РВС 2 лаба. Лабораторная работа 2 Содержание Введение 3 Ход выполнения лабораторной работы 4 Заключение 7
 Скачать 68.25 Kb. Скачать 68.25 Kb.
|

|
Лабораторная работа №2 СодержаниеВведение 3 Ход выполнения лабораторной работы 4 Заключение 7 ВведениеТехнология CUDA появилась 2006 году и представляет из себя программно-аппаратный комплекс производства компании Nvidia, позволяющий эффективно писать программы под графические адаптеры. С 2006 года компания Nvidia обещает, что все графические адаптеры их производства независимо от серии будут иметь сходную архитектуру, которая полностью поддерживает программную часть технологии CUDA. Программная часть, в свою очередь, содержит в себе всё необходимое для разработки программы: расширения языка С, компилятор, API для работы с графическими адаптерами и набор библиотек. Ход выполнения лабораторной работыПосле установки CUDA Toolkit для Visual Studio 2019 Community. В данном типе проекта доступны дополнительные настройки для CUDA, позволяющие настроить параметры компиляции под GPU, в зависимости от типа GPU и т.д. Далее написан код программы на CUDA, который выводит на экран информацию об аппаратных возможностях GPU, таких например как: Название устройства Размер общей, глобальной памяти Размер варпа Максимальное количество потоков на блок Максимальный размер сетки Тактовая частота Размер общей постоянной памяти Вычислительные возможности #include #include int main() { int deviceCount; cudaDeviceProp deviceProp; //Сколько устройств CUDA установлено на PC. cudaGetDeviceCount(&deviceCount); printf("Device count: %d\n\n", deviceCount); for (int i = 0; i < deviceCount; i++) { //Получаем информацию об устройстве cudaGetDeviceProperties(&deviceProp, i); //Выводим иформацию об устройстве printf("Device name: %s\n", deviceProp.name); printf("Total global memory: %d\n", deviceProp.totalGlobalMem); printf("Shared memory per block: %d\n", deviceProp.sharedMemPerBlock); printf("Registers per block: %d\n", deviceProp.regsPerBlock); printf("Warp size: %d\n", deviceProp.warpSize); printf("Memory pitch: %d\n", deviceProp.memPitch); printf("Max threads per block: %d\n", deviceProp.maxThreadsPerBlock); printf("Max threads dimensions: x = %d, y = %d, z = %d\n", deviceProp.maxThreadsDim[0], deviceProp.maxThreadsDim[1], deviceProp.maxThreadsDim[2]); printf("Max grid size: x = %d, y = %d, z = %d\n", deviceProp.maxGridSize[0], deviceProp.maxGridSize[1], deviceProp.maxGridSize[2]); printf("Clock rate: %d\n", deviceProp.clockRate); } return 0; } Результаты выполнения программы показаны на рисунке 1. 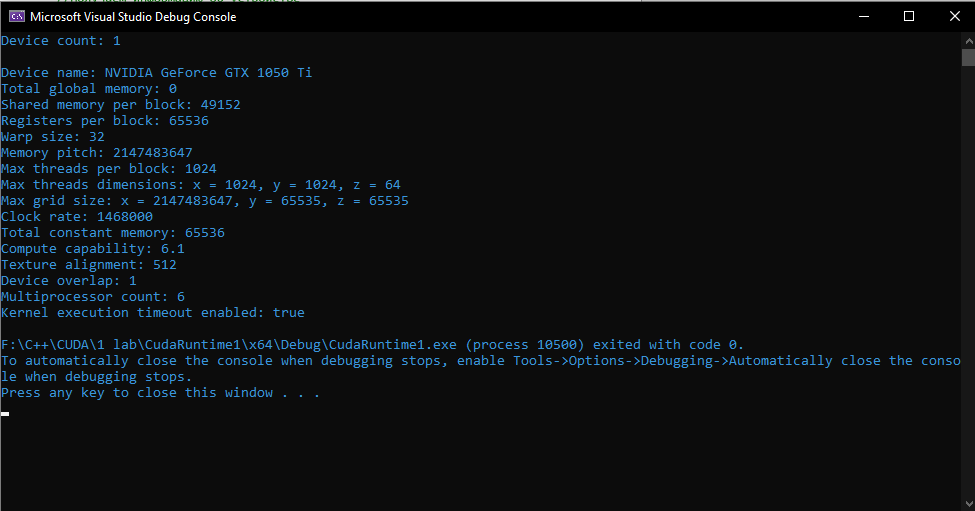 Рисунок 1 – Результаты выполнения программы ЗаключениеПроделанная работа показала, что архитектура CUDA имеет ряд возможностей, которые могут облегчить работу, благодаря работе на графических ускорителях. Ответы на вопросы |