Лаба. Лабораторная работа 3 Нарушения допущений классической модели линейной регрессии Задания
 Скачать 0.94 Mb. Скачать 0.94 Mb.
|

|
8.4 Лабораторная работа № 3 Нарушения допущений классической модели линейной регрессии Задания 1 Проведите графический анализ остатков. Проверьте остатки на гетероскедастичность с помощью: - графического анализа, - теста Голдфелда-Квандта, - теста ранговой корреляции Спирмена, - теста Уайта (White test). 2 Если будет обнаружена гетероскедастичность остатков, примените для исходных данных ОМНК, предполагая, что 3 Проверить остатки на наличие автокорреляции первого порядка, используя метод рядов, критерий Дарбина – Уотсона и Q- статистику Льюинга – Бокса. Если гипотеза об отсутствии автокорреляции первого порядка не будет отвергнута, то применить ОМНК для оценивания параметров уравнения регрессии. Реализация типовых заданий 1 Провести графический анализ остатков В лабораторной работе № 1 выявили, что на чистый доход (y) предприятий оказывают влияния такие факторы, как использованный капитал (x2) и численность служащих (x3). Для нахождения остатков а) в главном меню выберите Сервис/Анализ данных/Регрессия. Щелкните по кнопке ОК; б) заполните диалоговое окно ввода данных и параметров ввода как показано на рисунке 8.8: Входной интервал Y – диапазон, содержащий данные результативного признака; Входной интервал Х – диапазон, содержащий данные всех пяти факторов; Метки – флажок, который указывает, содержит ли первая строка названия столбцов или нет; Константа – ноль – флажок, указывающий на наличие или отсутствие свободного члена в уравнении; Выходной интервал – достаточно указать левую верхнюю ячейку будущего диапазона; Новый рабочий лист - можно задать произвольное имя нового листа; Остаток - флажок, указывает вывод остатков 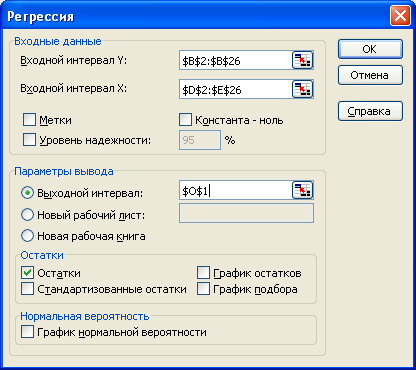 Рисунок 8.8 – Регрессия с остатками Результаты регрессионного и корреляционного анализа, а также вспомогательные характеристики представлены на рисунке 8.9.  Рисунок 8.4.2 – Вывод остатков Проверим остатки полученного уравнения регрессии на гетероскедастичность. Графический анализ остатков Построим графики остатков для каждого уравнения (рисунок 8.10 и 8.11) 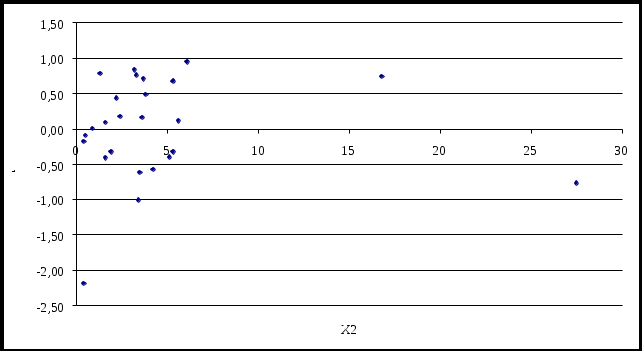 Рисунок 8.10 – График остатков для фактора х2 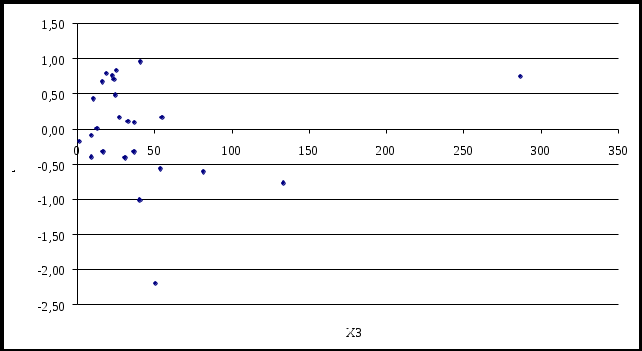 Рисунок 8.11 – График остатков для фактора х3 Как видно на рисунке отклонения не лежат внутри полуполосы постоянной ширины, это говорит, о зависимости дисперсионных остатков от величины х3 и о их непостоянстве, т.е. о наличии гетероскедастичности. Тест Голфелда-Квандта Выдвигаются гипотезы: Но: Н1: Порядок проведения теста следующий: 1 Все n наблюдений упорядочиваются по величине X2 и X3 (таблица 8.12 и 8.13). Таблица 8.12 – Упорядоченные значения по фактору х2
2 Исключим С центральных наблюдений, разобьем совокупность на две части: а) со значениями x ниже центральных; б) со значениями x выше центральных. Пусть С=5, это наблюдения с порядковыми номерами 11-15. 3 Оцениваются отдельные регрессии для первой подвыборки (10 первых наблюдений) и для третьей подвыборки (10 последних наблюдений). Если предположение о пропорциональности дисперсий отклонений значениям X верно, то дисперсия регрессии по первой подвыборке (сумма квадратов отклонений Таблица 8.13 – Упорядоченные значения по фактору х3
4 По каждой части находим уравнение регрессии (рисунок 8.12)  Рисунок 8.12 – Вывод итогов для подвыборок для фактора х2 5 Для сравнения соответствующих дисперсий строится следующая F-статистика: При сделанных предположениях относительно случайных отклонений построенная F-статистика имеет распределение Фишера с числами степеней свободы v1=v2=(n-C-2m)/2. 6 Если По проведенным расчетам мы получили, что Аналогично проводится анализ для фактора х3. Тест ранговой корреляции Спирмена Выдвигаются гипотезы: Но: Н1: Значения хi и абсолютные величины ui ранжируются (упорядочиваются по величинам). Затем определяется коэффициент ранговой корреляции: где di - разность между рангами хi и ui, i = 1, 2, ..., n; n - число наблюдений. Рассчитаем теоретические значения 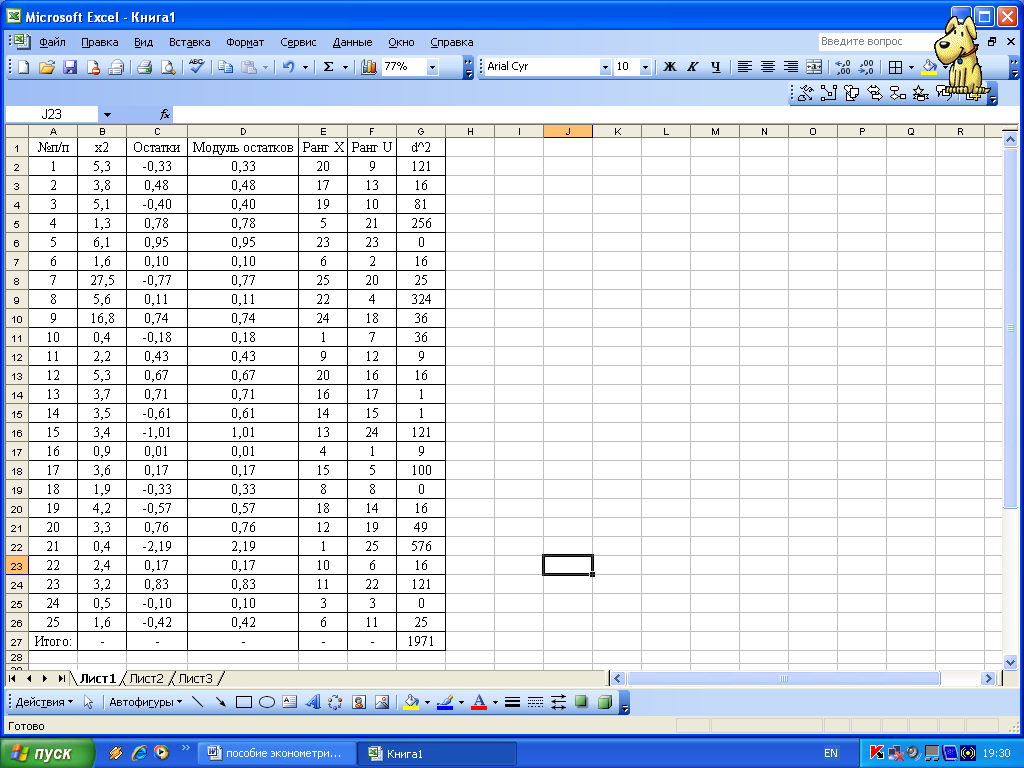 Рисунок 8.13 – Расчетная таблица для проведения теста Спирмена Тогда Если коэффициент корреляции имеет распределение Стьюдента с числом степеней свободы v=n-2. Следовательно, если наблюдаемое значение t-статистики превышает табличное, то необходимо отклонить гипотезу о равенстве нулю коэффициента корреляции В нашем примере статистика Стьюдента равна: Табличное значение статистики Стьюдента составит t(0,05; 23)=2,0687. Таким образом, мы получили, что расчетное значение меньше табличного, следовательно, гипотеза об отсутствии гетероскедастичности принимается на уровне значимости 5 %. Аналогично проводится анализ для фактора х3. Тест Уайта(Whitetest). Выдвигаются гипотезы: Но: Н1: Тест Уайта позволяет оценить количественно зависимость дисперсии ошибок регрессии где 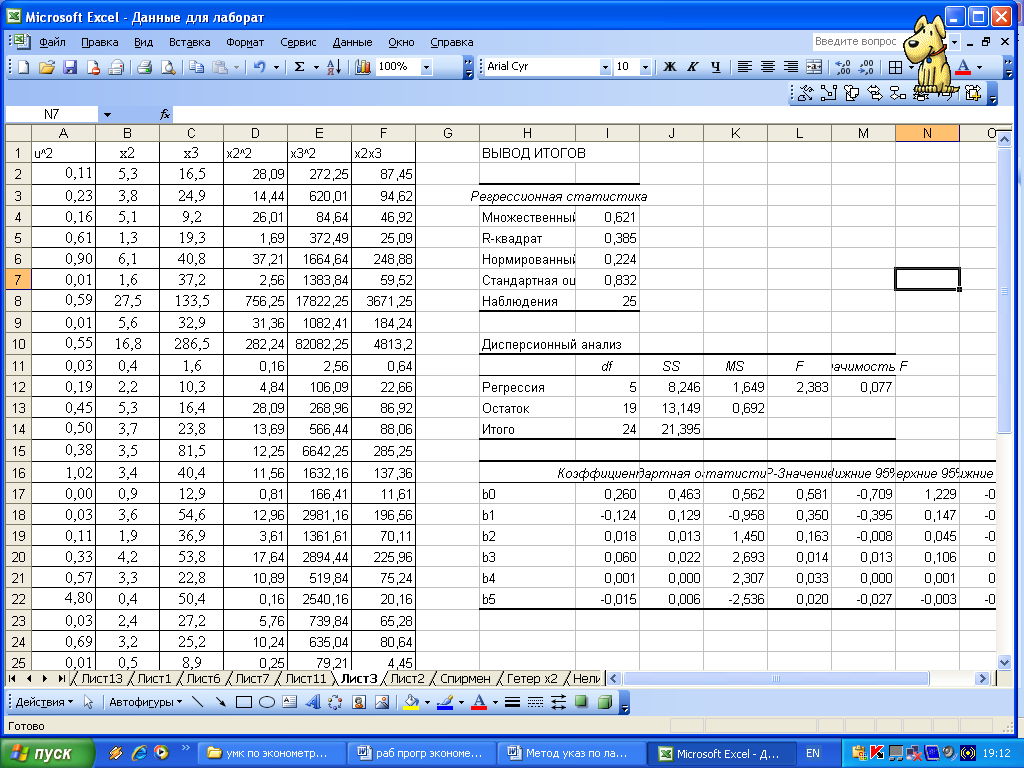 Рисунок 8.14 – Вывод итогов вспомогательной регрессии теста Уайта Проводится этот тест следующим образом: 1) получаем регрессионные остаткиui; 2) оцениваем вспомогательную регрессию; Гипотеза об отсутствии гетероскедастичности принимается в случае незначимости регрессии в целом. 3) в нашем примере вспомогательная регрессия принимает вид: Уравнение статистически незначимо на уровне значимости 2 Если будет обнаружена гетероскедастичность остатков, примените для исходных данных ОМНК, предполагая, что По всем проведенным тестам можно сделать вывод о гомоскедастичности регрессионных остатков. В противном случае для устранения гетероскедастичности необходимо применить к исходным данным обобщенный метод наименьших квадратов в предположении, что Исходное уравнение преобразуем делением правой и левой частей на x2:  Рисунок 8.15– Вывод итога ОМНК 3 Проверить остатки на наличие автокорреляции первого порядка, используя метод рядов, критерий Дарбина – Уотсона и Q- статистику Льюинга – Бокса. Если гипотеза об отсутствии автокорреляции первого порядка не будет отвергнута, то применить ОМНК для оценивания параметров уравнения регрессии. Метод рядов Последовательно определяются знаки остатков Ряд определяется как непрерывная последовательность одинаковых знаков. Количество знаков в ряду называется длиной ряда. Пусть n — объем выборки; n1 — общее количество знаков «+» при n наблюдениях; n2 — общее количество знаков «-» при n наблюдениях; k — количество рядов. Если при достаточно большом количестве наблюдений (n1>10, n2>10) количество рядов k лежит в пределах от k1 до k2: 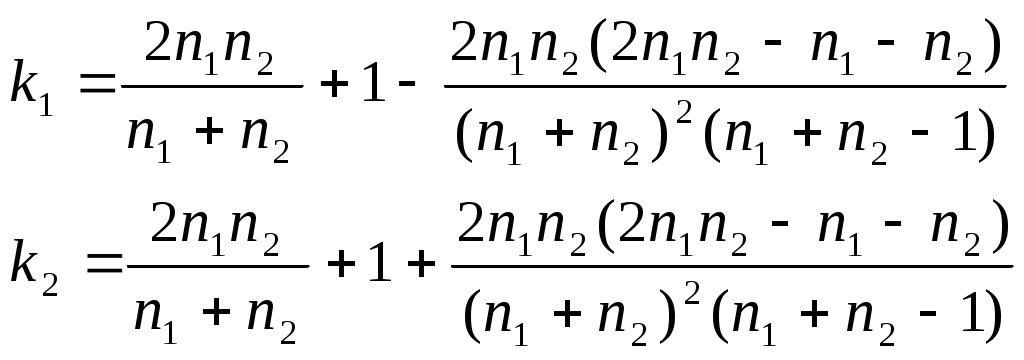 , ,то гипотеза об отсутствии автокорреляции не отклоняется. 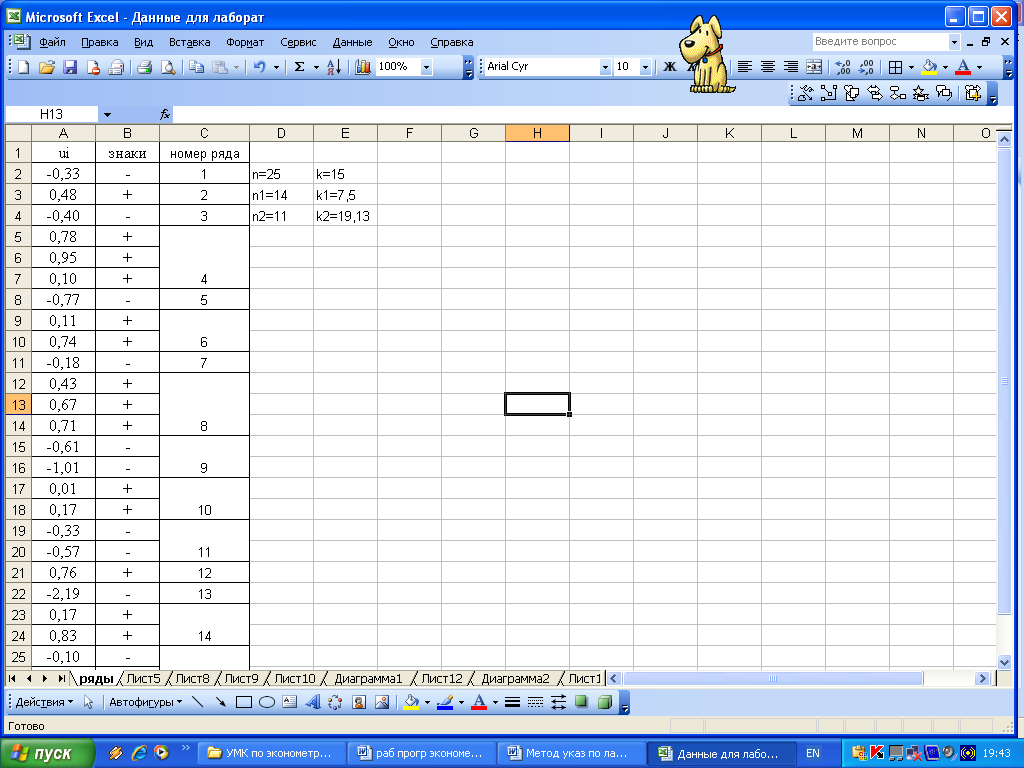 Рисунок 8.16 – Расчет характеристик метода рядов Найдя знаки отклонений теоретических уровней от фактических, мы получили, что в анализируемой выборке содержится 15 рядов, т.е. k=15 (рисунок 8.16). Общее количество знаков «+» n1=14, количество знаков «-» n2=11. Подставим найденные значения в формулу, получим, что k1=7,5, k2=19,13. Следовательно, гипотеза об отсутствии автокорреляции не отклоняется. Критерий Дарбина – Уотсона Для проверки автокорреляции первого порядка необходимо рассчитать критерий Дарбина—Уотсона. Он определяется так:  . .Выдвигается гипотеза Н0 об отсутствии автокорреляции остатков. При сравнении расчетного значения статистики (DW<2) с dl и du возможны следующие варианты. 1 Если DW< dl , то гипотеза Н0 отвергается. 2 Если DW > du, то гипотеза Н0 не отвергается. 3 Если dl< DW< du, то нельзя сделать определенного вывода по имеющимся исходным данным (зона неопределенности). При DW > 2, то с табличными значениями сравнивается величина (4-DW).  Рисунок 8.17 – Расчет критерия Дарбина – Уотсона В результате проведенных расчетов получено значение критерия Дарбина - Уотсона DW=2,2032 (рисунок 8.17). Так как оно больше 2, то с критическими значением сравниваем величину 4-DW=1,7967. Оно больше duследовательно мы не можем отвергнуть гипотезу Н0 – в ряду остатков отсутствует автокорреляция первого порядка. Q-тест Льюинга – Бокса Использование данного теста предполагает использование Q- статистики, значение которой определяется по формуле: где n – число наблюдений. Q- статистика имеет Рассчитаем для нашей задачи Q- статистику. Для этого необходимо определить коэффициенты автокорреляции. Максимальная величина лага не должна превышать ¼ числа наблюдений, т.е. в рассматриваемом примере  Рисунок 8.18 – Расчет Q-статистики Льюинга - Бокса Подставив полученное значение в формулу, получим: Табличное значение Фактическое значение статистики меньше критического, следовательно, гипотеза принимается, т.е. в ряду остатков отсутствует автокорреляция. |