Лабораторная работа по предмету Конструирование компиляторов
 Скачать 0.97 Mb. Скачать 0.97 Mb.
|

Модельный язык в расширенной форме Бэкуса — Наура |
| { | } |
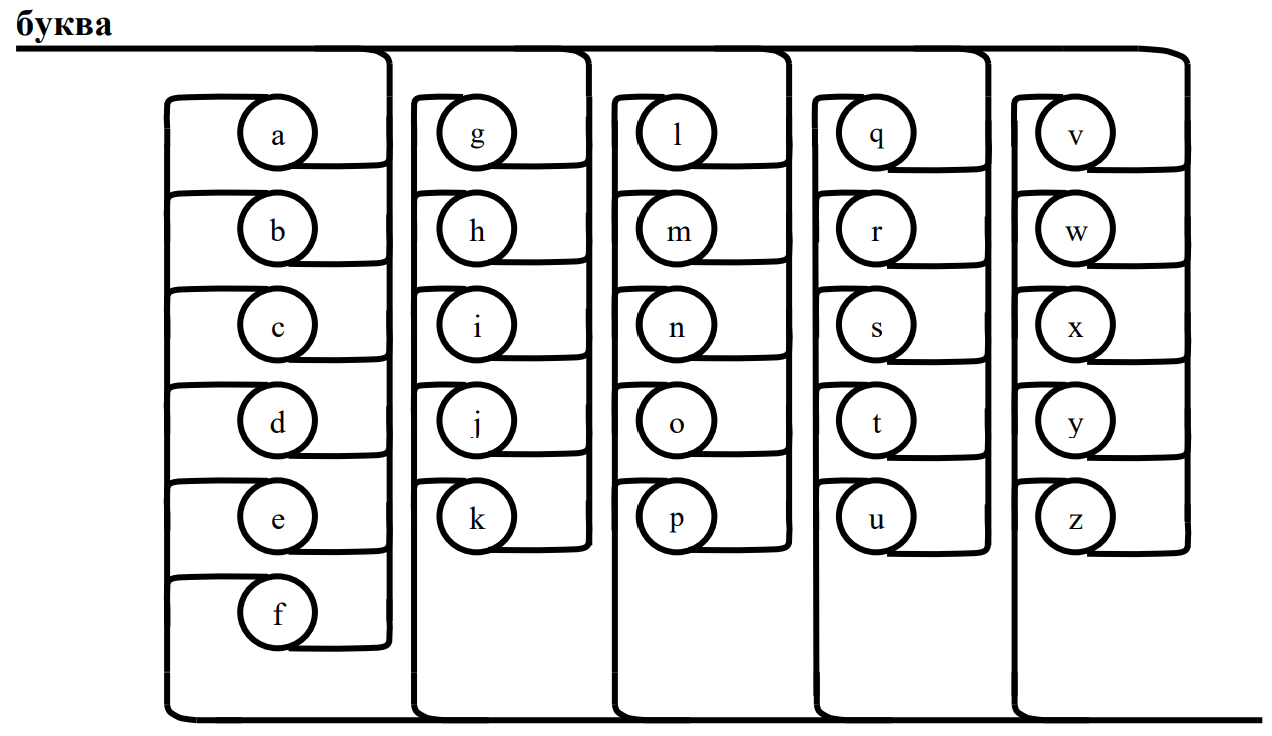
Служебные слова (1):
| true | false | dim | int | float | bool | if | then | else | for | to | do | while | read | write |
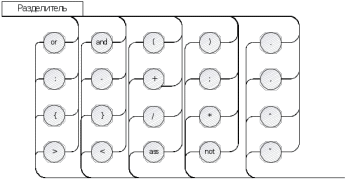
Разделители (2):
| <> | = | < | <= | > | >= | + | - | or | * | / | and | not | ( | ) |
| { | } | ; | : | , | ass | | | | | | | | | |
Диаграмма состояний
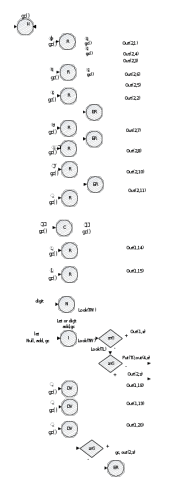
Рис 1. Диаграмма состояний при распознавании базовых лексем
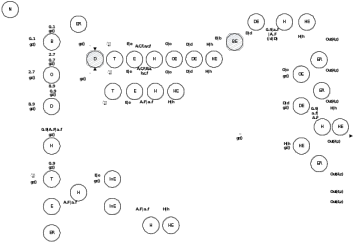
Рис 2. Диаграмма состояний при распознавании числа
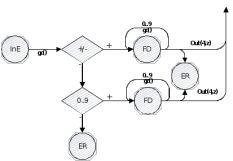
Рис 3. Диаграмма состояний при распознавании порядка числа
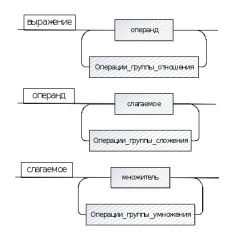
Диаграммы Вирта
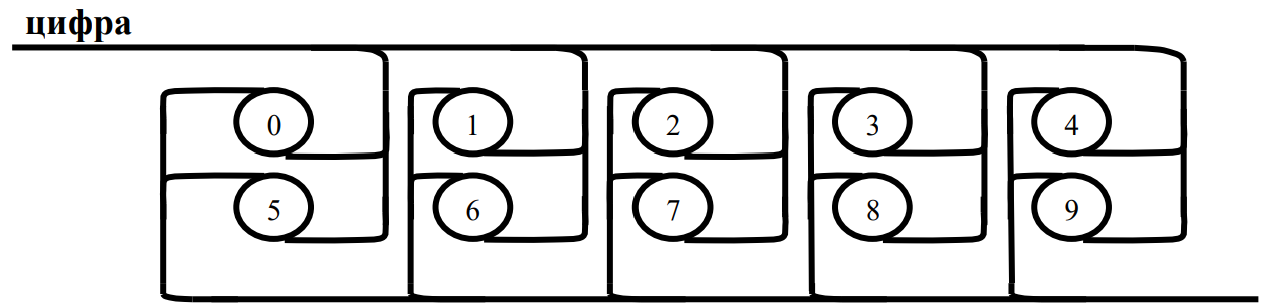
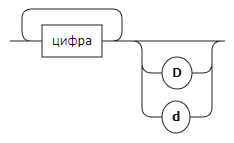
число


Целое:
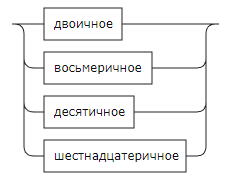
Двоичное:
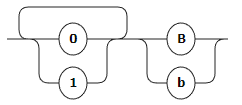
Восьмеричное:
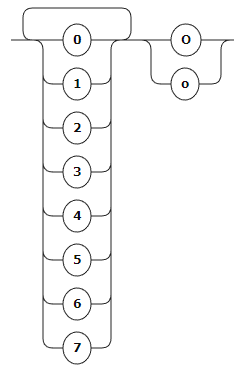
Десятичное:
Действительное:
Шестнадцатиричное:
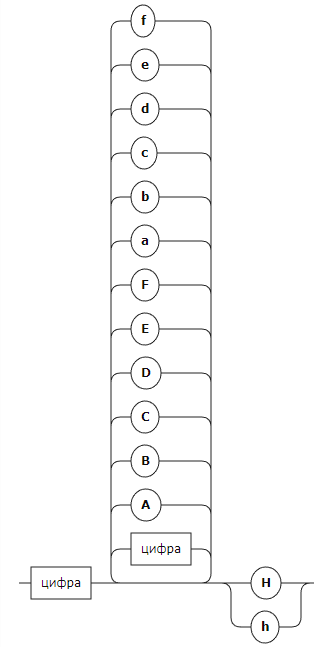
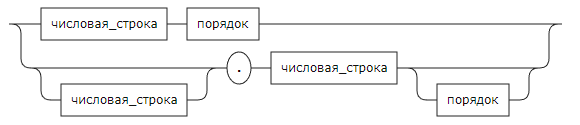
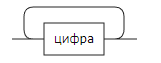
Числовая строка:
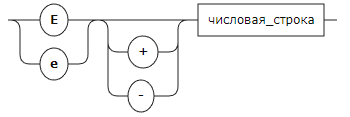
Порядок:
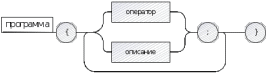
Оператор:





Операции группы отношения:
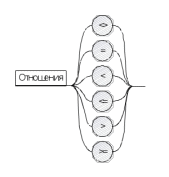
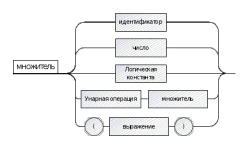
 Логическая константа:
Логическая константа: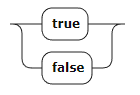
ANTLR
Для реализации модульного языка был выбран язык программирования Python3 и среда разработки PyCharm в окружении дистрибутива Debian 11.
Для начала необходимо установить python3, pip и antlr4, выполним от администратора:
apt install python3 pip antlr4
Далее установим библиотеку antlr4 для python3:
pip install antlr4-python3-runtime
После этого создаём проект в PyCharm, в нём создаём грамматику, главный файл и слушатель.
grammar GrammarBelovNikita;
BOOL: 'true' | 'false';
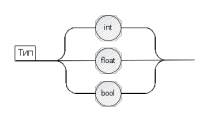
TYPE: 'int' | 'float' | 'bool';
WS: [ \n\t\r]+ -> skip;
SPACE: ' ';
COMMA: ',';
COLON: ':';
SEMICOLON: ';';
BLOCK_OPEN: '(';
BLOCK_CLOSE: ')';
OPERATION_RATIO: '=' | '<>' | '<' | '<=' | '>' | '>=';
OPERATION_SUMMARY: '+' | '-' | 'or';
OPERATION_MULTIPLE: '*' | '/' | 'and';
OPERATION_UNARY: 'not';
fragment NUMBER_STRING: [0-9]+;
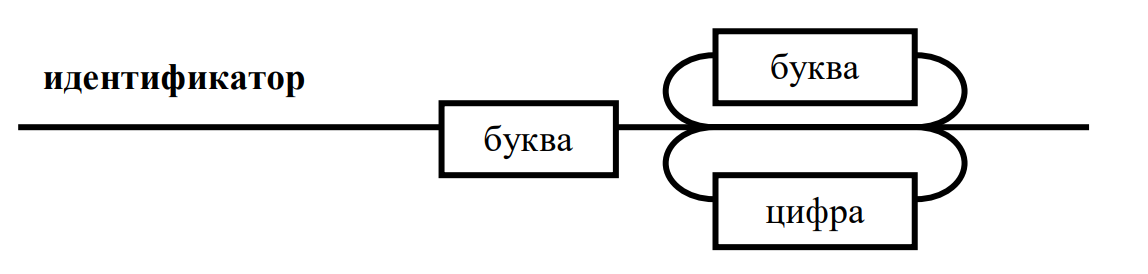
IDENTIFIER: [a-zA-Z]([a-zA-Z] | NUMBER_STRING)*;
NUMBERS: INTEGER | REAL;
INTEGER: BINARY | OCTAL | DECIMAL | HEXADECIMAL;
BINARY: [0-1]+ ('B' | 'b');
OCTAL: [0-7]+ ('O' | 'o');
DECIMAL: NUMBER_STRING ('D' | 'd')?;
HEXADECIMAL: NUMBER_STRING ([0-9] | [a-fA-F])* ('H' | 'h');
REAL: (
(NUMBER_STRING ORDER)
| ((NUMBER_STRING)? '.' NUMBER_STRING (ORDER)?)
);
fragment ORDER: ('E' | 'e') ('+' | '-')? NUMBER_STRING;
// ------------------
program: '{' ((((description | operator) SEMICOLON) | multistr_comment) (' ' | '\n' | '\t' | '\r')*)+ '}';
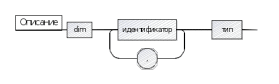
description: 'dim' IDENTIFIER (COMMA IDENTIFIER)* TYPE;
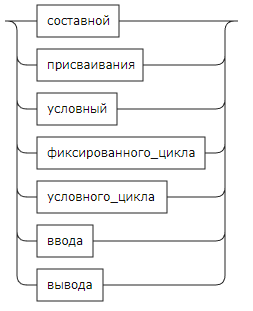
operator: operator_wo_composite | composite;
operator_wo_composite:
assignments
| conditional
| fixed_cycle
| conditional_loop
| input_m
| output_m;
composite:
operator_wo_composite ((COLON | '\n') operator_wo_composite)*;
assignments: IDENTIFIER 'ass' expression;
conditional: 'if' expression 'then' operator ('else' operator)?;
fixed_cycle: 'for' assignments 'to' expression 'do' operator;
conditional_loop: 'while' expression 'do' operator;
expression: operand ( OPERATION_RATIO operand)*;
operand: summand (OPERATION_SUMMARY summand)*;
summand: multiplier (OPERATION_MULTIPLE multiplier)*;
multiplier:
BOOL
| IDENTIFIER
| NUMBERS
| OPERATION_UNARY multiplier
| BLOCK_OPEN expression BLOCK_CLOSE;
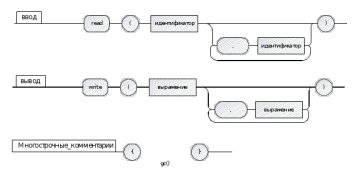
input_m:
'read' BLOCK_OPEN IDENTIFIER (COMMA IDENTIFIER)* BLOCK_CLOSE;
output_m:
'write' BLOCK_OPEN expression (COMMA expression)* BLOCK_CLOSE;
multistr_comment: '{' '}'* '}';
Листинг 1. GrammarBelovNikita.g4
import sys
from antlr4 import *
from MyListner import MyGrammarListner
from com.antlr.GrammarBelovNikitaLexer import GrammarBelovNikitaLexer
from com.antlr.GrammarBelovNikitaParser import GrammarBelovNikitaParser
def create_generator(argv):
lexer = GrammarBelovNikitaLexer(FileStream('test.prog'))
stream = CommonTokenStream(lexer)
parser = GrammarBelovNikitaParser(stream)
tree = parser.program()
program = MyGrammarListner()
walker = ParseTreeWalker()
walker.walk(program,tree)
if __name__ == '__main__':
create_generator(sys.argv)
Листинг 2. Главный файл приложения.
import antlr4
import regex as regex
from com.antlr.GrammarBelovNikitaListener import GrammarBelovNikitaListener
from com.antlr.GrammarBelovNikitaParser import GrammarBelovNikitaParser
class MyGrammarListner(GrammarBelovNikitaListener):
def enterProgram(self, ctx: GrammarBelovNikitaParser.ProgramContext):
self.variables = {}
self.stack_value = []
def enterDescription(self, ctx: GrammarBelovNikitaParser.DescriptionContext):
# проходимся циклом по токенам до :
type = ctx.TYPE()
for identifier in ctx.IDENTIFIER():
#print(identifier.__str__() + ' (' + type.__str__() + ')')
self.variables[identifier.__str__()] = {
'type': type.__str__(),
'value': 'None'
}
def exitDescription(self, ctx: GrammarBelovNikitaParser.DescriptionContext):
pass
def enterExpression(self, ctx: GrammarBelovNikitaParser.ExpressionContext):
pass
def exitExpression(self, ctx: GrammarBelovNikitaParser.ExpressionContext):
pass
def exitAssignments(self, ctx: GrammarBelovNikitaParser.AssignmentsContext):
# Присваивание
buf_ident = ctx.IDENTIFIER().__str__()
if buf_ident in self.variables.keys():
# проверяем на типы данных
# expression - должен быть последним в наборе данных, по этому берем последнее
expression = self.stack_value[-1]
if self.variables[buf_ident]['type'] == expression['type']:
self.variables[buf_ident]['value'] = expression['value']
#print(str(buf_ident) + ' = ' + str(self.variables[buf_ident]['value']))
elif self.variables[buf_ident]['type'] == 'int' and expression['type'] == 'float':
self.variables[buf_ident]['type'] = 'float'
self.variables[buf_ident]['value'] = expression['value']
elif self.variables[buf_ident]['type'] == 'float' and expression['type'] == 'int':
self.variables[buf_ident]['value'] = expression['value']
else:
print('Ошибка! Переменной ' + self.variables[buf_ident]['type'] + ' нельзя присвоить данные типа ' +
expression['type'])
print(str(buf_ident) + ' = ' + str(self.variables[buf_ident]['value']))
def exitExpression(self, ctx: GrammarBelovNikitaParser.ExpressionContext):
if ctx.OPERATION_RATIO():
print(ctx.OPERATION_RATIO())
return
def exitOperand(self, ctx: GrammarBelovNikitaParser.OperandContext):
if ctx.OPERATION_SUMMARY():
count_move = len(ctx.OPERATION_SUMMARY())
list_operand = list(reversed(self.stack_value[-(count_move+1):]))
del self.stack_value[-(count_move + 1):]
for i in range(0, len(ctx.OPERATION_SUMMARY())):
buf_value = {'type': None, 'value': None}
operation = str(ctx.OPERATION_SUMMARY()[i])
left = list_operand[count_move-i]
right = list_operand[count_move-i-1]
if operation == '+':
if left['type'] != 'bool' and right['type'] != 'bool':
buf_value['value'] = left['value'] + right['value']
# TODO
if left['type'] == 'float' or right['type'] == 'float':
buf_value['type'] = 'float'
else:
buf_value['type'] = 'integer'
elif operation == '-':
if left['type'] != 'bool' and right['type'] != 'bool':
buf_value['value'] = left['value'] - right['value']
if left['type'] == 'float' or right['type'] == 'float':
buf_value['type'] = 'float'
else:
buf_value['type'] = 'integer'
elif operation == 'or':
if left['type'] == 'bool' and right['type'] == 'bool':
buf_value = left['value'] | right['value']
del list_operand[count_move - i]
del list_operand[count_move - i - 1]
#print('add ' + buf_value['type'] + ' ' + buf_value['value'])
list_operand.append({'type': buf_value['type'], 'value': buf_value['value']})
self.stack_value.append(list_operand[0])
def exitSummand(self, ctx: GrammarBelovNikitaParser.SummandContext):
if ctx.OPERATION_MULTIPLE():
count_move = len(ctx.OPERATION_MULTIPLE())
list_operand = list(reversed(self.stack_value[-(count_move + 1):]))
del self.stack_value[-(count_move + 1):]
for i in range(0, len(ctx.OPERATION_MULTIPLE())):
buf_value = {'type': None, 'value': None}
operation = str(ctx.OPERATION_MULTIPLE()[i])
left = list_operand[count_move - i]
right = list_operand[count_move - i - 1]
if operation == '*':
if left['type'] != 'bool' and right['type'] != 'bool':
buf_value['value'] = left['value'] * right['value']
if left['type'] == 'float' or right['type'] == 'float':
buf_value['type'] = 'float'
else:
buf_value['type'] = 'int'
elif operation == '/':
if left['type'] != 'float' and right['type'] != 'float':
buf_value['value'] = left['value'] / right['value']
buf_value['type'] = 'float'
elif operation == 'and':
if left['type'] == 'bool' and right['type'] == 'bool':
buf_value = left['value'] & right['value']
del list_operand[count_move - i]
del list_operand[count_move - i - 1]
#print('add ' + buf_value['type'] + ' ' + buf_value['value'])
list_operand.append({'type': buf_value['type'], 'value': buf_value['value']})
self.stack_value.append(list_operand[0])
#print('exit operand')
#print('exit summand')
def exitMultiplier(self, ctx: GrammarBelovNikitaParser.MultiplierContext):
#print(ctx.OPERATION_UNARY())
#Здесь необходимо записать данные о значении просто в память
if ctx.OPERATION_UNARY():
self.stack_value.append('not')
elif ctx.BOOL():
self.stack_value.append(self.get_value_with_type(ctx.BOOL().__str__()))
elif ctx.IDENTIFIER():
self.stack_value.append(self.variables[str(ctx.IDENTIFIER())])
elif ctx.NUMBERS():
self.stack_value.append(self.get_value_with_type(ctx.NUMBERS().__str__()))
elif ctx.BLOCK_OPEN() and ctx.BLOCK_CLOSE():
self.stack_value.append(ctx.BLOCK_OPEN().__str__())
self.stack_value.append(ctx.BLOCK_CLOSE().__str__())
#print('exit multiplier')
def exitProgram(self, ctx: GrammarBelovNikitaParser.ProgramContext):
print('Программа закончила свою работу')
def exitOutput_m(self, ctx:GrammarBelovNikitaParser.Output_mContext):
list_children = [x for x in ctx.children if str(x) not in ['write','(',',',')']]
buf_k = ''
for x in list_children:
try:
buf_k += str(self.get_value_with_type(x.start.text))
except:
buf_k += str(self.get_value_with_type(x.symbol.text))
buf_k += '\n'
print(buf_k)
def get_value_with_type(self, value: str) -> dict:
if isinstance(value, antlr4.TerminalNode):
return
#print('_DBG_: ' + value)
#print(self.stack_value)
output = {
'type': None,
'value': None
}
if value in self.variables.keys():
return self.variables[value]
# если bool
if any(x in value for x in ['true', 'false']):
output['type'] = 'bool'
if value == 'true':
output['value'] = True
else:
output['value'] = False
# если real
# < действительное >: := < числовая_строка > < порядок > | [ < числовая_строка >].< числовая_строка > [
# порядок]
elif regex.fullmatch(r'([0-9]+[eE][+-][0-9]+)|([0-9]*\.[0-9]+([eE][+-][0-9]+)?)', value):
output['type'] = 'float'
output['value'] = float(value)
else:
output['type'] = 'int'
# двоичное
if regex.fullmatch(r'[01]+[bB]', value):
value = regex.split(r'[bB]', value)[0]
output['value'] = int(value, 2)
# восьмиричное
elif regex.fullmatch(r'[0-7]+[oO]', value):
value = regex.split(r'[oO]', value)[0]
output['value'] = int(value, 8)
# десятичное
elif regex.fullmatch(r'[0-9]+[dD]?', value):
value = regex.split(r'[dD]', value)[0]
output['value'] = int(value, 10)
# шестнадцатеричное
elif regex.fullmatch(r'[0-9][0-9a-fA-F]+[hH]', value):
value = regex.split(r'[hH]', value)[0]
output['value'] = int(value, 16)
return output
Листинг 3. Слушатель.
Для тестирования программы используем следующий файл:
{
dim intVar, i int;
dim floatVar, f float;
intVar ass 123 ;
i ass 10101010b;
floatVar ass 456;
f ass 78.90;
write(intVar, i, floatVar, f, 101, true);
{ lelelele
kearkeaw }
}
Листинг 4. Тестовая программа модульного языка.
intVar = 123
i = 170
floatVar = 456
f = 78.9
{'type': 'int', 'value': 123}
{'type': 'int', 'value': 170}
{'type': 'float', 'value': 456}
{'type': 'float', 'value': 78.9}
{'type': 'int', 'value': 101}
{'type': 'bool', 'value': True}
Программа закончила свою работу
Листинг 5. Вывод работы тестовой программы модульного языка.