it лаб работы. IT_лаб работы_ЗАОЧНОЕ. Лабораторная работа 1 2 Оценка размера и сложности программных средств методом функциональных точек с использованием пакета cosmos 2
 Скачать 2.46 Mb. Скачать 2.46 Mb.
|

6. Рекомендуемая литератураБоэм Б.У. Инженерное проектирование программного обеспечения. – М.: Радио и связь, 1985. – 512 с. Брукс Ф.П. Мифический человеко-месяц или как создаются программные системы. – М.: Символ-Плюс, 2000. – 304 с. http://www-cs.etsu.edu/softeng/ http://sunset.usc.edu/research/COCOMOII/cocomo_main.html COSMOS Technical Reference. The Software Cost Modeling System. Version 4.1. Revision E5. East Tennessee State University - Department of Computer and Information Sciences. 1998. – 71 p. Соммервилл Иан Инженерия программного обеспечения. – М., СПб., Киев: «Вильямс», 2002. – 625 с. Орлов С.А. Технологии разработки программного обеспечения. – СПб.: Питер, 2004. – 528 с. ЛАБОРАТОРНАЯ РАБОТА № 3Оценка трудоемкости разработки программных средств на основе аналогий с использованием пакета ANGELplus1. Цель работыПознакомиться с концепциями оценки трудоемкости разработки ПС на основе аналогий, получить практические навыки работы с программой ANGELplus 2. Теоретическая справка2.1. Методика оценки на основе аналогийДолгий опыт оценки стоимости и трудоемкости разработки программного обеспечения показал, что это довольно сложное занятие, часто приводящее к дорогостоящим ошибкам. До недавнего времени большинство исследований было сконцентрировано на алгоритмических методах оценки, например, таких как метод функциональных точек, модель COCOMO и т.п. Однако, отсутствие непротиворечивых результатов от алгоритмических моделей заставило исследователей взглянуть на альтернативные методы, в частности на методы «обучения машины» такие, как нейронные сети и принятие решений на основе прежнего опыта. Один из таких методов - оценка на основе аналогий, является предметом исследования Empirical Software Engineering Research Group (ESERG) в Борнмутском университете (Великобритания). Оценка по аналогии включает в себя поиск подобий между целевой сущностью, такой как начинаемый программный проект и множеством исторических сущностей того же класса (случаев успешно завершенных программных проектов). Каждая сущность характеризуется набором свойств или атрибутов. В случае программного проекта этими атрибутами могут быть, например, количество строк кода, трудозатраты в человеко-днях, количество функциональных точек, язык программирования и т.п. Упрощенно процесс поиска аналогий состоит в следующем: в некотором n–мерном пространстве, где n – количество атрибутов, строятся точки соответствующие случаям успешно завершенных программных проектов. Затем на основании известных атрибутов исследуемого проекта строится в общем случае некоторая гиперплоскость и находится евклидово расстояние между этой гиперплоскостью и точками существующих случаев. Существующий случай, евклидово расстояние, между точкой которого и гиперплоскостью минимально, формирует базис оценок, используемый для вычисления остальных атрибутов исследуемого случая. ANGELplus (ANaloGy softwarE tooL) является программным средством прогнозирования издержек разработки программного обеспечения, использующим метод оценки по аналогии, описанный выше. 2.2. Основные шаги при работе с ANGELplusЧтобы выполнить большинство оценочных задач в ANGELplus, необходимо предпринять три основных шага. Шаг №1: подготовка набора исходных исторических данных, т.е. значений атрибутов успешно выполненных проектов. Существует несколько способов, как это можно сделать. Создание нового набора данных. Если необходимо создать новый набор данных непосредственно в ANGELplus, то производятся следующие действия: Из меню «File» выбирается команда «New Dataset» (Новый набор данных). После этого откроется форма для ввода исходных данных. Сначала в таблице вкладки «Template» (Шаблон) определяются все атрибуты, которые будут использоваться в дальнейшем в процессе оценивания. Затем необходимо открыть таблицу вкладки «Source» (Исходные данные) и ввести все необходимые новые исходные данные. Таблица во вкладке «Template» состоит из пяти столбцов: «Name» (Название атрибута), «Type» (Тип шкалы измерения атрибута), «Priority» (Приоритет атрибута), «Description» (Описание атрибута) и «Status» (Состояние атрибута). Тип шкалы измерения атрибута показывает, как будут измеряться его значения. Например, шкала измерения атрибута может быть типа «Numeric» (численная), если атрибут может принимать численные значения, и «Categorical», если атрибут принимает одно из предопределенных для него значений. Приоритет атрибута показывает насколько важно учитывать расстояние по оси этого атрибута при определении расстояния до точки, существующего факта. Приоритет может быть «LOW» (низкий), «NORMAL» (нормальный), «HIGH» (высокий), «VERY HIGH» (очень высокий). Описание атрибута является необязательным для заполнения полем, служащим для конкретизации смысла атрибута. Состояние атрибута показывает, учитывается ли расстояние по оси данного атрибута при нахождении общего расстояния между исследуемым случаем и существующими случаями или нет. Состояние может быть «ON» (учитывается) и «OFF» (не учитывается). Первые три атрибута являются обязательными. Эти атрибуты: «Case Index» (порядковый номер случая), «Case Status» (состояние случая) и «Case Name» (название случая). Атрибут «Case Index» является неизменяемым. Атрибут «Case Status» показывает, использовать ли случай для поиска по аналогии. Добавление атрибута осуществляется нажатием кнопки «Add» (добавить) на нижней панели команд. Поля описания атрибутов, имеющие предопределенные значения, могут быть изменены двойным щелчком мыши или нажатием пробела. В поле «Description» информация заносится с помощью клавиатуры. Остальные команды на нижней панели команд служат для удаления атрибутов («Delete»), очистки значений всех введенных атрибутов («Clear»), смены состояния одновременно всех атрибутов («On/Off»), установки шкалы измерения всех атрибутов по умолчанию («Fill Default Type»), установки приоритета всех атрибутов по умолчанию («Fill Default Priority»). Пример заполненной вкладки «Template» приведен на рис. 6.1. 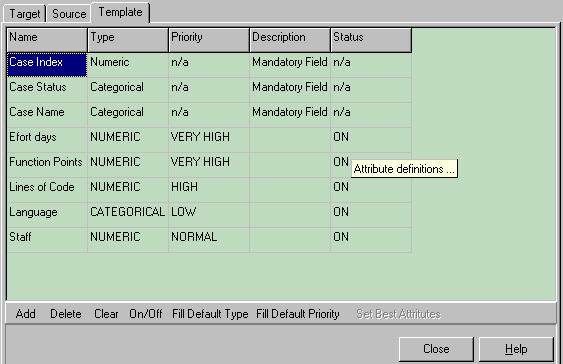 Рис. 6.1. Заполненная вкладка «Template» Вкладка «Source» содержит таблицу значений атрибутов уже существующих случаев (успешно завершенных проектов). Столбцы этой таблицы (рассматриваемые атрибуты) определяются во вкладке «Template». Редактирование таблицы осуществляется с помощью нижней панели команд: «Add» (добавить случай), «Delete»(удалить случай), «Clear» (очистить значения всех атрибутов, существующих случаев), «On/Off»(изменить состояние случая), «Import Source…» (импортировать значения атрибутов), «Export Source…» (экспортировать значения атрибутов). Два поля в нижней правой части панели показывают общее число случаев («CaseCount») и общее число рассматриваемых атрибутов («AttrCount»)/ Пример заполненной вкладки «Source» приведен на рис. 6.2. Открытие набора данных. Если можно использовать набор данных, ранее сохраненный в формате ANGELplus, то необходимо сделать следующее: Из меню «File» выбирается команда «Open Dataset…» (Открыть набор данных). После открытия файла с расширением adf на экране раскроется форма исходных данных, в которой будут заполнены таблицы вкладок «Template» и «Source». 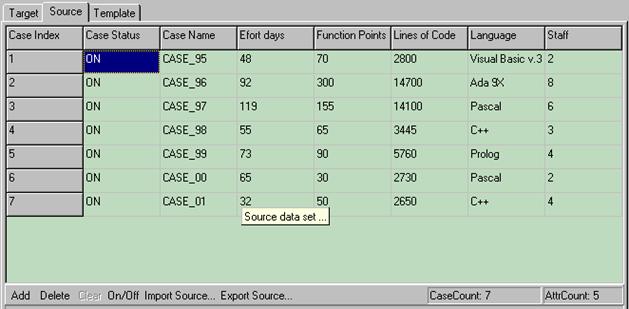 Рис. 6.2. Заполненная вкладка «Source» Рис. 6.2. Заполненная вкладка «Source»Импорт исходного набора данных. Если уже имеется исходный набор данных, сохраненный в файле в формате ASCII с запятыми или знаками табуляции в качестве разделителей, можно импортировать этот набор данных в таблицы исходных данных ANGELplus. До импортирования необходимо убедиться в том, что первая строка исходного ASCII файла состоит только из названий атрибутов. Операции импорта исходного набора данных производятся в следующей последовательности: Из меню File выбирается команда «Import Dataset…» (Импорт набора данных). В диалоге «Open File» (Открыть файл) выбирается нужный текстовый файл и нажимается кнопка «ОК». До того, как файл загрузится в таблицу данных ANGELplus, появится окно диалога, запрашивающего тип разделителя, используемого в файле. Необходимо выбрать соответствующую опцию и нажать «ОК». После этого информация из файла записывается в окно исходных данных вкладки «Source». Если теперь открыть вкладку «Template», названия атрибутов импортированного исходного набора данных автоматически появляются в первом столбце таблицы «Template». При необходимости можно отредактировать любые характеристики каждого атрибута. Шаг 2: подготовка исследуемого случая для расчета. Перед использованием каких-либо команд из меню «Run» (Расчет) обычно необходимо подготовить рассчитываемый случай, для чего требуется: Открыть вкладку «Target» (Исследуемый случай). Ввести атрибуты рассчитываемого случая вручную или выбрать случай из списка, хранящего индексы всех исходных случаев. Затем отредактировать один или несколько атрибутов рассчитываемого случая, если это необходимо. Шаг 3: операции оценивания. Выполнив первые два шага, можно приступить к одной из следующих операций оценивания. Спрогнозировать значения одного или более атрибутов рассчитываемого случая. Для этого необходимо: Выбрать «Estimate Targets» (Оценка значений атрибутов рассчитываемого случая) из меню Run (Расчет). Появится диалог «Estimation Option» (Опции оценивания). Выбрать один или более оцениваемых атрибутов рассчитываемого случая из левой части списка. Нажать кнопку «>» или дважды щелкнуть по выбранному атрибуту. Атрибут(ы) для прогнозирования появляются в правой части списка. Выбрать из выпадающего списка количество наиболее близких случаев, которые будут использоваться для прогнозирования. Нажать «ОК», чтобы выполнить оценку. Найти для рассчитываемого случая наиболее близкие успешно завершенные проекты и расстояние до них. Для этого необходимо: Выбрать команду «Find Closest Case» (Найти наиболее близкие случаи) из меню Run и выполнить поиск. Найти подмножество наиболее важных для оценивания атрибутов. Для этого необходимо: Выбрать «Find Best Attribute Set» (Найти подмножество наиболее важных для оценивания атрибутов) из меню Run. Появится диалог «Best Attribute Search Option» (Опции поиска подмножества наиболее важных для оценивания атрибутов). Выбрать атрибут из предлагаемого списка и количество рассматриваемых исходных случаев (аналогий). Нажать «ОК», чтобы выполнить поиск. Найти подмножество наиболее важных для оценивания атрибутов с ограничением по времени. Для этого необходимо: Выбрать «Find Best Attribute Set with Time Limit» (Найти подмножество наиболее важных для оценивания атрибутов с ограничением по времени) из меню Run. Появится диалог «Best Attribute Search Option» (Опции поиска подмножества наиболее важных для оценивания атрибутов). Выбрать атрибут из предлагаемого списка и количество рассматриваемых исходных случаев (аналогий). Ввести ограничение по времени (в минутах) в поле для ввода. Нажать «ОК», чтобы выполнить поиск. Результат выполнения каждой операции показывается в соответствующей части окна результатов. |