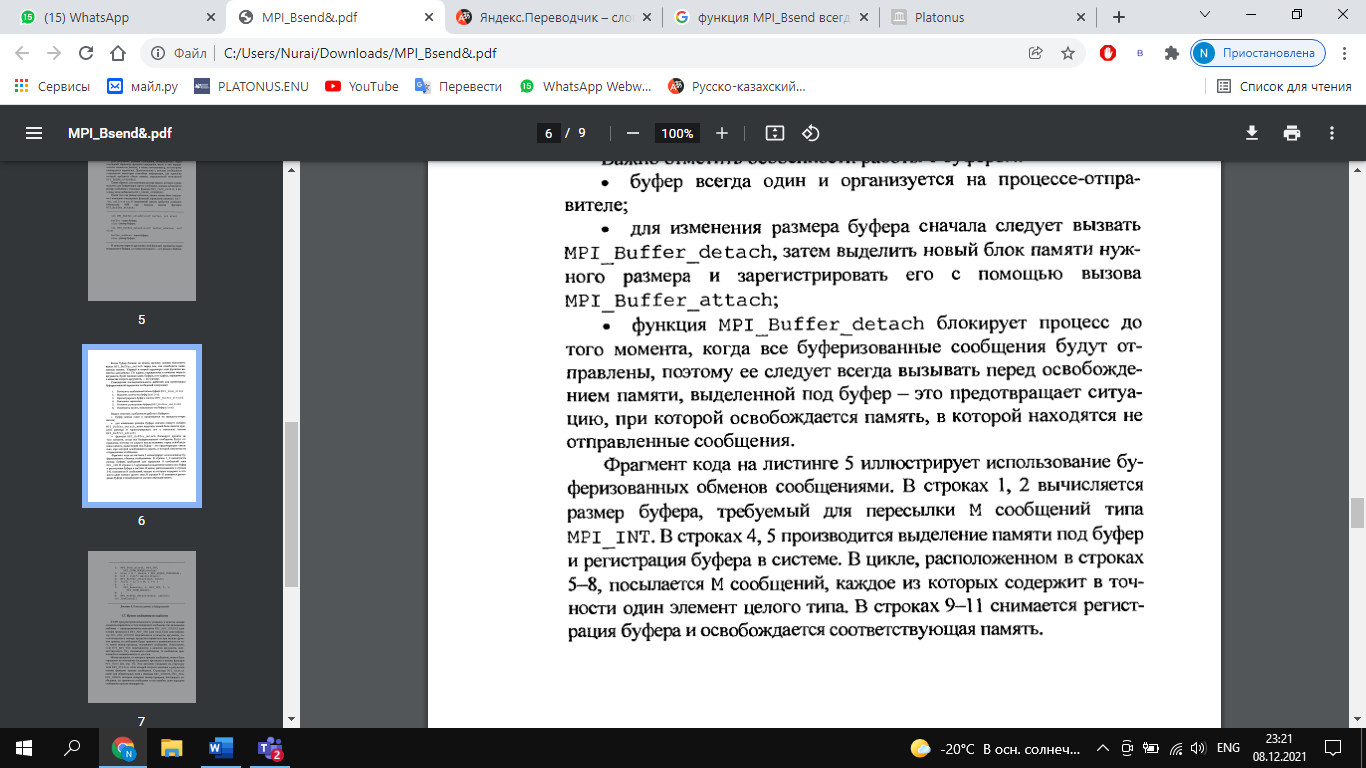 Вычисление размера области памяти для передаваемого сообщения. Функции MPI_Pack_size(), MPI_Buffer_attach(),MPI_Buffer_detach(), константаMPI_BSEND_OVERHEAD. то Функции MPI_Get_count() и MPI_Probe().Принцип работы и особенности использования, отличие. Неблокирующие коммуникационные операции. Объект "запрос обмена" (request). Использование неблокирующих коммуникационных операций повышает безопасность с точки зрения возникновения тупиковых ситуаций, а также может увеличить скорость работы программы за счет совмещения выполнения вычислительных и коммуникационных операций. Эти задачи решаются разделением коммуникационных операций на две стадии: инициирование операции и проверку завершения операции. Неблокирующие операции используют специальный скрытый (opaque) объект "запрос обмена" (request) для связи между функциями обмена и функциями опроса их завершения. Для прикладных программ доступ к этому объекту возможен только через вызовы MPI-функций. Если операция обмена завершена, подпрограмма проверки снимает "запрос обмена", устанавливая его в значение MPI_REQUEST_NULL. Снять запрос без ожидания завершения операции можно подпрограммой MPI_Request_free. Функции MPI_Isend(), MPI_Irecv(), опишите параметры, параметр типа MPI_Request. Возврат из подпрограммы происходит немедленно (immediate), без ожидания окончания передачи данных. Этим объясняется префикс I в именах функций. Поэтому переменную buf повторно использовать нельзя до тех пор, пока не будет погашен "запрос обмена". Это можно сделать с помощью подпрограмм MPI_Wait или MPI_Test, передав им параметр request. Параметры:
|