МУЛР ИСИТ. МУЛР ИСиТ №8. Лабораторная работа 8 Метод случайного леса
 Скачать 120.39 Kb. Скачать 120.39 Kb.
|

|
Лабораторная работа № 8 Метод случайного леса Цель: Сформировать понятие случайного леса, а также научить обучающихся использовать данную модель для решения задач. Задачи: Рассмотреть понятие случайного леса; рассмотреть пример кода для решения простых задач; научить подбирать параметры модели для улучшения качества прогнозов модели. Ход работы: Случайный лес (Рисунок 1) — очень популярный и эффективный алгоритм машинного обучения. Это разновидность ансамблевого алгоритма, называемого бэггингом. Бутстрэп является эффективным статистическим методом для оценки какой-либо величины вроде среднего значения. Вы берёте множество подвыборок из ваших данных, считаете среднее значение для каждой, а затем усредняете результаты для получения лучшей оценки действительного среднего значения. В бэггинге используется тот же подход, но для оценки всех статистических моделей чаще всего используются деревья решений. Тренировочные данные разбиваются на множество выборок, для каждой из которой создаётся модель. Когда нужно сделать предсказание, то его делает каждая модель, а затем предсказания усредняются, чтобы дать лучшую оценку выходному значению. 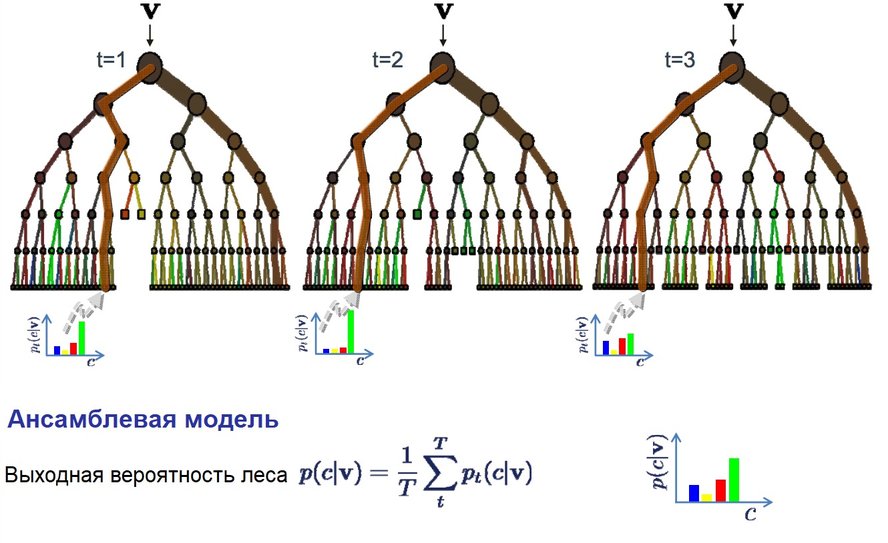 Рисунок 1-Леса решений Разбирать лес решений мы будем на примере датасета ирисов и для начала мы импортируем все необходимые для работы библиотеки (Рисунок 2):  Рисунок 2-Импортируемые библиотеки Выгружаем датасет в переменную (Рисунок 3): Рисунок 3-Выгрузка датасета в переменную Теперь необходимо разделить датасет на тестовую и тренировочные выборки (Рисунок 4): Рисунок 4-Деление датасета на выборки Обучаем модель (Рисунок 5): Рисунок 5-Обучение модели Производим предсказание на основе обученной модели (Рисунок 6): Рисунок 6-Классификация Теперь с помощью функции выведем точность произведенной классификации (Рисунок 7): Рисунок 7-Подсчет точности ответов Результат (Рисунок 8) получился невероятно хорошим: Рисунок 8-Результат Причиной этому может быть маленькая выборка датасета, а также большое количество деревьев в лесу. В отличие от одного дерева, для леса не страшно переобучение. Также чем больше деревьев в лесу, тем более точными будут ответы, но и скорость обработки будет увеличиваться пропорционально. Вопросы для самопроверки: Что такое метод случайного леса? Как влияет на результат классификации количество деревьев в лесу? Опишите процесс работы случайного леса. Возможно ли переобучение для этого метода? Назовите плюсы и минусы данного метода классификации. |