Курсовая. Евсина (1) (2). Курсовая работа дисциплина Системы автоматизированного перевода
 Скачать 445.66 Kb. Скачать 445.66 Kb.
|

|
МИНОБРНАУКИ РОССИИ Федеральное государственное бюджетное образовательное учреждение высшего образования «Тульский государственный университет» Институт гуманитарных и социальных наук Кафедра лингвистики и перевода КУРСОВАЯ РАБОТА Дисциплина: Системы автоматизированного перевода Направление: 45.03.02 – Лингвистика Контроль качества текста перевода при работе в программе переводческой памяти с учетом типологии переводческих ошибок (на примере программных продуктов Wordfast Anywhere и OmegaT) Студент группы 820301аф-ПБ ______________________ Келлер А.С. (подпись, дата) (фамилия, инициалы) Руководитель работы ________________ к.ф.н., доц. Евсина М.В. (подпись, дата) (фамилия, инициалы) Заведующий кафедрой _____________ проф., д. пед. н. Иванова В.И. (подпись, дата) (фамилия, инициалы) Тула 2023 Содержание Введение 3 Глава 1. Автоматизированный перевод 5 1.1.Составляющие автоматизированного перевода 5 1.2.Типология переводческих ошибок 12 Глава 2. Возможности контроля качества текста перевода в программах переводческой памяти 19 2.1. Контроль качества текста перевода в программе OmegaT 19 2.2 Контроль качества текста перевода в программе Wordfast Anywhere 25 Вывод 29 Список использованных источников 30 ВведениеЖизнь современного человека тяжело представить без технических достижений. Люди уже не видят себя без телефона в руке, навигатора в автомобиле или персонального компьютера под рукой. Говоря о переводчиках, для них вопрос современных технологий стоит еще более актуально. Тяжело представить человека, который профессионально занимается переводами, но при этом ни разу не пользовался электронными словарями, машинным переводом, программами памяти перевода или просто компьютером. Развитые современные технологии помогают переводчику экономить время, повысить качество и скорость работы. За последние несколько лет в отрасли переводов произошли огромные изменения, связанные с развитием технологий. Внедрение компьютерных технологий стало настоящим переломом в отрасли, поскольку позволило переводчикам стать более эффективными и продуктивными. Это, в свою очередь, помогло отрасли справиться с растущим спросом и острой нехваткой квалифицированных переводчиков. Такие технологии перевода, как машинный перевод и системы перевода на основе нейронных сетей, значительно повысили точность и эффективность переводов. Кроме того, теперь предприятиям как никогда легко локализовать свой контент на несколько языков с помощью услуг, предоставляемых переводческими компаниями. Компьютерные технологии произвели революцию в переводческой отрасли и продолжают оставаться неотъемлемой частью ее успеха. В связи с появлением крайне важных для переводчика инструменты, в том числе программ памяти перевода, возник вопрос о точности и качестве перевода, выполненного с помощью них, что также говорит об актуальности нашего исследования. Цель данной работы состоит в определении средств контроля качества перевода в программах переводческой памяти. Объектом исследования станут программы памяти переводов OmegaT и Wordfast Anywhere. Предметом исследования станут функции контроля качества текста в программах OmegaT и Wordfast Anywhere. Глава 1. Автоматизированный переводСоставляющие автоматизированного переводаВ XXI веке основополагающим фактором развития человечества в информационной области является повсеместная интеграция средств информатики не только на национальном уровне, но и в международном масштабе. Автоматизированный перевод можно рассматривать как один из способов формирования мультиязыкового пространства. Понятие автоматизированного перевода появилось в середине XX века. Первые теоретические разработки относят к 30-40-м годам, однако практическое применение теория автоматического перевода нашла в начале 50-х годов - после появления ЭВМ. В период холодной войны исследования в данной области представляли особый интерес в военной сфере и при достаточном финансировании усиленно развивались. Помимо составления алгоритмов, интенсивно проводились прикладные исследования в области структурной лингвистики по изучению и формализации языковых структур. По мере снятия технических трудностей с развитием кибернетики становился очевидным тот факт, что процесс перевода не сводится к формальному переходу от одного языка к другому. Разработчикам необходимо было решить ряд задач, связанных с формализацией контекста, передачей смысла всей фразы и отдельных единиц мысли с учётом факторов адекватности перевода. [Гуслякова, с. 66, 2016] Автоматизированный перевод - программа перевода, которая включает в себя одну из двух или обе технологии: Machine Translation (машинный перевод) и Translation Memory (переводческая память). [Силонов, с. 12, 2000] Зверева Н.С. и Терехова Е.В. сходятся во мнении, что преимущества использования автоматизированных систем перевода, по сравнению с традиционной технологией, заключаются в следующем: 1. Присутствует возможность глобального предварительного перевода всего текста (Pretranslate). 2. Присутствует возможность исключения полного повторного перевода документации, в которую внесены изменения и дополнения. 3. Использование комплексного математического механизма нечёткой логики при поиске похожих выражений и терминов позволяет находить огромное количество вариантов, к примеру, без учёта падежных окончаний. 4. Обеспечивается единообразие перевода, благодаря чему переводчик тратит меньше времени на редактирование и процесс редактирования переходит на качественно другой уровень. 5. Благодаря автоматизации монотонных операций (к примеру, автоматическое копирование перевода аналогичных фрагментов исходного текста) происходит сокращение затрат труда переводчиков, что позволяет им уделить большее внимание собственно переводу. 6. Обеспечиваются минимальные трудозатраты на выполнение работ в заданные сроки. Однако, эти преимущества достаточно спорны: затраты времени на редактирование могут не уменьшаться, а наоборот расти. Это зависит от качества используемой переводческой памяти. Автоматизация не столько сокращает затраты труда переводчика, сколько интенсифицирует труд переводчика, трудозатраты могут и расти, здесь, скорее, оптимизируется распределение трудозатрат между исполнителями переводческих проектов. [Кутузов, с. 41, 2007] В основе данных ТМ-программ лежит принцип сбора и хранения фрагментов переведенных текстов на двух языках (исходный фрагмент и его перевод). Эти фрагменты хранятся в специальном накопителе переводов (Translation Memory) и служат бесценным подспорьем при последующем выполнении переводов в рамках заданной тематики. Принципиальное различие между Machine Translation и Translation Memory продуктами заключается в том, что программы машинного перевода рассчитаны, прежде всего, на любительский перевод (по признанию сотрудников ПРОМТ, 80% использования их программ приходится на людей, выполняющих не перевод, а поиск), в то время как ТМ-программы могут быть использованы только профессиональными переводчиками. В основу перевода, выполняемого при помощи ТМ-программы, ложатся конструкции, выбранные человеком. Поэтому необходимым условием адекватности текста перевода является бесспорная компетентность специалиста-переводчика. Необходимо также учитывать, что МТ-программы опираются на изданные словари и поэтому готовы к работе в момент их приобретения. А для ТМ-программ базой данных служит накопитель, который в момент покупки программы пуст. Для того чтобы начать плодотворно использовать ТМ-программу, накопитель необходимо заполнить соответствующими речевыми моделями, при этом существует возможность обмена накопителями в рамках больших коллективных проектов что, в свою очередь, повышает качество работы специалистов и обеспечивает единство терминологии. [Кутузов, с. 95, 2007] Компьютерные программы могут по-разному влиять на процесс перевода. Для начала предлагаем следующие критерии различия: По степени автоматизации процесса перевода В зависимости от стадии, на которой применяются компьютерные программы По степени участия программы в переводе Сфера применения По степени автоматизации процесса перевода. А. Шкала Хатчинсона и Соммерса. С одной стороны, традиционный перевод (traditionalhumantranslation) - перевод человека без использования каких-либо автоматизированных вспомогательных средств. С другой- fullyautomatichighqualitytranslation (FAHQT)- перевод, который полностью осуществляется компьютером, не требуя человеческого вмешательства, «высшее качество» является своеобразной целью, которая кажется утопией, никакого контроля и никакие поправки в окончательный перевод не вносятся. Human-aidedmachinetranslation (HAMT) – перевод осуществляется полностью компьютерной программой, но человек редактирует конечный результат: особенности грамматики исходного и переводящего языка или реалии. Machine-aidedhumantranslation (MAHT) - включает в себя любой процесс, который выполняется компьютером, любую степень автоматизации процесса перевода. Таким образом, MAHTвключает в себя: орфографию, проверку грамматики и стиля, словари, энциклопедии, тезаурус, и другие источники информации, к которым переводчик может обращаться, как и сам, так и с помощью программы перевода. B. Классификация Алана Мелби (1983,1996) основана на различии между программами перевода первого и второго уровней. К первому уровню относятся программы, которые могут быть использованы с помощью переводчика при распечатке текста или отправке его по факсу. К ним относятся системы перевода с голоса на текст, электронная почта, факсимильные аппараты, программное обеспечение для подсчета слов и другие подобные технологии. Эти инструменты могут помочь сократить разрыв между переводчиками и их клиентами, предоставляя специалистам по переводу удобный способ завершить свою работу. Кроме того, эти программы могут обеспечить большую точность по сравнению с ручным переводом, поскольку они способны обнаружить и исправить любые ошибки, которые могут возникнуть в процессе перевода. Таким образом, они являются незаменимыми инструментами для любого профессионального переводчика.Ко второму уровню относятся устройства, которые требуют исходный текст в электронном варианте. К ним относятся: программа поиска терминов, эквивалентов, проверки качества и переводческая память. Большинство из этих программ требуют наличие билингвального корпуса [Гуслякова, с. 60, 2016]. Стадия, на которой применяется компьютерная программа. Алан Мелби в 1998 году предложил классификацию систем, которые могут оказать помощь переводчику, основываясь на этапе их применения (до, во время или после перевода и необходимые на всех этапах процесса перевода). Инфраструктура (Infrastructure) - программы, которые не предназначены непосредственно для перевода, однако относятся к одними из решающих. К ним относятся: Системы управления, создания документа Терминологические базы данных Телекоммуникации (интернет, электронная почта, передача файлов) Терминологический уровень (Term-level before translation) перед переводом — программы, способствующие выявлению необходимых в процессе перевода терминов в базе данных. Они способны обнаруживать не только слова, но и фразы. Такой отбор эффективнее, чем поиск в интернете. Терминологический уровень во время перевода (Term-level during translation) — программы, которые автоматически ищут подходящие термины и предлагают их эквиваленты на целевом языке, установленном переводчиком. Сам же переводчик не нуждается в ручном поиске терминов в базах данных. Терминологический уровень после перевода (Term-level after translation) — программы, которые проверяют согласование терминов уже в законченном переводе, а также помечают те термины, которые не рекомендуются переводчику для использования. Сегментный уровень перед переводом (Segment-level before translation) — программы, которые выравнивают сегменты переводного текста в согласовании с их порядком в исходном. Сегментный уровень во время перевода (Segment-level during translation) — включает в себя программы, которые проверяют наличие сегментов в памяти переводов. Сегментный уровень после перевода (Segment-level after translation) — программы, которые отмечают пропущенные сегменты (к примеру, если один из них не был переведен), проверяющие грамматику и напоминающие о формате исходного текста. Последовательность выполнения действий и подведение итогов (Translation workflow and billing management) — эти программы, которые не используются непосредственно в переводе, но очень важны для отслеживания проделанной работы, особенно если речь идет о больших проектах. В этом случае программы контролируют дедлайны, видоизменения текста, дату проверки и так далее. Степень участия программы в процессе перевода. Джоан Виларнау в 2001 году предложил классификацию компьютерных программ в зависимости от их участия в переводе. Программы перевода (Translation programs) — текстовые редакторы, программы перевода, программы машинного перевода, редакционно-издательские приложения, редакторы HTML и др. Программное обеспечение (Translation aid software) — базы данных, словари и энциклопедии на дисках, браузеры, электронные таблицы, программы проверки орфографии и грамматики и др. Программы для получения и отправки документов (Programs for sending and receiving documents) — электронная почта, протоколы, предназначенные для передачи файлов в сети интернет, программы распознавания голоса и др. Вспомогательное программное обеспечение (Accessory translation software) — системы сжатия информации, программы кодирования и др. Основные программы (General programs) — программы антивирусов и межсетевой защиты, техническое обслуживание и др. Эту классификацию можно представить в виде пяти кругов, чем ближе к центру круг, т.е. чем меньше его диаметр, тем больше он связан именно с самим переводом. Сфера применения. Вильгельм Нойнциг (Neunzig) в 2001 году выявил три сферы применения программ компьютерного перевода: Преподавание перевода Профессиональный перевод Изучение и анализ перевода Эта классификация выдвигает прагматическую точку зрения, фокусируясь на том, для чего используются определенные компьютерные программы и ресурсы, а также на том, кто их использует, без учета технологии, на которой они основаны. Например, этот тип классификации может быть использован для проведения различия между программой перевода и ресурсом перевода; оба эти понятия могут оказывать значительное влияние на точность перевода. Однако технология, используемая в каждом случае, может быть разной - одна может быть основана на искусственном интеллекте, а другая - на базе данных существующих переводов. Независимо от этого, данная классификация предоставляет полезный способ разделить компьютерные программы на категории с точки зрения их использования и пользователей [Кутузов, с. 102, 2007]. Типология переводческих ошибокБольшинство исследователей пришли к выводу, что ошибки перевода делятся на две большие категории: ошибки смысла, которые также называются денотативными ошибками, и ошибки формы. Внутри каждой группы можно выделить несколько типов ошибок. Таким образом, среди денотативных ошибок можно выделить пропуски, искажения, неточности и двусмысленности. Формальные ошибки подразделяются на чисто языковые, функционально-стилистические и ошибки, связанные с переформулировкой фигуры речи. Денотативные ошибки. Опущения и пропуски. Далеко не все расхождения между оригиналом и переводом можно считать переводческим несоответствием. К примеру, такое явление как опущение иногда не является ошибкой, а наоборот представляет собой часть переводческой стратегии. Такой род стратегии называется деформацией. «Деформация – это осознанное искажение какого-либо параметра текста оригинала, обоснованное стремлением решить глобальную переводческую задачу» [Цатурова, с. 78, 2008]. Опущения имеют под собой лингвистическую основу и обусловлены межъязыковой асимметрией, которая проявляется в отсутствии возможности передать средствами языка перевода игру слов, которая заключена в оригинале. В этих случаях опущение становится вынужденной мерой со стороны переводчика, которая никак не свидетельствует о его некомпетентности. Совсем другое дело – пропуски, или так называемые переводческие лакуны. Этот феномен возникает не тогда, когда язык перевода в принципе не обладает средствами для выражения содержания оригинала, а просто в труднопереводимых местах. Именно по этой причине пропуски говорят о недостаточной компетенции переводчика и не имеют лингвистической природы, а соответственно, могут быть отнесены к переводческим ошибкам. Существует и иное явление, относящееся к разряду деформаций, которое, однако, не исключает из перевода фрагмента текста, а, наоборот, добавляет, иными словами, речь идет о неоправданном расширении. Эта стратегия перевода была гораздо более распространена до 20 века, чем сейчас. Эти тенденции можно объяснить тем, что переводчики считались соавторами, иногда самостоятельными авторами, создателями совершенно новых произведений на основе исходных текстов. В соответствии с этим переводчик имеет право формировать стиль произведения, вносить исправления и даже полностью изменять смысл исходного текста. Так как переводчик многое добавил, вывод несопоставим с исходным текстом. Так, к примеру, переводы К. Д. Бальмонта стихов английского поэта П. Б. Шелли изобилуют подобными расширениями: там, где в оригинале написано лютня, в оригинале появляется рокот лютни чаровницы. Этот метод сейчас считается неприемлемым, а главным условием перевода сегодня является правильная передача содержания [Бузаджи и др., 120, 2009]. Поэтому к наиболее серьезному разряду ошибок сегодня относят денотативные ошибки. Среди исследователей нет разногласий по поводу того, следует ли относить такие ошибки к переводу. Искажения. Денотативные (смысловые, когнитивные) ошибки возникают при преобразовании содержания исходного текста. К ним относятся: искажения, неточности, неясности и двусмысленности. Их классификация основана на специфике и степени воздействия ошибки на получателя перевода. Искажения в этой градации стоят на первом месте, потому что они очень сильно дезинформируют адресата относительно того, что на самом деле сказано в тексте оригинала. Искажение предметной соотнесенности из-за неверной интерпретации отрезка исходного текста или ошибочного выбора средств языка перевода не позволяет читателю переведённого текста определить область референции исходного текста, что препятствует осуществлению успешной коммуникации. Неточности и неясности. Неточности также могут ввести получателя перевода в заблуждение относительно заявленной тематики. Но в этом случае степень дезинформации не так велика, как в случае искажения. Ср. рус. лысый и плешивый – общий смысл сохраняется (отсутствие волос на голове), но стилистически между этими двумя словами есть существенное различие, и перевод нейтрального испанского calvo русским плешивый может в некоторых контекстах исказить смысл, так как «плешивый» также может означать «облезлый» и иметь однозначно деспективный оттенок [Дебренн, с. 36, 2007]. К неточностям также относят так называемую «фигуру умолчания», то есть неполный перевод словосочетания или составного термина. Читатель может не заметить неполноты, так как в переводе часто не остается никаких следов пропущенного содержания. «Фигура умолчания» может привести не только к элиминации смысла, но и к расширению значения понятия, что придает тексту более обобщённый характер. Неясность от искажения и неточности отличается тем, что не столько дезинформирует адресата перевода, сколько дезориентирует его. Искажения и неточности приводят к неправильному пониманию смысла переданной информации, а неясности вводят читателя в замешательство, при котором он не знает, каким образом ему интерпретировать прочитанное. Точно такое же воздействие на получателя оказывают и двусмысленности. Ошибки формы. Также утверждается, что ошибки формы не стоит относить к переводческим ошибкам. Именно по этой причине некоторые учёные относят ошибки такого рода к собственно языковым ошибкам, то есть к ошибкам, которые вызваны не непониманием содержания текста, а плохим владением языком ПЯ. Данное мнение можно принять в том случае, если говорить только о переводе на неродной язык. Если бы языковые ошибки были обусловлены только плохим владением переводящего языка, то их не допускали бы образованные и грамотные переводчики в переводах на родном языке. Значит, можно говорить о том, что они вызваны именно ситуацией перевода [Дебренн, с. 40, 2007]. Во-вторых, неверно и то, что языковые ошибки не оказывают существенного влияния на переведенный контент. Если денотативные ошибки искажают предметную отнесенность текста, затрудняют поиск области референции, то функциональные ошибки посредством речевого сообщения разрушают социальное взаимодействие. Собственно языковые ошибки. Исследователь М. А. Куниловская предлагает следующее деление языковых ошибок: 1) лексические; 2) грамматические (морфологические и синтаксические); 3) орфографические и пунктуационные. К лексическим ошибкам относятся тавтология, нарушение сочетаемости слов, использование слов в несвойственных для них. К синтаксическим – нарушение порядка слов в предложении. К морфологическим – нарушение правил согласования и управления. Некоторые исследователи, говоря о языковых ошибках, также выделяют подкласс узуальных ошибок. С точки зрения нормы мы имеем дело с дихотомией «правильно-неправильно», а с точки зрения узуса – «уместно-неуместно». Одна и та же фраза может быть правильно построенной с точки зрения нормы русского языка, но разные её варианты могут быть более или менее узуальны (типичны) в разных ситуациях общения. Например, спросить на рынке «Какова цена ваших огурцов?» вместо «Почем огурцы?» или «Сколько стоят огурцы?» можно, и вас даже поймут, но звучать это будет несколько смешно, так как такая фраза нетипична для данной ситуации общения. Функционально-стилистические ошибки. К художественному переводу нельзя подходить «чисто технически, с точки зрения перевода смысла» [Шевнин, с. 51, 1985], ведь сложность художественного перевода заключается именно в необходимости передать на языке ПЯ не только то, что сказано в тексте оригинала, но и то, как это сказано. Хотя художественный текст заключает в себе и информационную составляющую, это не является его отличительной особенностью. Сложность состоит в том, что содержание художественного текста является многоплановым: литературный текст призван оказывать на читателя и эмоциональное, и эстетическое, и рациональное воздействие, формируя у него определенное отношение к тем или иным описанным событиям. Вполне естественно, что для данных целей необходимы и особые способы передачи информации. В этом случае могут быть задействованы языковые средства всех уровней: ритмическая организация текста, фоносемантика, лексическая семантика, грамматическая семантика и т.д. [Kupsch-Losereit, с. 82, 1985]. Часть содержания литературного произведения заключена в его форме, и нарушение авторского стиля при переводе может привести к тому, что у читателя сложится неверное представление о позиции самого автора по отношению к изложенному в тексте. В упомянутой выше работе «Переводческий билингвизм» выделяется еще один вид стилистических ошибок, а именно так называемые «стилистические неровности» [Тетерлева, с. 52, 2009]. Бывают случаи, когда переводчик в следствие отсутствия четкой стратегии не придерживается одного стиля на протяжении произведения, постоянно сменяя стилевой регистр, в то время как язык оригинала предельно выдержан. Помимо личного стиля автора, необходимо учитывать и особенности национального языка. Каждая культура имеет свое представление о том, что представляет собой хороший стиль. Например, для испанского языка характерно использование в качестве эпитетов нескольких полных синонимов, что является нормой. В русской традиции это считается тавтологией. Если мы сохраним эту особенность испанского национального языка в переводе на русский язык, русские читатели могут увидеть в нем безграмотность и безвкусицу автора. В этом случае важно адаптировать стиль исходного текста к восприятию получателя перевода. Бывают иные случаи, когда переводчики адаптируют текст к реалиям носителей ПЯ настолько, что произведение полностью теряет свою национальную стилистическую окраску. Такой подход сегодня считается ошибочным. Л. С. Бархударов в своей работе «Язык и перевод» подчеркивает, что так называемое «склонение на русский лад» может привести как к смысловому, так и к стилистическому искажению подлинника. Образность и экспрессивность. Информация в художественном тексте, в отличие от текстов научных или технических, может сообщаться не только эксплицитно, но и имплицитно — с помощью всевозможных иносказаний: метафор, аллегорий, символов — которые порой допускают множество прочтений. Неправильный перевод форм образной речи относится к разряду ошибок, обусловленных неверным истолкованием смыслов текста оригинала. По существу, перевод фигур речи, основанных на метафорическом принципе, не должен представлять сложности: метафоры и средства их передачи существуют практически во всех языках. Но кроме клишированных метафор, которые не так сложно выделить в тексте и для которых возможно найти соответствия в языке перевода, существуют еще и индивидуальные метафоры, и аллегории. В художественном тексте реальность преломляется через художественное видение автора, и это может значительно усложнить задачу переводчика, так как даже при наличии обширных фоновых и культурных знаний авторский замысел может быть им неверно интерпретирован. Подобные явления относятся к так называемым «косвенным речевым актам» [Гарбовский, с. 516, 2004], т.е. к высказываниям, внешняя форма которых может скрывать истинную интенцию автора. Кроме того, важную роль при чтении текстов могут играть этнокультурные стереотипы. В любом языке существует жесткий и устойчивый набор сравнений, метафор и эпитетов, которые не считаются художественными для носителей языка, но могут показаться остроумными новыми читателям изучаемого языка. С одной стороны, если переводчик в процессе перевода сохранит метафору неизменной, это нарушит намерение автора ничего не выражать в данном отрезке, и такое переводческое решение покажется противоречивым. Ведь читатели исходного текста будут воспринимать произведение как менее художественное, тогда как читатели переведенного текста будут воспринимать его как написанное экспрессивно-образным языком. С другой стороны, стереотипные метафоры и эпитеты можно рассматривать как национальные условия, и с этой точки зрения сохранение их в переводе не лишено смысла [Жигалина, с. 17, 2008]. В любом случае важно осознавать, что чрезвычайно сложно перевести литературное произведение таким образом, чтобы оно произвело на иностранных читателей впечатление, задуманное первоначальным автором: культурные реалии всегда будут восприниматься читателем языка перевода как нечто экзотическое и яркое, но в то же время не обратят на себя внимания носителя языка оригинала. Глава 2. Возможности контроля качества текста перевода в программах переводческой памяти2.1. Контроль качества текста перевода в программе OmegaTOmegaT — система автоматизированного перевода, поддерживающая память переводов, написана на языке Java. OmegaT содержит все основные функции полноценной переводческой среды, включая управление проектами, память переводов и терминологические глоссарии, тем самым являясь жизнеспособной альтернативой платным аналогам. OmegaT имеет много общих функций с распространенными CAT-программами. К ним относятся создание, импорт и экспорт памяти переводов, нечеткое сопоставление из памяти переводов, поиск в глоссарии, а также поиск ссылок и соответствий. Панель редактирования также имеет встроенную проверку орфографии с использованием словарей Hunspell. OmegaT может получить машинный перевод и отобразить его в отдельном окне. Из плюсов работы с программой хотелось бы отметить, во-первых, что программа бесплатная, то есть с ней можно работать неограниченное количество времени, а не только пробный период, как с большинством других подобных программ. Во-вторых, при создании проекта в OmegaT автоматически формируется папка, в которую также автоматически сохраняется перевод, добавленные в глоссарий по ходу перевода слова и т.д. Это очень удобно, поскольку, например, можно сразу сохранить проект на необходимой карте памяти. В-третьих, в Omega T есть окно неточных совпадений, откуда можно в один клик вставить вариант перевода в область редактирования и корректировать его в соответствии с текстом текущего документа. Программа OmegaT имеет вкладку «Инструменты», в которой можно провести контроль качества текста перевода. 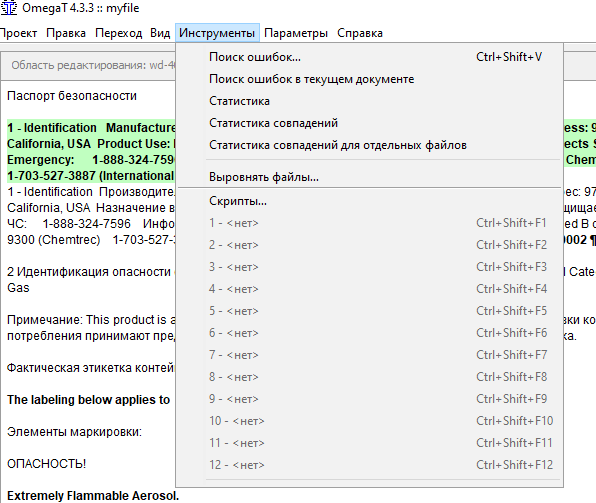 Изображение 1. Вкладка «Инструменты» в OmegaT В данной вкладке можно произвести поиск ошибок и посмотреть статистику совпадений в тексте. 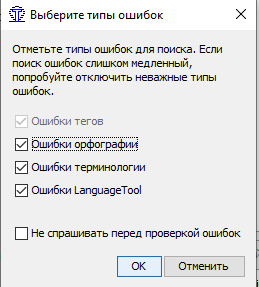 Изображение 2. Функция поиска ошибок Функция «Поиск ошибок» позволяет обнаружить ошибки тегов, орфографии, терминологии и LanguageTool. LanguageTool — это свободная программа для проверки стиля и грамматики в текстах на английском, французском, немецком, польском, нидерландском, румынском и других языках. Мы можем рассматривать LanguageTool как программу, которая находит ошибки, пропущенные обычной проверкой орфографии. Также эта программа может обнаруживать некоторые грамматические ошибки. А вот поиском собственно орфографических ошибок она не занимается. LanguageTool ищет ошибки согласно определённым правилам языка, которые записаны в соответствующих файлах конфигурации. 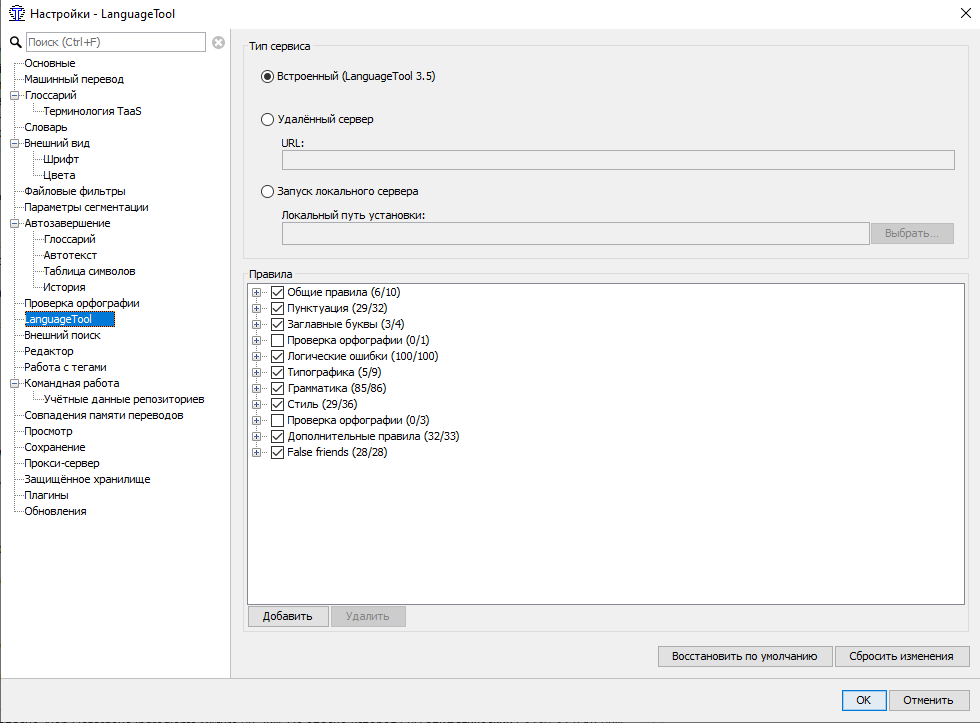 Изображение 3. LanguageTool Настройки модуля LanguageTool позволяют выбрать его версию. Можно использовать встроенную, либо же загрузить из удалённого или локального сервера. Также, в программе предоставляется возможность выбора правил LanguageTool, по которым будет проходить проверка текста. 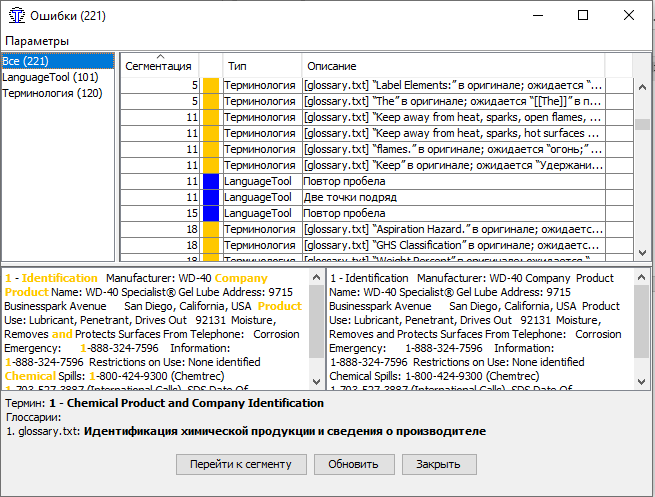 Изображение 4. Выполнение функции поиска ошибок Функция произвела анализ текста и разделила выявленные ошибки на два типа: терминология и LanguageTool. При поиске терминологических ошибок программа сравнивала переведённые терминами с терминами из глоссария. В LanguageTool были выявлены пунктуационные ошибки, такие как две точки подряд и пропуск пробела, и грамматические ошибки, такие как двойное отрицание и несогласованность прилагательного с существительным. Также, OmegaT обладает возможностью выбора словаря для проверки орфографии. 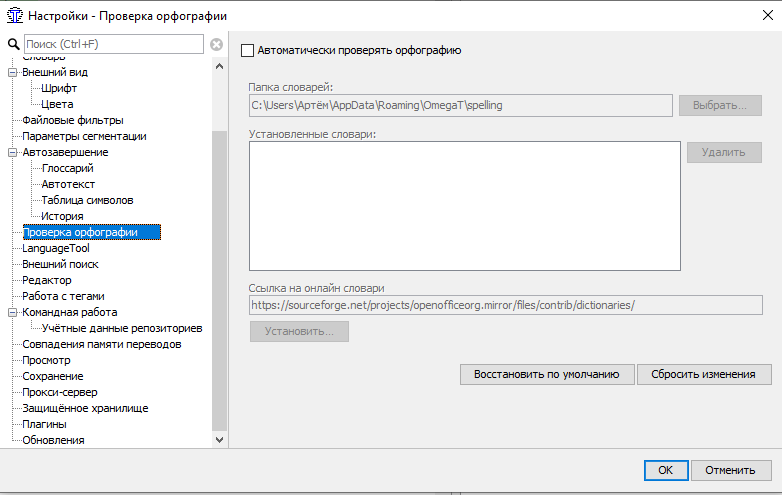 Изображение 5. Настройки проверки орфографии OmegaT предоставляет возможность загрузки словаря с устройства или из интернета. 2.2 Контроль качества текста перевода в программе Wordfast AnywhereWordfast Anywhere - это бесплатная интернет-версия Wordfast, выпущенная в 2010 году, в которой команды и интерфейс пользователя очень схожи с Wordfast Classic. Для ее использования не требуется установки никакого специального программного обеспечения, все, что вам необходимо — это браузер, подключение к Интернету и любое оборудование. Несмотря на то, что использование Wordfast Anywhere является бесплатным, оно имеет некоторые ограничения, которые будут упомянуты немного позже. Подобно другим программам этого класса, Wordfast Anywhere позволяет выполнять сегментацию исходного текста, использовать точные и неточные соответствия с уже переведёнными фрагментами, создавать и использовать глоссарии терминов, выравнивать ранее выполненные переводы с загрузкой в базу данных переводов, искать контексты в базах данных переводов. Переводчики могут также использовать дополнительную функцию «машинного перевода» и обширную, общедоступную память переводов. С 2011 года Wordfast Anywhere содержит оптическое распознавание документов в формате PDF. Из плюсов стоит упомянуть, что программа бесплатная, что позволяет пользоваться ею неограниченное количество времени, а не только пробный период, как в большинстве других подобных программ, также при нечетких совпадениях часть сегмента, отличающаяся от того, что сохранено в базе данных, автоматически выделяется желтым цветом, что облегчает поиск не совпавшего фрагмента, и позволяет отредактировать его в соответствии с текстом текущего документа. Ещё на базе Wordfast Anywhere находится сервис Wordfast Aligner, позволяющий создавать память перевода, не закрывая при этом саму программу. Среди минусов нельзя не отметить, что программа не исправляет ошибки, а также невозможность работать с программой без интернета. После загрузки документа в программу и выполнения перевода мы можем увидеть следующую картину: 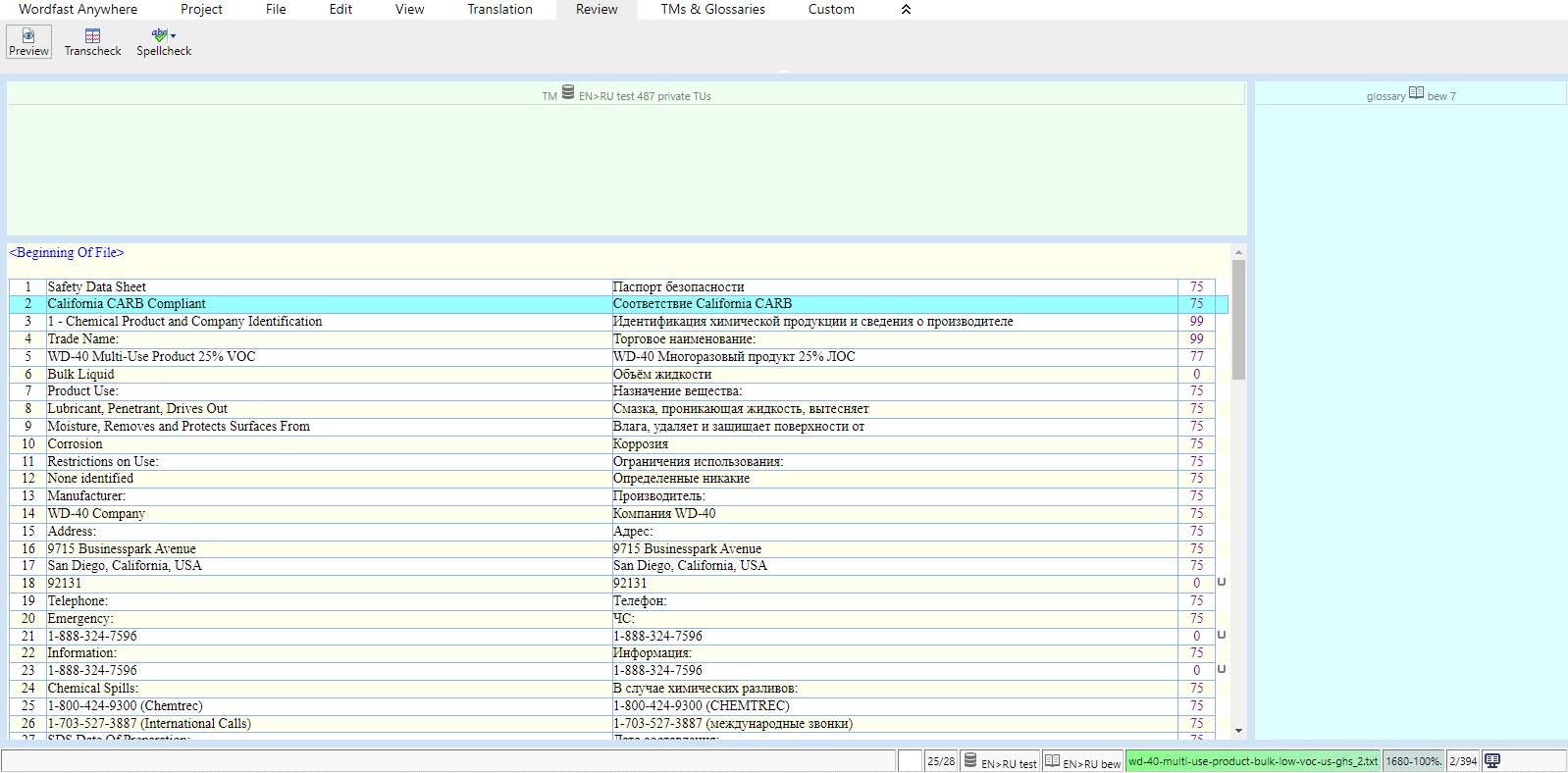 Изображение 6. Интерфейс WordfastAnywhere На данный момент в программе Wordfast Anywhere есть две функции, которые позволяют провести контроль качества переведённого текста. Проверка орфографии: Wordfast Anywhere использует словарь, чтобы проверить орфографию переведенного текста. Если слово не найдено в словаре, оно будет помечено как ошибочное. Проверка соответствия: Эта функция позволяет проверить соответствие переведенного текста оригиналу. Wordfast Anywhere выделяет несоответствия и предлагает варианты исправления. Для проведения контроля качества текста в программе предоставлена отдельная вкладка «Review».  Изображение 7. Вкладка контроля качества в WordfastAnywhere Функция «Preview» позволяет создать PDF файл переведённого текста и открыть его. Функция «Transcheck» выполняет проверку соответствия критериям качества переведённого текста оригинальному. 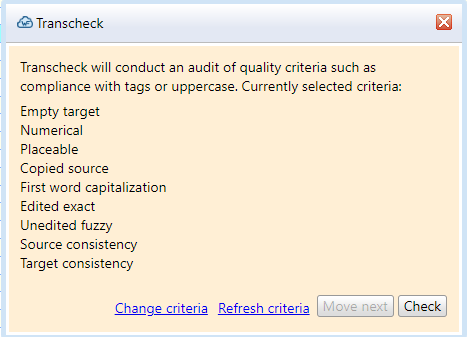 Изображение 8. Описание функции «Transcheck» Описание функции говорит о том, что проверка будет выявлять не соответствия в виде пустых сегментов, чисел, заглавных букв, целостности сегментов, неисправленных неясностей. Также, функция позволяет изменить критерии качества и обновить их. После нажатия кнопки «Check» функция производит анализ текста. 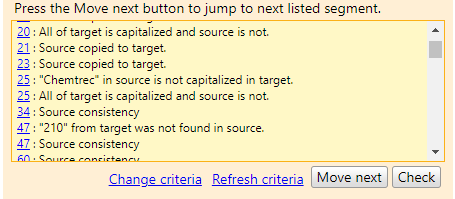 Изображение 9. Выполнение функции «Transcheck» Функция произвела анализ текста и вывела отчёт о найденных несоответствиях. Числа синего цвета обозначают номера сегментов. Как мы можем заметить, в данном фрагменте были найдены несоответствия в заглавных буквах, числах и целостности текста. Для перехода к следующему фрагменту текста необходимо нажать кнопку «Move next». Функция «Spellcheck» производит проверку орфографии.  Изображение 10. Интерфейс функции «Spellcheck» Функция проанализировала текст и выявила возможные орфографические ошибки. В тех случаях, когда программа считает, что в слове есть орфографическая ошибка, но не может предложить исправленный вариант, она выводит «No suggestions.». Также, стоит упомянуть, что данная функция не всегда даёт верные и точные варианты исправления. К примеру, в сегменте 40 функция предложила исправить «промышленного/профессионального» на «высокопрофессионального», что не является точным вариантом перевода. ВыводПодводя итог, можно сделать вывод, что общим преимуществом функций контроля качества текста интегрированных в программы переводческой памяти OmegaT и Wordfast Anywhere является возможность осуществлять мониторинг качества перевода без задействования дополнительных программных и временных ресурсов. Программы памяти перевода действительно могут помочь переводчику, экономя его время и усилия. Это происходит за счёт использования определённого глоссария и определённой памяти перевода для конкретных текстов, что позволяет переводчику выбирать между предложенными вариантами перевода определённой направленности. Более того, в программах памяти перевода есть встроенные функции контроля качества текста перевода, которые позволяют произвести автоматический анализ текста на предмет ошибок разного типа, что помогает избежать долгой и монотонной ручной проверки. Данное исследование выявило, что программа OmegaT обладает большим количеством возможностей контроля качества. Wordfast Anywhere не имеет функции проверки стиля, грамматики и ложных друзей переводчика и дополнительных правил. Однако, как показало наше исследование, нельзя полагаться только на помощь программ памяти перевода в контроле качества текста. Хоть они и упрощают работу переводчика, они могут допускать ошибки. Список использованных источников1. Мильчин А. Э. Человек книги. Записки главного редактора. М.: Новое лит. обозрение, 2016. 2. Письменный перевод. Рекомендации переводчику и заказчику / сост. Н. Дупленский URL: http://www.russian-translators.ru/netcat_files/130/84/h_58f42cc46a26303b7e5d851ec593a368 3. Моисеенко Г. Практический справочник переводчика и редактора. URL: https://msn.khnu.km.ua/pluginfile.php/257466/mod_resource/content/1/Translator-editor_reference_ book_02-2015_Moiseenko.pdf 4. Мильчин А. Э. Методика редактирования текста. Изд. 3-е, перераб. и доп. М.: Логос, 2005 5. Разница машинного и автоматизированного перевода [Электронный ресурс] URL: http://www.toptr.ru/library/translationtruth/avtomatizirovannyij-i-mashinnyij-perevodyi-v-chyom-raznicza.html 6. Гуслякова А.В. Информационные технологии и лингвистика XXI века, 2016 7. Грабовский В.Н.: Технология Translation Memory. «Мосты» 2/2004 8. Кутузов, А.Б.: Компьютерные технологии в формировании профессиональной компетенции переводчика // Языки профессиональной коммуникации: сборник статей Третьей международной научной конференции, т.2. - Челябинск, 2007 г. URL: http://tc.utmn.ru/files/kutuzov_it.pdf 9. Шахова Н.Г.: Поезд снова уходит. Домашний компьютер №5 1.05.2000 10. Силонов А.: Программы, помогающие переводчику. Компьютерная неделя №16 (238) Москва 16-22.05.2000 11. Бузаджи Д.М., Гусев В.В., Ланчиков В.К., Псурцев Д.В. Новый взгляд на классификацию переводческих ошибок. М.: Всероссийский центр переводов научно-технической литературы и документации, 2009. 12. Дебренн М. Межъязыковая девиатология: ошибки порождения и понимания // Вестник Новосибирского государственного университета. Серия: Лингвистика и межкультурная коммуникация. 2007. № 5. 13. Жигалина В.М. Проблема переводческого решения // Иностранные языки: лингвистические и методологические аспекты: c6. науч. трудов. Вып. 2. 2005. М., 2009. 14. Комиссаров В.Н. Общая теория перевода. М.: ЧеРо, 1999. 15. Тетерлева Е.В., Попова Ю.К. Типы переводческих ошибок. Сборник научных трудов Пермского государственного педагогического университета (ПГПУ), 2009. 16. Цатурова И.А., Каширина Н.А. Переводческий анализ текста. СПб.: Перспектива, Изд-во «Союз». 2008. 17. Шевнин А.Б. Переводческая эрратология: новый взгляд на описание концептуальной и языковой картины мира / А.Б. Шевнин // Теория и практика перевода и профессиональной подготовки переводчиков: устный перевод. 2008. 18. Kupsch-Losereit, S. The problem of translation error evaluation, Christopher Titford and A.E. Hieke. Translation in Foreign Language Teaching and Testing. Tubingen: Narr., 1985. 19. Kussmaul, P. Training the Translator.Amsterdam and Philadelphia: John Benjamins, 1995. 20. Newmark, P. About Transldtion. Clevedon and Philadelphia: Multilingual Matters, 1991. |