вфывфыв. 1. Абстрагирование данных. Концепция типа данных. Массив фундаментальная структура данных. Отображение массива на оперативную память, выравнивание, упаковка
 Скачать 6.92 Mb. Скачать 6.92 Mb.
|

|
1. Абстрагирование данных. Концепция типа данных. Массив – фундаментальная структура данных. Отображение массива на оперативную память, выравнивание, упаковка. Структура данных — это программная единица, позволяющая хранить и обрабатывать множество однотипных и/или логически связанных данных в ЭВМ. Абстрактный тип данных (АТД) — это математическая модель для типов данных, где тип данных определяется поведением (семантикой) с точки зрения пользователя данных, а именно в терминах возможных значений, возможных операций над данными этого типа и поведения этих операций. Типы СД: Линейные/нелинейные. С последовательным распределением элементов/с произвольно связанным распределением элементов в памяти. Массив -- упорядоченный и ограниченный набор однотипных элементов. Массив — это регулярная структура; все его компоненты — одного типа, называемого базовым типом. Массив — также структура с так называемым случайным доступом, все его компоненты могут выбираться произвольно и являются одинаково доступными. Округление числа занимаемых слов до ближайшего целого называется выравниванием. Выравнивание понижает коэффициент использования памяти. Если несколько компонентов записи умещаются в одном слове памяти, то может идти речь об упаковке.  Все компоненты массива – одного базового типа.    2. Записи (record) - фундаментальные структуры. Отображение записи на ОП, упакованная запись. Представление множества, как фундаментальной структуры данных, в память машины. Запись и массив имеют общее свойство: оба являются структурами со «случайным доступом». Запись — более универсальная структура, поскольку не требуется, чтобы типы всех ее компонент были одинаковы. Если несколько компонент записи умещаются в одном слове памяти, то может идти речь об упаковке. Так же как для массива, желательность упаковки можно указать в описании с помощью слова packed перед словом record.  Фундаментальная структура данных — множество. Представление множеств их характеристической функцией позволяет реализовать операции объединения, пересечения и разности двух множеств с помощью элементарных логических операций.  3. Алгоритм линейного поиска элемента в массиве и его оптимизация – установка «барьера». Для нахождения некоторого элемента (ключа) в заданном неупорядоченном массиве используется алгоритм линейного (последовательного) поиска. Слово «последовательный» содержит в себе основную идею метода. Начиная с первого, все элементы массива последовательно просматриваются и сравниваются с искомым. Если на каком-то шаге текущий элемент окажется равным искомому, тогда элемент считается найденным. Барьер - это механизм синхронизации потоков, позволяющий блокировать выполнение в определённой точке программы до тех пор, пока все остальные потоки не придут к барьеру, а затем разблокировать все потоки и продолжить их работу. Барьеры особенно полезны, когда потоки выполняют несколько этапов циклически, что вполне реально в алгоритме линейного поиска.   4. Алгоритм бинарного поиска по ключу в массиве и пути повышения его эффективности. Бинарный поиск — очень быстрый алгоритм с не сложной реализацией, который находит элемент с определенным значением в уже отсортированном массиве. Бинарный поиск производится в упорядоченном массиве. При бинарном поиске искомый ключ сравнивается с ключом среднего элемента в массиве. Если они равны, то поиск успешен. В противном случае поиск осуществляется аналогично в левой или правой частях массива. Интерполяционный поиск Одно из возможных усовершенствований бинарного поиска - более точное предположение о положении ключа поиска в текущем интервале (вместо тупого сравнения его на каждом шаге со средним элементом). Эта тактика имитирует способ поиска имени в телефонном справочнике или слова в словаре: если нужная запись начинается с буквы, находящейся в начале алфавита, мы открываем книгу ближе к началу, а если она начинается с буквы из конца алфавита, поиск выполняется в конце книги.   5. Сортировка: общие понятия, классификация, характеристики, цели. Сортировка массива прямым включением (блок-схема алгоритма). 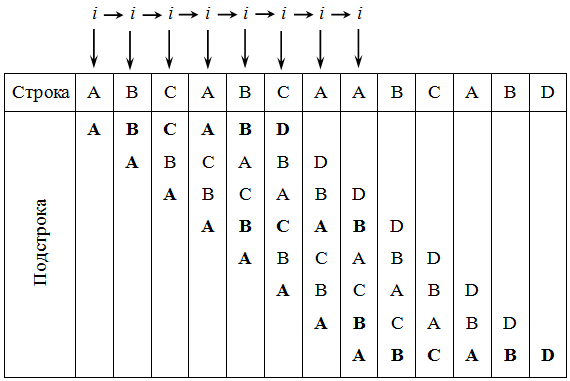 Символы, которые сравниваются, на рисунке выделены жирным. Рассматриваемые сдвиги подстроки повторяются до тех пор, пока конец подстроки не достиг конца строки или не произошло полное совпадение символов подстроки со строкой, то есть найдется подстрока. Символы, которые сравниваются, на рисунке выделены жирным. Рассматриваемые сдвиги подстроки повторяются до тех пор, пока конец подстроки не достиг конца строки или не произошло полное совпадение символов подстроки со строкой, то есть найдется подстрока.Или Поиск строки формально определяется следующим образом. Пусть задан массив Т из N элементов и массив W из M элементов, причем 0 Пример. Требуется найти все вхождения образца W = abaa в текст T=abcabaabcabca.  Образец входит в текст только один раз, со сдвигом S=3, индекс i=4.   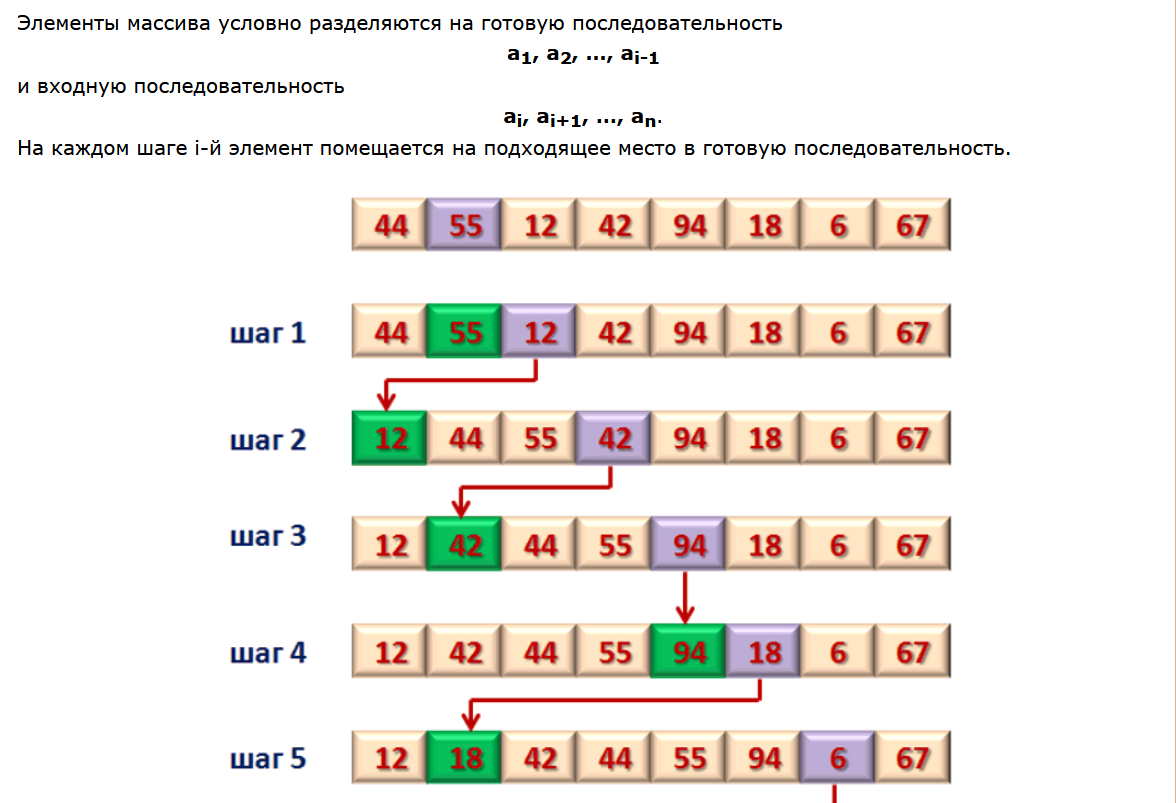 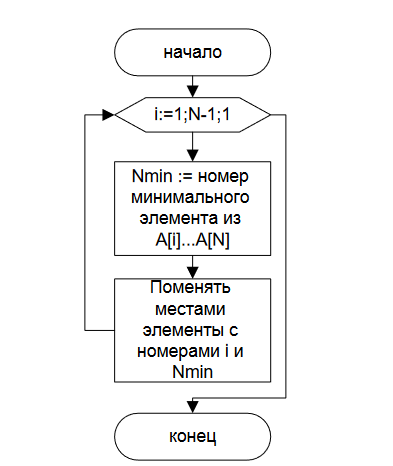 6. Сортировка: общие понятия, классификация, характеристики, цели. Сортировка массива прямым включением (блок-схема алгоритма).  Алгоритм сортировки — это алгоритм для упорядочивания элементов в массиве. В случае, когда элемент в массиве имеет несколько полей, поле, служащее критерием порядка, называется ключом сортировки. Алгоритм сортировки — это алгоритм для упорядочивания элементов в массиве. В случае, когда элемент в массиве имеет несколько полей, поле, служащее критерием порядка, называется ключом сортировки.Классификация: Сортировка пузырьком — один из самых известных алгоритмов сортировки. Здесь нужно последовательно сравнивать значения соседних элементов и менять числа местами, если предыдущее оказывается больше последующего. Таким образом элементы с большими значениями оказываются в конце списка, а с меньшими остаются в начале.  Шейкерная сортировка отличается от пузырьковой тем, что она двунаправленная: алгоритм перемещается не строго слева направо, а сначала слева направо, затем справа налево. Сортировка расчёской — улучшение сортировки пузырьком. Её идея состоит в том, чтобы «устранить» элементы с небольшими значения в конце массива, которые замедляют работу алгоритма. Если при пузырьковой и шейкерной сортировках при переборе массива сравниваются соседние элементы, то при «расчёсывании» сначала берётся достаточно большое расстояние между сравниваемыми значениями, а потом оно сужается вплоть до минимального. (дополнительно про расчёску) Первоначальный разрыв нужно выбирать не случайным образом, а с учётом специальной величины — фактора уменьшения, оптимальное значение которого равно 1,247. Сначала расстояние между элементами будет равняться размеру массива, поделённому на 1,247; на каждом последующем шаге расстояние будет снова делиться на фактор уменьшения — и так до окончания работы алгоритма. Цель: Операция сортировки данных используется всегда для удобства нахождения нужной информации. Когда на экране (или на бумаге) отображается таблица, гораздо легче найти нужную строку, если эти строки упорядочены. Сортировка методом прямого включения, так же, как и сортировка методом простого выбора, обычно применяется для массивов, не содержащих повторяющихся элементов. Сортировка этим методом производится последовательно шаг за шагом. На k –м шаге считается, что часть массива, содержащая первые k– 1 элемент, уже упорядочена, т.е. UPD: (вопрос №8) сортировка прямым выбором предпочтительнее алгоритму прямого включения, однако, если ключи в начале упорядочены или почти упорядочены, прямое включение будет оставаться несколько более быстрым. 7. Алгоритм сортировки двоичным включением – модификация прямого включения. Блок-схема. Рассмотрим пример сортировки по возрастанию восьми случайно выбранных чисел 44 55 12 42 18 19 06 67. При i=6 отсортированная последовательность состоит из пяти чисел 12 18 42 44 55. Очередной элемент 19 необходимо вставить в последовательность. Поиск места будет проходить следующим образом: находим средний элемент отсортированной последовательности. Это 42. Если он больше вставляемого элемента, то находим средний элемент для левой части последовательности относительно элемента 42, иначе находим средний элемент правой части последовательности относительно 42. Следующий средний - 18. Повторяем сравнения и т.д. + Такой модифицированный алгоритм сортировки называется методом с двоичным включением. 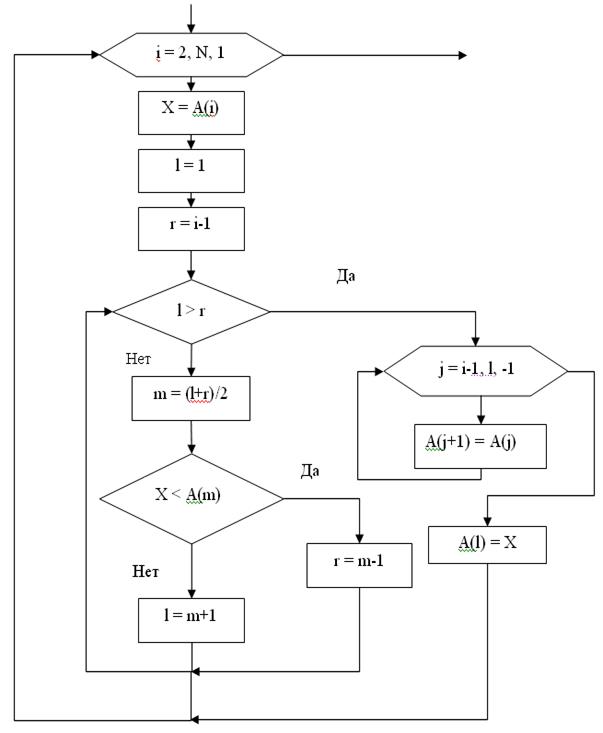 8. Сортировка массива прямым выбором (блок-схема алгоритма).    9. Сортировка массива с помощью прямого обмена (пузырьковая сортировка) - блок-схема алгоритма.  10. Алгоритм шейкерной сортировки (блок-схема алгоритма).  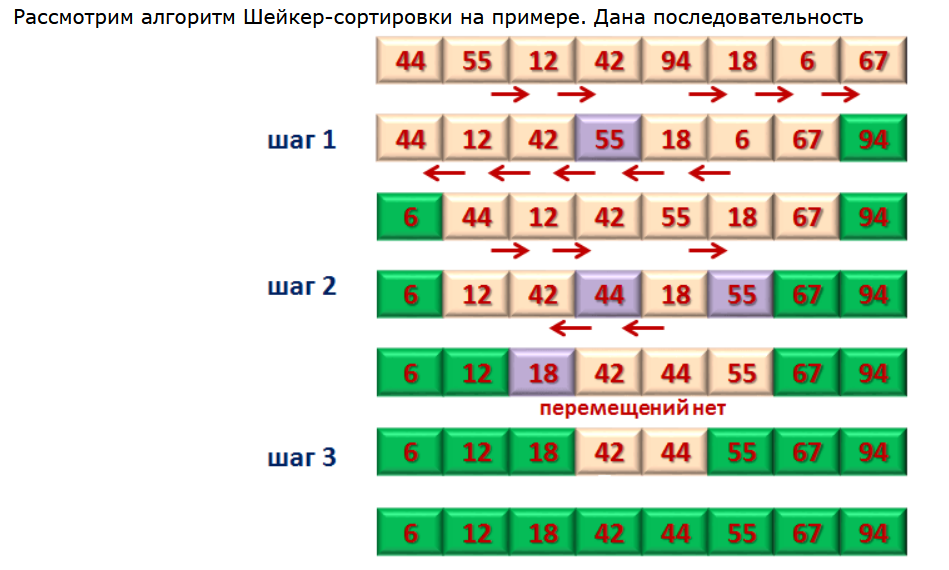  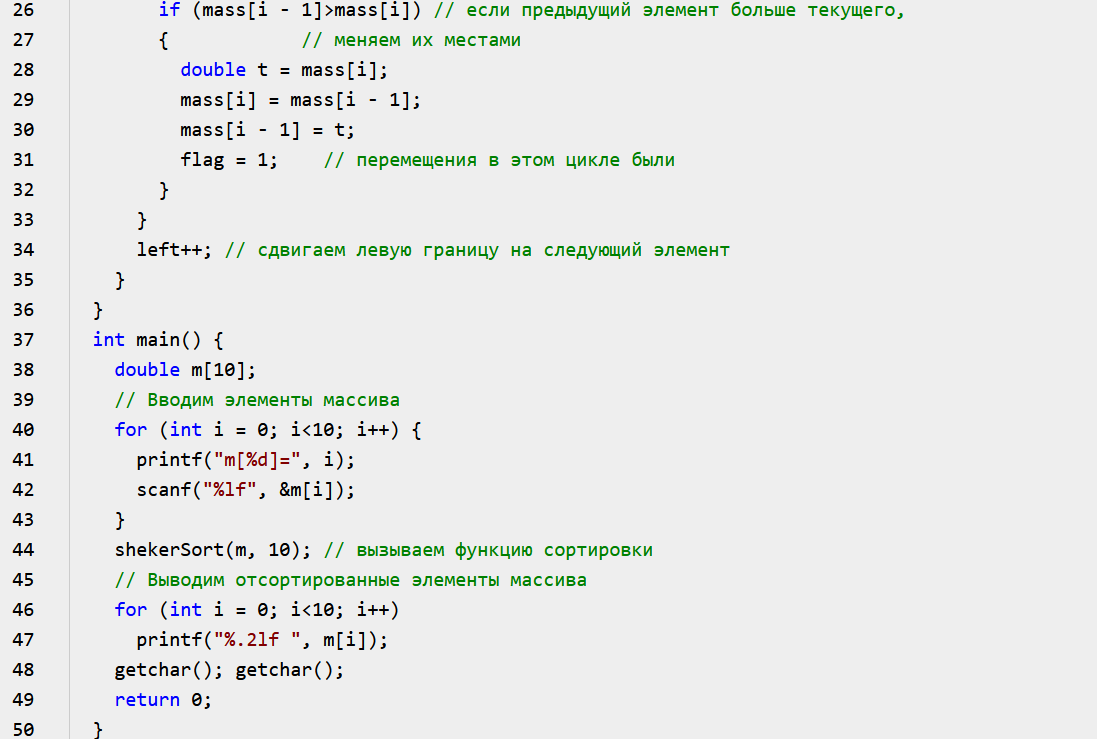 11. Улучшенный метод сортировки – сортировка Шелла (блок-схема алгоритма). 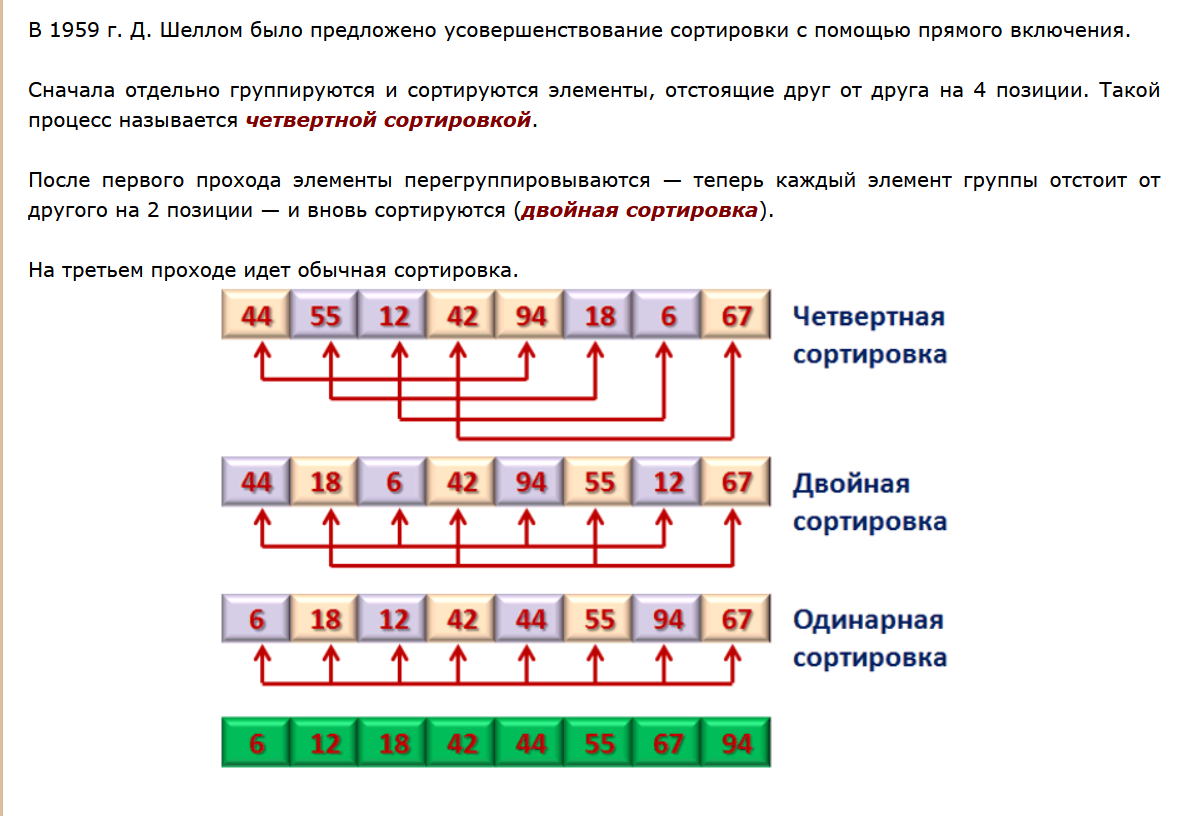    12. Сортировка деревом. Сдвигающий алгоритм Флойда и его применение для построения пирамиды и получения упорядоченности элементов с помощью пирамиды.    13. Сортировка с помощью разделения – Quick Sort. Разбиение Ломуто, разбиение Хоара (блок – схема разделения и ее рекурсивное использование в общей процедуре Quick Sort).    14. Сортировка последовательностей. Прямое слияние (рекурсивный алгоритм).  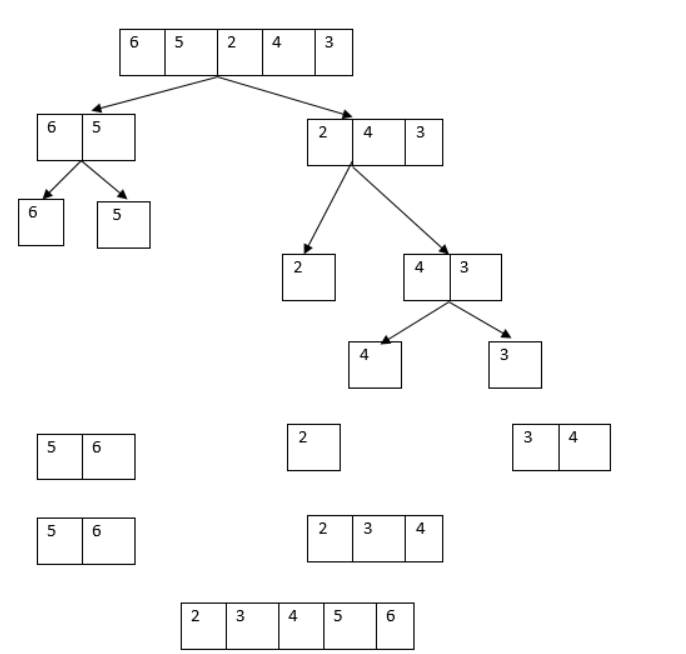     15. Рекурсия в алгоритмах. Хвостовая рекурсия. Организация и эффективность применения. Пример рекурсивного алгоритма. Хвостовая рекурсия — это когда любой рекурсивный вызов является последней операцией перед возвратом из функции. При каждом рекурсивном вызове функции создаётся новый набор её параметров и локальных переменных, который вместе с адресом возврата размещается в стеке, что ограничивает максимальную глубину рекурсии объёмом стека. Если рекурсивный вызов является последней операцией перед выходом из вызывающей функции и результатом вызывающей функции должен стать результат, который вернёт рекурсивный вызов, сохранение контекста уже не имеет значения — ни параметры, ни локальные переменные уже использоваться не будут, а адрес возврата уже находится в стеке. Поэтому в такой ситуации вместо полноценного рекурсивного вызова функции можно просто заменить значения параметров в стеке и передать управление на точку входа. До тех пор, пока исполнение будет идти по этой рекурсивной ветви, будет, фактически, выполняться обычный цикл. Когда рекурсия завершится (то есть исполнение пройдёт по терминальной ветви и достигнет команды возврата из функции) возврат произойдёт сразу в исходную точку, откуда произошёл вызов рекурсивной функции. Таким образом, при любой глубине рекурсии стек переполнен не будет. Пример рекурсивной функции для вычисления факториала, использующей хвостовую рекурсию:  В качестве примера простой рекурсивной функции, которая не является хвостово-рекурсивной и не может быть автоматически преобразована в итеративную, можно привести наиболее очевидный рекурсивный способ вычисления факториала, который обычно приводят в учебниках как простейший пример рекурсивной функции:  В этом примере, несмотря на то, что рекурсивный вызов в тексте функции стоит на последнем месте, автоматической оптимизации рекурсии не получится, так как фактически последней выполняемой операцией является операция умножения на n, а значит условие хвостовой рекурсии не выполняется. Приведённые выше хвостово-рекурсивные варианты вычисления факториала являются модификацией очевидного способа, которая как раз и направлена на перенос операции умножения. Применённый для этого метод, кстати, является одним из типовых способов приведения рекурсии к хвостово-рекурсивному виду. Он заключается в том, что набор локальных данных, который нуждается в сохранении при рекурсивном вызове, переносится в параметры вызова функции. В случае с приведёнными примерами вычисления факториала таким параметром является переменная acc, в которой происходит накопление результата.     16. Полустатические структуры данных – организация очереди, стека, дека. Программирование элементарных операций.    17. Организация линейного списка. Программирование элементарных операций: включение и исключение элементов, проход по списку.    18. Линейный упорядоченный список, на примере построения алфавитно-частотного словаря. Списком называется упорядоченное множество, состоящее из переменного числа элементов, к которым применимы операции включения, исключения. Список, отражающий отношения соседства между элементами, называется линейным. Длина списка равна числу элементов, содержащихся в списке, список нулевой длины называется пустым списком. Частотный словарь — вещь очень простая, слова в нем упорядочены по частоте, с которой они встречаются в анализируемом тексте. или же Частотный словарь, в котором слова с указанием их частоты (встречаемости) расположены по алфавиту.  (на сей раз без комменатриев, this is the way) 19. Двусвязные списки; алгоритм поиска и включения в упорядоченном списке.    20. Динамические структуры – реальные структуры данных. Моделирование кольцевой очереди, кольцевого стека.       21. Деревья. Основные понятия. Двоичные деревья. Пример построения идеально сбалансированного дерева.   Идеально сбалансированное дерево – это дерево, у которого для каждой вершины выполняется требование: число вершин в левом и правом поддеревьях различается не более чем на единицу. Идеально сбалансированное дерево – это дерево, у которого для каждой вершины выполняется требование: число вершин в левом и правом поддеревьях различается не более чем на единицу.22. Основные операции с двоичными деревьями. Способы обхода.  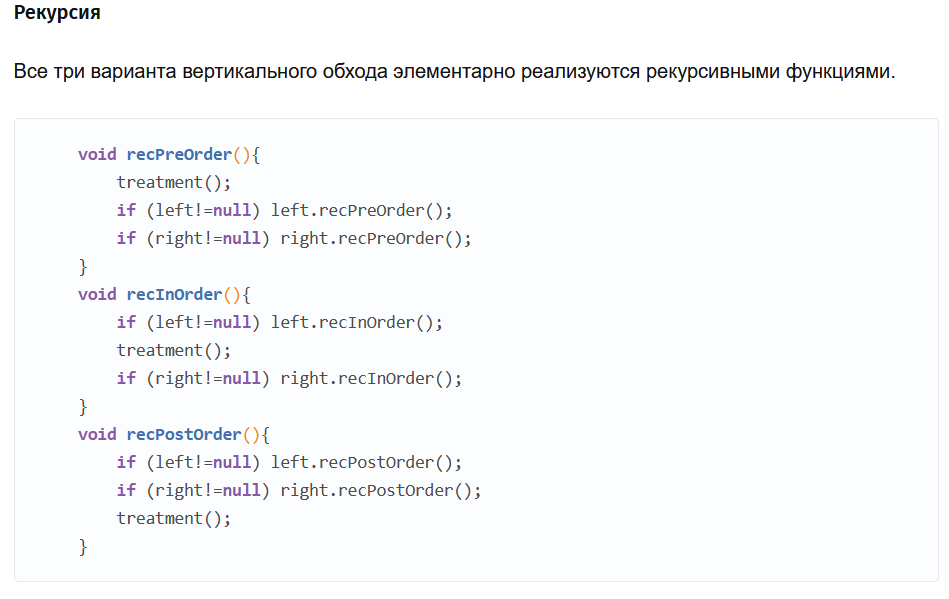  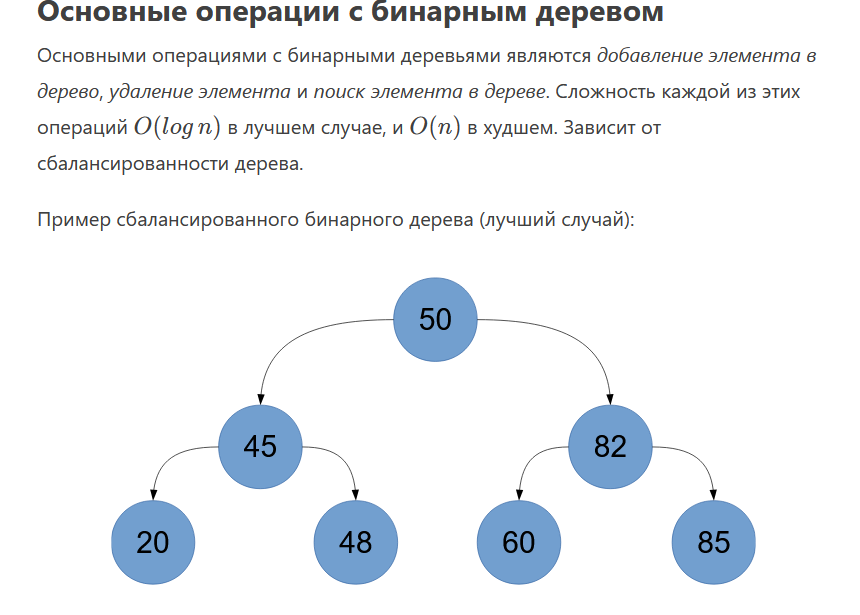      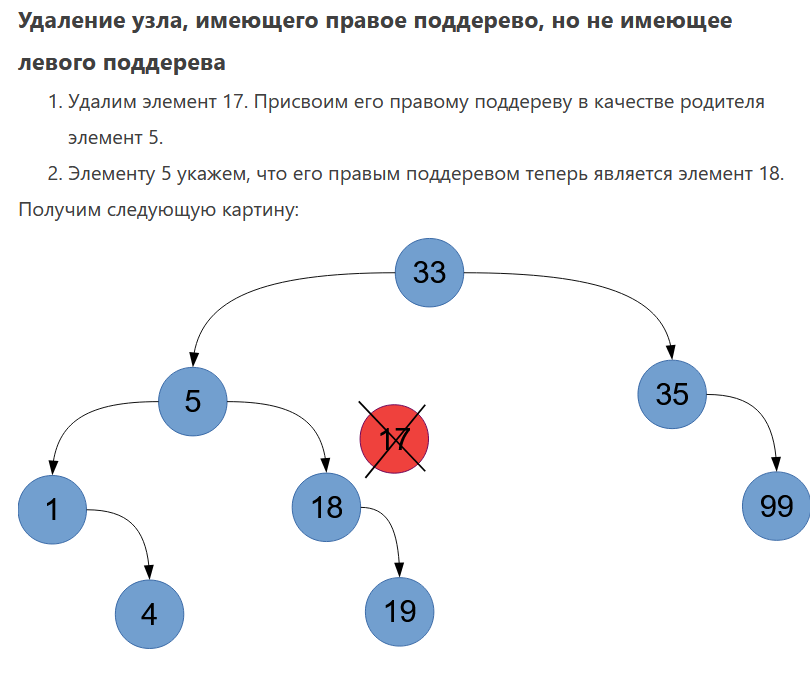 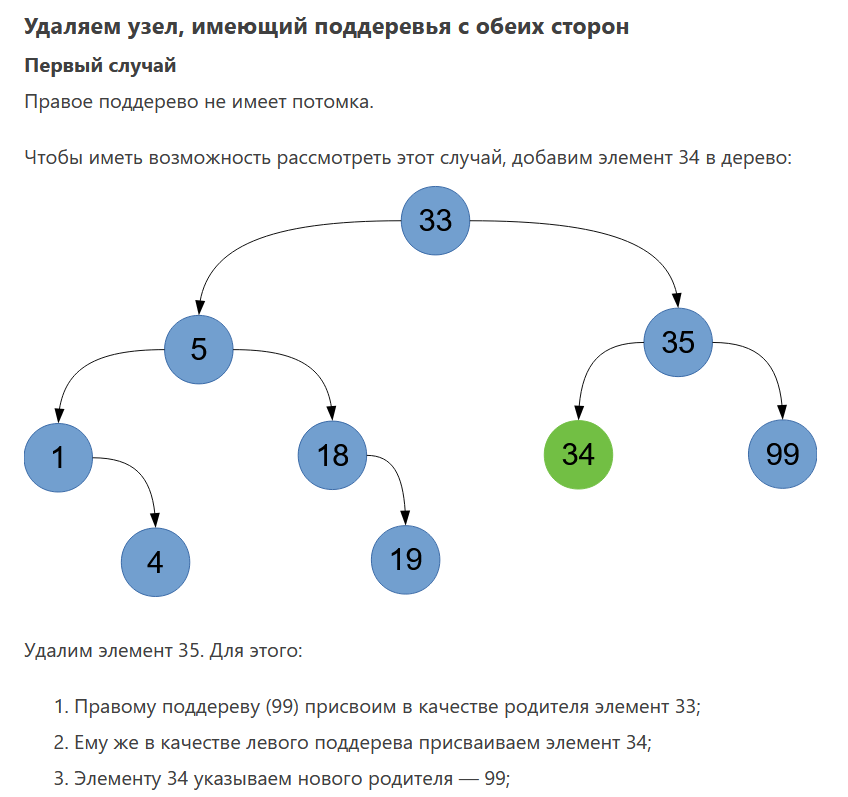 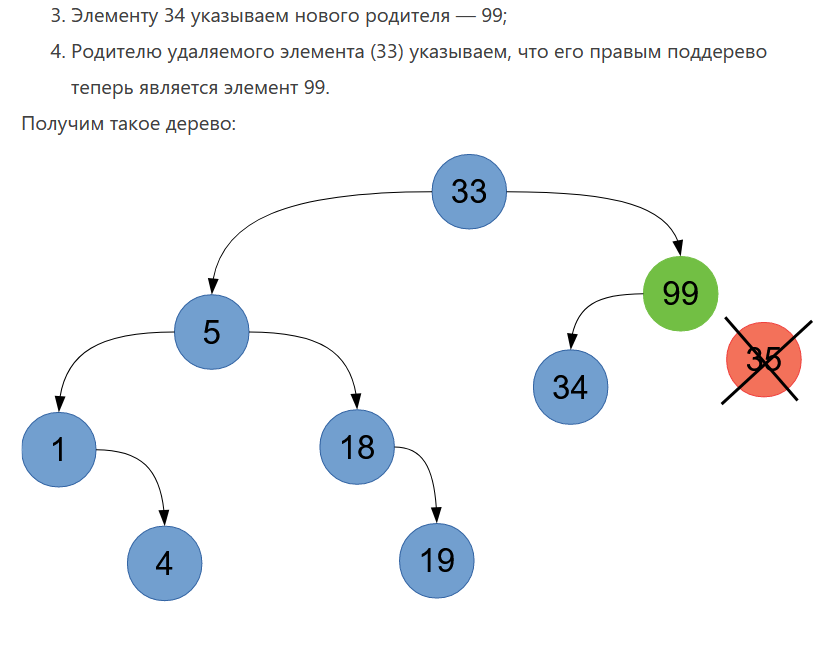 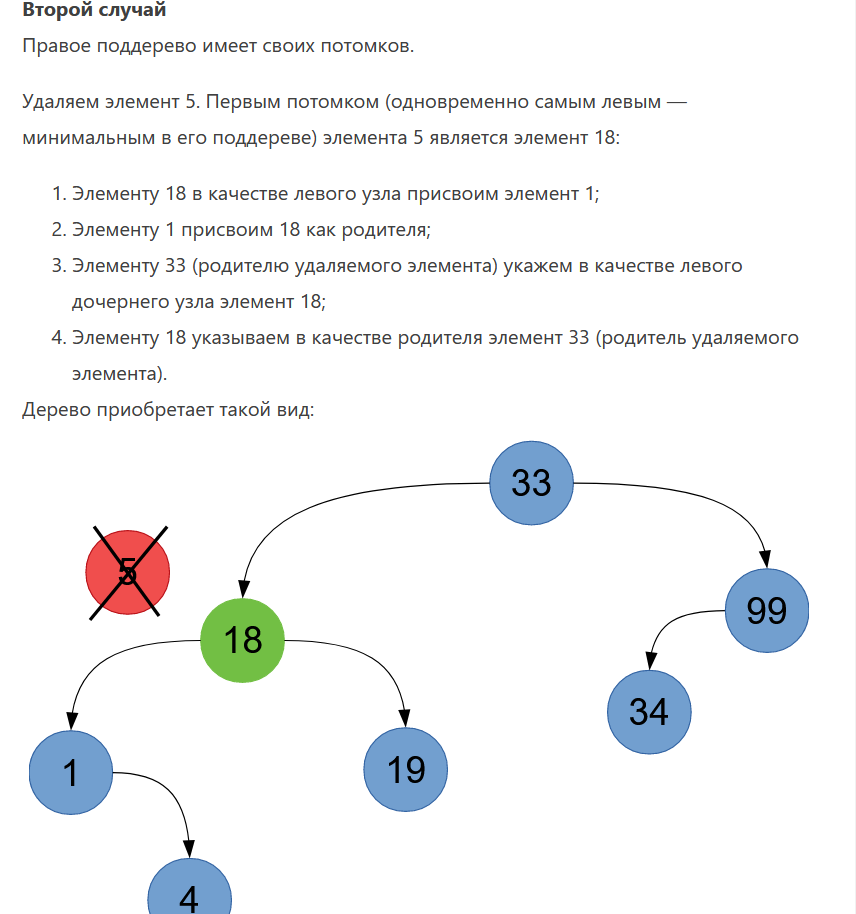  23. Алгоритм поиска по ключу в двоичном дереве. Алгоритм поиска и включения элемента в двоичное дерево (рекурсивный). 24. Алгоритм исключения элемента из двоичного дерева (рекурсивный). 26. Исключение элемента из АВЛ – дерева; балансирующие повороты. (23, 24 и 26 ПРИВЕДЕНЫ ВЫШЕ, если их нет, то таков путь) 25. Сбалансированные АВЛ - деревья. Включение элемента и балансировка дерева (блок – схемы балансирующих поворотов). 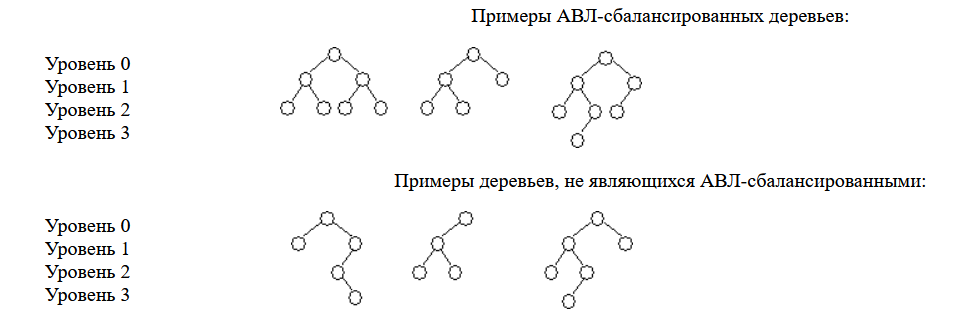 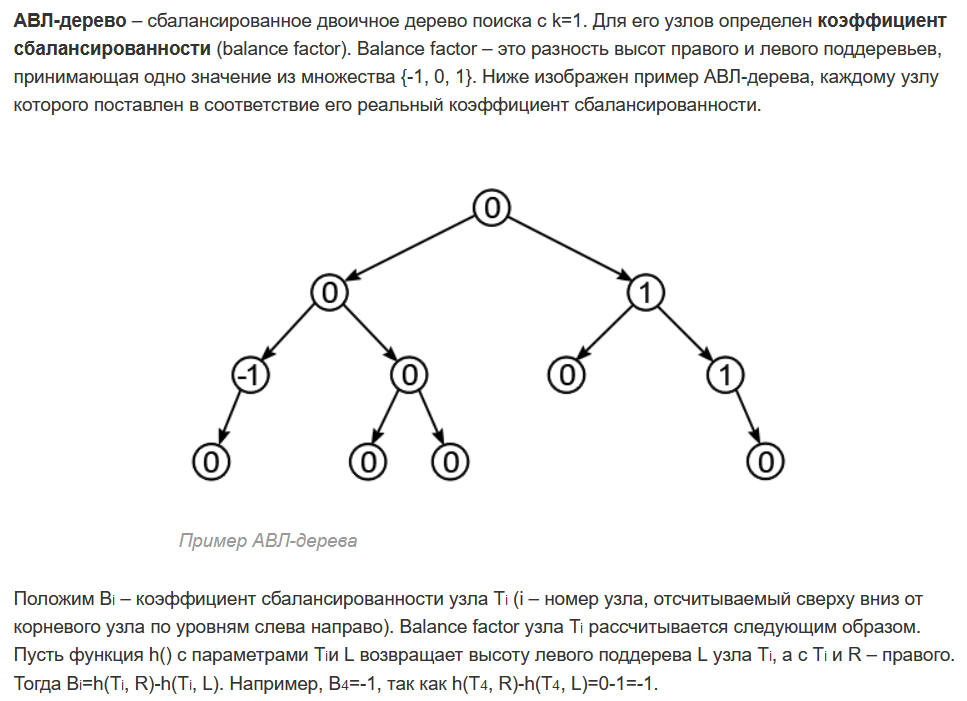  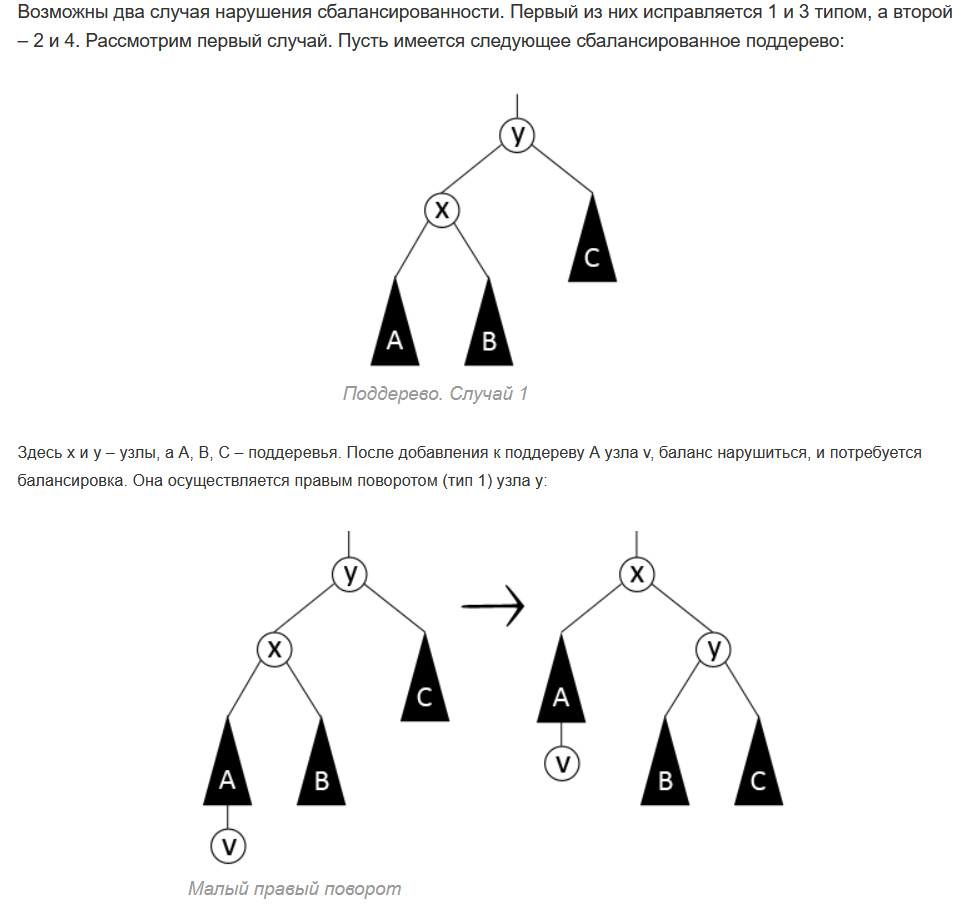 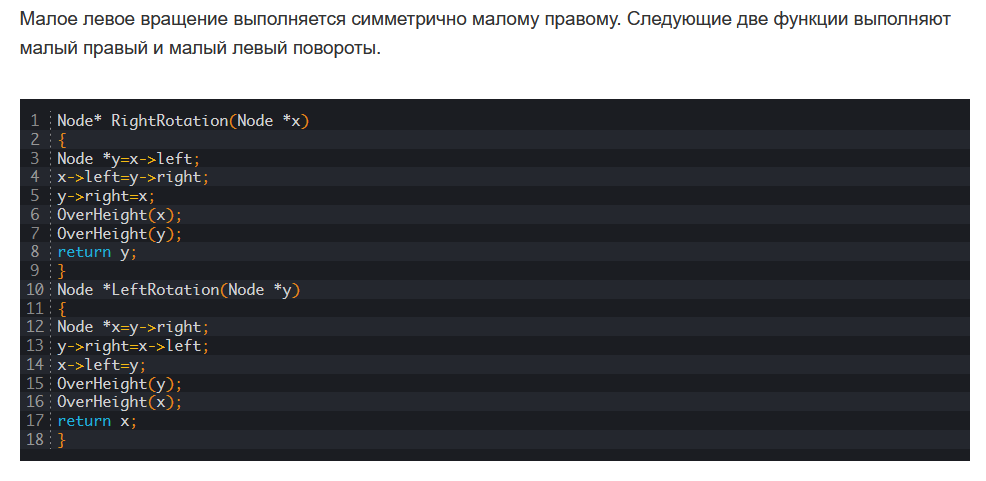   |