реферат на тему Разработка алгоритмов для технологий туманных вычислений. Контрольная работа по дисциплине Технологии цифровой обработки информации
 Скачать 1.87 Mb. Скачать 1.87 Mb.
|

 ИНСТИТУТ ИНФОКОММУНИКАЦИОННЫХ СИСТЕМ И ТЕХНОЛОГИЙ Кафедра информационных технологий и управляющих систем Контрольная работа по дисциплине «Технологии цифровой обработки информации» На тему: Разработка алгоритмов для технологий туманных вычислений Вариант 14 Выполнил: студент группы ИСТ-ИТ-21 Муратов Н.К. Проверил: к.т.н. доцент Аббасова Т.С. Королев 2023 Оглавление Введение………………………………………………………………...3 Понятие о туманных вычислениях…………………………………4 Преимущества и прогнозы…………………………………………...7 Постановка задачи процесса…………………………………………9 Онтологический подход……………………………………………..10 Заключение……………………………………………………………12 Список литературы…………………………………………………..13 Введение Мобильные устройства в настоящее время занимают преобладающую позицию по количеству и распространенности среди прочих вычислительных устройств. В среднем производительность мобильных устройств «отстает» от настольных ПЭВМ примерно на 10-15 лет, однако их количество уже сейчас заметно выше. Желание использовать вычислительные возможности мобильных устройств привело к появлению технологий «туманных вычислений» (fog computing) [1]. Термин был введен сравнительно недавно компанией Cisco Systems, и определяет технологии использования сети мобильных устройств для решения вычислительно сложных задач. «Туманные вычисления» являются логическим продолжением облачных вычислений и развитием инфокоммуникационных технологий, сотовых сетей новых поколений (5G) и «интернета вещей» (IoT – «Internet of Things»). «Туманная» вычислительная сеть состоит из множества устройств с невысокой производительностью, но объединённых в единый инфокоммуникационный ресурс. К таким устройствам относятся мобильные вычислительные устройства (смартфоны, планшетные компьютеры, «умные» часы и браслеты), бортовые ЭВМ транспортных средств, «умная» бытовая техника, камеры, датчики и многое другое. Современные высокопроизводительные системы обработки данных условно можно разделить на три больших группы: суперкомпьютеры, выполняющие до 18 10 оп/с; центры обработки данных таких компаний как Google, Amazon – до 19 20 10 10 − оп/с; криптомайнинг: 23 24 10 10 − оп/с. Технология туманных вычислений позволяет использовать вычислительные возможности объединенных в сеть мобильных устройств. Наиболее распространенными мобильными устройствами, пригодными для использования в туманных вычислениях, являются мобильные абонентские устройства (далее – МАУ) под управлением операционных систем (ОС) Android, iOS и других. Актуальность исследования способов построения инфраструктуры для туманных вычислений подтверждается наличием поручения от администрации президента РФ Минкомсвязи, Минпромторгу, «Ростелекому» и Агентству стратегических инициатив об исследовании данной технологии с точки зрения ее практической реализации. Постановка задачи. К настоящему времени парадигма «облачных» вычислений была расширена до границ сети и получила название «туманных» вычислений. Одной из отличительных особенностей данной концепции является возможность динамического переноса части вычислительной нагрузки из «облачного» слоя в «туманный» и обратно. Это обеспечивает снижение нагрузки на коммуникационную инфраструктуру сети, что, в свою очередь, позволяет производить вычисления с более высокой скоростью [2 - 4]. Результаты исследования Туманные вычисления — это технология, благодаря которой хранение и обработка данных происходят в локальной сети между конечным устройством и ЦОД. «Туман», в отличие от «облака», находится ближе к пользователям. Это децентрализованная система, которая фильтрует информацию, поступающую в дата-центр. Туманные вычисления призваны расширить облачные функции хранения, вычисления и сетевого взаимодействия. Концепция предполагает обработку данных на конечных устройствах сети (компьютерах, мобильных устройствах, датчиках, смарт-узлах и т.п.), а не в облаке, решая таким образом основные проблемы, возникающие при организации интернета вещей. Термин Fog Computing («туманные вычисления») был введен в оборот вице-президентом компании Cisco Флавио Бономи (Flavio Bonomi) в 2011 году. Он предложил концепцию Fog Computing по аналогии с «облачными вычислениями» (Cloud Computing), как расширение «облака» до границ сети. Технологически, концепция Fog Computing тесно связана с распределёнными (облачными) дата-центрами, в которых серверы дата-центров могут располагаться во многих местоположениях, вплоть до границы сети. Дата-центры могут быть небольшими (контейнерного, модульного или мобильного исполнения), являясь фактически «выносами» крупных дата-центров. Таким образом, отличительная черта Fog Computing - приближенность к конечным пользователям и поддержка их мобильности. Развитие интернета вещей (IoT, Internet of Things) потребовало поддержки мобильности устройств IoT для различных местоположений с геолокацией и с небольшой задержкой на обработку данных. Поэтому была предложена новая платформа для удовлетворения таких требований, которая и получила название Fog computing – «туманные вычисления». Её основной особенностью является обработка данных в непосредственной близости от источников их получения, без необходимости их передачи в крупные дата-центры только для того, чтобы их там обработать и передать назад результаты. Таким образом, становится ясным происхождение термина «туманные вычисления»: когда густое облако опускается до поверхности земли (на границу сети), мы видим туман. Типовое применение Fog Computing показано на рисунке 1. 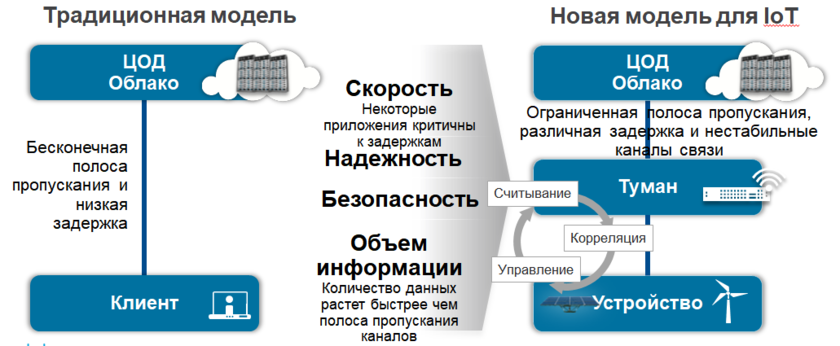 Рисунок 1 — Распределенное вычисления и большие данные Основные архитектурные отличия Fog от Cloud: Обеспечение качества услуг (QoS, Quality of Service), что требует динамической адаптации приложений к состоянию сети. Отслеживание местоположения (Location Awareness) для того, чтобы поддерживать стабильность работы приложения в условиях мобильности терминала. Отслеживание контекстной информации (Context Awareness), т.е. способность обнаруживать наличие доступных ресурсов поблизости, чтобы задействовать их в работе приложения, с возможностью горизонтального взаимодействия. В архитектуре Fog сетевые узлы (Fog Sites), расположенные ближе к облачным дата-центрам, обладают большей вычислительной мощностью и бóльшим объемом данных в системах хранения. Сетевые узлы, расположенные ближе к сенсорам интернета вещей и мобильным устройствам, обладают большей интерактивностью и быстрым откликом. Отличительной особенностью Fog является то, что в качестве сетевого узла могут выступать устройства пользователя, такие как персональные компьютеры, домашние шлюзы (рисунок 2), телеприставки и мобильные устройства. 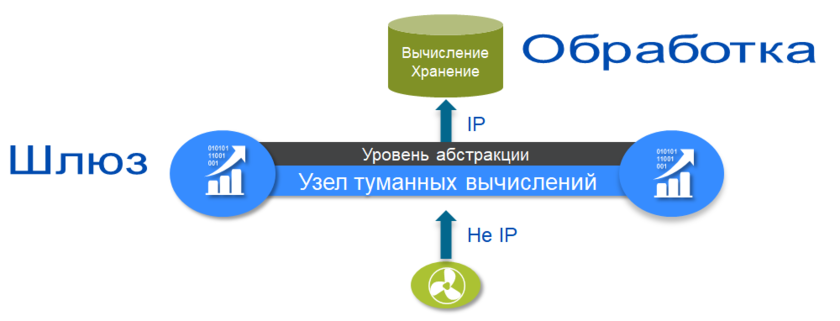 Рисунок 2 – Типовое применение Fog Computing Чтобы устройство пользователя могло работать как узел сети Fog, пользователь должен дать оператору связи соответствующее разрешение на использование вычислительной мощности своего гаджета в фоновом режиме, в обмен на различные льготы со стороны оператора. Преимущества и прогнозыFog Computing – новая ступень развития облачных вычислений, которая снижает задержки, возникающие при передаче данных в центральное облако и обеспечивает новые возможности создания интеллектуальных устройств интернета вещей[7]. Преимуществом туманных вычислений является снижение объема данных, передаваемых в облако, что уменьшает требования к пропускной способности сети, увеличивает скорость обработки данных и снижает задержки в принятии решений. Туманные вычисления решают ряд самых распространенных проблем, среди которых: высокая задержка в сети; трудности, связанные с подвижностью оконечных точек; потеря связи; высокая стоимость полосы пропускания; непредвиденные сетевые заторы; большая географическая распределенность систем и клиентов. Платформы для туманных вычислений показаны на рисунке 3. 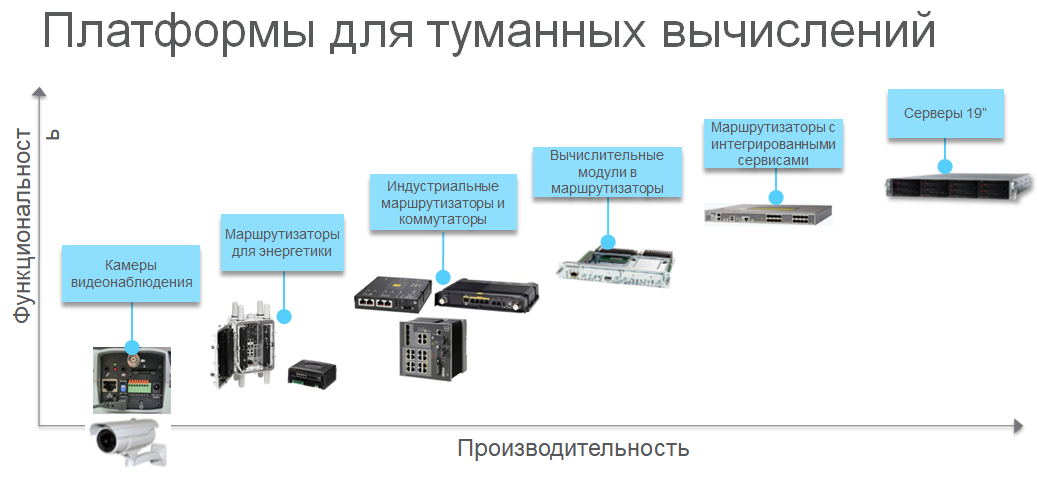 Рисунок 3 — Платформы для туманных вычислений В архитектуре Fog сетевые узлы (Fog Sites), расположенные ближе к облачным дата-центрам, обладают большей вычислительной мощностью и бóльшим объемом данных в системах хранения. Сетевые узлы, расположенные ближе к сенсорам интернета вещей и мобильным устройствам, обладают большей интерактивностью и быстрым откликом. Отличительной особенностью Fog является то, что в качестве сетевого узла могут выступать устройства пользователя, такие как персональные компьютеры, домашние шлюзы, телеприставки и мобильные устройства. Чтобы устройство пользователя могло работать как узел сети Fog, пользователь должен дать оператору связи соответствующее разрешение на использование вычислительной мощности своего гаджета в фоновом режиме, в обмен на различные льготы со стороны оператора. Постановка задачи переноса вычислительной нагрузки РПP’ туманного слоя, в то время, как вычислительные задачи подграфа G”продолжает исполняться на сегменте сети P”показано на рисунке 4. 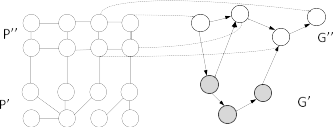 Рисунок 4 — Распределение вычислительных подзадач для модели «разгрузки» устройств Полная загрузка j-го вычислительного устройства описывается следующей формулой: Lj Lpj( A) Ldistj( A, Flow_ in, Flow_ out) Ltrj( A) (1) где Lp(A)–загрузка узла,порождаемаяпереносомвычислительной подзадачи на узел; Ldist( A, Flow_ in, Flow_ out) – загрузка узла, порождаемая обменом информации между подграфами G’иG’’; Ltr(A,Flow_in,Flow_out)– загрузка узла, порождаемая передачей информации через узел. Более подробно с данной формальной постановкой задачи переноса вычислительной нагрузки и методом ее решения можно ознакомиться в работе [Мельник, 2019]. Предложенная модель учитывает особенности «туманных» сред, а именно наличие транзиторных участков сети и географическую распределенность вычислительных узлов. Поэтому далее будем использовать данную математическую модель. Характеристика для туманных вычислений представлена в таблице 1. Таблица 1 —- Таблица для туманных вычислений 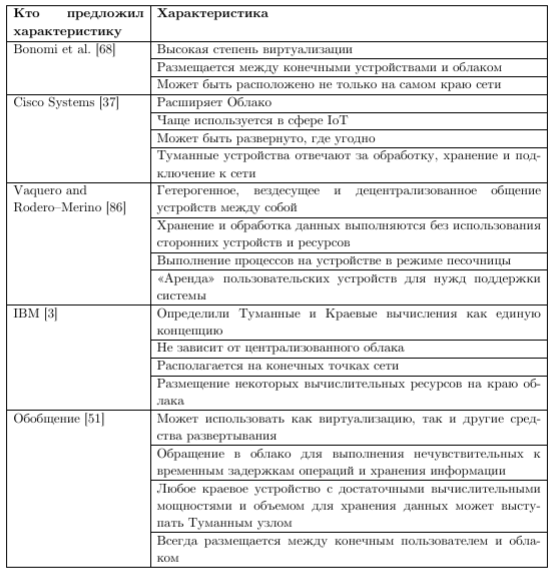 Онтологический подход к формированию ограничений в задачи переноса вычислительной нагрузкиМетод решения задачи переноса вычислительной нагрузки, предложенный в работе [5] является универсальным для любых алгоритмов, используемых в распределенных системах. Однако, он носит итерационный характер, и в наихудшем случае его исполнения, учитывая огромное количество узлов «туманного» слоя, невозможно предсказать время его работы. Такой исход является неудовлетворительным для случая функционирования РСАПР, ввиду соблюдения критерия быстродействия. В связи с этим, авторы предлагают метод, позволяющий учитывать специфику структур параллельных алгоритмов, тем самым, сократить количество потенциальных узлов для размещения вычислительной нагрузки. В основе данного метода лежит модель онтологии, позволяющая формально описать знания о структурах параллельных популяционных алгоритмах и способах их разбиения. Наряду с информацией о ресурсах потенциальных для размещения узлов происходит усечение множества узлов-кандидатов для переноса вычислительной нагрузки. Концепция предложенного метода изображена на рисунке. 5. 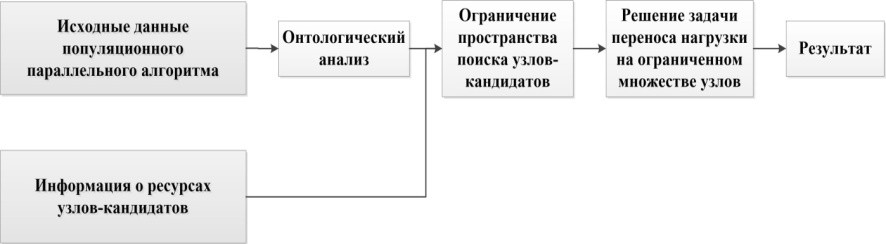 Рисунок 5 — Концепция метода формирования ограничений в задаче переноса вычислительной нагрузки Идея формирования ограничений на множество узлов-кандидатов для переноса вычислительной нагрузки заключается в проведении процедуры онтологического анализа и использовании сведений об узлах-кандидатах для переноса вычислительной нагрузки. К сведениям о ресурсах узлов- кандидатов относятся загруженность узла, его производительность, удаленность от узла-лидера, находящегося в «облаке» и отвечающего за перенос вычислительной нагрузки. Согласно предложенному методу, исходные данные популяционного параллельного алгоритма, позволяющие учесть его специфику информационных обменов, происходящих на уровне процессов, могу быть описаны в модели онтологии. Для реализации предложенного онтологического подхода к формированию ограничений в задаче переноса вычислительной нагрузки необходимо принять следующие допущения: каждый узел «туманного» слоя обладает информацией о структуре используемого алгоритма; множество узлов «туманного» слоя достаточно большое, но ограниченное; существует конечное множество способов разбиения параллельных алгоритмов, используемых для решения NP-сложной задачи в РС и оно может быть описано в видео онтологии. Заключение В работе предложен метод поддержки функционирования распределенных САПР в среде «туманных» вычислений. Рассмотрены формальные постановки задачи переноса вычислительной нагрузки. Обозначены их недостатки в рамках функционирования РСАПР в «туманной» среде с учетом критерия быстродействия. Проведенный анализ популяционных алгоритмов и моделей их распараллеливания выявил наличие характерных особенностей, заключающихся в объемах и частоте информационных обменов между процессами, присущие каждой модели. Разработана модель онтологии, содержащая формализованные знания о структуре рассмотренных алгоритмов. На основании этих знаний, узлы, потенциально подходящие для размещения с точки зрения имеющихся ресурсов, но, не отвечающие требованиям специфики информационных обменов между процессами, не рассматриваются в качестве кандидатов для размещения вычислительной нагрузки. Таким образом, множество узлов для проведения процедуры моделирования размещения сокращается. Соответственно, сокращается общее время решения задачи переноса вычислительной нагрузки в РСАПР. Список использованной литературы Гаврилова Т. А., Кудрявцев Д. В., Муромцев Д. И. Инженерия знаний. Модели и методы: Учебник. — СПб.: Издательство «Лань», 2016. Глушань В. М., Лаврик П.В. Распределенные САПР. Архитектура и возможности. – Старый Оскол: ТНТ, 2015. Добров Б.В., Иванов В.В., Лукашевич Н.В., Соловьев В.Д. Онтологии и тезаурусы: модели, инструменты, приложения: учеб. пособие. – М.: ИнтернетУниверситет Информационных Технологий; БИНОМ. Лаборатория знаний, 2013. Загорулько Ю.А., Загорулько Г.Б., Боровикова О.И. Технология создания тематических интеллектуальных научных интернет- ресурсов, бази-рующаяся на онтологии // Программная инженерия. – М.: Новые технологии, 2016, № 2. Каляев И.А., Левин И.И., Семерников Е.А., Шмойлов В.И. Реконфигурируемые мультиконвейерные вычислительные структуры. –Ростов-на-Дону: ЮНЦ РАН, 2008. |