Лекции и практики (1). Курс лекций и материалы для практических занятий
 Скачать 1.01 Mb. Скачать 1.01 Mb.
|

Лекция 11. ОПТИМИЗАЦИЯ РЕЛЯЦИОННЫХ ЗАПРОСОВВ оптимизацию реляционных запросов входят два различных аспекта. Во-первых, это внутренняя задача СУБД, которая заключается в определении наиболее оптимального (эффективного) способа выполнения реляционных за- просов. Во-вторых, это задача программиста (или квалифицированного пользо- вателя): она заключается в написании таких реляционных запросов, для кото- рых СУБД могла бы использовать более эффективные способы нахождения данных. Сначала рассмотрим первый аспект. Этапы оптимизации запросов в реляционных СУБДЯзык SQL является декларативным языком. В его командах отсутствует информация о том, как выполнить запрос, какие методы доступа к данным ис- пользовать. А почти каждая команда SQL из подмножества языка манипулиро- вания данными (DML) может быть выполнена разными способами. Рассмотрим следующий запрос: Пример 8.1. Список программистов 4-го отдела с «чистой» зарплатой не менее 40000 рублей («чистой» называется зарплата после уплаты подоходного налога, в настоящее время – 13%). SELECT * FROM Emp WHERE depNo=4 AND post LIKE 'программист%' AND salary*0.87>=40000; В этом запросе к таблице Emp (Сотрудники) указаны условия на поля depNo (Номер отдела), post (Должность) и salary (Зарплата). Если по этим полям есть индексы, то способы выполнения этого запроса могут быть такими: Найти по индексу INDEX(depNo) записи, удовлетворяющие первому усло- вию, и проверить для найденных записей второе условие. Найти по индексу INDEX(post) записи, удовлетворяющие второму условию, и проверить для найденных записей первое условие. Последовательно считать все записи таблицы Emp и проверить для каждой записи оба условия. Индексом по полю salary система воспользоваться не может, т.к. это поле нахо- дится внутри выражения. Цель СУБД – выполнить запрос, причём сделать это как можно более эф- фективным способом. Итак, под оптимизацией понимается построение квази- оптимального процедурного плана выполнения декларативного запроса. Примечание: квазиоптимальным план является потому, что система не гарантирует, что она для любого запроса выберет оптимальный план. Для гарантированного выбора опти- мального плана необходимо рассмотреть все возможные планы и сравнить их, а это может потребовать больше времени, чем выполнение самого запроса. Поэтому СУБД выбирает и анализирует лишь несколько планов выполнения каждого запроса, и среди них может не оказаться оптимального плана. План выполнения запроса состоит из последовательности шагов, каж- дый из которых либо физически извлекает данные из памяти, либо делает под- готовительную работу. Построением этого плана занимается оптимизатор – специальная компонента СУБД. 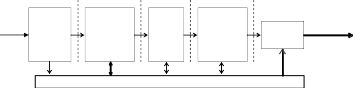 Обработка запроса, поступившего в РСУБД и представленного на декла- ративном языке запросов, состоит из этапов (фаз), представленных на рис. 8.1. Обработка запроса, поступившего в РСУБД и представленного на декла- ративном языке запросов, состоит из этапов (фаз), представленных на рис. 8.1. Рис. 8.1. Последовательность выполнения запросов в реляционных СУБД На первой фазе запрос, представленный на языке запросов, подвергается лексическому и синтаксическому анализу. Лексический анализатор разбивает запрос на лексические единицы – лексемы (наименования полей и таблиц, кон- станты, знаки операций и т.д.). Синтаксический анализатор проверяет синтак- сическую правильность запроса. В результате вырабатывается внутреннее представление запроса. Оно отражает структуру запроса и содержит информа- цию, которая характеризует объекты базы данных, упомянутые в запросе (таб- лицы, поля, константы). Информация об объектах базы данных выбирается из словаря-справочника данных. Внутреннее представление запроса используется и преобразуется на следующих стадиях обработки запроса. На второй фазе запрос в своём внутреннем представлении подвергается логической оптимизации. При этом могут применяться различные преобразова- ния, "улучшающие" начальное представление запроса. Среди этих преобразо- ваний могут быть эквивалентные преобразования (см. раздел 8.2). После прове- дения эквивалентных преобразований получается внутреннее представление, семантически эквивалентное начальному запросу. Преобразования могут также использовать информацию об ограничениях целостности, существующих в БД. Такие преобразования являются семантиче-скими, т.е. они основаны на семантике (смысле) предметной области. В этом случае получаемое представление не является семантически эквивалентным начальному запросу. Но система гарантирует, что результат выполнения преоб- разованного запроса совпадает с результатом запроса в начальной форме при соблюдении ограничений целостности, существующих в базе данных. Напри- мер, если для таблицы Emp определено такое ограничение целостности: CHECK (salary>9500 AND salary<80000), то система к запросу из примера 8.1 могла бы добавить эти условия в часть WHERE, чтобы иметь возможность использовать индекс по полю salary. В любом случае после выполнения второй фазы обработки запроса его внутреннее представление остается непроцедурным, хотя и является в некото- ром смысле более эффективным, чем начальное. Это означает, что по этому представлению система сможет построить более эффективный план. Третья фаза обработки запроса состоит в выборе альтернативных проце- дурных планов выполнения данного запроса в соответствии с его внутренним представлением, полученным на второй фазе. Оптимизатор выбирает методы доступа, последовательность соединений и методы соединений для генерации эффективного плана выполнения запроса. Информация о существующих путях доступа к данным берётся из словаря-справочника данных. Единственный путь доступа, который возможен в любом случае, – это последовательное чтение (FULL). Возможность использования других путей доступа зависит от способов размещения данных в памяти (например, кластеризация или хеширование дан- ных), от наличия индексов и формулировки самого запроса. Также на третьем этапе для каждого из выбранных планов оценивается предполагаемая стоимость выполнения запроса по этому плану. При оценках используется либо доступная оптимизатору статистическая информация о рас- пределении данных, либо информация о механизмах реализации путей доступа. Из альтернативных планов выбирается наиболее оптимальный с точки зрения некоторого (заранее выбранного или заданного) критерия. На четвертом этапе по внутреннему представлению наиболее оптималь- ного плана выполнения запроса формируется процедурное представление пла- на. Выполняемое представление плана может быть программой в машинных кодах, если, как в случае System R, система ориентирована на компиляцию за- просов в машинные коды. В других системах, например, в INGRES, представ- ление плана является машинно-независимым, что более удобно для интерпре- тации запросов. Для нас это непринципиально, поскольку четвертая фаза обра- ботки запроса уже не связана с оптимизацией. Наконец, на последнем, пятом этапе обработки запроса происходит его реальное выполнение в соответствии с процедурным планом выполнения за- проса. Результат помещается в специальную область ОП (т.н. курсор). Более конкретные сведения о правилах работы оптимизаторов можно подчерпнуть из статей [11, 12]. Теперь рассмотрим преобразования, которым может подвергаться исход- ный реляционный запрос на этапе логической оптимизации. |