|
|
Запуск примеров MapReduce. Лабораторная работа 2. Лабораторная работа 2 Запуск примеров MapReduce. Python&Hadoop
Лабораторная работа №2
Запуск примеров MapReduce. Python&Hadoop
Попробуем выполнить пример MapReduce с использованием Python. Это типичный пример подсчета слов в файле.
Прежде всего, нам нужна среда Hadoop. Поскольку он у нас есть, нам просто нужно перезапустить его.
$ docker start -i
Загрузка файлов в HDFS (распределенная файловая система Hadoop)
Прежде всего, внутри нашей среды Hadoop мы должны перейти к каталогу examples.
hduser@localhost:$ cd examples
Теперь скопируем файлы txt из локальной файловой системы в HDFS, используя следующие команды.
hduser@localhost:
/examples$ hdfs dfs -put *.txt input
Для создания входного каталога в распределенной файловой системе Hadoop, следует выполнить следующие команды:
hduser@localhost:
/examples$ hdfs dfs -mkdir /user
hduser@localhost:
/examples$ hdfs dfs -mkdir /user/
hduser
hduser@localhost:
/examples$ hdfs dfs -mkdir input
Мы можем проверить файлы, загруженные в распределенную файловую систему, используя.
hduser@localhost:
/examples$ hdfs dfs -ls input Found 4 items
-rw-r--r-- 1 hduser supergroup 1586488 2020-08-09 00:29 input/4300-0.txt
-rw-r--r-- 1 hduser supergroup 1428841 2020-08-09 00:29 input/5000-8.txt
-rw-r--r-- 1 hduser supergroup 15929 2020-08-09 00:29 input/data-text.txt
-rw-r--r-- 1 hduser supergroup 674570 2020-08-09 00:29 input/pg20417.txt
Проверка и разбор кода
Mapper будет считывать строки из stdin (стандартный ввод). Hadoop отправит поток данных, считанных из HDFS, в mapper, используя стандартный вывод (stdout). Картограф прочитает каждую строку, отправленную через стандартный интерфейс, очистив все символы, отличные от буквенно-цифровых, и создав список Python со словами (split). Наконец, он создаст строку “word \ t1”, это пара (work,1), результат снова отправляется в поток данных с использованием стандартного вывода (print).
#!/usr/bin/env python
import sysimport re
for line in sys.stdin: line = re.sub(r'\W+',' ',line.strip()) words = line.split()
for word in words: print('{}\t{}'.format(word,1))
Редуктор будет считывать каждый ввод (строку) из stdin и будет считать каждое повторяющееся слово (увеличивая счетчик для этого слова) и отправит результат в стандартный вывод. Процесс будет выполняться итеративным способом до тех пор, пока в stdin не останется больше входных данных.
#!/usr/bin/env python
import sys
current_word = None
current_count = 0
word = None
for line in sys.stdin:
line = line.strip()
word, count = line.split('\t',1)
try:
count = int(count)
except ValueError:
continue
if current_word == word:
current_count += count
else:
if current_word: print('{}\t{}'.format(current_word,current_count))
current_word = word
current_count = count
if current_word == word:
print('{}\t{}'.format(current_word,current_count))
Выполнение примера MapReduce
На диаграмме (рис. 1) показано, как MapReduce будет работать при подсчете слов, прочитанных из текстовых файлов. Все текстовые файлы считываются из HDFS / input и помещаются в поток стандартного вывода для обработки mapper и reducer, чтобы, наконец, результаты были записаны в каталог HDFS с именем /output.
Следующая команда выполнит процесс MapReduce с использованием текстовых файлов, расположенных в /user /hduser/input (HDFS), mapper.py, и reducer.py . Результат будет записан в распределенную файловую систему /user/hduser/output.
hduser@localhost:
/examples$ hadoop jar $HADOOP_HOME/share/hadoop/tools/lib/hadoop-streaming-
3.3.0.jar -картограф mapper.py -редуктор reducer.py
-ввод /user/hduser/input/*.txt –вывод
/user/hduser/output
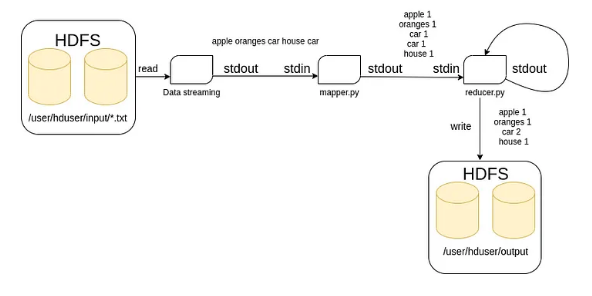
Рисунок 1
Чтобы проверить результаты, следует выполнить.
hduser@localhost:
/examples$ hdfs dfs -ls output
Found 2 items
-rw-r--r-- 1 hduser supergroup 0 2020-08-09 00:31 output/_SUCCESS
-rw-r--r-- 1 hduser supergroup 530859 2020-08-09 00:31 output/part-00000
Чтобы показать результаты, мы будем использовать команду cat.
hduser@localhost:
/examples$ hdfs dfs -cat output/*
0 64
00 2
000 116
001 1
01 1
02 4
Abulafia 1
Abulfeda 1
Academie 3
Academy 4
Accademia 7
Accademia_ 1
Accep 1
.......
......
....
zoophyte 2
zoophytes 2
zouave 1
zrads 3
zum 1
zur 1
zvith 1
zwanzig 1
zweite 1
Это простой способ (на простом примере) понять, как работает MapReduce.
|
|
|
 Скачать 71.67 Kb.
Скачать 71.67 Kb.