Ответы_Ткаченко. Конкурс фпи 4,5 мехфак 1,5 тхп 2,0
 Скачать 151.62 Kb. Скачать 151.62 Kb.
|

|
17. Тупики. Способы предотвращения тупиков. Использование блокировок может привести к различным нежелательным эффектам, таким как бесконечные ожидания и тупики. Тупики возникают как правило из-за применения стратегии устранении бесконечного ожидания «первый вошел – первым обслужился». Пример ситуации тупика приведен на рисунке 37. Есть две транзакции: транзакция Т1, содержащая команды, работающие с элементами данных А и В: LOCK(A); LOCK (B); …; UNLOCK (A); UNLOCK (B) и транзакция Т2: LOCK(B); LOCK (A); …; UNLOCK (B); UNLOCK (A). При этом не имеет значения, для каких процессов требуются элементы данных А и В в транзакциях Т1 и Т2 (команда LOCK – заблокировать элемент данных, команда UNLOCK – разблокировать элемент данных). Транзакция T1 время Транзакция T2 Пример ситуации тупика: LOCK(A) Т1 LOCK(В) LOCK(В) НЕТ! Т2 LOCK(A) НЕТ! Т3 ожидание ожидание Каждая из транзакций ожидает, пока другая разблокирует требуемый для неё элемент. Ожидание будет бесконечным. Ситуация, при которой каждая из множества двух или более транзакций ожидает, когда ей будет предоставлена возможность заблокировать элемент, заблокированный в данный момент времени какой—либо иной транзакцией из рассматриваемого множества, называется тупиком. Способы предотвращения тупиков являются объектом исследования в области теории БД. Предлагаются различные методы разрешения тупиков. 1) Выполняется линейное упорядочивание элементов по какому—либо признаку (например, последовательно перечисляются все элементы, подлежащие блокированию) и вводится системное требование на составление запросов (программ): все запросы должны выполнять блокировки в этом порядке. 2) Вводится системное требование, чтобы в каждом запросе (программе) каждой транзакции все требуемые блокировки запрашивались сразу. Это позволяет СУБД управлять транзакциями без тупиковых ситуаций. 3) Никакие системные требования не вводятся. СУБД просто следит за возникновением тупиковых ситуаций. При обнаружении тупика действие одной из транзакций останавливается, все выполненные ею изменения в БД устраняются, транзакция переводится либо в состояние ожидания, либо полностью аннулируется. При этом все данные об этой транзакции СУБД фиксирует в системных журналах для возможного последующего перезапуска. 18. Понятие расписания совокупности транзакций. Сериализуемое расписание. Расписанием называется упорядоченная последовательность действий, предпринимаемых в процессе выполнения одной или нескольких транзакции. Расписание последовательно, если оно подразумевает выполнение всех действий одной транзакции, а затем всех действий другой транзакции, и т.д. Расписание называется условно-последовательным, если результат его реализации оказывается аналогичным результату реализации последовательного расписания. Сериализация (в программировании) — процесс перевода какой-либо структуры данных в последовательность битов. Обратной к операции сериализации является операция десериализации (структуризации) — восстановление начального состояния структуры данных из битовой последовательности. // К сожалению, нормальную инфу найти не удалось • Расписание называется сериализуемым, если оно эквивалентно по конфликтам серийному 19. Понятие протокола. Двухфазный протокол. Двухфазные транзакции. Типы блокировок. Протокол передачи данных — набор соглашений интерфейса логического уровня, которые определяют обмен данными между различными программами. Эти соглашения задают единообразный способ передачи сообщений и обработки ошибок при взаимодействии программного обеспечения разнесённой в пространстве аппаратуры, соединённой тем или иным интерфейсом. Протокол двухфазной блокировки Важную роль в обеспечении корректной параллельной обработки транзакций играет «протокол двухфазной блокировки» (Two Phase Locking – 2PL). Существует соответствующая теорема, что сериализуемость транзакций заведомо гарантируется, если блокировки, относящиеся к одновременно выполняемым транзакциям, удовлетворяют правилу: "Ни одна блокировка от имени какой-либо транзакции не должна устанавливаться, пока не будет снята ранее установленная блокировка". Это правило известно под названием двухфазовое блокирование. Суть 2PL в том, что нельзя снять однажды наложенную блокировку до тех пор, пока не наложены все блокировки, необходимые транзакции. Таким образом, работа с блокировками в транзакции делится на две фазы: фаза наложения блокировок и фаза снятия. В практических реализациях, как правило, применяется строгий протокол двухфазной блокировки – Strict 2PL. Его особенность в том, что фаза снятия блокировок наступает после фиксации транзакции. Двухфазные транзакции Распределенные системы обычно включают несколько компьютеров - серверов баз данных, называемых узлами. Данные физически распределены между ними. На каждом узле содержится некоторая локальная база данных, содержащая фрагмент данных из общей распределенной базы. В распределенных базах транзакция, выполнение которой заключается в обновлении данных на нескольких узлах сети, называется глобальной или распределенной транзакцией. Внешне выполнение распределенной транзакции выглядит как обработка транзакции к локальной базе данных. Тем не менее распределенная транзакция включает в себя несколько локальных транзакций, каждая из которых завершается двумя путями - фиксируется или прерывается. Распределенная транзакция фиксируется только в том случае, когда зафиксированы все локальные транзакции, ее составляющие. Если хотя бы одна из локальных транзакций была прервана, то должна быть прервана и распределенная транзакция. Как на практике учесть это требование? Для этого в современных СУБД предусмотрен так называемый протокол двухфазовой (или двухфазной) фиксации транзакций (two-phase commit). Название отражает тот факт, что фиксация распределенной транзакции выполняется в две фазы. Фаза 1 начинается, когда при обработке транзакции встретился оператор COMMIT. Сервер распределенной БД (или компонент СУБД, отвечающий за обработку распределенных транзакций) направляет уведомление "подготовиться к фиксации" всем серверам локальных БД, выполняющим распределенную транзакцию. Если все серверы приготовились к фиксации (то есть откликнулись на уведомление и отклик был получен), сервер распределенной БД принимает решение о фиксации. Серверы локальных БД остаются в состоянии готовности и ожидают от него команды "зафиксировать". Если хотя бы один из серверов не откликнулся на уведомление в силу каких-либо причин, будь то аппаратная или программная ошибка, то сервер распределенной БД откатывает локальные транзакции на всех узлах, включая даже те, которые подготовились к фиксации и оповестили его об этом. Фаза 2 - сервер распределенной БД направляет команду "зафиксировать" всем узлам, затронутым транзакцией, и гарантирует, что транзакции на них будут зафиксированы. Если связь с локальной базой данных потеряна в интервал времени между моментом, когда сервер распределенной БД принимает решение о фиксации транзакции, и моментом, когда сервер локальной БД подчиняется его команде, то сервер распределенной БД продолжает попытки завершить транзакцию, пока связь не будет восстановлена. Типы блокировок: Принудительное упорядочение транзакций обеспечивается с помощью механизма блокировок. Суть этого механизма в следующем: если для выполнения некоторой транзакции необходимо, чтобы некоторый объект базы данных (кортеж, набор кортежей, отношение, набор отношений,..) не изменялся непредсказуемо и без ведома этой транзакции, такой объект блокируется. Основными видами блокировок являются:
Применение механизма блокировки приводит к замедлению обработки транзакций, поскольку система вынуждена ожидать пока освободятся данные, захваченные конкурирующей транзакцией. Решить эту проблему можно за счет уменьшения фрагментов данных, захватываемых транзакцией. В зависимости от захватываемых объектов различают несколько уровней блокировки:
20. Стратегия временных отметок, оптимистические стратегии. Оптимистическая стратегия. Основным предположением является то, что любая транзакция T, как правило, работает «одна» и никакая другая транзакция T? не изменяет ни множество чтения, ни множество записи транзакции T до момента ее фиксации. Все конфликты чтения/записи, ограничения целостности проверяются в момент фиксации транзакции T. Транзакция T фиксируется в том и только в том случае, когда от момента ее старта и до момента ее фиксации отсутствовали описанные выше конфликты с любой другой параллельной транзакцией T?. Во всех остальных случаях транзакция T откатывается. При таком протоколе работы транзакция T не блокирует каким-либо образом объекты данных, к которым она обращается. Особенности этого протокола — долгая фиксация (проверки ограничений целостности и наличия конфликтов, перенос данных в базу данных) и быстрая работа при выполнении действий над данными в течение работы транзакции (ничто не блокируется, ничто не проверяется). Такой протокол работает плохо, когда множества чтения и записи коротких и длинных транзакций пересекаются: длинные транзакции фиксируются относительно редко, а для коротких транзакций велик процент откатов по причине разрешения конфликтов только на стадии фиксации. В этом состоит существенный недостаток позднего обнаружения конфликтов. Однако если прикладные задачи построены так, что множества чтения и записи разных транзакций пересекаются редко, то оптимистическая стратегия дает существенный выигрыш в производительности за счет отсутствия проверок взаимодействий с другими транзакциями в процессе работы транзакции.вает дату и время (иногда с точностью до долей секунд). // стратегия временных отметок не найдена 21. Защита БД от отказов. Типы отказов. Архивные копии БД, Журнал БД. Зафиксированные транзакции. Стратегия двухфазной фиксации Защита БД от отказов Восстановление базы данных — это функция СУБД, которая в случае логических и физических сбоев приводит базу данных в актуальное и консистентное состояние. В случае логического отказа или сигнала отката одной транзакции журнал изменений сканируется в обратном направлении, и все записи отменяемой транзакции извлекаются из журнала вплоть до отметки начала транзакции. Согласно извлеченной информации выполняются действия, отменяющие действия транзакции. Этот процесс называется откат (rollback). В случае физического отказа, если ни журнал изменений, ни сама база данных не повреждены, то выполняется процесс прогонки (rollforward). Журнал сканируется в прямом направлении, начиная от предыдущей контрольной точки. Все записи извлекаются из журнала вплоть до конца журнала. Извлеченная из журнала информация вносится в блоки данных внешней памяти, у которых отметка номера изменений меньше, чем записанная в журнале. Если в процессе прогонки снова возникает сбой, то сканирование журнала вновь начнется сначала, но восстановление фактически продолжится с той точки, где оно прервалось. В случае физического отказа, если журнал изменений доступен, но сама база данных повреждена, то должен быть выполнен процесс восстановления базы из резервной копии. После восстановления база будет находиться в состоянии на момент выполнения резервной копии. Для восстановления базы данных на момент отказа необходимо выполнить прогонку всех изменений, используя журнал изменений. В случае физического отказа, если журнал изменений недоступен, но сама база данных не повреждена, восстановление возможно только на момент предыдущей контрольной точки. В случае физического отказа, если повреждены как журнал изменений, так и сама база данных, то восстановление возможно только на момент выполнения резервной копии Журнализация транзакций — функция СУБД, которая сохраняет информацию, необходимую для восстановления базы данных в предыдущее согласованное состояние в случае логических или физических отказов. В простейшем случае журнализация изменений заключается в последовательной записи во внешнюю память всех изменений, выполняемых в базе данных. Записывается следующая информация: Архивная копия – это полная копия БД к моменту начала заполнения журнала (имеется много вариантов более гибкой трактовки смысла архивной копии)
Формируемая таким образом информация называется журнал изменений базы данных. Журнал содержит отметки начала и завершения транзакции, и отметки принятия контрольной точки СУБД с отложенной записью периодически выполняет контрольные точки. Во время выполнения этого процесса все незаписанные данные переносятся на внешнюю память, а в журнал пишется отметка принятия контрольной точки. После этого содержимое журнала, записанное до контрольной точки может быть удалено. Журнал изменений может не записываться непосредственно во внешнюю память, а аккумулироваться в оперативной. В случае подтверждения транзакции СУБД дожидается записи оставшейся части журнала на внешнюю память. Таким образом гарантируется, что все данные, внесённые после сигнала подтверждения, будут перенесены во внешнюю память, не дожидаясь переписи всех измененных блоков из дискового кэша. СУБД дожидается записи оставшейся части журнала так же при выполнении контрольной точки. Как правило, журнал изменений перезаписывается сначала, как только заканчивается пространство внешней памяти, распределенное под него. Это позволяет восстановить базу данных до актуального и согласованного состояния, но только в том случае, если сама база данных не потеряна, пусть даже и не в актуальном состоянии. Однако в некоторых информационных системах восстановление должно быть гарантировано, даже если вся база данных потеряна. В таких системах периодически выполняются резервное копирование базы данных, а журнал изменений разделяется на последовательные отрезки и архивируется. Перед началом резервного копирования выполняется контрольная точка и журнал разделяется на отрезки, записанные до и после начала резервного копирования. По завершении процесса резервного копирования весь журнал изменений записанный до начала резервного копирования удаляется. Таким образом, при наличии резервной копии и всех архивированных журналов изменений, записанных с момента создания резервной копии, база данных может быть восстановлена до актуального состояния, даже если все блоки данных были потеряны. Резервное копирование (англ. backup copy) — процесс создания копии данных на носителе (жёстком диске, дискете и т. д.), предназначенном для восстановления данных в оригинальном или новом месте их расположения в случае их повреждения или разрушения. Стратегия двухфазной фиксации Фиксация транзакции – это действие, обеспечивающее запись на диск изменений в БД, которые были сделаны в процессе выполнения транзакции. Протокол двухфазовой фиксации Т состоит из 2 фаз(этапов): Фаза 1 – подготовка к фиксации глобальной транзакции. Сервер БД направляет уведомления локальным БД для подготовки фиксации транзакций. Если хотя бы один из локальных узлов не откликнулся , то происходит откат всех локальных транзакций. Фаза 2 – фиксация глобальной транзакции. Происходит фиксация всех локальных транзакций. Если произойдет сбой в течение данного этапа, то сервер БД выполнит фиксацию глобальной транзакции вплоть до восстановления соединения. Клиент видит больш БД, кот сост из мн-ва локальных БД 22. Восстановление БД (совпадает многое с вопросом выше) Возможны следующие ситуации, при которых требуется производить восстановление состояния базы данных:
Во всех трех случаях основой восстановления является избыточное хранение данных. Эти избыточные данные хранятся в журнале, содержащем последовательность записей об изменении базы данных. 23. Администрирование БД Непосредственное управление данными во внешней памяти. Эта функция включает обеспечение необходимых структур внешней памяти как для хранения непосредственных данных, входящих в БД, так и для служебных целей, например, для убыстрения доступа к данным в некоторых случаях (обычно для этого используются индексы). В некоторых реализациях СУБД активно используются возможности существующих файловых систем, в других работа производится вплоть до уровня устройств внешней памяти. Но подчеркнем, что в развитых СУБД пользователи в любом случае не обязаны знать, использует ли СУБД файловую систему, а если использует, то как организованы в ней файлы. В частности, СУБД поддерживает собственную систему именования объектов БД (это очень важно, поскольку имена объектов базы данных соответствуют именам объектов предметной области). правление буферами оперативной памяти. СУБД обычно работают с БД значительного размера; по крайней мере этот размер обычно существенно превышает доступный объем оперативной памяти. Понятно, если при обращении к любому элементу данных будет производиться обмен с внешней памятью, то вся система будет работать со скоростью устройства внешней памяти. Управление транзакциями. Транзакция – это последовательность операций над БД, рассматриваемых СУБД как единое целое. Либо транзакция успешно выполняется, и СУБД фиксирует (COMMIT) изменения БД, произведенные ею, во внешней памяти, либо ни одно из этих изменений никак не отражается в состоянии БД. Понятие транзакции необходимо для поддержания логической целостности БД. Журнализация. Одно из основных требований к СУБД – надежное хранение данных во внешней памяти. Под надежностью хранения понимается то, что СУБД должна быть в состоянии восстановить последнее согласованное состояние БД после любого аппаратного или программного сбоя. 24 25. Трехуровневая архитектура БД Трехуровневая архитектура БД – это стандартная структура БД, состоящая из концептуального, внешнего и внутреннего уровней. На концептуальном уровне выполняется концептуальное проектирование БД. Оно включает анализ информационных потребностей пользователей и определение нужных им элементов данных. Результатом этого уровня является концептуальная схема, единое логическое описание всех элементов данных и отношений между ними. Концептуальный уровень – структурный уровень БД, определяющий логическую схему БД. Внешний уровень составляют пользовательские представления данных БД. Каждая пользовательская группа имеет свое представление данных в базе данных. Каждое такое представление имеет ориентированное на пользователя описание элементов данных и отношений между ними. Его можно напрямую вывести из концептуальной схемы. Совокупность всех таких пользовательских представлений данных и есть внешний уровень. Внешний уровень – структурный уровень базы данных, определяющий пользовательские представления данных. Внутренний уровень обеспечивает физический взгляд на БД: дисководы, физические адреса, индексы, указатели и т.д. За этот уровень отвечают проектировщики физической БД. Ни один пользователь не касается этого уровня. Внутренний уровень – структурный уровень БД, определяющий физический вид БД. 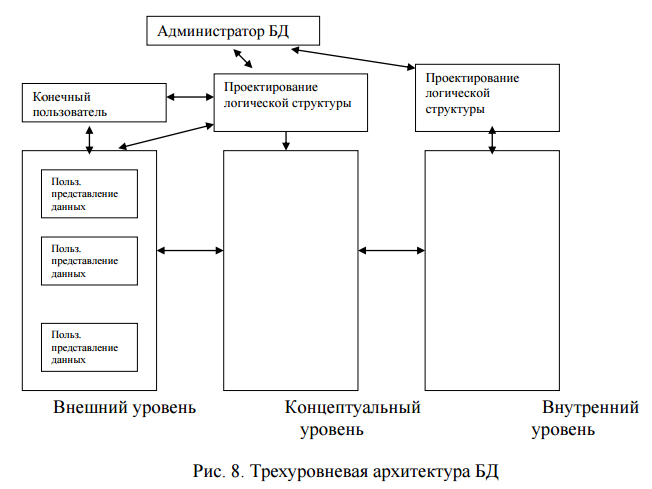 26. Средства для реализации Трехуровневых БД ( не нашел инфы) 27.Инфологический и даталогический уровни моделирования предметной области. Концептуальное (инфологическое) моделирование — построение семантической модели предметной области, то есть информационной модели наиболее высокого уровня абстракции. Такая модель создаётся без ориентации на какую-либо конкретную СУБД и модель данных. Термины «семантическая модель», «концептуальная модель» и «инфологическая модель» являются синонимами. Кроме того, в этом контексте равноправно могут использоваться слова «модель базы данных» и «модель предметной области» (например, «концептуальная модель базы данных» и «концептуальная модель предметной области»), поскольку такая модель является как образом реальности, так и образом проектируемой базы данных для этой реальности. Логическое (даталогическое) проектирование — создание схемы базы данных на основе конкретной модели данных, например, реляционной модели данных. Для реляционной модели данных даталогическая модель — набор схем отношений, обычно с указанием первичных ключей, а также «связей» между отношениями, представляющих собой внешние ключи. Преобразование концептуальной модели в логическую модель, как правило, осуществляется по формальным правилам. Этот этап может быть в значительной степени автоматизирован. На этапе логического проектирования учитывается специфика конкретной модели данных, но может не учитываться специфика конкретной СУБД. 28. Классификация моделей данных Кроме трех рассмотренных уровней абстракции при проектировании БД существует еще один уровень, предшествующий им. Модель этого уровня должна выражать информацию о предметной области в виде, независимом от используемой СУБД. Эти модели называются инфологическими, или семантическими. Инфологические модели данных- отражают в естественной и удобной для разработчиков и других пользователей форме информационно-логический уровень абстрагирования, связанный с фиксацией и описанием объектов предметной области, их свойств и их взаимосвязей. Инфологические модели данных используются на ранних стадиях проектирования для описания структур данных в процессе разработки приложения, а дата-логические модели уже поддерживаются конкретной СУБД. Документальные модели данных- соответствуют представлению о слабоструктурированной информации, ориентированной в основном на свободные форматы документов, текстов на естественном языке. Тезаурусные модели- это модели, которые основаны на принципе организации словарей, содержат определенные языковые конструкции и принципы их взаимодействия в заданной грамматике. Эти модели эффективно используются в системах-переводчиках, особенно многоязыковых переводчиках. Принцип хранения информации в этих системах и подчиняется тезаурусным моделям. Дескрипторные модели- самые простые из документальных моделей, они широко использовались на ранних стадиях использования документальных баз данных. В этих моделях каждому документу соответствовал дескриптор - описатель. Этот дескриптор имел жесткую структуру и описывал документ в соответствии с теми характеристиками, которые требуются для работы с документами в разрабатываемой документальной БД. Например, для БД, содержащей описание патентов, дескриптор содержал название области, к которой относился патент, номер патента, дату выдачи патента и еще ряд ключевых параметров, которые заполнялись для каждого патента. Обработка информации в таких базах данных велась исключительно по дескрипторам, то есть по тем параметрам, которые характеризовали патент, а не по самому тексту патента 29. Тоже самое, немного изменено 30. Инфологическое моделирование. Модель «сущность–связь»: Сущности,классификация и характеристика сущностей. Модель "сущность-связь" Как любая модель, модель "сущность—связь" имеет несколько базовых понятий, которые образуют исходные кирпичики, из которых строятся уже более сложные объекты по заранее определенным правилам. Эта модель в наибольшей степени согласуется с концепцией объектно-ориентированного проектирования, которая в настоящий момент несомненно является базовой для разработки сложных программных систем, поэтому многие понятия вам могут показаться знакомыми, и если это действительно так, то тем проще вам будет освоить технологию проектирования баз данных, основанную на ER-модели. В основе ER-модели лежат следующие базовые понятия:
31. Инфологическое моделирование. Модель «сущность–связь»: Атрибуты, классификация и характеристика атрибутов. Атрибут – поименованная характеристика сущности. Его наименование должно быть уникальным для конкретного типа сущности, но может быть одинаковым для различного типа сущностей (например, ЦВЕТ может быть определен для многих сущностей: СОБАКА, АВТОМОБИЛЬ, ДЫМ и т.д.). Атрибуты используются для определения того, какая информация должна быть собрана о сущности. Примерами атрибутов для сущности АВТОМОБИЛЬ являются ТИП, МАРКА, НОМЕРНОЙ ЗНАК, ЦВЕТ и т.д. Здесь также существует различие между типом и экземпляром. Тип атрибута ЦВЕТ имеет много экземпляров или значений: Красный, Синий, Банановый, Белая ночь и т.д., однако каждому экземпляру сущности присваивается только одно значение атрибута. Абсолютное различие между типами сущностей и атрибутами отсутствует. Атрибут является таковым только в связи с типом сущности. В другом контексте атрибут может выступать как самостоятельная сущность. Например, для автомобильного завода цвет – это только атрибут продукта производства, а для лакокрасочной фабрики цвет – тип сущности. Атрибуты могут быть однозначные и многозначные однозначный атрибут – атрибут,который может принимать единственное значение. многозначный – принимает несколько значений . Например,человек может закончить несколько ВУЗов,иметь несколько телефонных номеров и т.д 32. Инфологическое моделирование. Модель «сущность–связь»: Связи, классификация и характеристика связи. Связь – ассоциирование двух или более сущностей. Если бы назначением базы данных было только хранение отдельных, не связанных между собой данных, то ее структура могла бы быть очень простой. Однако одно из основных требований к организации базы данных – это обеспечение возможности отыскания одних сущностей по значениям других, для чего необходимо установить между ними определенные связи. А так как в реальных базах данных нередко содержатся сотни или даже тысячи сущностей, то теоретически между ними может быть установлено более миллиона связей. Наличие такого множества связей и определяет сложность инфологических моделей. Характеристика связей и язык моделирования При построении инфологических моделей можно использовать язык ER-диаграмм (от англ. Entity-Relationship, т.е. сущность-связь). В них сущности изображаются помеченными прямоугольниками, ассоциации – помеченными ромбами или шестиугольниками, атрибуты – помеченными овалами, а связи между ними – ненаправленными ребрами, над которыми может проставляться степень связи (1 или буква, заменяющая слово "много") и необходимое пояснение. Между двумя сущностям, например, А и В возможны четыре вида связей. Первый тип – связь ОДИН-К-ОДНОМУ (1:1): в каждый момент времени каждому представителю (экземпляру) сущности А соответствует 1 или 0 представителей сущности В: Студент может не "заработать" стипендию, получить обычную или одну из повышенных стипендий. Второй тип – связь ОДИН-КО-МНОГИМ (1:М): одному представителю сущности А соответствуют 0, 1 или несколько представителей сущности В. Квартира может пустовать, в ней может жить один или несколько жильцов. Так как между двумя сущностями возможны связи в обоих направлениях, то существует еще два типа связи МНОГИЕ-К-ОДНОМУ (М:1) и МНОГИЕ-КО-МНОГИМ (М:N). 33. Инфологическое моделирование. Модель «сущность–связь»: Первичные и внешние ключи. Первичный ключ. Каждая сущность обладает хотя бы одним возможным ключом. Один из них принимается за первичный ключ. При выборе первичного ключа следует отдавать предпочтение несоставным ключам или ключам, составленным из минимального числа атрибутов. Нецелесообразно также использовать ключи с длинными текстовыми значениями (предпочтительнее использовать целочисленные атрибуты). Так, для идентификации студента можно использовать либо уникальный номер зачетной книжки, либо набор из фамилии, имени, отчества, номера группы и может быть дополнительных атрибутов, так как не исключено появление в группе двух студентов (а чаще студенток) с одинаковыми фамилиями, именами и отчествами. Плохо также использовать в качестве ключа не номер блюда, а его название, например, " Закуска из плавленых сырков "Дружба" с ветчиной и соленым огурцом" или "Заяц в сметане с картофельными крокетами и салатом из красной капусты". Не допускается, чтобы первичный ключ стержневой сущности (любой атрибут, участвующий в первичном ключе) принимал неопределенное значение. Иначе возникнет противоречивая ситуация: появится не обладающий индивидуальностью, и, следовательно не существующий экземпляр стержневой сущности. По тем же причинам необходимо обеспечить уникальность первичного ключа. Внешние ключи. Если сущность С связывает сущности А и В, то она должна включать внешние ключи, соответствующие первичным ключам сущностей А и В. Если сущность В обозначает сущность А, то она должна включать внешний ключ, соответствующий первичному ключу сущности А. Внешние ключи связывают сущности. Обнаружив связь, ERwin может передать ключ (набор ключевых атрибутов) в область ключей или область данных дочерней сущности. Переданные атрибуты будут внешними ключами. Атрибуты, перемещающиеся в другие сущности, называют мигрирующими. 34. Инфологическое моделирование. Модель «сущность–связь»: ограничение целостности. Целостность (от англ. integrity – нетронутость, неприкосновенность, сохранность, целостность) – понимается как правильность данных в любой момент времени. Но эта цель может быть достигнута лишь в определенных пределах: СУБД не может контролировать правильность каждого отдельного значения, вводимого в базу данных (хотя каждое значение можно проверить на правдоподобность). Например, нельзя обнаружить, что вводимое значение 5 (представляющее номер дня недели) в действительности должно быть равно 3. С другой стороны, значение 9 явно будет ошибочным и СУБД должна его отвергнуть. Однако для этого ей следует сообщить, что номера дней недели должны принадлежать набору (1,2,3,4,5,6,7). Поддержание целостности базы данных может рассматриваться как защита данных от неверных изменений или разрушений (не путать с незаконными изменениями и разрушениями, являющимися проблемой безопасности). Современные СУБД имеют ряд средств для обеспечения поддержания целостности (так же, как и средств обеспечения поддержания безопасности). Выделяют три группы правил целостности: Целостность по сущностям. Целостность по ссылкам. Целостность, определяемая пользователем. Не допускается, чтобы какой-либо атрибут, участвующий в первичном ключе, принимал неопределенное значение. Значение внешнего ключа должно либо: быть равным значению первичного ключа цели; быть полностью неопределенным, т.е. каждое значение атрибута, участвующего во внешнем ключе должно быть неопределенным. Для любой конкретной базы данных существует ряд дополнительных специфических правил, которые относятся к ней одной и определяются разработчиком. Чаще всего контролируется: уникальность тех или иных атрибутов, диапазон значений (экзаменационная оценка от 2 до 5), принадлежность набору значений (пол "М" или "Ж"). 35. Документальные,тезаурусные и дескрипторные модели данных. Документальные - Связаны прежде всего со стандартным общим языком разметки документов, который позволяет организовывать информацию, содержащуюся в документах, и представлять ее в некотором стандартном виде. Тезаурусные модели. Основаны на принципе организации словарей, описывающих языковые выражения и взаимодействия между ними. Под тезаурусом понимается иерархическая словарь понятий и отношений между ними, что позволяет представлять исходный текст документа в виде системы этих понятий. В качестве понятий в тезаурусе встречаются именные и глагольные группы, существительные, прилагательные и отдельные глаголы. Дескрипторные модели. Каждому документу соответствует дескриптор или описатель, который имеет жесткую структуру и описывает документ в соответствии с теми характеристиками, которые требуются для работы с документами. Обработка информации ведется исключительно по дескриптору документа, а не по его содержанию. 36. Фактографические модели данных. Теоретико–графовые модели: Иерархическая модель данных: структура данных, ограничения целостности, типичные операции манипулирования данными. Достоинства и недостатки иерархической модели данных. Организация данных в СУБД иерархического типа определяется в терминах: элемент, агрегат, запись (группа), групповое отношение, база данных. Атрибут (элемент данных)- наименьшая единица структуры данных. Обычно каждому элементу при описании базы данных присваивается уникальное имя. По этому имени к нему обращаются при обработке. Элемент данных также часто называют полем. Запись - именованная совокупность атрибутов. Использование записей позволяет за одно обращение к базе получить некоторую логически связанную совокупность данных. Именно записи изменяются, добавляются и удаляются. Тип записи определяется составом ее атрибутов. Экземпляр записи - конкретная запись с конкретным значением элементов Групповое отношение - иерархическое отношение между записями двух типов. Родительская запись (владелец группового отношения) называется исходной записью, а дочерние записи (члены группового отношения) - подчиненными. Иерархическая база данных может хранить только такие древовидные структуры. Корневая запись каждого дерева обязательно должна содержать ключ с уникальным значением. Ключи некорневых записей должны иметь уникальное значение только в рамках группового отношения. Каждая запись идентифицируется полным сцепленным ключом, под которым понимается совокупность ключей всех записей от корневой по иерархическому пути. При графическом изображении групповые отношения изображают дугами ориентированного графа, а типы записей - вершинами (диаграмма Бахмана). Для групповых отношений в иерархической модели обеспечивается автоматический режим включения и фиксированное членство. Это означает, что для запоминания любой некорневой записи в БД должна существовать ее родительская запись (подробнее о режимах включения и исключения записей сказано в параграфе о сетевой модели. При удалении родительской записи автоматически удаляются все подчиненные. Операции над данными, определенные в иерархической модели: ДОБАВИТЬ в базу данных новую запись. Для корневой записи обязательно формирование значения ключа. ИЗМЕНИТЬ значение данных предварительно извлеченной записи. Ключевые данные не должны подвергаться изменениям. УДАЛИТЬ некоторую запись и все подчиненные ей записи. ИЗВЛЕЧЬ:извлечь корневую запись по ключевому значению, допускается также последовательный просмотр корневых записей извлечь следующую запись (следующая запись извлекается в порядке левостороннего обхода дерева) В операции ИЗВЛЕЧЬ допускается задание условий выборки (например, извлечь сотрудников с окладом более 1 тысячи руб.) Как видим, все операции изменения применяются только к одной "текущей" записи (которая предварительно извлечена из базы данных). Такой подход к манипулированию данных получил название "навигационного". Ограничения целостности.Поддерживается только целостность связей между владельцами и членами группового отношения (никакой потомок не может существовать без предка). Как уже отмечалось, не обеспечивается автоматическое поддержание соответствия парных записей, входящих в разлные иерархии. |